🔄
LLMで追加学習なしで、回帰が強い!これ本当なら凄いですよね!
まえがき
- いいねの数予測したくて、ググったらこんな論文見つけました。説明します!
論文読んで、自分が理解した内容です。コスト無視したら実用的に使えると思う。
読者対象
- 回帰タスクをさらっとやりたい人。特に他の言語タスクと連携したい人。
- インコンテキストラーニング等、LLMの理解を深めたい人
1. どんなもの
- LLMで追加学習なしで、回帰、つまり入力変数から出力変数の値を予測するタスクで性能が従来の教師ありモデルと同等もしくはより性能高い結果が出てる(回帰モデル、多項式回帰モデルには負けてそう)
- 最近のLLMはコンテキスト長がやばいので、けっこう使える手法かなと思えた。
- From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples
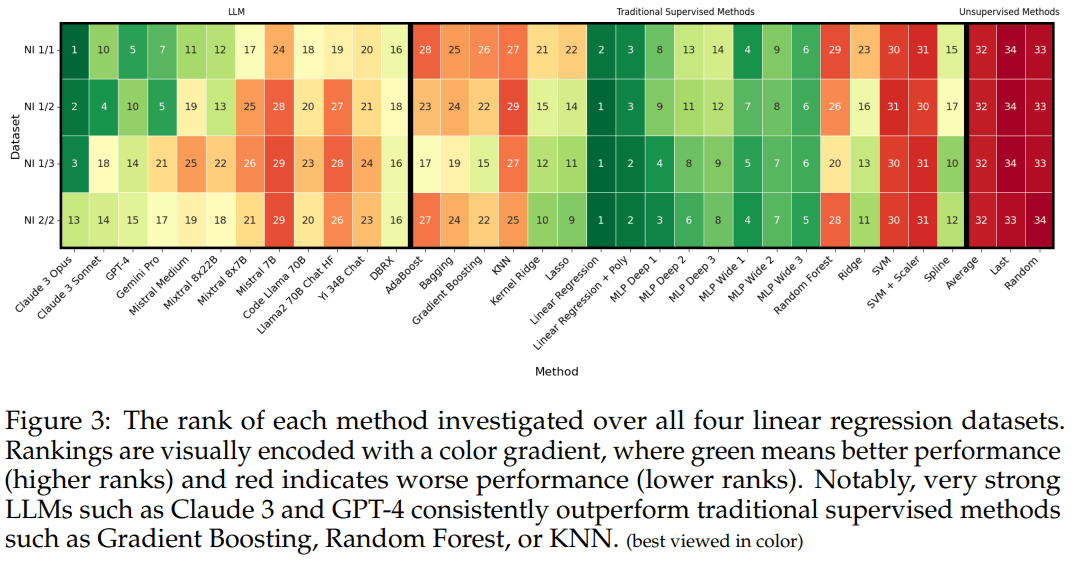
- 図は線形回帰での評価左3点がLLM、残りは従来教師あり学習モデル

- 図は線形回帰データでの勝敗表(右3つは単に平均、最後のデータ、ランダムでデータから選ぶ)
- 図は非線形での結果(多項式回帰モデルには負けてそう)
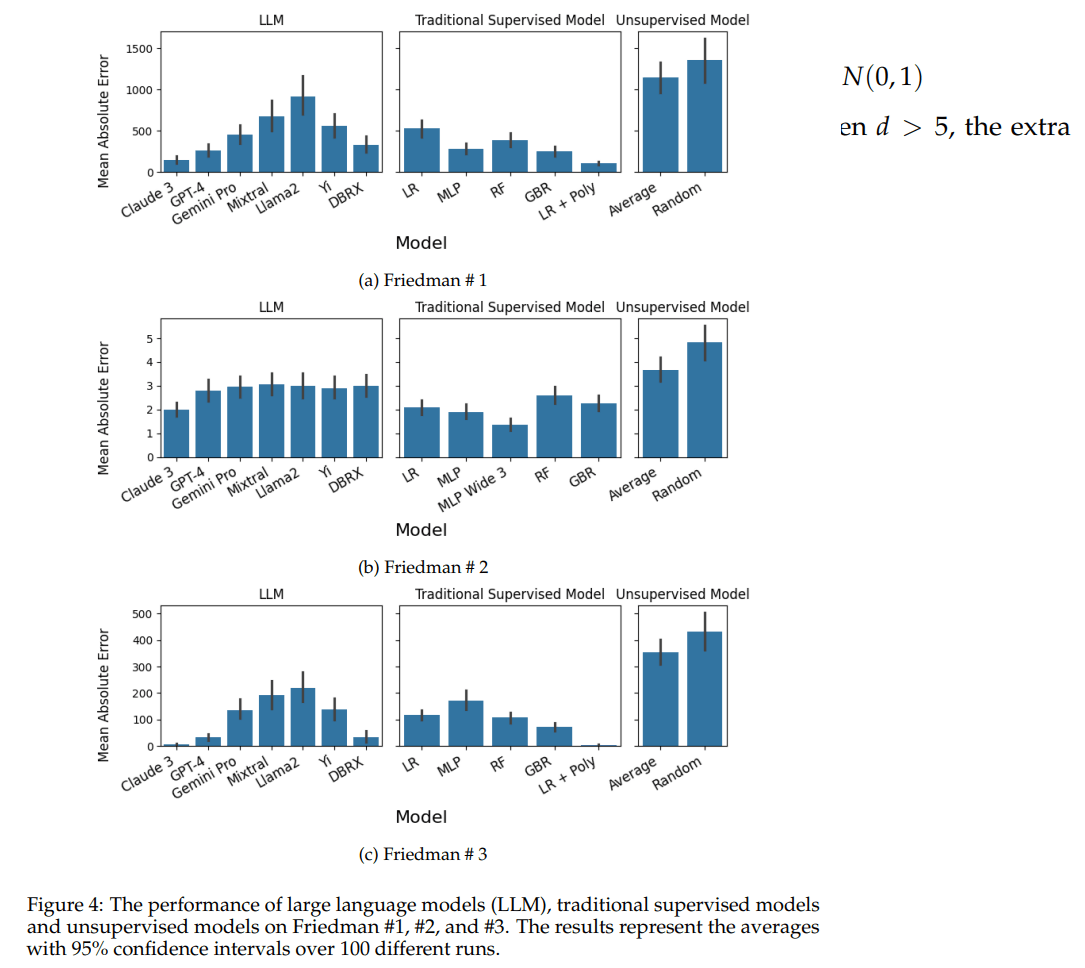
- 図は非線形回帰データでの勝敗表

2. 先行研究と比べてどこがすごいの?
- 事前学習LLMに対し追加学習なしで、つまり重み更新なしで、インコンテキストラーニングつまり例を複数与えるだけで、よい回帰性能を確認したこと。
3. 技術や手法の"キモ"はどこにある?
- 以下キモってほどではないが。
- 回帰データを生成して学習に使っている。フリードマンというツールを使用。生成データを使っていいところは 1)アルゴリズムをもとに生成できる。2)難しさを制御できる 3)データの可用性が高い
- データ点が増えると損失は増えるがその割合は減っている、つまり、データ数多い方がより予測ができるようになることを確認した。亜線形になっている(増加の割合がだんだん遅くなることの意味)

- 上記グラフがどんな関数に近いかの図 log>sqrt>linerの順で良いみたい
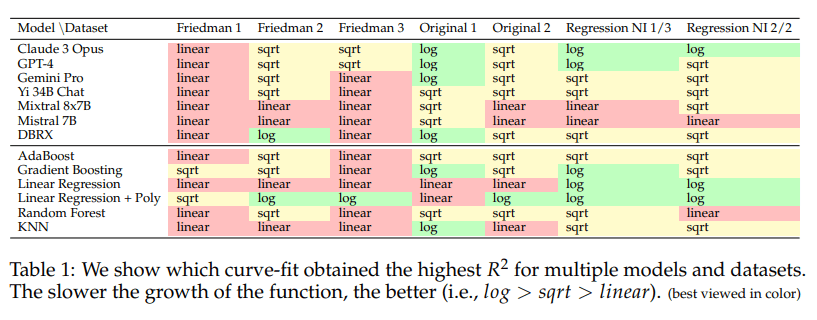
4. どうやって有効だと検証した?
同じ回帰データに対して複数のモデルで性能評価した。評価は何回も行われ、異なる試行における平均値であり、95%の信頼区間で示されているとのこと。
5. 議論はあるか?
- Friedmanは有名でFridman#1でLLMにきくとこの論文で使用している以下の式でてきた。つまり学習している可能性ある。ただし、独自の式でもいい評価でているとのこと。
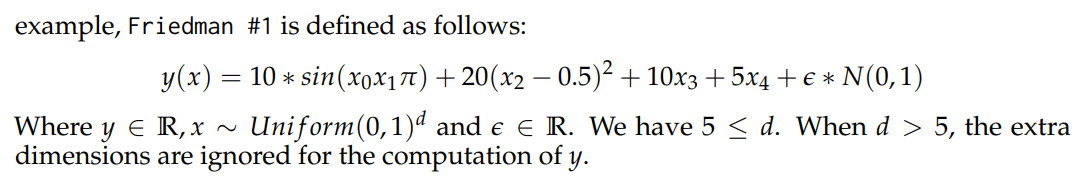
- ただし、独自の新しい式でもいい評価でているとのこと。以下はその一例

- 回帰モデル、多項式回帰モデルには負けてそうな部分で、論文は特に記載ないと思うが こちらは基底がうまく設計できないと性能出ないため LLMの方が実用的って考えもあると思った。
- 既存の学習モデルの学習データ数がインコテキストラーニングの例数と同じならLLM有利の可能性あると思った。
- 内部で、どうやっているかXAIで判明する論文がでてくるのが楽しみ!
- あと、推論結果だけでなくどう計算したもだせるとなお良いですね!
- 既存の推論と比べてコストはよくない気がするので、その対比表もみたい。
6. 次に読むべき論文はあるか? 記事も。
- ちょっと適当ですがThe Representation Landscape of Few-Shot Learning
and Fine-Tuning in Large Language Models - この論文見つけた動機となった記事ZENNの”投稿”経験を良くしよう! 第1回 ビューティフル スープで必要なデータを集める。
あとがき
記事よかったら、いいね♡ 押したり、フォローしてくれたら嬉しい!
Discussion