そろそろ次のアルゴリズム、複数多項式二次篩法 (MPQS) に移行します。
概要
QSでは
x2≡x2−N(modN)
として x2−N を篩っていましたが、MPQSでは適当な 3 数 a, b, c を設定して
(ax+b)2≡(ax+b)2−N(modN)=a(ax2+2bx+c)
を篩っていきます。a, b, c に関する制約は追々設定していきますが、今はこの式変形が成り立つものとして進めてください&名前の「複数」は一旦忘れてください。
このとき、実質的に QS での x2−N と MPQS での (ax+b)2−N が同じ程度の数になることが期待されますが MPQS では a を因数に持つことが確定するように係数設定をするので、本質的に篩をかける数 ax2+2bx+c はその分小さく、つまり smooth になりやすくなります。
参考までに QS と MPQSで同じ幅 2M の篩をかけたとするときの数の大きさを比較してみましょう。
QS では (N−M,N+M) で f(x)=x2−N を篩うので、
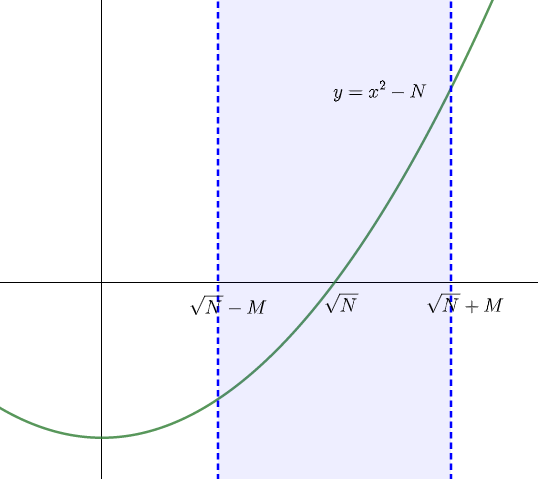
QSで篩う範囲
maxf(x)=f(N+M)=2NM+M2≃2NM
一方で MPQS では (−M,M) で f(x)=(ax+b)2−N=ag(x) を篩うので
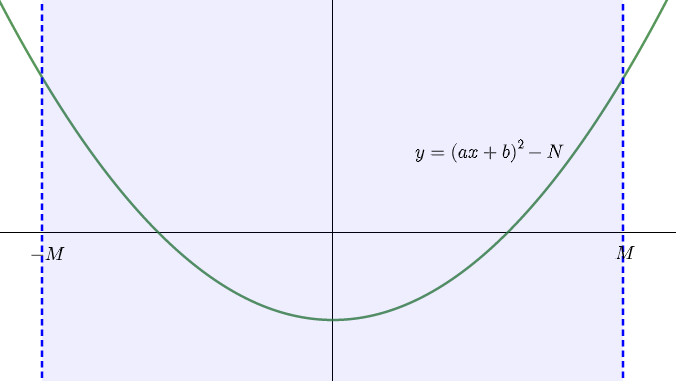
MPQSで篩う範囲
smoothness のことだけを考える場合は g(x)=ax2+2bx+c を考えて
max∣g(x)∣=max(g(M),−g(0))=a1max((aM+b)2−N,N−b2)
となります。こちらは候補の両方の値が同じくらいの時に全体として最小になることが期待されるので b≪aM として
(aM)2−N≃N∴a≃M2N
のときに
max∣g(x)∣≃N/a=2NM
の smoothness が対象となります。これは QS と比較してざっくり 1/22≃1/2.8 となっています。
さらに MPQS では異なる (a,b) を設定することで実質的に異なる値を篩うことになるので M をより小さく設定することができ、g(x) の絶対値をより小さく、より smooth になりやすくすることができます。(「複数」という名前を思い出したかのように)
制約
では上記のような計算ができる a, b, c の制約について見直していきましょう。
まず a については
a(ax2+2bx+c) を篩っていきます。
から、
a=(平方数)×(smoothな数)(A1)
となる必要があります。そうでなければ a(ax2+2bx+c) が smooth にならない(対偶)ので。ここで平方数の部分は FB に含まれない素数を使っていても構いませんが、どの a を使ったものか保持しておく必要はあります。あと後ろの説明から a の素因数 pi は (N/pi)=1 (平方剰余) を満たす必要があります。
次に b の制約について最初の式を変形させてみましょう。
(ax+b)2−N=a(ax2+2bx+c)a2x2+2abx+b2−N=a2x2+2abx+acb2−ac=N
するとこの式から
b2≡N(moda)(B1)
という条件が導かれます。この合同方程式は a の素因数分解を利用して解きます。具体的には各素因数 pi について bi2≡N(modpi) をこちらで解いて中国剰余定理で復元させます。 読んでる参考書類には尽く b<a/2 と書いてますが、どこからその条件が出てくるか分かりません。
c については同じ式から
c=ab2−N
で求まりますが使うことがないので計算しません。
MPQS と SIQS
MPQS は篩に使う式の数を増やすことで篩う範囲を絞り、効率的に smooth な関係式を得るアルゴリズムです。この複数の式を作る方法にも少しバリエーションというか発展があるので、そちらも紹介します。
オリジナルの MPQS では a の条件として平方数であることを採用していたので、b を求める計算の簡単さから FB に含まれない (P0 より少し大きな) 素数 pi を使って
a=pi2(piN)=1
という条件で a の数を増やし、式の数を稼ぎます。
一方、この方式ではあまり式の数を増やすと b の計算や篩に使う x の初期値計算(式あたり FB のサイズだけ必要) が必要になるので、これらの計算コストが高い事がネックになります。それに対する対策が 自己初期化二次篩法 (SIQS; Self-Initializing QS) です。
SIQS では a を FB のいくつか(k 個とする)の素数の積として固定します。
a=pi∈FB∏pi
一方で b については式 (B1) から b2≡N(modpi) という関係が成り立つので、各 pi に対して b=±bi の 2 つの解が得られ、中国剰余定理で復旧した b には ∣b∣<a を考慮しても 2k−1 個のバリエーションを作れることになります。
このとき、a の計算に使っていた素数については a(ax2+2bx+c) の変形を考えて 1 ずつの指数が確定します。指数が 2 以上になるケースについては smooth だという判断をした後で具体的に求めることになります。
逆に a の計算に使っていない pi∈FB について x の初期値を計算するときには ri2≡N(modpi) として
x≡(−b±ri)a−1(modpi)
となります。ここで式によって変わるのは b だけなので ri や a−1 を保存しておくと計算が素早くなりますし、さらに 2ria−1 も保存しておけば一方の解 x0≡(−b−ri)a−1 からもう一方 x1≡(−b+ri)a−1=x0+2ria−1 を少ない計算量で求めることができます。


Discussion