こんにちは!株式会社ペライチ のサーバーサイドエンジニアの福原です!
突然ですがみなさん、ロックマン、欲しくないですか?(exe のやつですよ)
30 歳になった私も直撃世代でして、当時は自分にもネットナビが欲しいという思いからあらゆるものにプラグインとトランスミッションを試みるわんぱく小僧でした。
学生時代の研究室でも自然言語処理系に行ってみたりして、音声入力して反応を返してくれるプログラムを作ってみたりしていました。
ですが、しかしというかやはりというか、当時の自分の技術力では決まったセリフに対して決まった返事をするだけのモブキャラしか実現できませんでした。
しかし!
世はまさに大生成 AI 時代!
ChatGPT の登場によって今なら入力に対して無限の返答バリエーションが作れてしまう!
これはもう作るっきゃないでしょ!
実現したいこと
まずはネットナビを構成する要素を考えてみます。
- 1 人と 1 体でパートナー
- インターネットの世界に身体を持っている
- 基本的に自由意志があり、自発的に発言や行動をする
- 主人とは音声によるコミュニケーションをとる
- (ウィルスと戦う能力がある)
あたりでしょうか。
ウィルスとの戦闘能力はさすがに置いときましょう。
まとめると、音声でやりとりができて個性ある身体が用意できれば良さそうです。
構成要素
では何を使って前述の要素を実現していくかについて考えます。
インターネット世界に生まれて欲しいので基本的には Web 上で動作するようにします。
身体
まずは身体についてですが、今回は MMD を採用します。
※ MMD についてはこちら
3D モデルのフォーマットも種々ありますが、世の中にモデルが大量に存在することから、一人一人のパートナーという要素の実現容易性を下げてくれそうです。
また、Web 上で MMD を利用するためのライブラリも出てきているため、取り扱いも容易だと判断しました。
さらに、モデルだけではなくモーションデータも豊富なため、表現できる情報量も増えると考えました。
音声入出力
Web 上での音声入出力なので大人しくウェブ音声 API を頼ります。
出力については音声モデルが制限されてしまいますが、そこは今後の拡張性ということで。
意思
一番重要な意思の実現についてです。
今回は他社サービスですが、対話型 AI の Saas であるmiiboを利用させていただきます。
ノーコードで生成 AI との対話を実現してくれます。
裏側の生成 AI も選択肢が豊富ですが、今回は Gemini を選択します。
実装
めちゃめちゃざっくりとした概念図ですがこちらになります。

MMDをブラウザ上に描画
babylon.js を利用して MMD モデルとモーションを読み込んで再生します。
以下は初期状態を用意するコードです。
const scene = new BABYLON.Scene(engine);
// カメラ
const camera = new BABYLONMMD.MmdCamera("mmdCamera", new BABYLON.Vector3(0, 10, 5), scene);
// ライト
const hemisphericLight = new BABYLON.HemisphericLight("HemisphericLight", new BABYLON.Vector3(0, 10, -20), scene);
// モデル
const pmxModel = "MMD/models/rea/レアv1_12.pmd"
const mmdMesh = await BABYLON.SceneLoader.ImportMeshAsync(undefined, pmxModel, undefined, scene).then((result) => result.meshes[0]);
// モーション
const vmdLoader = new BABYLONMMD.VmdLoader(scene);
const modelMotion = await vmdLoader.loadAsync("model_motion", vmdModel);
const mmdRuntime = new BABYLONMMD.MmdRuntime();
mmdRuntime.register(scene);
const mmdModel = mmdRuntime.createMmdModel(mmdMesh);
mmdModel.addAnimation(modelMotion);
mmdModel.setAnimation("model_motion");
mmdRuntime.playAnimation();
音声入力を miibo に渡す
miibo 上ではノーコードですが、API を利用するために若干 JavaScript で実装します。
難しいことはなく、受け取った音声入力をテキストとして API の body として送ります。
やってみるとわかりますが、この状態だとすべての入力が送られてしまうので google home や alexa のウェイクワードの重要性を感じますね。
必要に応じて実装しましょう。
const recognition = new webkitSpeechRecognition();
recognition.lang = "ja";
recognition.continuous = false;
recognition.onresult = async ({ results }) => {
const response = await fetch('https://api-mebo.dev/api', {
method: 'post',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
"utterance": results[0][0].transcript,
"api_key": "xxxxxxxxxxxxxxxxxxx",
"agent_id": "xxxxxxxxxxxxxxxxxxx"
})
})
}
MMD へのフィードバック
miibo から返事が返ってきたら返事の内容に合わせて MMD のモーションを読み込みます。
楽しい内容であれば楽しんでいるモーションを、悲しい内容であれば悲しんでいるモーションを読み込むという形です。
これを実現するために、miibo 側で AI へのプロンプトに以下を追記します。
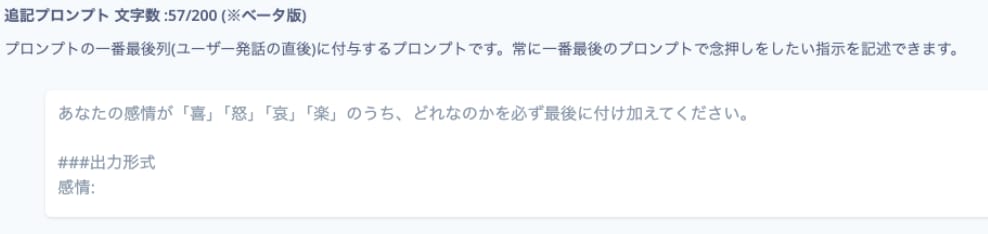
すると、返答に喜怒哀楽が付与されるのでこれを解析します。
const content = await response.json();
const emotionPattern = /感情:\s*.*/g;
let emotion = content.bestResponse.utterance.match(emotionPattern)
if (!!emotion) {
emotion = emotion[0].split(":")[1].trim()
} else {
emotion = content.userState["感情"]
}
const vmdNum = Math.floor(Math.random() * 2 + 1)
let vmdModel = ""
if (emotion === "喜") {
vmdModel = "MMD/motions/モーションデータ/喜ぶ" + vmdNum + ".vmd"
console.log("喜び" + vmdModel)
} else if (emotion === "怒") {
vmdModel = "MMD/motions/モーションデータ/すねる" + vmdNum + ".vmd"
console.log("怒り" + vmdModel)
} else if (emotion === "哀") {
vmdModel = "MMD/motions/モーションデータ/がっかり" + vmdNum + ".vmd"
console.log("哀しみ" + vmdModel)
} else if (emotion === "楽") {
vmdModel = "MMD/motions/モーションデータ/うなずく" + vmdNum + ".vmd"
console.log("楽しい" + vmdModel)
} else {
vmdModel = "MMD/motions/モーションデータ/考える" + vmdNum + ".vmd"
console.log("無" + vmdModel)
}
完成
これらを組み合わせることで音声とボディランゲージを持って受け答えをしてくれる自分だけのネットナビの骨格が完成です!
モデルを自作したり、音声を変えてみたり、ナビ側から自発的に発言してみたりと改良を加えてオンリーワンのネットナビにしてみてください!
採用情報
現在エンジニア募集しています!
▼ 採用ページ
▼ 選考をご希望の方はこちら(募集職種一覧)
▼ まずはカジュアル面談をご希望の方はこちら
募集中の職種についてご興味がある方は、お気軽にお申し込みください(CTO がお会いします)

Discussion