

こんにちは。株式会社ペライチ の佐藤と申します。
ペライチでは Sentry を使ったアプリケーション監視を始めました。
運用開始して、日は浅いですが、やっていることや、やってみた効果についてまとめます。
Sentryとは
Sentry とは、アプリケーションのパフォーマンスの監視やエラー追跡ができるサービスです。
実際に使ってみると、かなり細かくエラー発生時のログの状況や、回数をモニタリングできています。
導入も個別の SDK があるプラットフォームであれば、容易に導入できてあまり設定にハマるようなこともありませんでした。
(ものによるところはありますが、Rails 等はかなりよしなにやってくれます)
前提
今回運用開始する前に準備した内容は以下になります。
これらの具体的な設定方法は今回の記事の対象からは外します。
- アカウント管理
- メンバー個人のアカウントを発行しました。
- Sentry はアカウント数での課金はないので、個別に発行しました。
- タイムゾーン設定(デフォルト UTC です)
- メンバー個人のアカウントを発行しました。
- エラー通知
- エラー通知されるように設定(DSN の通知、アプリケーションへの設定)
- エラー発生した環境の通知(environment)
- デプロイ時にフロントのソースマップを Sentry へアップロードするように
- プロジェクトの整理
- リポジトリごとにプロジェクトを整理しました。
- 各担当チームが自分たちの対処すべきエラーを見落とさないように分けました。
- alert の設定から Slack 通知も可能なので Slack チャンネルも同様に分割しました。
- パフォーマンスモニタリング
- SDK が対応していればよしなにやってくれる
- CakePHP は対応しておらず、自作する必要がありました。
目指す姿
究極的に目指す姿はエラー通知 0 です。
エラーが 0 件だとこんな感じに気持ちの良い表示がされます。
現状
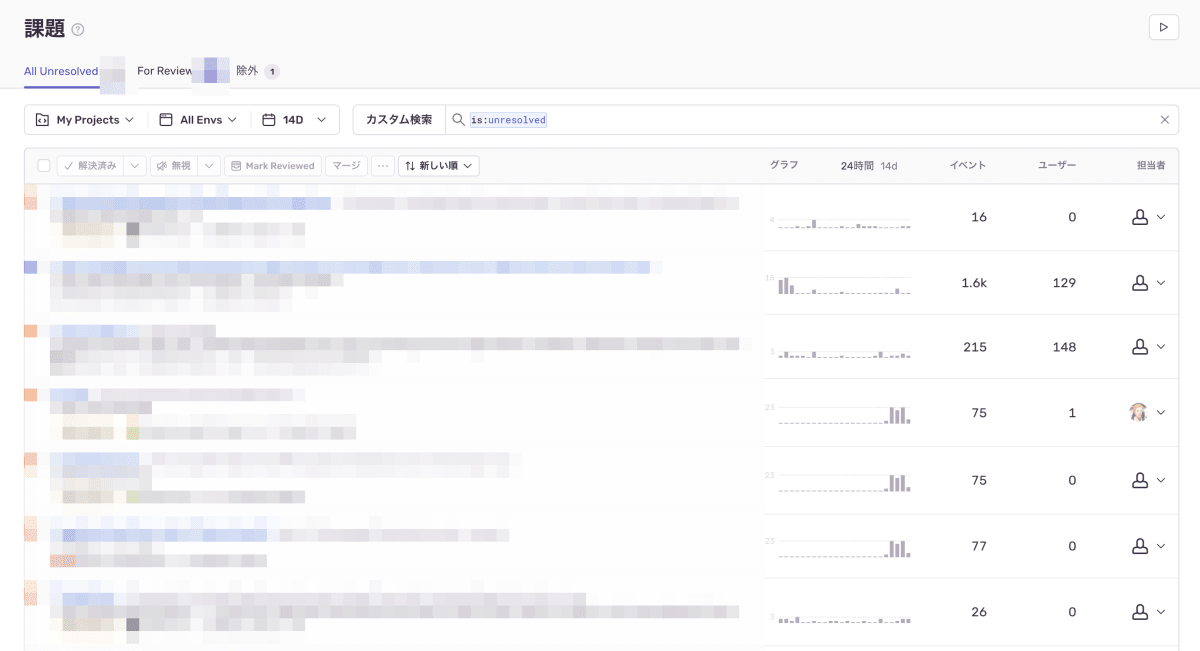
ですがすでに数年単位で稼働中のプロダクトに Sentry を導入すると大小合わせ多くのエラーが検知される状況でした...
このような状態からも着実に検知件数の減少、プロダクトの安定運用を目指して行くことにしました。
やったこと
-
検知件数が特段多い issue の集中対応
検知傾向を確認すると、正確に計測したわけではなかったのですが、パレートの法則的に 8 割の通知が 2 割のエラーにより引き起こされているような状況でした。
また、こういった検知はほとんど無害で対応しなくても特段問題ないようなエラーでした。(だからこそこれまで放置されてしまっていた。)
このようなエラーをオオカミ少年アラートと名付け、一ヵ月程度、新規開発を停止して一気に解消し検知量を 8 割程度低減しました。 -
Sentry 運用の本格開始
ある程度オオカミ少年アラートを低減できたので、Sentry の検知に信憑性を持ているようになってきました。
そこで各チームで日々の Sentry の運用を始めました。
具体的には以下の運用を開始しました。
1. リリース時運用
目的
- リリースしたもので意図しないエラーが出ていないかの確認
やること
- リリース後 Sentry の画面より新規に出てきたエラーや急増しているエラーがないかを確認する。
2. 日次運用
目的
- 即時で対応すべき課題(issue)の検知
- 日々の不具合急増の抑止(いつの間にか、エラーがたまってた。といったことが起きないように)
やること
-
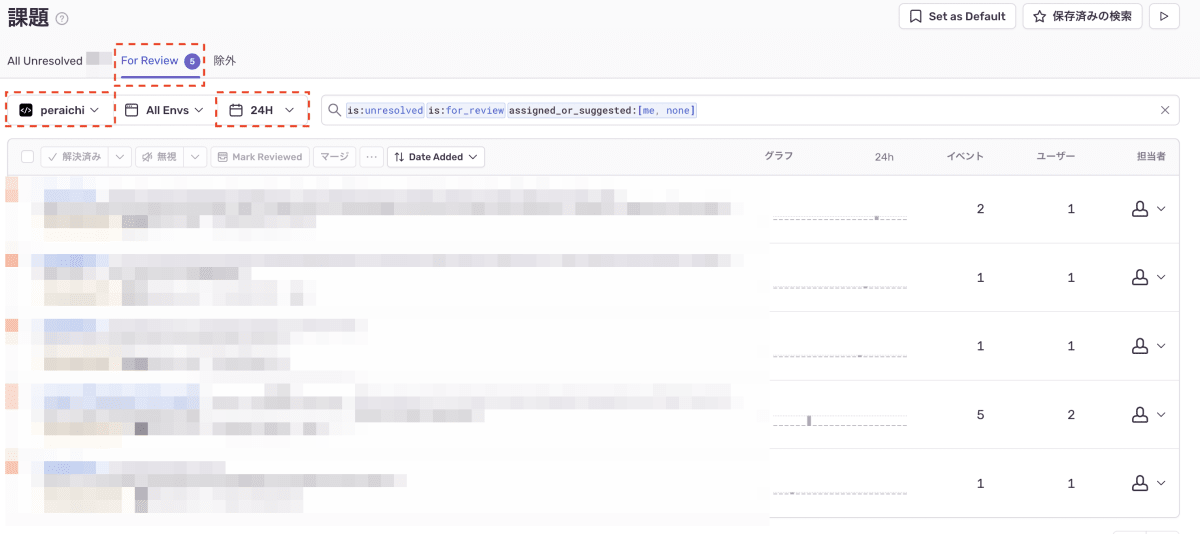
担当プロダクトの前日発生の For Review 案件の確認
- 即時で対応すべきエラーであるか確認→問題ある場合は即時調査対応
- 即時対応の必要がないが、次スプリントで対応したほうが良いかも検討して見繕っておく
- 前日発生分だけであれば各プロダクトでも数件程度ですので、デイリースクラムのついで等で確認できるレベルと想定。
- 即時で対応すべきエラーであるか確認→問題ある場合は即時調査対応
-
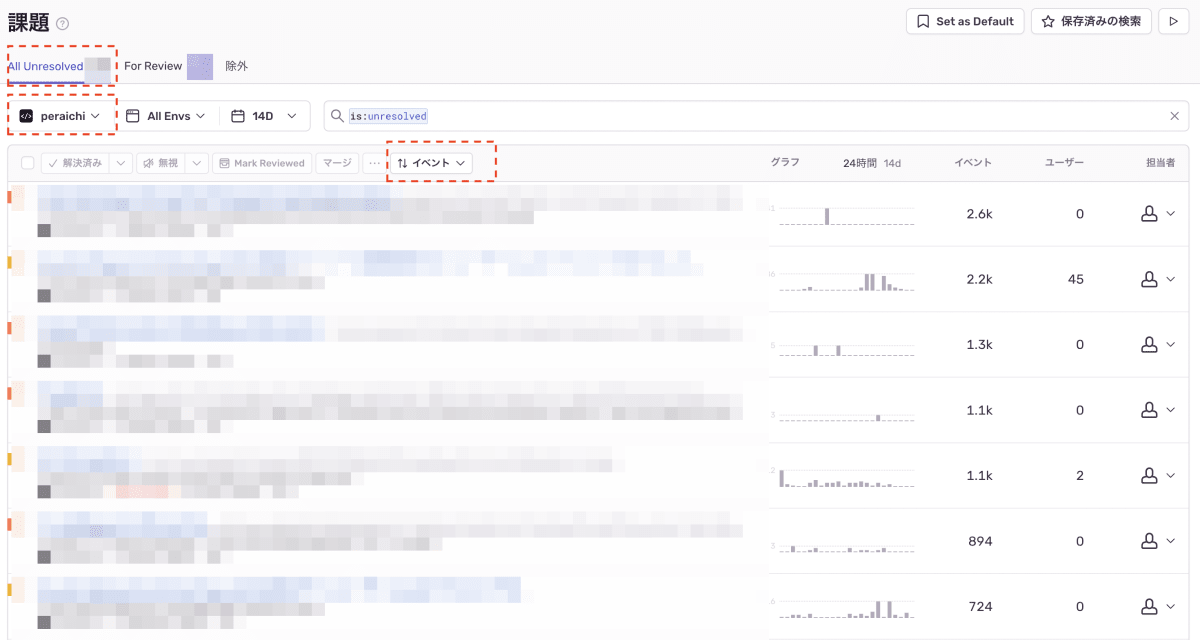
担当プロダクトの All Unresolved で件数が多い issue の確認
- 急増していないか?→問題ある場合は即時調査対応
- 次スプで対応したほうが良いかも検討して見繕っておく
- 次スプで対応したほうが良いかも検討して見繕っておく
- 急増していないか?→問題ある場合は即時調査対応
3. スプリントごとの運用
目的
- 即時対応はしなかったエラー対応の対応実施可否を判断して、担当者をアサインする
やること
- 日次の確認で見繕ったエラーについて次スプリントでの担当者をアサインする。
- 保守工数鑑みて適切な量をアサインする。
- 日々のスプリントで対応しても増加傾向になる場合、保守工数の見直し等を検討する。
結果
このような運用を開始してみて以下のような結果が出始めています。
- リリース直後のエラー検知スピードが上がった
- リリース時運用を実施することでリリース後の予期せぬエラーの検知スピードが上がり、早期に切り戻しするなど障害復旧スピードが向上しました。
- いままでだとリリース後にユーザーから問い合わせによって気付くエラーもありましたが、そのような検知がほぼ 0 になっています。
- 継続的な不具合解消を実施しやすくなった。
- 日次でのエラーチェックを実施することで、対応すべきエラーをチームでリアルタイムで把握できるように。
- スクラムイベントとも連動させることで実際に解消に向けたアサインまで行えるようになった。
ポイント
ここまでやってきた上でのポイントは以下だと思いました。
- 運用開始までは、エンジニアの自由研究的な活動ではなく、ひとつのプロジェクトとして開発ロードマップに入れて計画的に進める。
- 全社巻き込んでプロダクト開発をやめて不要なアラートの削除に取り組む時間を作れて一気に運用しやすい環境を作れました。
- 運用開始後、チームで Sentry を毎日見る。
- Sentry の活用を日々の運用に取り込むことで、ツール入れて終わりの対策にはなっていない。
- 不要なアラート削除など、運用に耐えられる状態まで、エラーの解消や整理を行えていた点もやりやすさに寄与していると思います。
- 毎日 Sentry を見ることでどれだけのエラーが起きているかチームで認識合わせられる。
- 一方で最初期はそれでも量が多くて見切れない。といったことはあると思うので、時間を区切って見れる範囲で見る。といった工夫も必要だと思います。
- (いきなり 0 を目指すのではなく、下降トレンドになっていれば長期的には 0 を目指していけるはずと考えています。)
- Sentry の活用を日々の運用に取り込むことで、ツール入れて終わりの対策にはなっていない。
一方で、残された課題として、
不具合解消にどれだけの時間をかけてよいかはまだ定量的に判断ができていません。
こちらについてはさらに、SLA,SLO のような指標を計測できるようにして定量的に、今は工数のうち何%不具合解消系のタスクを割り当てるべきか。といった判断ができるように集計のしくみを作っていく予定です。
採用情報
品質にもこだわって不具合を放置しないしくみづくり中です!少しでも興味持っていただいた方、現在エンジニア募集していますので以下よりご連絡いただければ幸いです!
▼ 採用ページ
▼ 選考をご希望の方はこちら(募集職種一覧)
▼ まずはカジュアル面談をご希望の方はこちら
募集中の職種についてご興味がある方は、お気軽にお申し込みください(CTO がお会いします)

Discussion