はじめに
GMOペパボ株式会社 技術部 技術基盤グループでソフトウェアエンジニアをやっているDrumatoです。
GMOペパボ株式会社のPublication 作成記念で記事を書いてみます。
普段は 個人ブログ に記事を書いているのですが、これからはペパボで扱っている技術のアウトプットをこちらにどんどん出していきたいと思っています。
今回は、nginxのngx_http_upstream_moduleにある least_conn について検証した結果をご紹介します。具体的には、 least_conn を指定する場合としない場合で、nginxの保持するコネクション数と、バックエンドの持つコネクション数がどのように増減するのかをPrometheus Metricに書き出して、可視化することでロードバランシングアルゴリズムを直感的に理解しよう、という趣旨です。
Least ConnectionやRound-Robin, その他ほとんどのロードバランサが提供するアルゴリズムの詳細な解説は本記事の対象外とします。
これ自体はとてもシンプルな動作検証だと思うのですが、
なぜこのような記事を出すのかについては、記事末尾の 経緯 セクションでお話します。
検証環境
今回利用するcompose.yamlやGoのコードはすべて以下に置いてあります。
https://github.com/Drumato/blog_samples/tree/main/nginx/least-conn
今回は、以下のような検証環境をDocker Composeで構築することにします。
バックエンドのアプリケーションはシンプルなHTTPサーバを立てることにします。詳細な実装は後述します。
動作検証するマシンの情報を以下に記載します。
$ uname -a
Linux alternatives 5.15.167.4-microsoft-standard-WSL2 #1 SMP Tue Nov 5 00:21:55 UTC 2024 x86_64 GNU/Linux
$ cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=22.04
DISTRIB_CODENAME=jammy
DISTRIB_DESCRIPTION="Ubuntu 22.04.5 LTS"
検証
round-robin
least_conn の挙動を検証する前に、デフォルトの挙動であるweighted round-robin についても調べてみます。weightパラメータは指定しなければデフォルトで1であるため、これはシンプルなラウンドロビンと変わらない挙動となるはずです。
以下のようなdocker-compose.yamlを用意します。
nginxとbackend, nginx-prometheus-exporterをそれぞれ3台ずつ用意します。
また、メトリクスを見るためにPrometheusサーバも導入します。
# docker-compose.yaml
services:
backend1:
hostname: backend1
build:
context: .
dockerfile: ./Dockerfile
ports:
- "9101:8080"
networks:
- appnet
backend2:
hostname: backend2
build:
context: .
dockerfile: ./Dockerfile
ports:
- "9102:8080"
networks:
- appnet
backend3:
hostname: backend3
build:
context: .
dockerfile: ./Dockerfile
ports:
- "9103:8080"
networks:
- appnet
nginx1:
image: nginx:latest
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
ports:
- "8081:80"
depends_on:
- backend1
- backend2
- backend3
networks:
- appnet
nginx2:
image: nginx:latest
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
ports:
- "8082:80"
depends_on:
- backend1
- backend2
- backend3
networks:
- appnet
nginx3:
image: nginx:latest
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
ports:
- "8083:80"
depends_on:
- backend1
- backend2
- backend3
networks:
- appnet
nginx_exporter1:
image: nginx/nginx-prometheus-exporter:latest
command: -nginx.scrape-uri="http://nginx1:80/stub_status"
ports:
- "9111:9113"
depends_on:
- nginx1
networks:
- appnet
nginx_exporter2:
image: nginx/nginx-prometheus-exporter:latest
command: -nginx.scrape-uri="http://nginx2:80/stub_status"
ports:
- "9112:9113"
depends_on:
- nginx2
networks:
- appnet
nginx_exporter3:
image: nginx/nginx-prometheus-exporter:latest
command: -nginx.scrape-uri="http://nginx3:80/stub_status"
ports:
- "9113:9113"
depends_on:
- nginx3
networks:
- appnet
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports:
- "9090:9090"
depends_on:
- backend1
- backend2
- backend3
- nginx_exporter1
- nginx_exporter2
- nginx_exporter3
networks:
- appnet
networks:
appnet:
それぞれのnginx.confは以下の設定を共有します。
今回は何もロードバランシングアルゴリズムを指定していないので、
デフォルトのweighted round-robinで動作します。
ngx_http_stub_status_module を有効化して、nginx-prometheus-exporterが情報収集できるようにします。
events {}
http {
upstream backend_app {
server backend1:8080;
server backend2:8080;
server backend3:8080;
}
server {
listen 80;
location / {
proxy_pass http://backend_app;
}
location /stub_status {
stub_status;
}
}
}
バックエンド側の実装を以下に載せます。
今回は、 backend1 コンテナのみ露骨にレスポンスが遅延するサーバ を作ってみました。
これはデモなので意図的に発生させていますが、
実際のWebアプリケーションでは 特定の重いクエリを実行するパスを通ってしまった場合や、ネットワークの輻輳によってレイテンシが悪化してしまうパターンなどなどが考えられます。
package main
import (
"context"
"fmt"
"log/slog"
"net"
"net/http"
"os"
"os/signal"
"strings"
"sync/atomic"
"time"
"github.com/labstack/echo/v4"
)
func main() {
ctx, stop := signal.NotifyContext(context.Background(), os.Interrupt)
defer stop()
logger := slog.New(slog.NewTextHandler(os.Stdout, nil))
slog.SetDefault(logger)
// Setup
e := echo.New()
listener, err := net.Listen("tcp", ":8080")
if err != nil {
logger.Error("Failed to create listener", slog.String("error", err.Error()))
return
}
e.Listener = &trackedListener{
Listener: listener,
totalConns: 0,
activeConns: 0,
}
e.GET("/metrics", func(c echo.Context) error {
l := c.Echo().Listener.(*trackedListener)
hostname, _ := os.Hostname()
return c.String(
http.StatusOK,
fmt.Sprintf(
"tcp_connections_active{host=\"%s\"} %d\ntcp_connections_total{host=\"%s\"} %d",
hostname, l.ActiveConnections(), hostname, l.TotalConnections()))
})
e.GET("/", func(c echo.Context) error {
l := c.Echo().Listener.(*trackedListener)
hostname, _ := os.Hostname()
if strings.Contains(hostname, "backend1") {
logger.InfoContext(ctx, "Simulating a long-running process")
time.Sleep(10 * time.Second)
return c.JSON(http.StatusOK, fmt.Sprintf("OK(%d)", l.ActiveConnections()))
}
return c.JSON(http.StatusOK, fmt.Sprintf("OK(%d)", l.ActiveConnections()))
})
// Start server
go func() {
if err := e.Start(":8080"); err != nil && err != http.ErrServerClosed {
panic(err)
}
}()
// Wait for interrupt signal to gracefully shut down the server with a timeout of 10 seconds.
<-ctx.Done()
ctx, cancel := context.WithTimeout(context.Background(), 20*time.Second)
defer cancel()
if err := e.Shutdown(ctx); err != nil {
panic(err)
}
}
type trackedListener struct {
net.Listener
totalConns int64
activeConns int64
}
func (l *trackedListener) Accept() (net.Conn, error) {
conn, err := l.Listener.Accept()
if err != nil {
return nil, err
}
atomic.AddInt64(&l.totalConns, 1)
atomic.AddInt64(&l.activeConns, 1)
return &trackedConn{
Conn: conn,
onClose: func() {
atomic.AddInt64(&l.activeConns, -1)
},
}, nil
}
func (l *trackedListener) ActiveConnections() int64 {
return atomic.LoadInt64(&l.activeConns)
}
func (l *trackedListener) TotalConnections() int64 {
return atomic.LoadInt64(&l.totalConns)
}
type trackedConn struct {
net.Conn
onClose func()
}
func (c *trackedConn) Close() error {
err := c.Conn.Close()
c.onClose()
return err
}
これに対し、以下のようなclientを実行して、nginxを経由してbackendにリクエストを大量送信します。
package main
import (
"context"
"fmt"
"log/slog"
"net/http"
"os"
"os/signal"
"sync"
"time"
)
var processedCount int64
var processedCountMu sync.Mutex
func main() {
ctx, stop := signal.NotifyContext(context.Background(), os.Interrupt)
defer stop()
logger := slog.New(slog.NewTextHandler(os.Stdout, nil))
slog.SetDefault(logger)
i := 0
wg := &sync.WaitGroup{}
ticker := time.NewTicker(1 * time.Second)
for {
select {
case <-ticker.C:
for {
if processedCountMu.TryLock() {
fmt.Println("Current processed count:", processedCount)
processedCount = 0
processedCountMu.Unlock()
break
}
}
case <-ctx.Done():
slog.Info("Received interrupt signal, shutting down")
wg.Wait()
return
default:
wg.Add(1)
go func(wg *sync.WaitGroup, count int) {
defer wg.Done()
var resp *http.Response
var err error
if count%3 == 0 {
resp, err = http.Get("http://localhost:8081")
} else if count%3 == 1 {
resp, err = http.Get("http://localhost:8082")
} else {
resp, err = http.Get("http://localhost:8083")
}
if err != nil {
slog.Error("failed to get", slog.String("url", fmt.Sprintf("http://localhost:808%d", count%3+1)), slog.String("error", err.Error()))
return
}
defer resp.Body.Close()
for {
if processedCountMu.TryLock() {
processedCount++
processedCountMu.Unlock()
break
}
}
}(wg, i)
time.Sleep(1 * time.Millisecond)
}
i++
}
}
数分間クライアントを走らせたあとにnginx_connection_active を見てみると、
3つのnginxが均等にコネクションを処理しているのが確認できました。
これは、クライアントがround-robinしてnginxにアクセスするので、想定通りです。

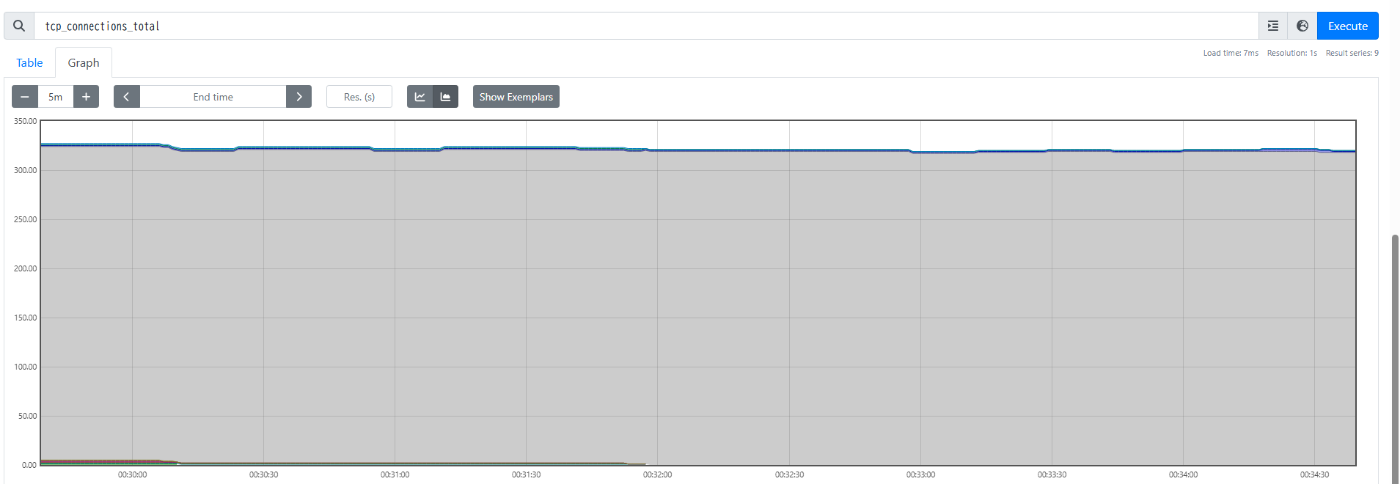
続いてアプリケーションが公開する tcp_connections_active を見てみると、 露骨にbackend1の値だけ大きく(下画像の灰色部分) 、ほかは1~2程度に抑えられているのが確認できました。
(すみません、スクリーンショット時点では tcp_connections_total となっていますが、これは上記サーバ実装における tcp_connections_active に置き換えてお読みください 🙇♀️ )
また、クライアント実行中に以下のようなエラーが出力されるタイミングがありました。
これは、backend1に対して(完全に均等に)リクエストが流れた結果、backend1が処理しきれずにこのようになったと推測できます。
time=2025-04-09T01:01:13.808+09:00 level=ERROR msg="failed to get" url=http://localhost:8082 error="Get \"http://localhost:8082\": EOF"
least_conn
続いて、nginx.confの設定を以下のように変更します。
events {}
http {
upstream backend_app {
+ least_conn;
server backend1:8080;
server backend2:8080;
server backend3:8080;
}
server {
listen 80;
location / {
proxy_pass http://backend_app;
}
location /stub_status {
stub_status;
}
}
}
この状態で同様に数分間クライアントを動かしてみたところ、 tcp_connections_activeのグラフは次のようになりました。
(こちらも同様に、スクリーンショット時点では tcp_connections_total となっていますが、これは上記サーバ実装における tcp_connections_active に置き換えてお読みください 🙇♀️ )

以下が tcp_connections_total であり、明らかにbackend1が処理しているリクエスト数が少ないことがわかります。
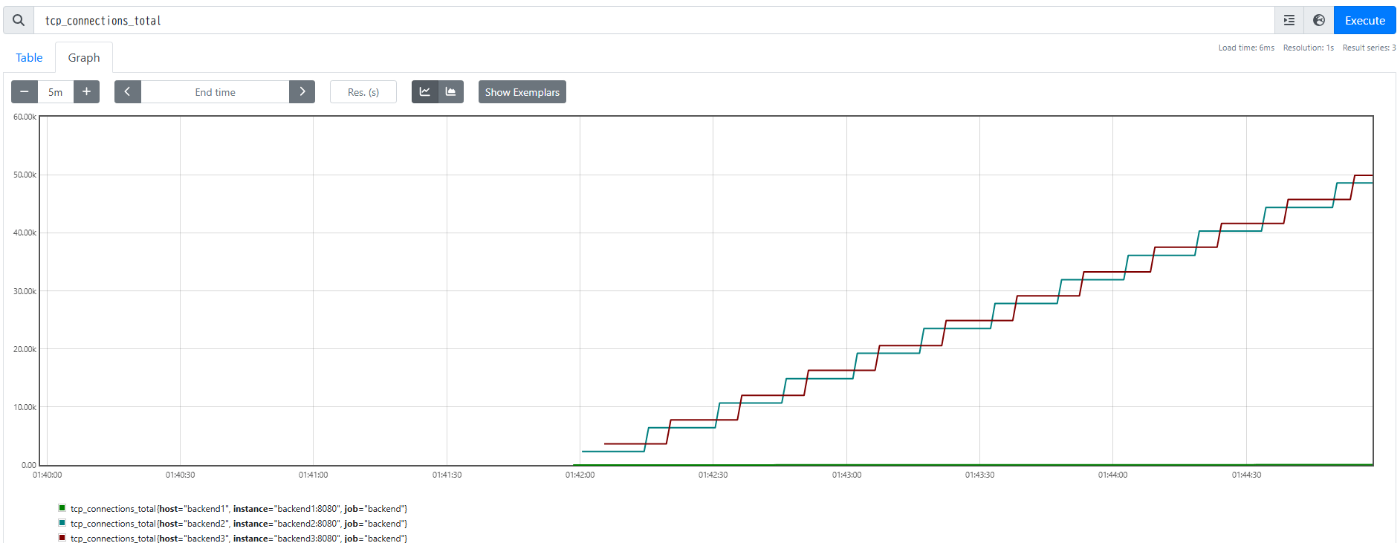
ここから、他バックエンドと比較してnginx - backend1間のTCPコネクション数が溜まりやすいのを前提に、backend1のsleepが経過するまで、nginxがbackend2および3へのロードバランシングを優先していることがわかります。backend2およびbackend3は高速にレスポンスを返すため、全体として保持されているTCPコネクションが著しく減少しています。
また、クライアントがエラーを出力することはなく、 安定して動いている ようでした。もちろん、クライアントが出力する「単位時間で処理できたリクエスト数」はweighted round-robin以上のものが確認できました。
このことから、 バックエンドに対する負荷分散( リクエスト分散ではない点に注意 )を実現するパラメータとして、TCP least connectionは有用なケースが有ることがわかりました。特に今回のように、一定以上の頻度で遅いパターンがあるような場合には有用だと改めて理解することができました。
実際には、各バックエンドサービスによってレスポンスが変わらない、複数台のバックエンドがステートを持たずに、同じリクエストに対して同じレスポンスを返すことが前提となりますが、 経緯 でお話する私たちのユースケースにうまくマッチした機能だと考えました。
まとめ
今回はnginxのロードバランシングアルゴリズムを改めて検証する、ということを行いました。
nginxはとてもとても多くの採用事例があり、インターネットにたくさんの情報があることから、生成AIを使うことで動きそうな設定を利用することが簡単にできる時代になりました。
そのような状態で、nginxの仕組みや挙動を正しく理解しながら運用するために、きちんと検証して自分の知識に落とし込む作業を続ける必要があるなあと感じている次第です。
経緯
ここでは余談として、なぜこのような検証をしたのかをお話します。
ペパボでは、NKEというKubernetesクラスタ基盤を利用してOpenStack VMをベースとするKubernetesクラスタを構築し、運用しています。
NKEについては、 こちらのスライドを見ていただければと思います。
最近、このNKEによって作成されたクラスタのうち、特に規模の大きく、Kubernetes APIをヘビーに使っているクラスタについて、 kube-apiserver間でCPU/メモリ使用率に大きなギャップがあり、時折OOMが発生している ことがわかりました。
調べてみると、kube-apiserver間でactiveなTCPコネクション数自体が大きく異なることが判明しました。
そこで私は、NKEに IPVS least connection を有効化する機能を実装しました。当該クラスタではKube-proxyのデータプレーンにIPVSを採用していたので、これでクラスタ内のPod間通信にLeast Connectionが適用され、負荷分散に寄与すると考えたのです。
しかし、実際には劇的な改善が得られませんでした。
というのも、kube-apiserverへの接続経路はServiceを経由したIn-clusterな通信だけでなく、master nodeに常駐するnginxから引き込むパターンがあったのです。
クラスタの各ノード(にいるKubelet等)はConsul DNS経由でmaster node上のnginxを解決し、そこに対して通信するようになっています。
この kubelet -> kube-apiserver なリクエストの分散が、IPVS least connectionでは行えていなかったのです。
ということで、master nodeに常駐するnginxに対して least_conn; を入れたところ、先述したapiserverのリソース使用量がある程度収束するように改善されたのでした。
今回のケースでは、クラスタの規模やコントロールプレーンへのリクエスト量の違いによって、特定のクラスタでのみ再現された問題でしたが、このnginxを用いたmaster nodes -> kube-apiserver processesな二段階のロードバランシング自体は、NKEで作成されたすべてのクラスタで採用されているため、一つの気づきで複数のクラスタの負荷改善を実現できたことになります。
私達ペパボのエンジニアは、このように 一石N鳥 をとても大事にしています。レバレッジの効いたエンジニアリングを実現し続けることで、事業成長のスピードを高く保ち、スケールし続けるサービスを実現することができると考えているからです。
技術基盤グループでは、事業横断な組織として、ペパボで運用しているKubernetesクラスタの基盤を開発・メンテナンスし、運用改善に取り組んでいます。Kubernetes以外にも、各サービスの信頼性向上のために活動しています。もしご興味のある方は、下記URLから採用サイトをご覧ください。

Discussion