AWS Summit Japan 2025 の個人的レポート
AWS Summit Japan 2025
AWS Community Builderのぺんぎん(@jitepengin)です。
先日開催されましたAWS Summit Japan 2025に参加してきました。本記事では印象に残ったセッションを中心にまとめたいと思います。
ちなみにCommunity Builderのデータ区分かつ仕事でもデータ基盤を扱うことが多いため、データ関連のセッションが中心になっています。
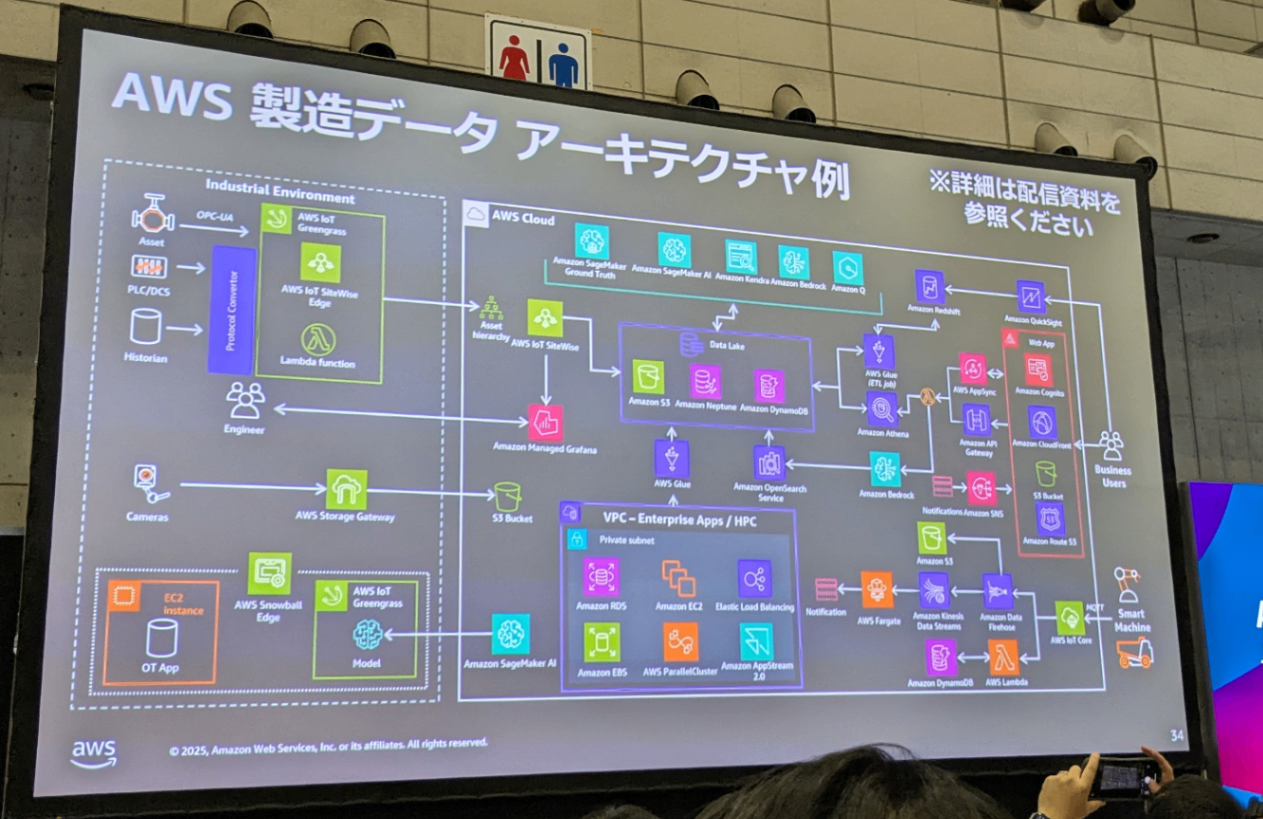
AWS-32 データによる製造業デジタル変革の実践
製造業におけるデータ活用の壁は、「作成」「取得」「利用」の 3 つの段階で生じています。具体的には、設計時の CAD データや手順書などの作成段階、製造ラインのセンサー情報や市場の製品からの取得段階、そして分析・予測への利用段階です。これら各段階で発生する課題が、スピードや活用の範囲、生み出される価値を損なっています。本セッションでは、設計から保守までの製品ライフサイクル全体を通じて、断片化したデータを有機的につなぎ、実践的な価値を引き出すアプローチをご紹介します。HPC を活用した設計データ開発の加速、IoT を活用したデータの取得、AI アシスタント実装による改善など、業務改革に実践可能な方法論をお伝えします。
ざっくりとした感想
弊社でも製造業のクライアントを多く担当しており、本セッションで紹介されたようなデータの取り扱いは非常によく直面するテーマです。
IoTデバイスからのデータ収集方法、AWSの関連サービスの使い分け、エッジとクラウドの適切な配置など実務に直結する多くの学びがありました。
そして、初期構築時のスコープ設定は悩ましい論点です。
スコープを広げすぎると費用対効果が不明確になり、「使われないシステム」になるリスクもあります。
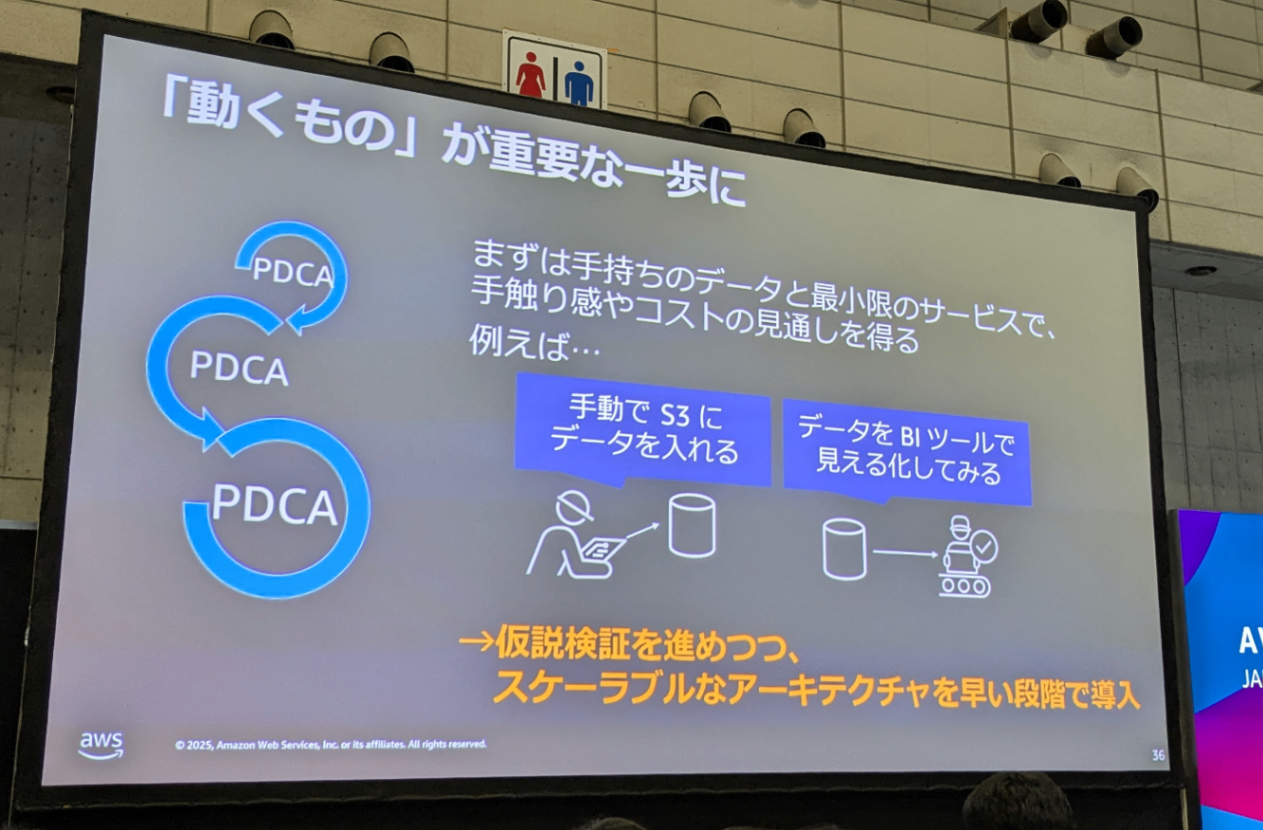
そういった場合には、本セッションでも強調されていたように、まずは 「「動くもの」が重要な一歩 になります。
いわゆるPoCフェーズを設け、ミニマムな構成でデータ基盤を構築・活用することで、実際の操作感を確認しつつ、関係者からのフィードバックを得て本格導入に繋げるアプローチが有効だと再認識しました。

AA-03 企業内に分散したデータの分析と AI 活用を推進する:AWS で実現するデータ活用の民主化
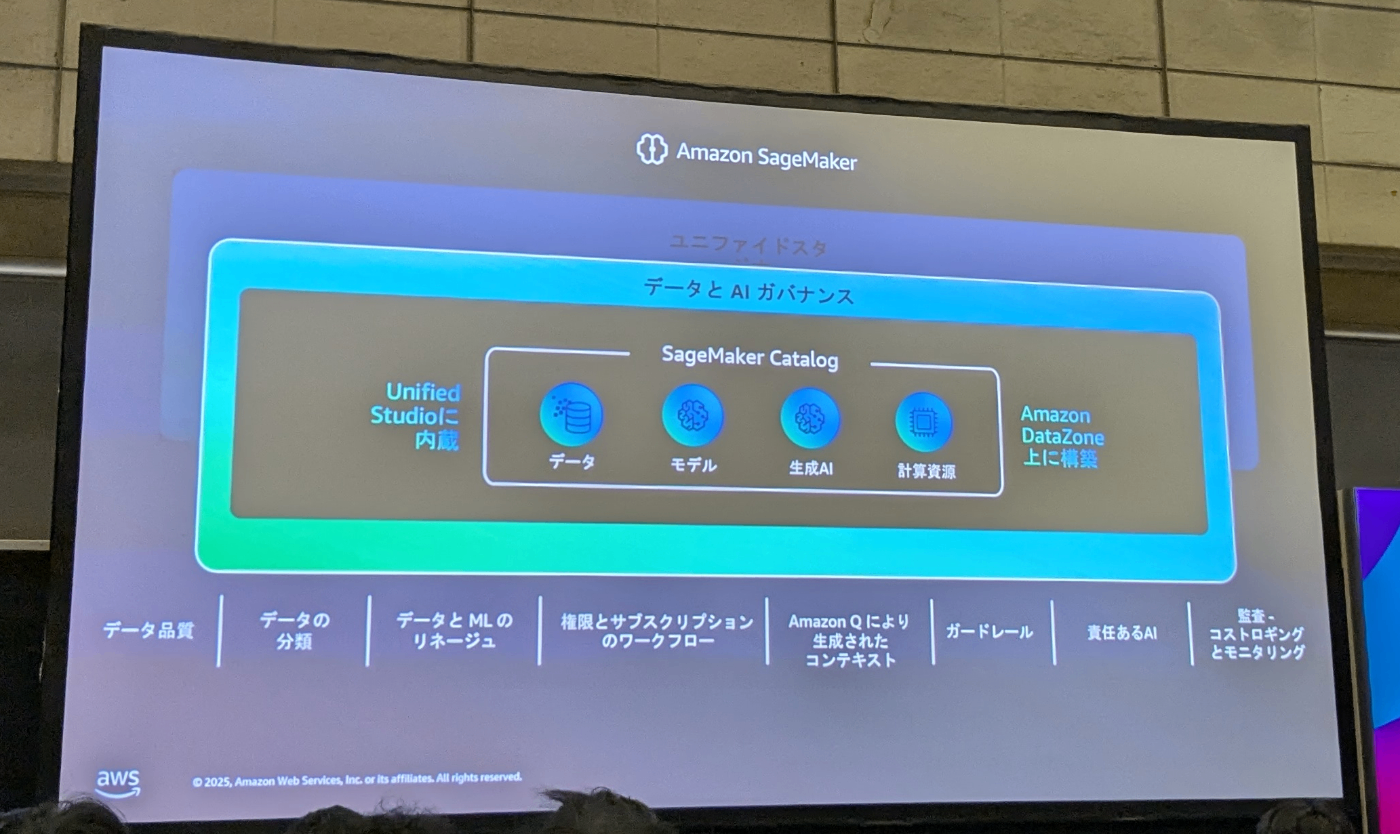
AI 技術の普及により分析(アナリティクス)と AI の境界がなくなりつつあり、両技術またがった活用が企業成長の鍵になっています。一方で企業内には多くのシステムが組織ごとに構築されており、データの分断(サイロ化)、運用負担の増加が課題になっています。これらの課題に対応するため、AWS では 次世代の Amazon SageMaker をリリースしました。これは企業内に散らばったデータを統合的に管理できる仕組みと、統合された分析 & AI 環境を用意することで、データサイエンティスト、アナリスト、基盤エンジニアがシームレスに協働できる環境を提供するものです。本講演では、今後の AWS AI & アナリティクスサービスの中心である 次世代の Amazon SageMaker がこれらの課題にどのように対応し、解決するかをご説明します。
ざっくりとした感想
他のセッションでも多く取り上げられていた次世代のAmazon SageMaker に関する話題が中心でした。
従来であれば、Redshift、Lake Formation、DataZoneなど複数のサービスを組み合わせて構築する必要がありましたが、Amazon SageMakerのUnified Studioを活用することで、より簡単に統合的なデータ基盤を構築できるとのことです。
この次世代SageMakerの中核を担うのが、Apache Icebergとデータレイクハウスアーキテクチャです。Apache IcebergはOTFのデファクトスタンダードとして急速に普及しており、DatabricksやSnowflakeも対応を発表したことは記憶に新しいですね。
実際のプロジェクトでも、Icebergを採用するケースが増えてきたと感じています。
私自身、これまでのSageMakerは「機械学習モデルの開発・学習」の側面でしか触れていなかったため、この機会に早めにキャッチアップしたいと感じました。
今回の内容を見る限り、次世代のSageMakerをベースに据え、必要に応じて他サービスを補完的に組み合わせる構成がよさそうです。
また、Icebergベースであることにより、他のツールとも高い互換性が期待できるため、柔軟性・汎用性の高いアーキテクチャとして今後ますます注目が集まるのかなと思います。



AWS-04 Amazon S3 によるデータレイク構築と最適化
データレイクの構築において、Amazon S3 の特性を理解することは欠かせません。Amazon S3 にデータを収集できても、その先の効果的な運用管理に課題を感じている方も多いのではないでしょうか?本セッションでは、架空の E コマース企業を例として、データレイクの構築から効果的な運用に至るまでのロードマップを具体的に示します。データレイクの構築要素の中心となる Amazon S3 の特性を踏まえ、セキュリティとガバナンス、クエリパフォーマンス改善やデータ品質管理を容易にするために有効活用できるサービスと方法について学ぶことができます。
ざっくりとした感想
S3でデータレイクを構築する際の課題や考慮事項について、架空の企業を例に取りながら、非常にわかりやすく解説されたセッションでした。
直近のプロジェクトでも同様の構成を検討していたこともあり、実務に直結する知見が多く、非常に参考になりました。
特に印象に残ったのは、パフォーマンス改善のためのアプローチです。
パーティション設計やプレフィックスの設計など、S3を効率的に活用する上で欠かせない要素ですが、これらは事前に理解していないと設計段階で見落としがちです。
プロジェクトメンバー全体で同じ認識を持つことが重要だと感じたため、このセッションで得た内容は、ぜひチーム内でも共有したいと思います。


AWS-47 オープンテーブルフォーマットで実現する、大規模データ分析基盤の構築と運用
機械学習や生成 AI の急速な発展により、企業のデータ基盤には、より高い拡張性と堅牢性が求められています。本セッションでは、AWS の分析サービスとオープンテーブルフォーマット (OTF) を活用し、この要件に応える大規模トランザクショナルデータレイクの構築方法をご紹介します。高いパフォーマンス、コスト最適化、運用の優秀性を実現するための具体的な実装方法と、大規模テーブル運用のベストプラクティスを解説します。さらに、ストリーミングデータにおけるスキーマ進化の課題に対し、OTF を活用することで高い信頼性とシームレスな運用を実現する手法もご紹介します。データ基盤の近代化に取り組むデータエンジニアの方々に、実践的な知見をお届けします。
ざっくりとした感想
今回のAWS Summitで、個人的に最も楽しみにしていたセッションでした。
従来のデータレイクが抱える課題と、それを解決する手段として注目されているオープンテーブルフォーマット(OTF)であるApache Icebergにフォーカスし、その仕組みや特徴が非常にわかりやすく解説されていました。
私自身も以前からApache Icebergに注目し、情報収集や学習を進めていたこともあり、本セッションはこれまでの理解を整理する良い機会となりました。現地で直接聴講する価値が十分にあったと感じています。
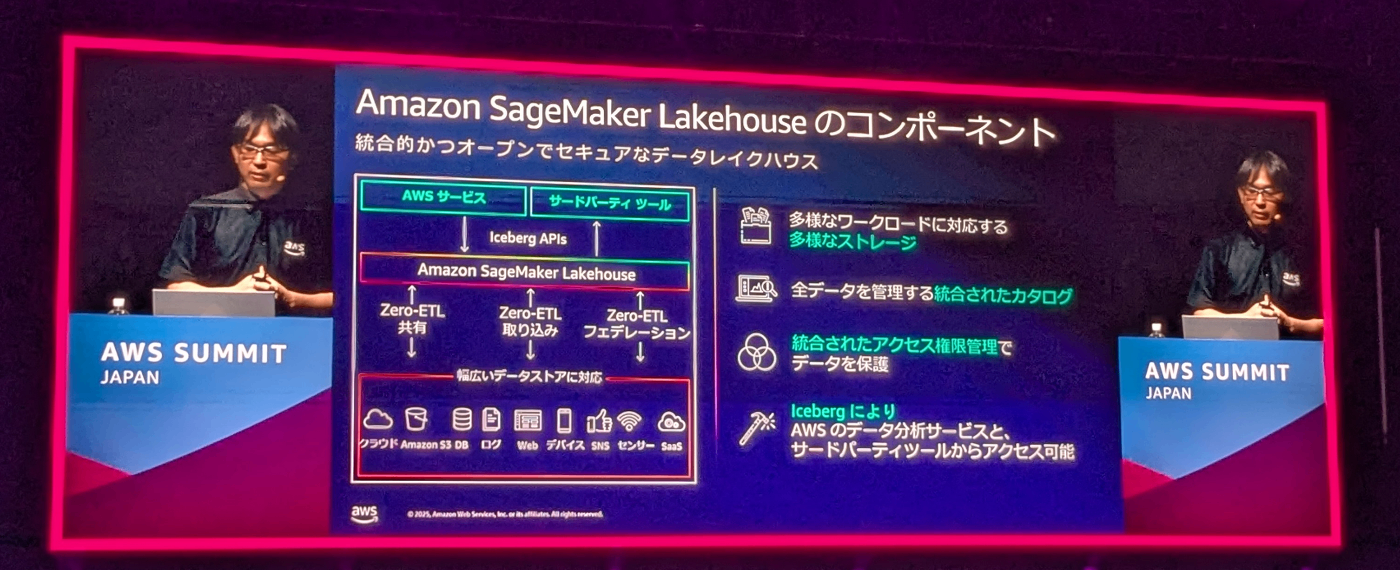
また、SageMaker Lakehouseの構成要素についての説明もあり、特にプレビュー中ながらRDSのCDCへの対応は、実運用を想定した際に非常に便利だと感じました。
AWSは以前からIceberg に注力してきた印象がありましたが、今回のSageMaker Lakehouseの登場によって、AWS上でデータ基盤を構築するならIcebergが第一選択肢になると改めて実感しました。



AWS-48 AWS 上で Apache Iceberg レイクハウスを構築・運用するためのベストプラクティス
近年、クラウドにレイクハウスを構築して多様なツールが利用可能な分析環境を構築したいというニーズが増えており、そのデータ保存方法として Apache Iceberg が注目されています。一方で、多くの企業ではオンプレミスのデータベースや、AWS 上の Amazon RDS や Amazon Aurora などのさまざまなデータストアにデータが蓄積されており、Iceberg やレイクハウスの導入に障壁を感じている方も多くいらっしゃいます。本セッションでは、データのサイロ化を解消しデータからのビジネス価値を最大限に引き出すコンセプトとして、レイクハウスをご紹介します。主にデータ基盤を構築・運用する技術者向けに、様々なデータストアからデータを収集し Iceberg と Amazon SageMaker Lakehouse を用いたレイクハウスを AWS 上に構築・運用するための方法をご紹介します。また、AWS で Iceberg を利用する際の検討ポイントを整理し、円滑な移行を実現するための体系的なアプローチをご説明します。
ざっくりとした感想
このセッションも非常に学びの多い内容でした。
Apache Icebergを用いたレイクハウス構築における課題やアプローチ、さらには移行に関する実践的な解決策まで幅広く解説されており、とても参考になりました。
特に印象的だったのが 移行に関する具体的な話で、戦略立案から移行方法の選定、スケジュール設計の考え方まで、実際に移行プロジェクトを計画・実行する際に役立つ情報が多く含まれていました。
セッションを聴きながら、「実際に移行を進めると、こうした課題に直面するよなー」と自分の経験とも重ねて考えることができ、理解が深まりました。
特に経験の浅いメンバーは、移行の難しさや落とし穴を見落としがちなため、今回のセッション内容をベースに、チーム内で認識を合わせるための資料としても活用したいと思います。



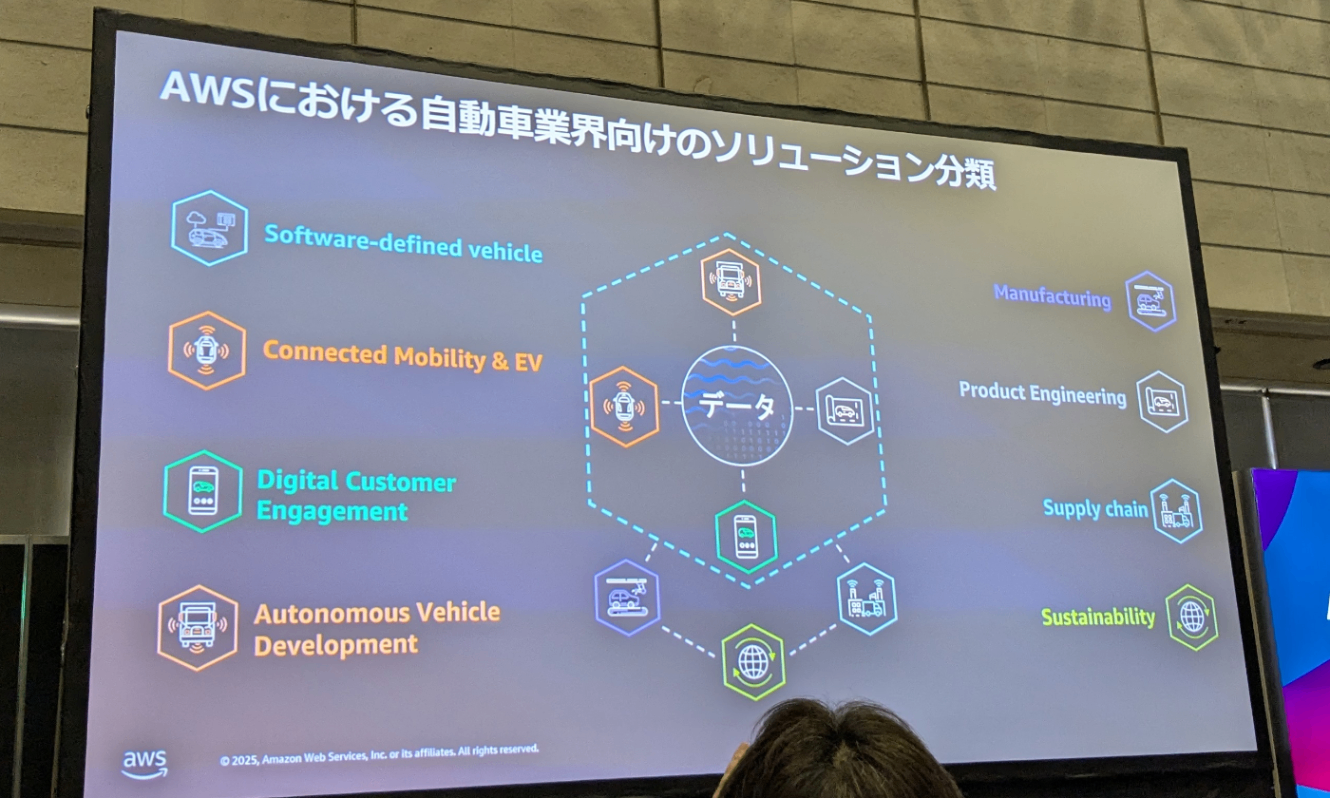
AWS-66 データメッシュで実現する 自動運転・ SDV におけるデータ駆動型開発
このセッションでは、複数の自動車メーカー (OEM) 様で実証実験中である、データメッシュコンセプトに基づく自動車 IoT データ利活用サービスについて解説します。従来の Connected Vehicle ソリューションでは、各部門が個別かつ独自にデータを収集・活用することが多く、複数部門のデータを組み合わせた新サービスの創出が課題がありました。この課題に対応するため、複数のデータ取得・提供部門とデータ群の活用部門をメッシュ状に連携させ、データカタログを通じて、データ活用部門は複数のデータ提供部門から必要なデータのみを選択しサービスを構築できるプラットフォームを AWS は実現しました。このセッションを通じて、部門の壁を超えたデータ連携の実現方法、データカタログの効果的な運用手法、そして組織横断的なデータ活用がもたらす新たなビジネスチャンスについて学ぶことができます。自動車業界のデジタルトランスフォーメーションに関わる方々にとって、実践的な知見を得られる貴重な機会です。
ざっくりとした感想
一時期、データメッシュ過激派(?)のようになっていた時期もあり、今回のセッションは個人的にも非常に楽しみにしていました。
データメッシュは「アーキテクチャ」というより概念や哲学に近い側面があり、実現方法にも多様なアプローチが存在します。
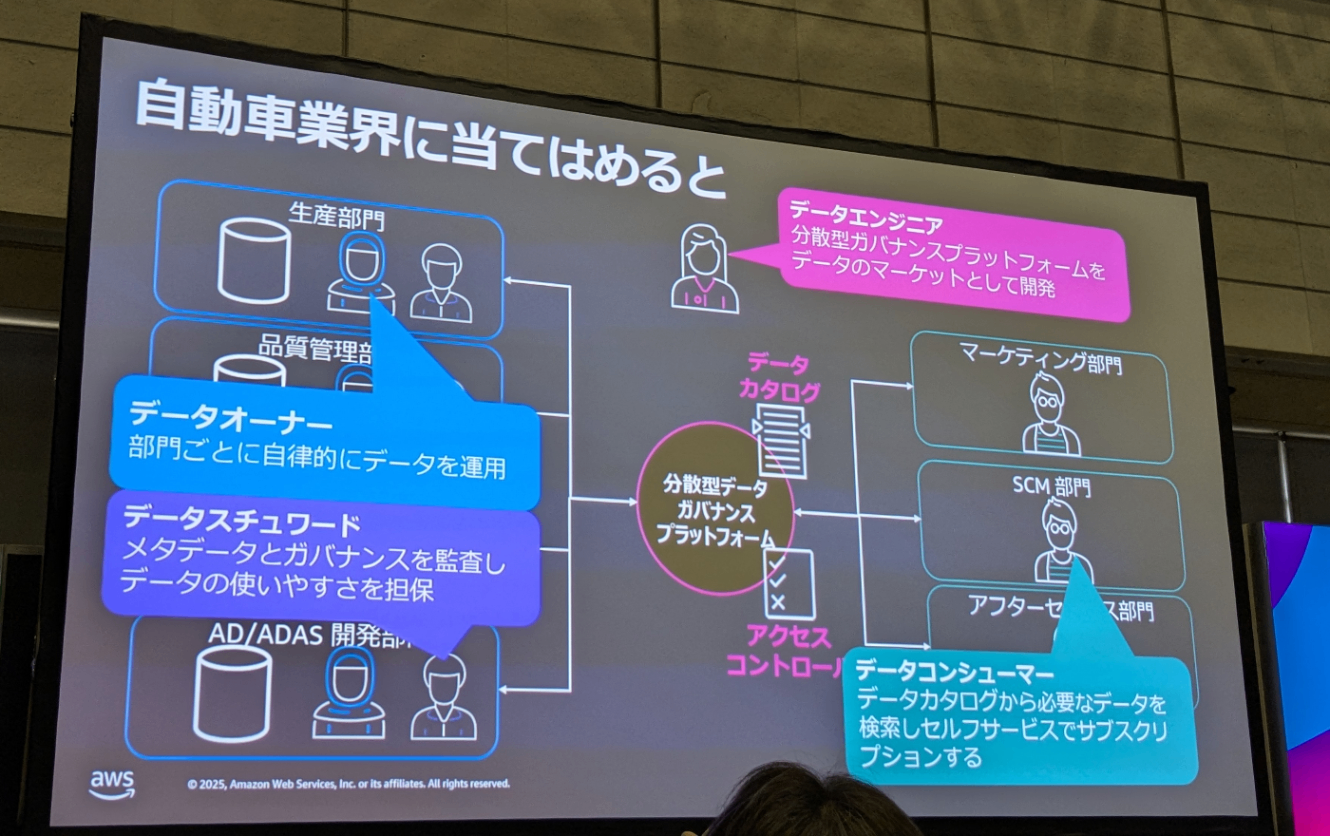
今回のセッションでは、特にドメイン別オーナーシップや横断的なガバナンスに焦点が当てられていた印象でした。
各ドメインが自律的にデータプロダクトを作成し、それらを横断的なガバナンスのもとで管理・流通させる仕組みが紹介されていました。
データの利用においては、コンシューマ側がプロデューサに対して利用申請・承認を得るようなフローも設計されており、現実的な運用を想定した構成になっていました。
このような承認フローを含む仕組みを構築するには、これまではDataZoneなどが選択肢となっていましたが、次世代のSageMakerを活用することで、より簡便かつ柔軟に実現できるとのことです。
データメッシュはその理念や理想論が先行して語られることも多いですが、現実には多くの課題もあり、適用には慎重な設計が求められます。
とはいえ、個々の要素は非常に強力です。そのため、「全部入り」の厳格なデータメッシュではなく、次世代SageMakerのような仕組みをベースに、良い部分だけを柔軟に取り入れた「ふわっとしたデータメッシュ」構成が、現実解として有効ではないかと改めて感じました。
過去データメッシュについて書いた記事はこちら


AWS表彰
2025 Japan All AWS Certifications Engineers に選出されました!
残念ながらAWS Top Engineerの方は落選となりましたが、育休中で実績が出しきれなかった状況を踏まえると、「今ではなく、来年しっかり狙うべき」という結果として納得しています。
むしろ、今の状態で選ばれていたら重みが薄れていたかもしれませんし、今回の結果は自分にとっても良い区切りだったと前向きに捉えています。
来年のリベンジに向けて、引き続き業務とアウトプットの両輪で着実に取り組んでいきます!


全体感想
全体を通して、AI関連のセッションが非常に多かったという印象を受けました。
私自身も日々の業務でAIを活用する機会が増えており、さまざまなユースケースを学ぶことができて、非常に有意義な時間となりました。
中でも印象的だったのが、データ基盤がAI活用の前提条件として強く意識されていた点です。
特にAmazon SageMakerを中心としたサービス紹介が多く取り上げられており、AI活用に向けた土台としてのデータ基盤の重要性が改めて強調されていたと感じました。
この構成を取り入れることで、データガバナンスの強化、セキュリティの確保、サイロ化の解消など、複数の課題を同時に解決できる可能性が示されており、非常に現実的かつ価値のあるアプローチだと感じました。
また、私自身が注目しているApache Icebergやレイクハウスアーキテクチャについても、多くのセッションで言及されており、これまで自分が追いかけてきた方向性が間違っていなかったと確信できました。
従来のデータレイクから Iceberg への移行や、組織文化の変革といったテーマも含め、データ基盤という切り口だけでも非常に多くの学びがあり、今後のプロジェクトを推進する上での大きなヒントになりました。
今回のAWS Summitを通して、AWSがAIおよびデータ基盤分野において、どれほど包括的かつ先進的な取り組みを行っているかを実感することができました。
この学びをしっかりと本業に活かしつつ、AWS Community Builder(データ部門)としても積極的にアウトプットを続けていきたいと思います。
その他
-
競合他社のブースを偵察するのも楽しかった。
-
元同僚がAWS Top Engineerに選ばれていてうれしかったのと、直接お祝いを伝えられてよかった!
-
微妙に寒いエリアがあってGolden Jacketを羽織るか葛藤する場面があった。
-
AWSのユーザグループに参加してみたい

-
お弁当食べる場所がない…

-
東京行くとシウマイ弁当を食べがち

Discussion