AWS Lambda×DuckDB×PyIcebergで実現する動的ルーティング軽量ETLの実装
はじめに
AWS Community Builderのぺんぎん(@jitepengin)です。
近年のデータパイプラインでは、複数のソースからデータを集約してデータレイクに取り込むケースが増えています。
しかし、ソースごとに処理内容や書き込み先テーブルが異なる場合、従来のETLでは柔軟性が低く、メンテナンスコストも増大します。
以前、紹介したようなAWS Lambdaを活用した軽量ETLでも同様にソースや書き込み先ごとに関数を作成する必要があり、ランタイムや参照ライブラリのバージョンアップ対応を行う場合に、各関数ごとに対応が必要となります。
今回の記事では上記の課題を解決する動的ルーティングETLの構築方法を紹介します。
ルーティング情報はDynamoDBに格納し、Lambdaが自動で処理対象のテーブルやSQLの切り替えを行います。
動的ルーティングを考えてみる
従来のETLでは、入力ソースごとにターゲットテーブルやSQLをハードコーディングすることが多く、ソースが増えるたびにコードを変更する必要があります。
動的ルーティングを導入することで、Lambdaは以下を自動で判断できる想定です。
- 書き込み先のIcebergテーブルの切り替え。
- ソースごとに異なるSQLによる抽出・加工の切り替え。
これにより、コードの変更なしに新しいソースにも対応可能となります。
今回のアーキテクチャ
バケットベースのルーティング

こちらはInputのバケット名をベースにルーティングする方式です。
様々なデータソースからデータが集まる場合に便利です。
フォルダベースのルーティング

こちらはInputのフォルダパスをベースにルーティングする方式です。
同じシステムから連携されるデータで、元テーブルが違う場合などに使うと便利です。
処理イメージ
今回のパイプラインの流れは以下となります。
- S3にファイルがPUTされるとLambdaがトリガ実行される。
- LambdaがS3パスをもとにルーティングキーを抽出する(バケット名またはフォルダ名)。
- DynamoDBから対象テーブルとSQLを取得する。
- DuckDBでParquetファイルを読み込み、SQLを実行する。
- 結果をPyIcebergでIcebergテーブルに追記する。
ポイントはLambdaで使用する各種ライブラリとなります。
- DuckDB:データベースエンジンとして、メモリ内での高速なSQLクエリ処理を実現。
- PyArrow:Arrowフォーマットを使用し、高速なデータの変換・転送をサポート。
- PyIceberg:AWS Glue Catalogを活用して、Iceberg形式のテーブルにアクセス・操作。
DuckDBとは
DuckDBとは、組み込み型のOLAP(オンライン分析処理)向けデータベースエンジンです。
DuckDBは非常に軽量で、インメモリ処理が可能となるためLambdaのようなシンプルな環境でも効率的に動作させることができます。
特にデータ分析やETL処理のようなバッチ処理において強力なパフォーマンスを発揮すると言われています。
PyArrowとは
PyArrowとは、Apache ArrowプロジェクトのPythonバインディングで、メモリ内データの効率的な操作と転送を可能にするライブラリです。
Apache Arrowは、データ解析や分散コンピューティングに特化した高速なカラムナメモリフォーマットを提供します。
PyArrowは、このArrowフォーマットをPythonで利用するためのAPIを提供し、さまざまなデータ操作やデータ間のやり取りを効率的に行うことが可能です。
PyIcebergとは
PyIcebergとは、Apache IcebergのPythonライブラリで、大規模データセットのテーブル管理を容易にするライブラリです。
Apache Icebergは、クラウドネイティブのデータレイクを効率的に扱うために設計されたオープンソースのテーブルフォーマットであり、PyIcebergはそのPython実装を提供します。
PyIcebergを使用することで、Python環境でIcebergテーブルにアクセスし、高度なデータ操作が可能となります。
サンプルコード
Lambda
バケットベース処理とフォルダベース処理はrouting_key取得処理を変更することで切り替え可能です。
また、append_to_icebergにて競合発生時のリトライ処理を追加しています。
import os
import boto3
import duckdb
import time
from pyiceberg.catalog.glue import GlueCatalog
# DynamoDB table storing routing information
ROUTING_TABLE = os.environ.get("ROUTING_TABLE", "routing_table")
# Iceberg catalog configuration
ICEBERG_CATALOG_NAME = os.environ.get('ICEBERG_CATALOG_NAME', 'my_catalog')
APP_REGION = os.environ.get('APP_REGION', 'ap-northeast-1')
# AWS clients
dynamodb_resource = boto3.resource('dynamodb', region_name=APP_REGION)
table = dynamodb_resource.Table(ROUTING_TABLE)
def lambda_handler(event, context):
try:
# 1. Extract S3 event information
s3_bucket = event['Records'][0]['s3']['bucket']['name']
s3_object_key = event['Records'][0]['s3']['object']['key']
s3_input_path = f"s3://{s3_bucket}/{s3_object_key}"
print(f"s3_input_path: {s3_input_path}")
# Set routing key based on S3 structure
# - If using bucket-level routing, use the bucket name:
routing_key = s3_bucket
# - If using path-level routing, extract from the object key:
# routing_key = s3_object_key.split('/')[0]
# ※When using path-level routing, adjust the index according to your S3 path structure.
# 2. Fetch routing config from DynamoDB
print(f"APP_REGION: {APP_REGION}")
print(f"table: {table}")
print(f"PartitionKey: {routing_key}")
response = table.get_item(Key={'PartitionKey': routing_key})
if 'Item' not in response:
raise Exception(f"No routing information found in DynamoDB for key: {routing_key}")
config = response['Item']
target_table = config['target_table']
query_sql = config['query_sql'].format(s3_input_path=s3_input_path)
print(f"Routing decision: {routing_key} -> {target_table}")
print(f"Executing SQL: {query_sql}")
# 3. Load and process data with DuckDB
con = duckdb.connect(database=':memory:')
con.execute("SET home_directory='/tmp'")
con.execute("INSTALL httpfs;")
con.execute("LOAD httpfs;")
arrow_table = con.execute(query_sql).fetch_arrow_table()
print(f"Fetched rows: {arrow_table.num_rows}")
print(f"Schema: {arrow_table.schema}")
# 4. Append to Iceberg with retry logic
append_to_iceberg(arrow_table, target_table)
return {"status": "success", "rows": arrow_table.num_rows}
except Exception as e:
print(f"Error occurred: {e}")
raise
def append_to_iceberg(arrow_table, target_table, retries=5):
catalog = GlueCatalog(region_name=APP_REGION, name=ICEBERG_CATALOG_NAME)
delay = 10
for attempt in range(retries):
try:
table = catalog.load_table(target_table)
table.refresh()
current_snapshot = table.current_snapshot()
snapshot_id = current_snapshot.snapshot_id if current_snapshot else "None"
print(f"Attempt {attempt + 1}: Using snapshot ID {snapshot_id}")
table.append(arrow_table)
print(f"Data successfully appended to Iceberg table {target_table}.")
return
except Exception as e:
print(f"Attempt {attempt + 1} failed: {e}")
if "Cannot commit" in str(e) or "branch main has changed" in str(e):
if attempt < retries - 1:
delay *= 2
print(f"Retrying in {delay} seconds...")
time.sleep(delay)
else:
print("Reached max retries. Aborting.")
raise
else:
raise
過去の記事でも言及していますが、Icebergテーブルのバージョン更新や競合によるエラー対応のための間隔をちょっと長めにしているのでここは要調整かなと。(リトライ回数の上限と時間は環境変数に持つのがいいかなと思います。)
実装としてはイマイチになってしまったこともありますが、そもそもリトライに関してはどうあるべきかしっかりと検討すべき事項だと思います。
今回のコードはあくまでもサンプルなので要件やIcebergの仕様を確認した上で、設計いただくのが良いかと思います。
dynamoDB

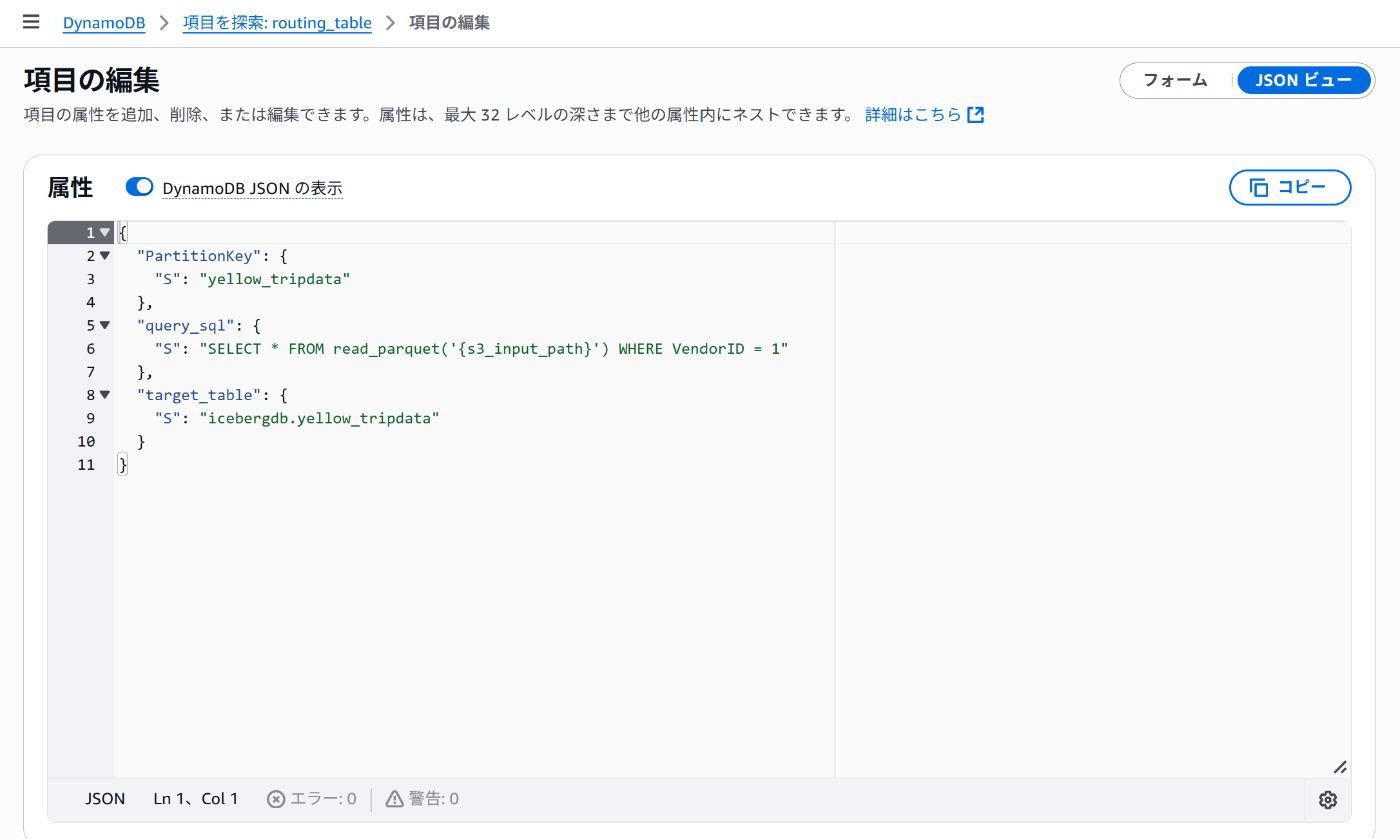
実行結果
ひとつめのバケットにアップロード

正常に書き込まれました!
ふたつめのバケットにアップロード
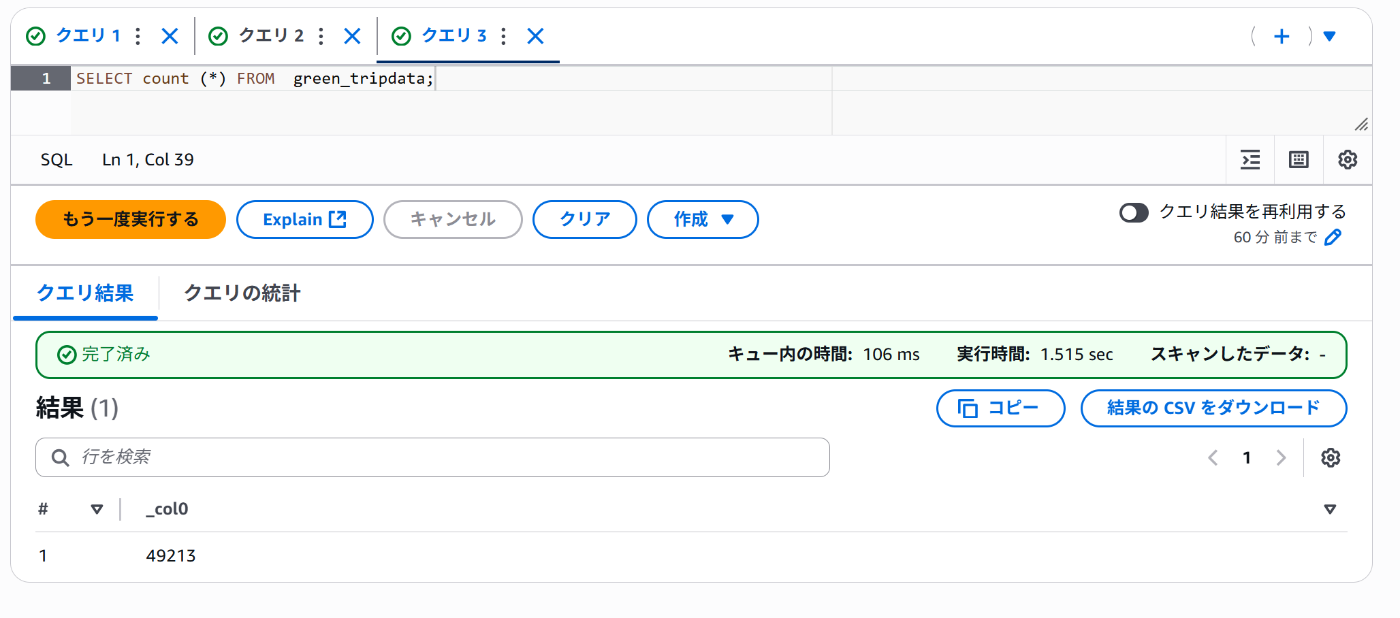
正常に書き込まれました!
メリット・デメリット
メリット
- 新しいソースや宛先の追加も S3のトリガ設定とDynamoDBの設定更新だけで対応が可能。
- Lambdaコードはシンプルで保守が容易となる。(経路ごとのLambdaの作成やメンテナンスが不要)
デメリット
- DynamoDBが単一障害点になる可能性がある。
- 最大メモリサイズの制限がある。
- 実行時間の制限がある。(実行時間は15分が最大となります。)
- 複雑な処理をやろうとすると難しい。あくまでもSQLをもとにした処理になるため、ロジックで対応する必要があるような高度な処理は難しい。ランディングゾーンからブロンズへの書き込みなど簡単な処理に適していると思います。
その他アプローチ
メタデータによるルーティング
Parquet内部のカスタムメタデータやカラムを使ってルーティングする方法です。
この場合、ファイル名やパスに依存せず柔軟にルーティングが可能となります。
ただし、キーとなるようなメタデータが含まれている必要があるので適用が難しい場合があります。
data_type = pq_file.metadata.metadata[b'type'].decode()
まとめ
今回はAWS Lambdaをベースにした動的ルーティング軽量ETLを実装しました。
今回のアプローチはソースごとに分散しがちな処理を一つにまとめることができるのでメンテナンスコストを下げることが可能となります。
また、柔軟に経路を追加することもできるので使い方次第では非常に便利だと思います。
今回の処理はあくまでもアイデアベースとなりますので、使用される場合は要件やメリデメを加味したうえで検討いただければと思います。
今回の記事が、軽量ETLを検討している方の参考になれば幸いです。
Discussion