【Azure】AzureOpenAI On Your Dataのイメージを掴む!
初めに
プレビュー版だったAzureOpenAI On Your DataがGA(一般提供)されました。調べてみると意外とOn Your Dataってわかりづらいと感じたので、今回の記事ではOn Your Dataとはどういうものなのかをしっかり理解できるように説明していこうと思います。細かい構築から使用方法などは他にわかりやすい記事があったので、そちらを参照する形で進めます。
AzureOpenAI On Your Dataとは
AzureOpenAI On Your Dataとは?という問いに対して、簡単に答えるならRAG構成を簡単にAzure上で構築して、試したり使用することができるようなものとなっています。MSの正確な説明は以下リンクを参照ください。
勘違いしないでいただきたいのは、On Your DataというAzureのリソースが存在するわけではなく、On Your Dataを利用すると比較的簡単にRAG構成が構築できるということです。RAG構成はAzureのリソースを組み合わせることで実現できて、ただそれを素人が一から構築しようとすると詰まりやすいので、On Your Dataだと多少楽に試したりできるって感じです。
テキストor画像のデータの使用
今回主に話していくのはデータをテキストとして使用するOn Your Dataについてです(上にも貼りましたが、以下のMSドキュメントの内容)。 それに対して、画像をデータとして活用できるOn Your Dataもあります(プレビュー版)。こちらはGPT-4 Turbo with Visionを用いて格納した画像を基に回答ができるらしいです。Azureポータル上でデータを格納する入り口もテキストの方とほとんど同じなのですが、テキストのものと画像のものとは別物だと思った方が理解がしやすいと感じたので、こちらの方は一旦忘れてください。こちらについて詳しく知りたい方はMSドキュメントとQiitaの記事を以下に記載しますので、そちらを見てもらえればある程度イメージが掴めると思います。
データのアップロード方法
独自のデータを基に回答してもらうために、データをアップロードする必要があります。そのアップロードの方法としてMSドキュメントには下図のような種類があると記載されています。

Webとファイルのアップロードの方法は使用したことがないのですが、Blob Storageにデータを格納した際の処理イメージとしては下図のようになります。Webとファイルのアップロードに関しても、結局はデータがインデックス化されAI Searchに格納されたインデックスを基にAOAIが回答するので、同じようなイメージをしておけば良いと思います。
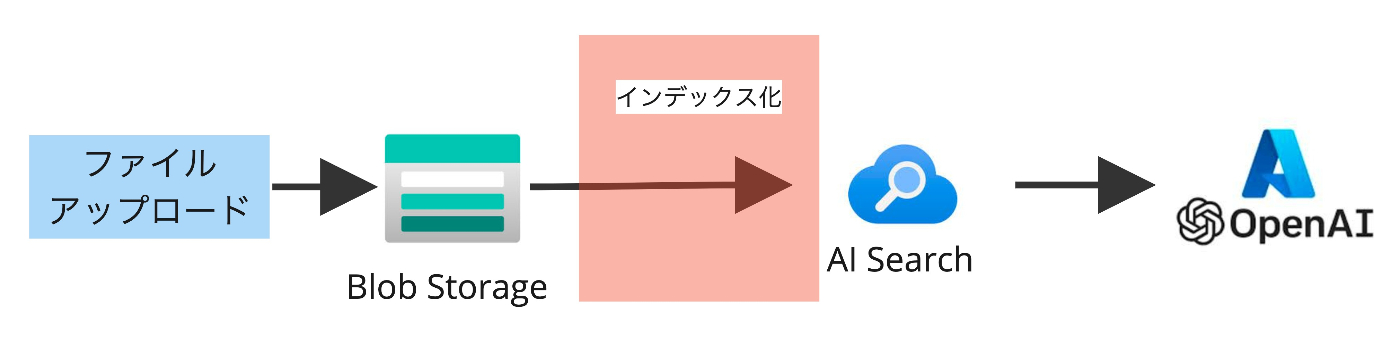
Blob Storageでのアップロード方法では上図のような、まだインデックス化されてないデータからインデックス化してAI Searchに保存するような仕組みをOn Your Dataを用いて構築することができます。
それに対して、AI Searchをデータソースとして選択することもでき、こちらは既にインデックスが出来上がってる前提なので、On Your Dataを用いて構築されるものがあまりありません。少しややこしくなってしまいましたが、要は上図が構築される基本のRAGイメージで選択されるデータソースによって構築される範囲が異なるみたいなイメージで大丈夫です。
On Your Dataの環境構築と利用方法
環境構築
簡単にRAG構成を構築できると思っていましたが、利用するまでには意外と必要な設定が多かったです。必要な設定は以下記事が参考になります。 出てくるAzureのリソースは先ほども触れたAzureOpenAI、AI Search、BlobStorageの3つです。これらに対して、必要な設定を超ざっくりまとめると以下のようになります。
- リソースの作成
- 各リソースにアクセスするためのロール割り当て
- (必要に応じて)ネットワークの設定
- BlobStorageはCORSの設定
この辺りは以下のMSドキュメントにも記載があるのですが、ドキュメントはかなり色々書かれていますし、必要なロールが英語で書かれているけど、Azureポータルでは日本語で表示されていてどのロールを選択したらいいかわからないといったことがありました。なので上のQiita記事を見た方が設定は圧倒的にわかりやすいです。会社などの場合はネットワークを閉域にしている場合などあると思うので、その場合はネットワークの設定が結構難しいかもしれません。
利用方法
環境構築(前準備)が終わった後の利用方法としては以下記事がわかりやすいです。細かい手順はこちらの記事を見てもらえれば大丈夫ですが、少しだけ画像を拝借して、私の記事でも説明します。
まず、AzureOpenAI Studioのチャット画面でデータソースを追加します。

そして、ファイルを格納するBlobStorageのコンテナとAI Searchにどのような名前のインデックスを作成するかを設定します。
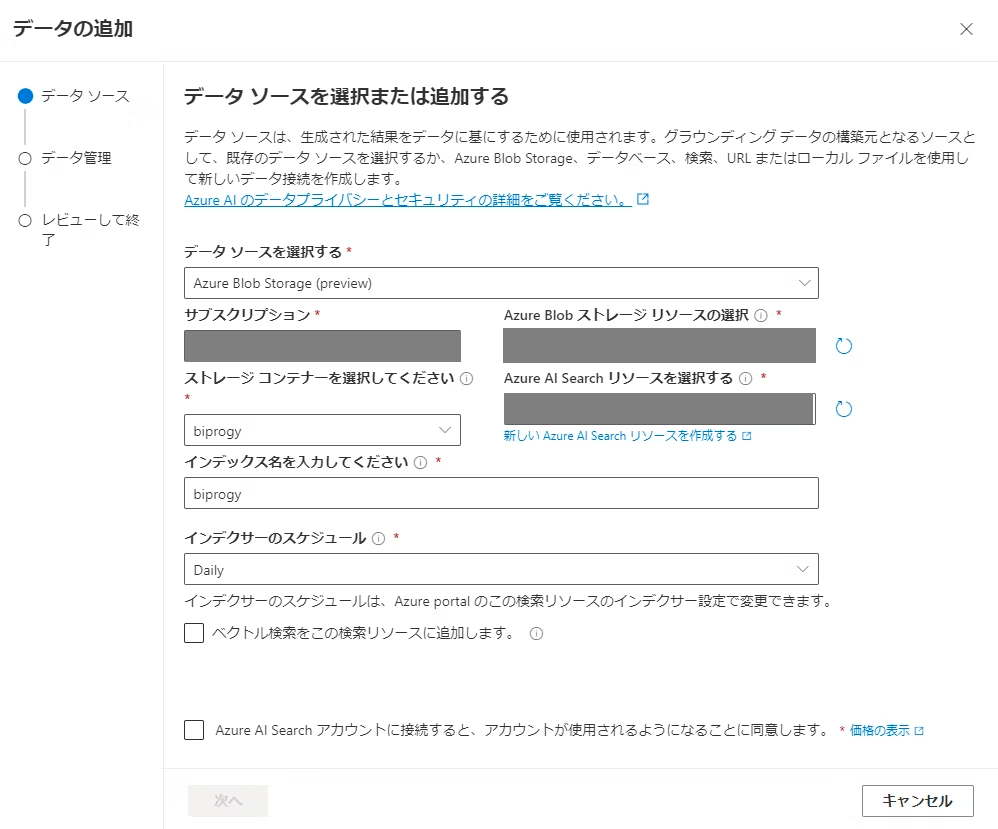
このデータソースの設定の部分でベクトル検索を可能にするかや検索時にハイブリッド検索やセマンティック検索ができるようになどを設定することができます。
データが追加されたらあとはStudio上でチャットすることで、データを参照しつつ回答してくれるようになります。
On Your Data実行後のAzureのリソースの変化
AI Searchに下図のようにいくつか作成されるものがあります。逆に他のリソースにはほとんど変化はありません。
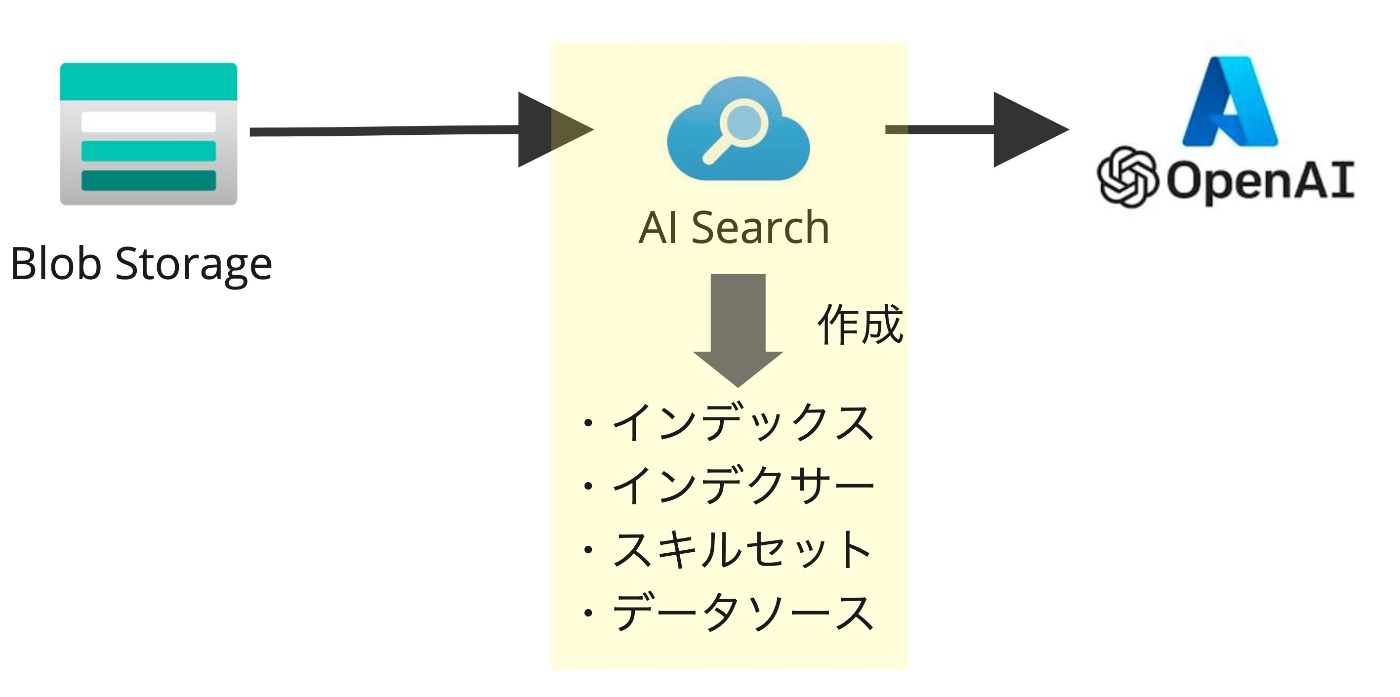
AI Searchで作成される以下について、どういう役割を果たすのかイメージレベルで説明します。
- データソース
- スキルセット
- インデクサー
- インデックス
データソース
どこに格納されたデータからインデックスを作成するのかを設定する役割で、データソースが作成されます。On Your Dataで指定できるデータの連携方法はかなり限られていますが、AI Searchから作成する場合には、もっといろんな連携方法がありそうです。詳しくは以下リンクをご確認ください。
スキルセット
データソースからドキュメントをインデックス化する際は、基本ドキュメントをテキストに変換する処理が必要になります。このテキスト変換をどのように行うのかという役割としてスキルセットが作成されます。RAGの精度向上には文字だけじゃないドキュメントがどのようにテキスト化されるかがとても重要です。On Your Dataを利用する際にはスキルセットを選択しなくて良かったので、ある程度Azureおすすめのスキルセットが使用されてそうと思っています。AI Searchのスキルセット画面からどのスキルセットが使用されているかは確認できて、それを変更することで、RAGの精度が大幅に変わる可能性もありそうです。詳しくは以下リンクをご確認ください。
インデクサー
実際にデータソースやスキルセットを使い、インデックスを作成する役割としてインデクサーが作成されます。インデクサーではどれくらいの頻度でインデックス化を実行するかも設定することができます。Blob Storageをデータソースに設定した場合は、格納されたデータの変更を確認して、いい感じにインデックス化してくれるようです。詳しくは以下のリンクをご確認ください。
インデックス
検索するために必要なインデックスを作成します。インデックスの中には基本的に適度に分割されたテキストとその情報を検索するために必要な情報(ベクトルなど)をひとまとまりに保存しています。これまでBlob Storageにデータを格納したりしましたが、ドキュメントをテキスト化したものがインデックスに保存されるので、RAGで回答する際の処理としては、Blob Storageにアクセスする必要はなく、AI SearchとAOAIだけで良いということです。なお、インデックスはインデクサーを使用しなくても、インデックスを作成するような処理を自分で0からコードを書いて作成することもできます。インデックスに関して、詳しくは以下リンクとその周辺のドキュメントなどをご確認ください。
インデックス化処理まとめ
AI Searchのインデックス化で、どういう処理が行われるかが文字だけだとイメージしづらいかと思ったのでイメージ図を作成しました(イメージなので厳密には少し違う部分もあるかもです)。こちらはユーザーが質問時に行われる処理ではなく、インデクサーで指定したインデックス化の実行頻度によって実行されるのでRAGにおける事前準備と思って貰えば良いかなと思います。
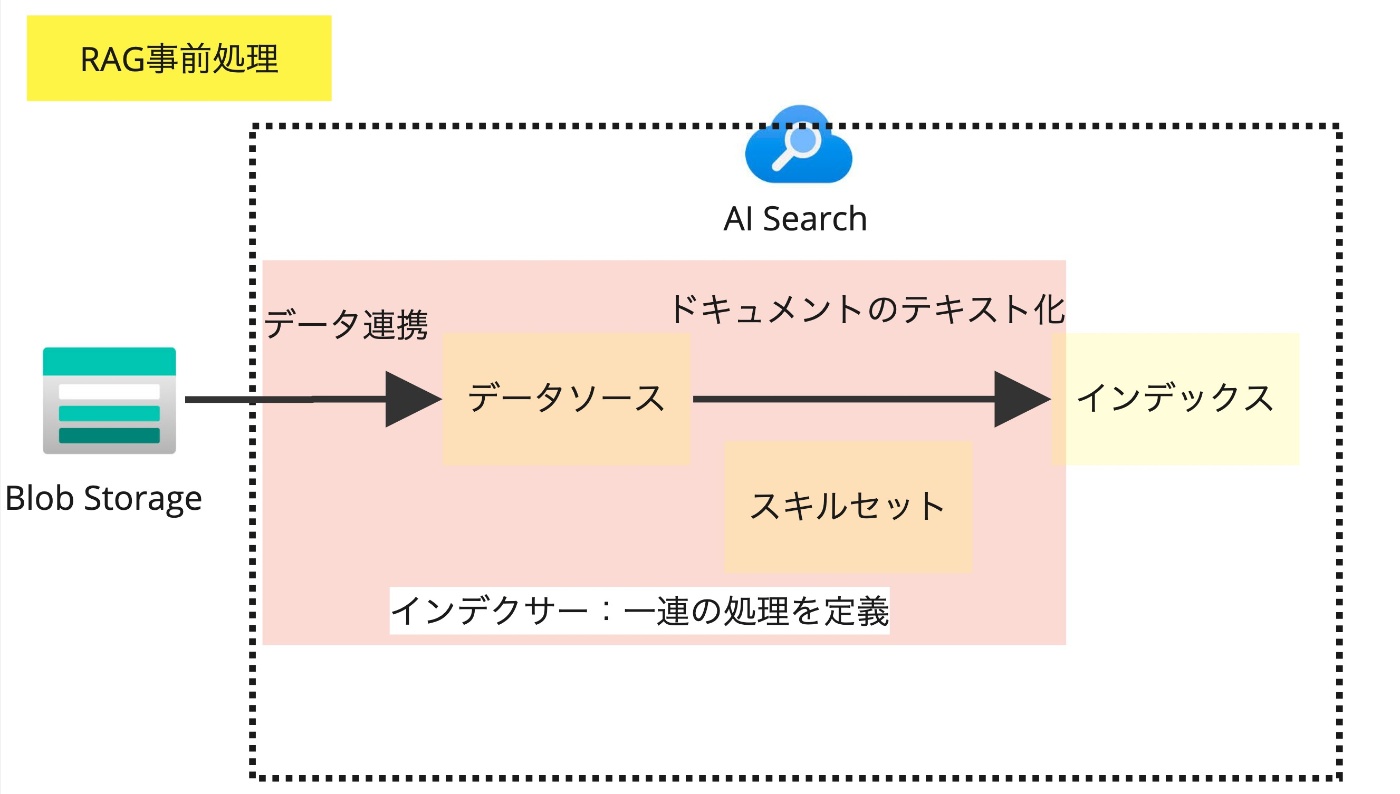
それに対して、作成されたインデックスを基にAOAIで回答することで、実際に独自の知識を持った回答をしてくれます。質問時の処理についてのイメージ図も以下に示します。
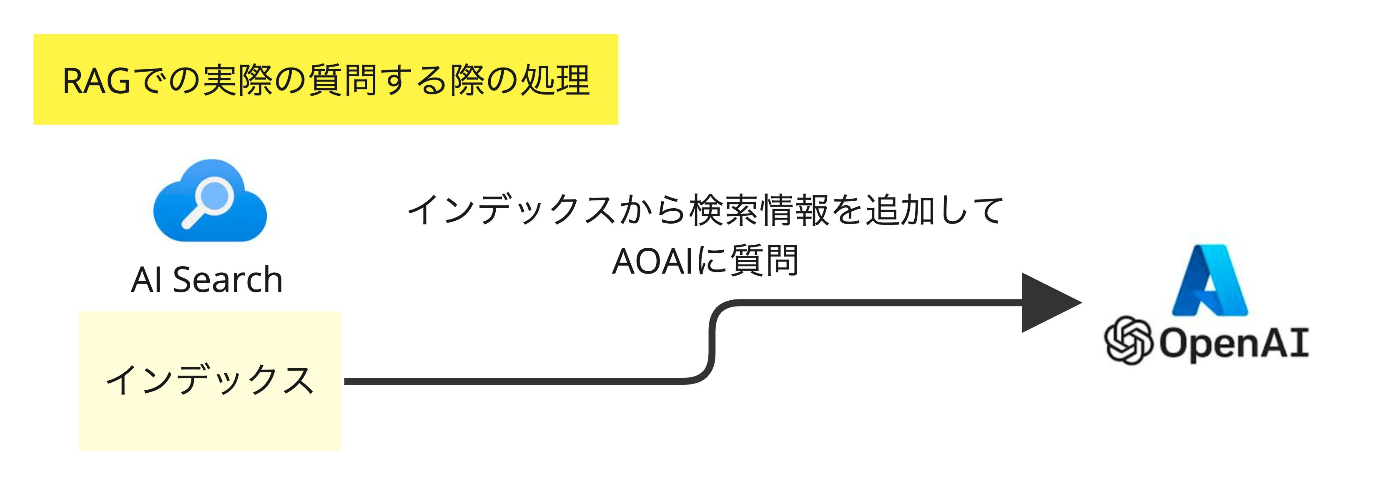
On Your Dataでデータを追加するとき、データソースとしてBlob Storageを選択すると、RAG事前処理の図のような構成で色々作成されますが、データソースとしてAI Searchを選択すると、既に作成済みのインデックスを利用してAzureOpenAI Studioのインターフェースで質問できる感じになり、新しく作成されるものなどはありません。なので、一回Blob StorageのOn Your Dataで作成したインデックスに、後日繋げたい場合は1回目で作成されたAI Searchのインデックスを選択すれば良いということになります。
また、On Your DataはAzureOpenAI Studio試せると話しましたが、インデックスさえ作成されてしまえば、インデックスとAOAIをアプリケーションに組み込むことで、ドキュメントを基に回答してくれるアプリを作成することも可能です。
実際に作成されたもの(詳細)
On Your Dataを用いてBlob Storageと繋げた際、実際にはこれまで説明してきたよりちょっとだけ多くのものが作成されました。作成されたものの詳細は以下に記載します(太字が今まで記載してこなかったもの)。ややこしくなってしまうので、大枠のイメージはこれまでのもので大丈夫なのですが、チャンク化処理をするために太字のものは追加されてるんだなと思っていただければと思います。
【AI Search】
<データソース>
- 元ファイルと繋ぐデータソース
- チャンク後のファイルと繋ぐデータソース
<スキルセット>
- スキルセット
<インデクサー>
- インデクサー
- チャンク用のインデクサー
<インデックス>
- インデックス
- チャンク用のインデックス
【BlobStorage】
- チャンク用のコンテナ
実際にOn Your Dataを使ってみた精度の所感
実際にOn Your Dataを使ってみて、回答精度に関する所感を簡単に記載します。精度としては、しっかりテキスト化されているpdfなどであればちゃんと正しい回答をしてくれる可能性が高いと思いますが、表や図などのドキュメントの場合はテキスト化が難しいため、やはり精度としては良くないと感じました。表や図がテキスト化されるときにAI Searchのスキルセットが使用されるので、ここでAzureさんがいい感じに処理してくれないかな?と期待したのですが、ただ文字になっているところを抜き出しただけのように感じました。スキルセットに関しては、私がまだ調べられてないだけで、より適したものを設定すれば精度が上がってくれるかもしれません。この辺りもまた理解が深まったら記事を書きたいと思っています。
まとめ
意外と理解しづらいAzureOpenAI On Your Dataを理解することができたでしょうか?
調べてみて、On Your Dataの仕組みを理解したり、RAGの精度を向上するためにはAI Searchへの理解が必要だなと強く感じました。引き続きAzureやRAGへの理解を深め、記事でも色々発信していけたらと思います!
Discussion