Embedding(ベクトル化)についてイメージを掴む!
初めに
職場で生成AI系の勉強会をしており、そこで私はEmbeddingについて調べるという機会があり、こちらの記事にも残そうと思います。Embeddingに関する記事もたくさんありますが、Embeddingを知らない人でもより理解しやすいように自分なりにまとめていきたいと思います。なお時短のため、いろんなwebサイトの画像や記事なども参照させていただきますので、出典先として都度URLも記載していきます。
Embeddingとは
Embeddingとは直訳すると「埋め込み」です。とはいえ、埋め込みと言われてもピンとこないと思います。
要は「Embeddingとはテキストなどのデータをベクトル化する処理」と思ってもらえれば大丈夫です。
参考:https://qiita.com/sakabe/items/5f14999ded1de087c9b5
そもそもベクトルって?
昔勉強した数学を思い出してみましょう。何も難しいことはありません。
ベクトルのイメージは下図のような矢印です。
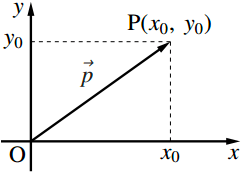
参照:http://www.ftext.org/text/subsubsection/3274
上図は二次元のベクトルですね。このような場合のベクトルは[x0, y0]のように配列で表現します。
二次元だと上図のようにイメージしやすいですが、Embeddingでは次元数がかなり増えます。その場合でも、次元数が増えただけの配列で表現される矢印ってイメージを持ってもらえれば良いと思います。
Embedding(ベクトル化)するイメージ
ベクトル化するとは下図のように「犬」というテキストが配列になるようなイメージです。
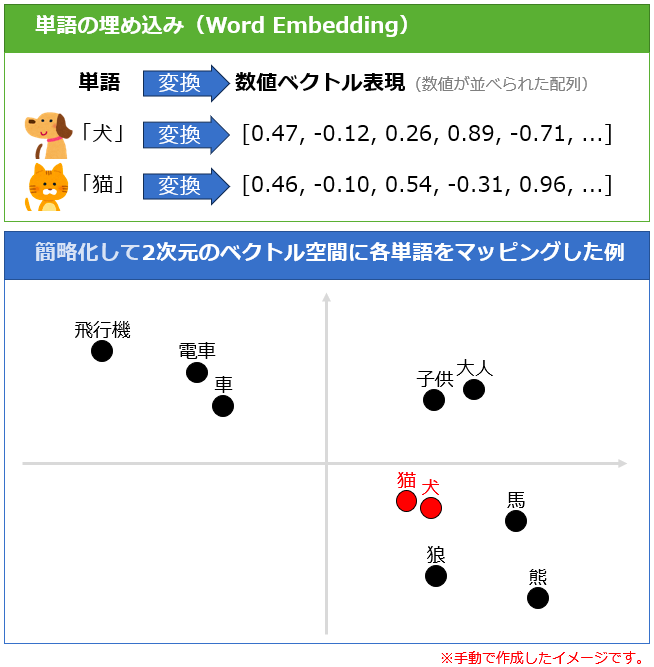
参照:https://atmarkit.itmedia.co.jp/ait/articles/2401/18/news023.html
じゃあどうやってベクトル化するのかというと現在ではEmbedding用のモデルを利用することで誰もが簡単にテキストをベクトルに変換することができます。例えばOpenAIのtext-embedding-ada-002というモデルを使えば、テキストを1536次元の配列に変換することができます。
Embedingモデルを使ってベクトル化する際に、覚えておいてほしいポイント以下3点です。
- どれだけ短いテキストでも長いテキストでも、同じモデルを使えば同じ次元数のベクトルに変換される
→text-embedding-ada-002であれば、どんなテキストでも1536次元になります - ベクトル化する際の次元数や各要素の数値の算出方法は各モデルによって異なる
→ベクトル同士の比較は同じモデルを利用しないとできない - 同じモデルを使って一言一句同じテキストをベクトル化すると、全く同じベクトルが返ってくる
→chatGPTのような回答にランダム性はない(ベクトルを比較する際には安心できる)
ベクトルの類似性(コサイン類似度)
ベクトル化したデータ同士が意味的に近いかどうかを調べる方法として、コサイン類似度という考え方があります。イメージはすごく簡単で下図のようにベクトルとベクトルのなす角度(つまりcosθの値)で意味的な近さを判断できるというものです。cosθが1に近づくほど、似ているということになります。cosθなので値は当然-1〜1の間の値をとることになります。
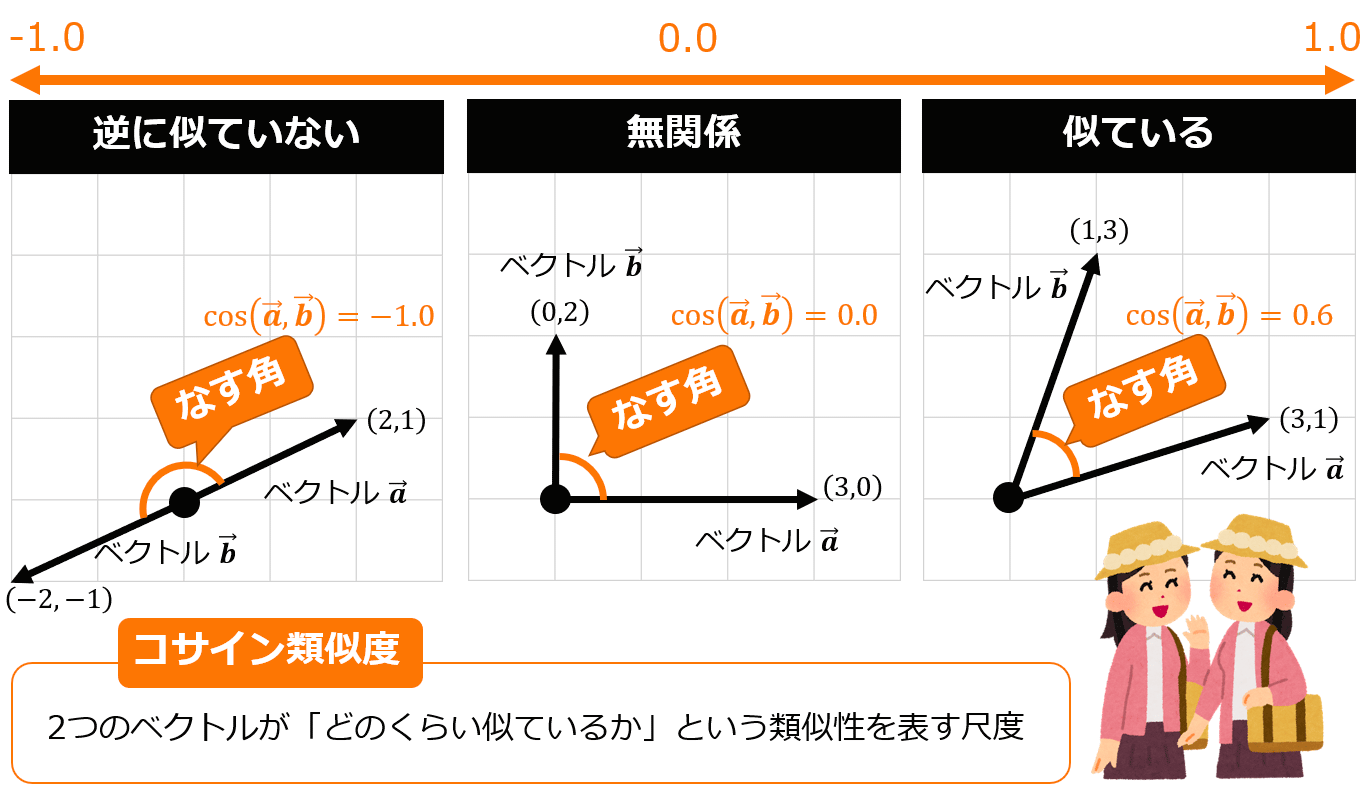
参照:https://atmarkit.itmedia.co.jp/ait/articles/2112/08/news020.html
ベクトルの類似度を調べる方法は他にもあるようですが、コサイン類似度を使うのが一番一般的だと言われてます。(OpenAIのサイトでもコサイン類似度を使うことが推奨されています)
コサイン類似度の算出方法については下図のような感じです。

参照:https://mathlandscape.com/cos-similar/
要は「ベクトル同士の内積 / (ベクトルの長さの積)」でcosθを算出することができます。興味のない人はベクトル化で得られた配列の値があれば計算できるんだくらいに思ってもらえればOKです。
ベクトル化のメリット
- テキスト同士の文字が一致していなくても類似性を調べられる
- テキストや画像など異なるデータでも同じモデルでベクトル化できれば、類似性を調べられる
これらのメリットから、コンテンツの意味的な近さ(セマンティック類似性)を用いて、検索サービスなどに利用できます。今後、さまざまな分野でベクトル化が利用されたり、活用方法が発展していきそうだと思っています。
最近では生成AI周りでRAGという技術があり、RAGではLLMに参考情報を与えることで、最新の情報や企業独自の知識を持ったような回答をしてくれるようになります。RAGにおいても、どの参考情報が回答に必要かを判断するため、ベクトル検索というものがよく用いられています。RAGについて詳しく知りたい方は、検索したらいろんな詳しい記事がヒットすると思います!
少し謎で面白いベクトル化
→こちらの記事を見てベクトル化って少し謎で面白いなと思ったポイントがありました。記事から下図を参照させていただきます(text-embedding-ada-002を用いたベクトル化についてです)。
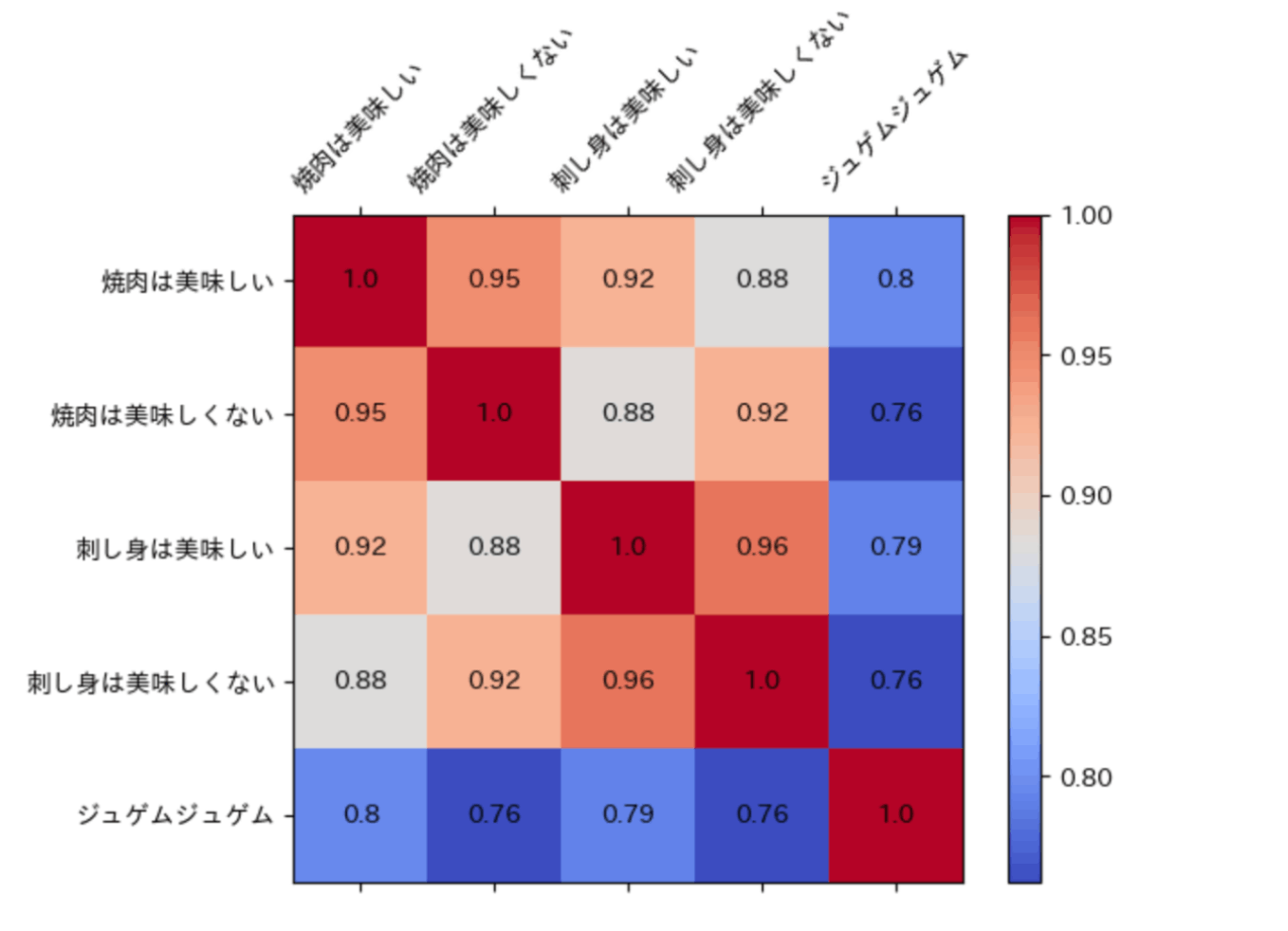
「焼肉は美味しい」と「焼肉は美味しくない」は一見真逆のようにも思えるテキストですが、コサイン類似度は約0.95と、1に近い値を示しています。意味的に近しい言葉を使っているから、ベクトルとしては近い値になるのかなと私は思っています。ちなみに「美味しい」、「美味しくない」でも試してみましたが、コサイン類似度は約0.91くらいだったと思います。自分がいくつか試した範囲では0に近い値やマイナスになる値は確認できなかったので、どのような言葉ならマイナスになるかなど、知ってる人がいたら教えてもらえると嬉しいです!
じゃあ結局ベクトルを比較しても意味的な違いはわからないじゃんと思う方もいるかもしれませんが、RAGのベクトル検索で用いられているなど、質問に対して似たような情報がどれかを判別するにはある程度有効という評価を受けているように感じます。この辺りはモデルも新しくなるにつれ、より精度が上がっていくと思います!
最後に
Embedingのイメージを掴むことができたでしょうか?Embeddingは奥は深そうですが、最低限Embeddingを理解して、利用するというところまでならあまり難しくはないと思っています。私もいろんなところでベクトル化を利用できないかを考えていきたいですし、より深いところまで理解できればその辺りも記事にしていきたいなと思っています!
(参考)AzureOpenAIを利用してpythonからEmbeddingしてみる
こちらは参考として、AzureOpenAIを用いて、Embeddingを実行してみたコードを記載します。
APIキーやエンドポイントは環境変数から取得するようにしてますが、そこは各自自分のAzureOpenAIのリソースを確認するようにしてください。
以下はただinputのテキストをモデルを使ってベクトル化するだけのコードです。といってもこちらのコードはMSのドキュメントに書いてあるのとほぼ同じです。
import os
from openai import AzureOpenAI
client = AzureOpenAI(
api_key = os.getenv("AZURE_OPENAI_KEY"),
api_version = "2023-05-15",
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT")
)
response = client.embeddings.create(
input = "Your text string goes here",
model = "text-embedding-ada-002"
)
print(response.model_dump_json(indent=2))
以下が二つのテキストからコサイン類似度を算出するコードです。こちらはchatGPTに書いてもらったらそれなりにいいコードを出してくれたので、あまり変更せずに動かすことができました。
import os
from openai import AzureOpenAI
import numpy as np
from numpy.linalg import norm
API_KEY = os.getenv('AZURE_OPENAI_KEY')
ENDPOINT = os.getenv('AZURE_OPENAI_ENDPOINT')
# ベクトル化を処理を行う関数
def embed_text(text):
client = AzureOpenAI(
api_key=API_KEY,
api_version="2023-05-15",
azure_endpoint=ENDPOINT)
response = client.embeddings.create(
input = text,
model = "text-embedding-ada-002"
)
# ベクトル化で出来上がった配列のみreturn
return response.data[0].embedding
# コサイン類似度を計算する関数
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (norm(vec1) * norm(vec2))
# 比較するテキスト
text1 = "焼肉は美味しい"
text2 = "焼肉は美味しくない"
vec1 = embed_text(text1)
vec2 = embed_text(text2)
# コサイン類似度を実際に計算
similarity = cosine_similarity(vec1, vec2)
print(f"コサイン類似度: {similarity}")
Discussion
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
model.encode(sentences)
これなら5万個*3文字の文章をlocalで30sで処理できます。
sentence tranceformerは関係/無関係で訓練されることが多いため0以下にcos近似がなることは珍しいです。
近くにあるテキスト2つ->関係。離れてる->無関係。逆->生成が難しい(少ない)