格安でRAGのデモアプリを作ってみる!
初めに
会社のLTで発表する機会があり、RAGを知ってもらうために簡単なRAGアプリを作成しました。この記事では自分が作ったアプリを紹介していこうと思います。簡単なデモアプリなので凄いものではありませんが、RAG実装をあまりやったことのない方にとっては、アプリの構成やデータのテキスト化、プロンプトの部分で参考になる部分も多少あるのではないかと思っています。
どのようなデモアプリを作ったか
現在勤めている会社はSES系の企業となるのですが、社員のスキルシートを基に回答してくれるようなアプリを作成しました。どのような社員がいるかや案件にマッチする人材を教えてくれると便利そうだなという発想から作成しています。
↓今回のアプリのGitHubはこちらです。
アプリの構成
自分が勝手に作ったので会社からお金が出るわけでもないため、なるべく安くなるように考えて作成しました。ただ、LT参加者に面白いと思ってもらえるように最低限精度が出そうかなということは考えています。
アプリの構成図を下図に示します(質問から回答の簡単な処理の流れも記載しています)。
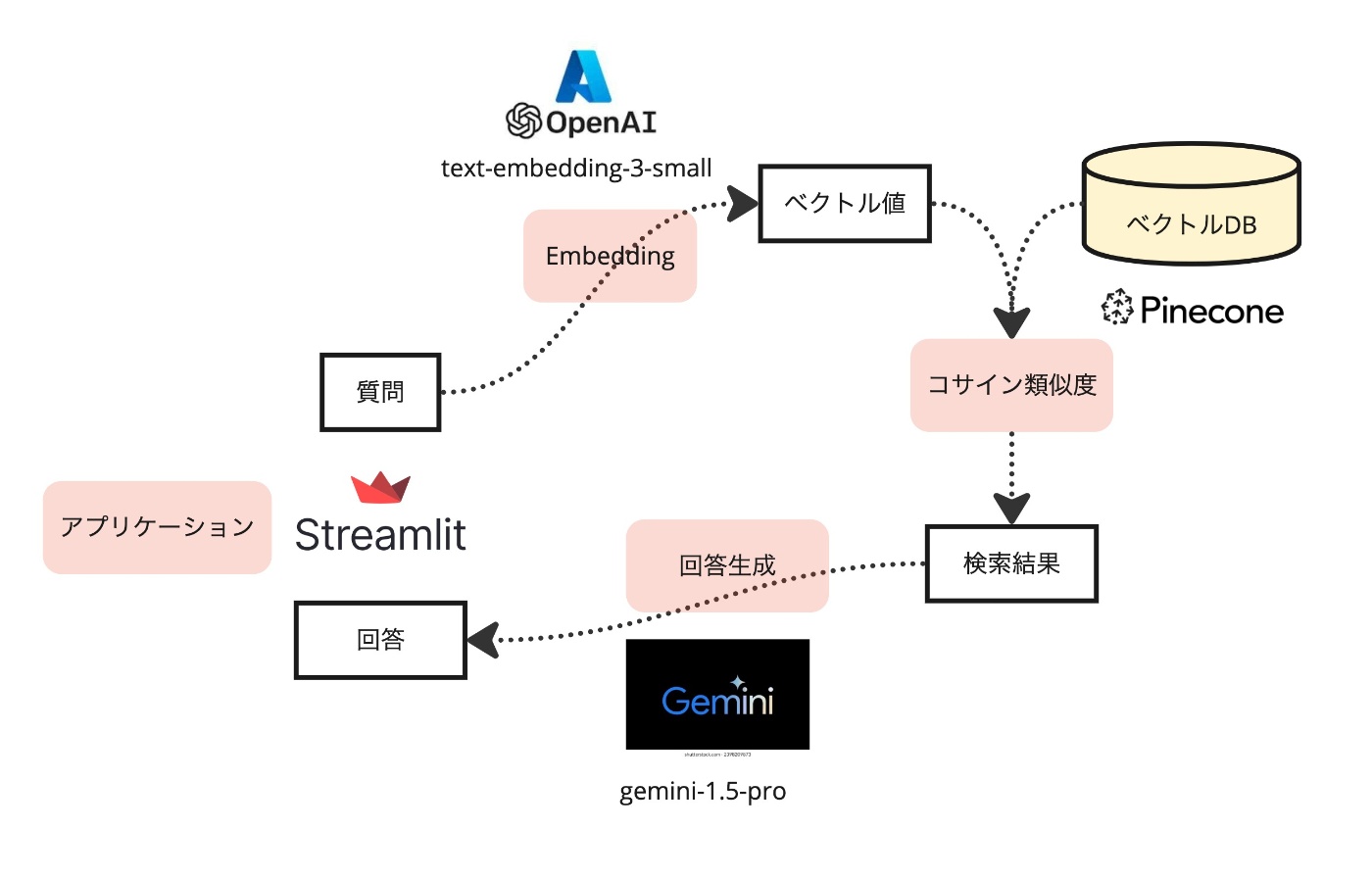
上図にも記載していますが、使用したサービスを以下の表にまとめています。
gemini-1.5-proは2024年5月2日までは無料で使えるとの情報があったので使用していますが、それ以降は普通に課金が必要そうなので注意です(それもあってこの記事は早めに公開することにしました)。
| 用途 | 使用サービス | 課金の有無 |
|---|---|---|
| アプリケーションのライブラリ | Streamlit(python) | 無料 |
| Embedding用モデル | text-embedding-3-small(AzureOpenAI) | リクエストごとに課金 |
| 回答生成用モデル | gemini-1.5-pro | 無料(期間限定) |
| ベクトルDB | pinecone | 無料(制限あり) |
サービス選定
なぜ今回利用したサービスを選んだかを簡単に紹介します。
Streamlit
生成AI系のアプリを作るときはpythonがライブラリが豊富なのでpythonは使おうという感じでした。Streamlitは一瞬でアプリの見た目を作ってくれるライブラリなので、デモアプリとしては最適かなということで選んでいます。
text-embedding-3-small(AzureOpenAI)
ここは少し手こずった部分があります。まず、なぜOpenAIではなくAzureOpenAI(AOAI)を用いているかですが、OpenAIに10ドルチャージしていざAPIを叩こうと思ったら429のエラーが出ました。どうやら、課金してからそれが反映されるのに時間が多少かかるみたいな情報も聞き、私の場合は2,3日経っても使えなかったため、LTに間に合わせるためにAOAIを使用することにしました。AOAIを使用するにもAzureに申請が必要なのですが、申請したら3時間程度で承認がおり、使えるようになりました。急ぎで使いたい方はAOAIを使うというのも1つの手かもしれません。
あとはどのモデルを使うかですが、text-embedding-ada002より精度が高くて、安いというtext-embedding-3-smallを使用することにしました。text-embedding-3では次元数(dimensions)を選択できるのですが、ここも小さめの512次元でも十分と思い設定しています。
価格や精度については以下記事も参考にしてください(正確には最新の公式ドキュメントを見た方が良いです)。
gemini-1.5-pro
ここはあまり考えていません。gemini-1.5-proが5月2日まで無料で使えるらしいから、使ってみたくらいの感覚です。ただ、gemini-1.0-ultraより精度が高いらしいと聞いた気がするので、悪くはないだろうと思って、実際使ってみたところ回答に不満はなかったです!
pinecone
ここもあまり考えていませんが、無料で使えるベクトルDBということで選定しました(無料だと制限はあります)。自分の調べた限りですが、Azure AI SearchのようにベクトルDB側でいい感じにハイブリッド検索が出来なさそうだと思ったのですが、今回はベクトル検索だけを用いようということでpineconeにしています。
スキルシートのテキスト化
RAGとして精度を出すためにはスキルシートをどのようにテキスト化できるかが非常に重要です。元々Excelのスキルシートをテキスト化しようとして試行錯誤したのですが、結構難しいです。表形式であったりセル結合しているデータをどうやってテキスト化し、LLMに伝えるかが難しいポイントとなってきます。
スキルシート自体は一般的なフォーマットになっていると思います(以下参照)。
スキルシート(イメージを掴むためのもので情報は限定しています)
pythonのライブラリでテキスト化なども試したのですが、今回はChatGPT(有料版)にスキルシートのPDFを入力して、プロンプトで指示を出してテキスト化してもらうという方法を最終的に採用しました。ちょっとズルですが、今回はこれが一番テキスト化の精度が高いと思いました。
テキスト化するためのプロンプトは以下のようなものを考えました。どのような経験がどれくらいの年数あるとわかると嬉しいと思ったため、必要な情報を抽出してくれそうなプロンプトにしています。また、回答の出力が同じ形式になるように、出力例もプロンプトとして含めています。
プロンプト
# 指示
添付したエンジニアのスキルシートを2000文字以内で要約してください。以下の条件を満たすように、LLMが理解しやすいテキストとして保存したいです。
- どのようなスキルがどれくらいの期間経験があるかがわかるようにまとめる
- 工程(要件定義・基本設計・開発など)に関してどれくらいの期間経験があるかわかるようにまとめる
- 業種についてどれくらい経験があるかをまとめる
- リーダー経験やサブリーダ経験がどれくらいあるかをまとめる
- 各項目の経験年数がわかる場合は具体的に年数で記載する
- 自己PRの内容は全て記載する
- 添付ファイルに記載されてない情報は記載しない
- 以下の出力例を参考に要約を出力する
# 出力例
### スキルと経験年数
- **プログラミング言語**:
- **C++、VC++**: 12年以上
- **Java**: 15年以上
- **フレームワークとツール**:
- **Spring Framework**: 10年以上
- **Eclipse、Redmine、Jenkins**: 10年以上
### 工程ごとの経験年数
- **要件定義**: 15年以上
- **基本設計**: 15年以上
- **詳細設計、開発**: 15年以上
- **結合テスト、総合テスト**: 15年以上
- **運用、保守**: 10年以上
### 業種経験
- **業界名**: 内容
### リーダー経験
- **案件名**: 内容(ない場合は記載しない)
### サブリーダー経験
- **案件名**: 内容(ない場合は記載しない)
### 自己PR
自己PR記載の内容をそのまま記載
ベクトルDBのデータ準備(コード紹介含む)
pineconeの登録とインデックス作成
詳しくは説明しませんが、pineconeの登録とデータを保存するためのインデックスを作成しましょう。今回インデックスには512次元のベクトルを保存するのでそこはインデックス作成時に設定します。pineconeの操作周りについては以下ドキュメントなど見ると良いと思います。
テキストをEmbeddingしてpineconeに保存
先ほどテキスト化したスキルシートの内容をtxtファイルとして保存しておきます。以下のコードはそのtxtファイルをembeddingしてpineconeに保存する処理を行います。少し手間ですが、私はこの処理を人数分実行して、pineconeに保存しました(今回は20人程度のデータで試したので自動化しなくても良いかなと思い)。このコードはmetadataの設定の部分を少し変えれば、スキルシートに関係なく、他でも活用できると思います。
embedding_to_pinecone.py
import os
from dotenv import load_dotenv
from openai import AzureOpenAI
from pinecone import Pinecone
# 環境変数をロード
load_dotenv()
# Azure OpenAIの設定
aoai_api_key = os.environ["AZURE_OPENAI_API_KEY"]
aoai_endpoint = os.environ["AZURE_OPENAI_ENDPOINT"]
client = AzureOpenAI(
api_key=aoai_api_key,
api_version="2024-02-01",
azure_endpoint=aoai_endpoint
)
# Pineconeの設定
pinecone_api_key = os.environ["PINECONE_API_KEY"]
pinecone_index_name = os.environ["PINECONE_INDEX"]
pc = Pinecone(api_key=pinecone_api_key)
index = pc.Index(pinecone_index_name)
# 設定すべきパラメータ(IDは重複するとデータ上書きされる)
id = "数字" # 例)"1"
filename = "技術経歴書_名前.txt"
username = "名前"
# 技術経歴書のテキストを読み込む
file_path = f"skill_sheet/text/{filename}"
with open(file_path, "r", encoding="utf-8") as file:
text_content = file.read()
# テキストをembedding
response = client.embeddings.create(
input=text_content,
model="text-embedding-3-small",
dimensions=512
)
# ベクトル配列を取得
embedding_vector = response.data[0].embedding
# Pineconeにアップロード
index.upsert(
vectors=[
{
"id": id,
"values": embedding_vector,
"metadata": {"filename": filename, "username": username}
}
]
)
print(embedding_vector)
print("技術経歴書のembeddingがPineconeに保存されました。")
コード紹介(アプリ)
簡単にコードも紹介しますが、詳しくはGitHubをご確認ください。長くなってしまうのでコードは基本トグルの中に記載しています。
Streamlitアプリ部分
↓簡単なstreamlitの実装です。(モデルを選択可能にしている部分は今後実装したい部分の途中です、、)
アプリ部分:app.py
import streamlit as st
from service.gemini_answer import gemini_answer
st.title("RAG test")
## オプションを定義
model_options = ['gemini-1.5pro', 'GPT-4-turbo']
## セレクトボックスをサイドバーに作成
selected_option = st.sidebar.selectbox('モデルを選択してください:', model_options)
# 選択したモデルを基にインスタンスを作成(classも後で作成)→それを実行することでモデルやベクトルDBを可変にできるようにしたい
prompt = st.chat_input("What is up?")
if prompt:
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
response = gemini_answer(prompt)
# response = selected_option
st.markdown(response)
質問内容のベクトル化
質問内容のベクトル化部分:aoai_question_embedding.py
import os
from dotenv import load_dotenv
from openai import AzureOpenAI
# 環境変数をロード
load_dotenv()
# 質問をembeddingしてベクトル配列を返す
def aoai_question_embedding(question: str):
# Azure OpenAIの設定
aoai_api_key = os.environ["AZURE_OPENAI_API_KEY"]
aoai_endpoint = os.environ["AZURE_OPENAI_ENDPOINT"]
client = AzureOpenAI(
api_key=aoai_api_key,
api_version="2024-02-01",
azure_endpoint=aoai_endpoint
)
# テキストをembedding
response = client.embeddings.create(
input=question,
model="text-embedding-3-small",
dimensions=512
)
# ベクトル配列を取得
embedding_vector = response.data[0].embedding
print("質問のベクトル化---------------")
print(embedding_vector)
return embedding_vector
pineconeでのベクトル検索
ベクトル検索では検索の上位4件を取得するようにしています。
pineconeでのベクトル検索:query_search_pincone.py
import os
from pinecone import Pinecone
from dotenv import load_dotenv
load_dotenv()
def query_search_pinecone(vector: list):
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
index = pc.Index(os.environ["PINECONE_INDEX"])
result = index.query(
vector=vector,
top_k=4, # 4件まで取得
include_values=False, # values(ベクトル値)を含めるか
include_metadata=True # metadataを含めるか
)
print("pinecone結果-----")
print(result)
print(result['matches'][0]['metadata']['filename'])
return(result['matches'])
回答生成部分
gemini-1.5-proを使用して回答を生成し、returnするメソッドです。このコード内に、質問のベクトル化とpineconeでの検索も入っていますが、メソッドとしては別ファイルに切り分けています。今回はpineconeにはベクトル値・ユーザー名・ファイル名だけを保存しており、実際のスキルシートのテキストはプロジェクト内にtxtファイルとして保存しているものを呼び出す実装にしています。
回答生成部分:gemini_answer.py
import os
from dotenv import load_dotenv
import google.generativeai as genai
from service.aoai_question_embedding import aoai_question_embedding
from service.query_search_pincone import query_search_pinecone
# .envファイルの読み込み
load_dotenv()
# API-KEYの設定
GOOGLE_API_KEY = os.getenv('GOOGLE_API_KEY')
genai.configure(api_key=GOOGLE_API_KEY)
def gemini_answer(input: str):
# 質問のベクトル化
vector_list = aoai_question_embedding(input)
# 検索
search_result = query_search_pinecone(vector_list)
# 技術経歴書のテキストを読み込む
text_content = "# 指示\n以下の参考情報を参考に質問内容に答えてください。参考情報には名前とその人のエンジニアとしての経歴が書かれています。質問内容に関係のない人の情報は答える必要はありません。\n"
text_content += "# 参考情報\n"
for person in search_result:
file_path = f"skill_sheet/text/{person['metadata']['filename']}"
with open(file_path, "r", encoding="utf-8") as file:
text_content += f"## {person['metadata']['username']}\n"
text_content += file.read()
text_content += "\n"
text_content += "# 質問内容\n"
text_content += input
print(text_content)
# 検索結果をプラスして質問投げる→回答返す
gemini_pro = genai.GenerativeModel("gemini-1.5-pro-latest")
response = gemini_pro.generate_content(text_content)
return response.text
また、RAGでの回答精度を上げるためにプロンプトを構築しています。プロンプトについては以下のようなイメージとなるように構築されます。要は検索結果を「参考情報」、質問内容を「質問内容」として、回答してくれるような指示を与えるといった感じです。
回答生成用のプロンプト
# 指示
以下の参考情報を参考に質問内容に答えてください。参考情報には名前とその人のエンジニアとしての経歴が書かれています。
質問内容に関係のない人の情報は答える必要はありません。
# 参考情報
## 名前(→この名前の部分が検索にヒットした人分繰り返される)
### スキルと経験年数
- **プログラミング言語**:
### 工程ごとの経験年数
- **基本設計**:何年
- **詳細設計、開発**: 何年
- **単体試験**: 何年
- **結合試験**: 経験あり(具体的な年数は記載なし)
### 業種経験
- **金融系**:何年
- **通信系**:何年
### リーダー経験
- 情報なし
### サブリーダー経験
- 情報なし
### 自己PR
PR内容。
# 質問内容
金融系に強いエンジニアを1人教えて。その人の強みについても教えて。
アプリの動作イメージ
実際の個人情報が入った画面は見せられないので回答時の画面を一部隠したものを下図に示します。

ちゃんと回答してくれて個人的にはそれなりに満足のいく出来になったと思います!
今回のアプリの実装では継続的に会話することはできません。継続的に会話ができた方が便利だとは思いますが、デモアプリということもありそこまでは実装していません。
アプリを動かせるようにしたい人向け
アプリを動かすためには主に以下が必要です。申し訳ないのですが、細かい部分は割愛します。
- 必要なpythonライブラリのインストール
→requirements.txtやインストールで実行したコマンドのメモを記載したlib_install_memo.txtを参考にしてください(一部動作に不要なライブラリが紛れているかもしれません、、) - AOAIのリソース作成
- pineconeの登録&インデックス作成
- pinconeのインデックスにデータを保存
- .envファイルに必要な環境変数を記載
利用コスト
最初の方で記載したようにgemini-1.5-proが期間限定で無料で使えたこともあり、コストがかかっているのはEmbeddingモデルのみです。しかしtext-embedding-3-smallは安いので、ある程度使ってからAzureのCostを確認しても0.05円しか使っていませんでした(下画像)。

最後に
細かいところ説明できてない部分もありますが、同様のサービスを使ったRAG構成を作る際に参考になる部分もあるのではないかと思います。最低限RAGとしての精度を出すためにテキスト化の部分やプロンプトの部分で工夫したところもありますので、そのあたりも参考になれば幸いです。
Discussion