dbt
まず、dbtの前提は「ELT」です。ETLなデータ前処理には対応していません。今日のDWHはパワーがありますので、先にDWHにロードを済ませてしまい、変換処理はDWH上で実施するという考え方です。
ですので、dbtの出番としては、「分析対象となるデータの抽出」「抽出したデータをDWHにロード」の2つが終わった後となります。要するに「DWHまでデータが持ってこれている状態」が前提ということですね。
dbt(データビルドツール)は、データアナリストやエンジニアがウェアハウス内のデータを変換することを可能にします。
エレベーターピッチより深く知りたいなら、かなり深く入る必要があります。dbtとは何か、エコシステムの中でどのような位置づけにあるのか、そしてどのように利用を考えるべきなのかを理解したいのであれば、この投稿がそれにあたります。
dbt and the modern BI stack
dbtのELTのThinkerにあたります。dbtはデータの抽出やロードは行いませんが、すでにウェアハウスにロードされているデータの変換を非常に得意としています。(一般的にはELTと呼ばれるもの)
ELTは最新の分析データベースとの相性がよく。現時点ではほとんどのデータ変換ユースケースは、外部レイヤーではなく、データベース内でより効果的に処理することができます。さらに計算機とストレージを分離することで、データ変換ジョブを別の場所で実行する理由はますます少なくなっています。
dbtは、ウェアハウス内で実行されるデータ変換ジョブの記述と実行を支援するツールです。dbtの唯一の機能は、コードを受け取り、SQLをコンパイルし、データベースに対して実行することです。
dbtはコンパイラでありランナーである
最も基本的なレベルでは、dbtはコンパイラとランナーという2つのコンポーネントを持っています。dbtは全てのコードを生のSQLにコンパイルし、設定されたデータウェアハウスに対してそのコードを実行します、これがユーザーとの対話の様子です。
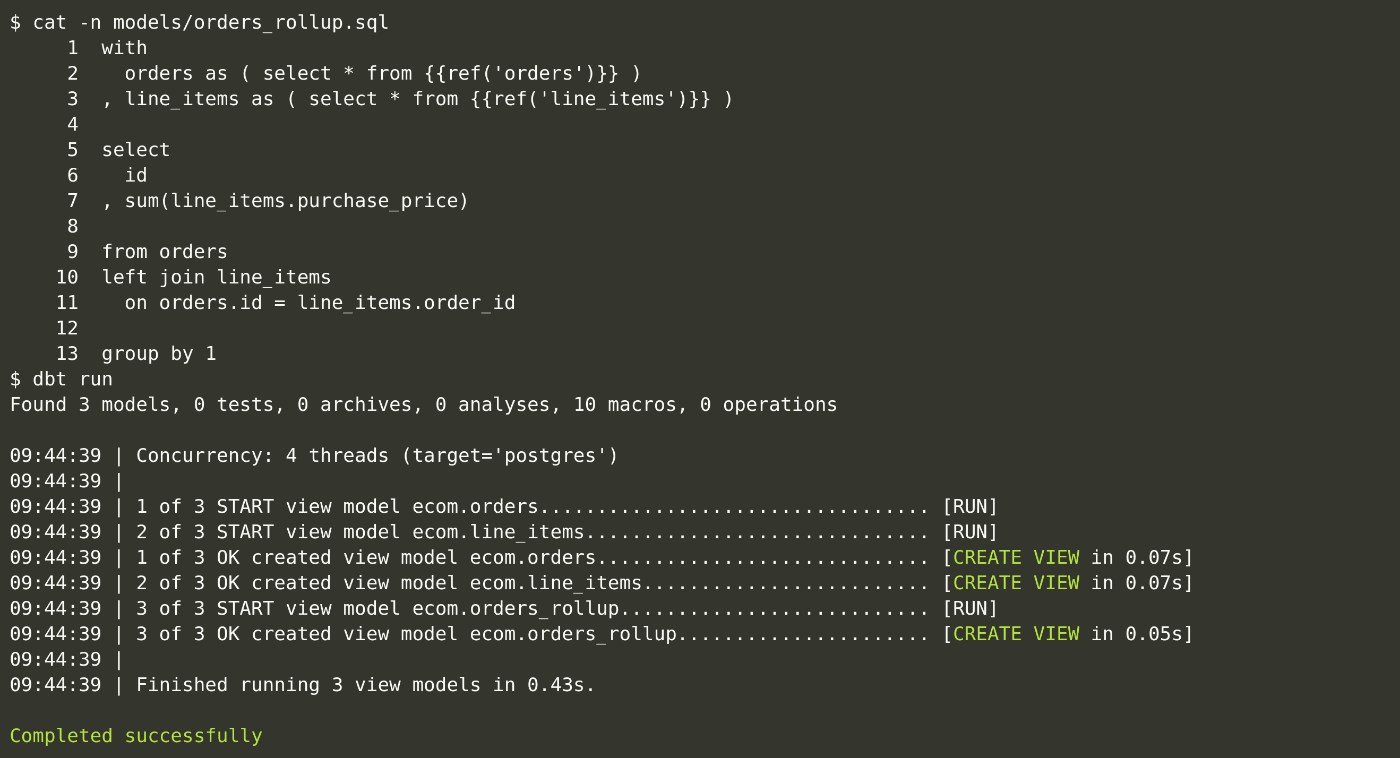
この例では、ユーザーがモデルのコードを表示し、そのモデルとその親を構築しています。この例では、各モデルがビューとして実体化されていますが、dbtはSQLで表現できる実体化ストラテジーをさぽーとしています。これらの用語を定義すると
モデル:単一のSELECT文で表現されるデータ変換
マテリアライゼーション:データモデルがデータウェアハウス内で構築される際の戦略。モデルはビュートテーブルにマテリアライズされるが、インクリメンタルロード、日付パーティションテーブルなど、多数の改良が可能である。
全てのモデルは正確に1つのSELECTクエリであり、このクエリによって結果のデータセットが定義されます。
with discounts as (
select * from {{ref('stripe_discounts')}}
),
invoice_items as (
select * from {{ref('stripe_invoice_items')}}
),
joined as (
select
invoice_items.*,
case
when discounts.discount_type = 'percent'
then amount * (1.0 - discounts.discount_value::float / 100)
else amount - discounts.discount_value
end as discounted_amount
from invoice_items
left outer join discounts
on invoice_items.customer_id = discounts.customer_id
and invoice_items.invoice_date > discounts.discount_start
and (invoice_items.invoice_date < discounts.discount_end
or discounts.discount_end is null)
),
final as (
select
id,
invoice_id,
customer_id,
event_id,
subscription_id,
invoice_date,
period_start,
period_end,
proration,
plan_id,
amount,
coalesce(discounted_amount, amount) as discounted_amount,
currency,
description,
created_at,
deleted_at
from joined
)
select * from final
この特定のモデルは、Stirpeの割引と請求書の関連付けを担当しています。このコードで純粋なSQLではないのは、冒頭のref()の呼び出しだけです。
dbtコードはSQLとPythonのエコシステムでよく使われるテンプレート言語であるjinjaの組み合わせです。ref()はdbtがJinjaのコンテキスト内で他のデータモデルを参照するためにユーザーに与える関数です。
ref()は次の2つのことを行います。与えられたモデルの適切なスキーマ.テーブルとして生のSQLに自分自身を補完します。与えられたdbtプロジェクト内の全てのモデルのDAGを自動的に構築します。
dbtは完全なJinjaコンパイラなので、Jinjaで表現できることはすべてdbtのコードで表現できます。if文、forループ、フィルタ、マクロなどなど。SQLはテンプレート言語と組み合わせることで、より強力なものになります。
dbtでは、Jinjaのコンテキスト内に関数と変数を追加することで、データ変換ロジックを簡単に表現することができます。以下は簡単な例です。
select * from {{ref('really_big_table')}}
{% if incremental and target.schema == 'prod' %}
where timestamp >= (select max(timestamp) from {{this}})
{% else %}
where timestamp >= dateadd(day, -3, current_date)
{% endif %}
このコードは、本番運用でインクリメンタルロードする場合、現在テーブルにある最新のタイムスタンプより新しい業だけを選択する。開発環境で実行する場合は、過去3日分のデータを取得するだけでよい。
このモデルは、現在の環境によって分岐する。データ量が多い場合には、有効に働く。
エンジニアはETLを書くな。
あなたのチームとデータサイエンティストの関係はどのようなものですか?がよく聞かれる質問らしい。
多くの企業では、エンジニアとサイエンティストの関係は、お互いの存在を全く認識できていない。まはた、非常に機能的ではない関係。
一般的なデータサイエンス部門
多くの企業では、データサイエンス部門を3つのグループに分けて構成している。
- データサイエンティスト
- 統計学者より優れたエンジニア、エンジニアより優れた統計学者。別名で思想家。
- データエンジニア
- データサイエンティストにデータを供給するパイプラインを構築し、データサイエンティストからアイデアを得て、それを実行にうつすひとたち。別名で実行者。
- インフラエンジニア
- Hadoopクラスタやビックデータインフラを保守する人たち。別名配管工。
データサイエンティストは、エンジニアが自分たちのアイデアを実用化するのに時間がかかり、作業サイクル、ロードマップ、モチベーションの不一致に不満を持つことがある。彼らのアイデアのバージョン1のA/Bテストが投入されるころには、2と3が待機しているようなことが起きる。
リードタイムが長いことにイライラするということ。
データエンジニアは、データサイエンティストが非効率的で不十分なコードを作成し、メンテナンスコストを度返し、非現実的な機能を要求して実装の労力を割かせ、ほとんど利益が出ないことにイライラする。
インフラエンジニアは、なんか知らんけどすごい負荷がかかってきたりするけど、利用者はそういうことよくわかってないので、つまり、辛い。
みんな辛い。
何が悪いのか?
規格が規格外、募集が誇大広告であること。データサイエンスやアルゴリズム開発チームも、同じような機能不全モデルに陥ってしまうのか?
2つの避難と2つの観察を提供する。
あなたはビッグデータを持っていないかもしれない
ビックデータの分野はこの5年間で大きく進化した。拡大するデータ量に対して、ほとんどのテクノロジーはニーズに合わせて簡単に拡張できるレベルまでに進化している。
使えるテクノロジーで可能なことの限界を超える必要がない限りは、これらのテクノロジー上にソリューションを構築するための専門的なチームは必要ない。もし、そのようなエンジニアを雇ったとしても、彼らは退屈してしまう、飽きたらビックテックに吸い込まれる。もし、彼らが退屈してないのであれば、かなり平凡なエンジニアである可能性が高い。平凡なエンジニアは非常に複雑で作業性の悪いものを作る。このような混乱は、専門性を必要とする傾向がある。
誰もが憧れる "考える人"
すごいアイデアを出して、そのアイデアを渡して実現する。そのような役割に憧れてる人は多い。
データサイエンティストに対して、このような役割であることを望んでいる人は多い。
それは、彼らがそれを望むように訓練してきたからです。(歴史的経緯)
従来のビジネスインテリジェンス部門は、3つの役割で構成されていた。
- ETLエンジニア
- ディメンションモデリングで頑張る
- レポート開発者
- Microstrategyなどのツールでレポート設計をしている
- DBA
- がんばる
ここで重要なことは、ETLエンジニアもレポート開発者もDBAもみな「Doer」なのです。
Doerとは実行者のこと。
10年ほど前のビックデータやデータサイエンスがバズワードになり始めた頃、老舗のBI部門にはDoerがたくさん居て、Thinkerが足りなかった。そこで「考える人」を役割にした。データサイエンティストには、データをいじくりまわして、ビジネスの流れを変える能力を約束し、既存のBI部門と融合させた。
現実にはそんなことは起きなかった。データサイエンティストは、時折、非常にクールなソリューションを生み出すおともありますが、大抵はビジネスに戻って、少しむずかしいレポーティングデベロッパーをするだけになる。
しかし、その役割はとても魅力的で、採用も簡単です。こうして、データサイエンティスト(レポートデベロッパー、別名「思想家」)、データエンジニア(ETLエンジニア、別名「実行者」)、インフラエンジニア(DBA、別名「配管工」)という、伝統的かつ現代的なデータサイエンス部門が誕生したのである。
おっと、ビジネスインテリジェンス部門はHadoopクラスターを追加して新しい名前で呼ぶようになっただけで、実際には何も変わっていなかったようです。
それは本当に悪いことですか?
実のところ、何を達成したいかによる。もし、上記の議論を受け入れるなら、BIの出現依頼、何年も何年も企業がそれでやってこれたことを受け入れる必要がある。
しかし、データサイエンスチームにパワーポイントのデッキやダッシュボードを作る以上のことをさせたいのであれば、これは非常に非効率的である。
ThinkerとDoerのモデルがその募集の誇大広告に応えることを妨げる根本的な欠陥は、データ科学者のアイデアやビジョンを熱心に実装する、魂のない中庸ではないDoerエンジニアの軍隊が存在すると仮定することです。あなたの知っている優秀なエンジニアのプロフィールに似ていると思いませんか?
このモデルでは、Doerは他人のアイデアの実装、失敗、サポートに対してのみ責任を負う。Thinkerは成功に対して報酬を得ます。このことがチーム間の争いやズレの核心となる。これはエンジニアチームというよりは、ITグループを作り出す。
有能なエンジニアをそのような役割に惹きつけるには、本当に大きなスケーリング問題が必要です。それは、あなたが彼らを雇った魂のない従属的な役割の気晴らしとなるものです、ビックデータの存在が生み出すような問題が必要なのです。しかし、あなたにはビックデータがありません。
その代わりに、平凡なエンジニアを雇って地獄になる。
その結果、データサイエンティスト地0無は強固で革新的なデータプラットフォームのサポートを受けられず、単なる報告書作成者に過ぎないということになる。そして、もし、リクルートが彼らにレポートデベロッパーの役割を売り込んだとしたら、彼らは反対側に走ったでしょう。結局のところ、彼らは考える人であって、実行者ではない。
これまでとは違うデータサイエンス部門のあり方
データサイエンス部門の目標は、情報提供することではなく、むしろ導くことであると考え、私が考えるデータサイエンス部門を構成するためのより良い方法を提案したいと思います。
それは役割、自律性、生産に至るまでの真のオーナーシップ、そしてアウトプットに対するアカウンタビリティを可能にする方法です。この方法はビジネスとデータが急速に進化している企業に適しています。
以下は、データサイエンスチームを構築するための青写真です。このチームは、直感や勘を頼りにパワーポイントを使って必死にプレゼンテーションするのではなく、思想的リーダーシップ、API、コードの作成を通じて、イノベーションを先導し、迅速に対応することができるのです。
誰もが世界一になれるようにする
役割に関係なく、優秀な人とそうでない人の根本的な違いは、独創的でありたいという願望と才能にあります。平凡な絶対に困惑するような問題を特定し、独創的に解決することができます。彼らは自律性、所有権、集中できる環境を得意とし、それを切望している。
サイエンティストからエンジニアへの組立ラインのハンドオフは、これとは正反対の環境を生み出す。(実は考える人でさえ、実行する人に頼らなければならないことに腹を立てている)。そのためには、関係者が自立、所有、集中できるような環境を作る。
しかし、エンジニアとデータサイエンティストは、全く異なるタスクに集中していることを認識することが重要です。
データサイエンティスト
データサイエンティストは、ビジネスと垂直方向に連携した問題に取り組むことが好きで、その努力によってプロジェクト/組織の成功に大きな影響を与えます。ある物事やプロセスを最適化したり、ゼロから何かを作り上げたりします。これらの問題はポイント指向であり、その解決策もまた同様です。このような問題には、ビジネスロジック、物事の進め方の再構築、そして創造性が大きく関わってきます。そのため、ビジネスの特定の部分がどのように運営されているかを深く理解し、ビジネスバーティカルと高度なパートナーシップを築くことが必要とされます。
"ビジネスの特定の部分がどのように運営されているかを深く理解し、ビジネスバーティカルと高度なパートナーシップを築くことが必要とされます。"
エンジニア
エンジニアは、抽象化、一般化、そして必要とされる場所で効率的な解決策を見つけることに優れています。これらの問題は、通常、水平方向に向かう性質を持っています。広く応用することで、最も大きなインパクトを与えることができます。しかし、抽象化されたソリューションであるため、ビジネスロジックが少なく、ビジネスにおける垂直的な関係や深い理解は必要ありません。
"抽象化されたソリューションであるため、ビジネスロジックが少なく、ビジネスにおける垂直的な関係や深い理解は必要ありません。"
ハイブリッドな思考者-実行者
データ領域のエンジニアがよく恐れるのは、職務内容や募集要項がどうであれ、密かにETLエンジニアを募集していることです。ご存知ないかもしれませんが、データパイプラインやETL作成と保守を好む人は居ない。この業界は究極のホットポテト。ETLエンジニアの職務の凡庸さの典型的な温床であることは、驚くことでは有りません。
エンジニアはETLを書くべきではありません。神聖な職業である以上、ETLを専門的かつ特殊な役割とするべきではありません。ETLを書き、維持し、修正し、サポートすることほど、魂を奪われることは有りません。
その代わり、自分が作成した仕事のエンドツーエンドのオーナシップ(自律性)を与えましょう。データサイエンティストの場合は、それはETLのオーナーシップを意味する。また、データ分析とデータサイエンスの成果に対するオーナーシップも意味します。また、データ分析とデータサイエンティストの多くの努力の裁量の結果は、人間ではなく機械の消費者のために作られた青果物である。それはレポートやダッシュボード、パワーポイントのプレゼンテーションではなく、エンジニアリングスタックに統合されたある種のアルゴリズムやAPIであり、ビジネス運営を根本的に変えるようなものである。
自律性とは、データサイエンティストがそのコードも所有することを意味します。本番環境に至るまで、エンジニアの許可を得ずに開発・デプロイし、サポートに責任を持ち、パフォーマンス、レイテンシ、SLAなどの要件を満たす必要があります。
このように、データサイエンティストには垂直的な責任と焦点が与えられているのです。しかし、データサイエンティストは、一般的に古典的な訓練を受けたり、高度な技術を持つソフトウェアエンジニアではありません。せいぜいその程度といえるでしょう。ですから、彼らが大混乱を引き起こすと予想されます。
これが、ETLやAPIやプロダクションアルゴリズムの開発が、一般的に組立ラインスタイルでエンジニアに渡される理由の一つです。しかし、それらの作業は全て、本質的に垂直方向に焦点をあてたものです。データ領域で有能なエンジニアは殆どの場合、水平方向アプリケーションに集中するのがベスト。
では、この新しい水平方向の世界でのエンジニアの役割とは何でしょう。要約するとエンジニアはデータサイエンティストが自律的にアイデアを考え、開発し、展開できるようなプラットフォーム、サービス、抽象化、フレームワークを配備する必要がある。
エンジニアは新しいレゴブロックを設計し、データサイエンティストはそれを独創的な方法で組み立てて、新しいデータサイエンスを生み出す。言うのは簡単ですが、実際に行なうのは難しいです。
エンジニアの仕事は、完全に水平方向で行なうことができます。これにより、複数のデータサイエンスの問題に広く適用できる技術の構築に集中することができます。これにより、エンジニアリングの成果を最大限に活用することができます。データサイエンス部門には、エンジニアよりもデータサイエンスの方がはるかに多いでしょうから、これは素晴らしいことです。
しかし、これを実現するには、エンジニアがデータサイエンティストのニーズを予測する必要があります。何歩も先を見据えた開発が必要なのです。
優秀でクリエイティブなエンジニアとデータサイエンティストにとって、それはとんでもなく楽しいことなのです。
チャレンジングな道
こんなこと出来るのかと思うかもしれませんが、それを実行したリスクへの見返りは大きい。
ここで、進捗を妨げたり、後退させたりする可能性のある注意すべき点をいくつか挙げてみましょう。
人は変化を嫌う。
使い慣れた環境を再現したがる傾向があります。このため、「考える人-実行する人」モデルに戻そうとするプレッシャーが生まれます。新入社員は新しい体制に早く馴染む必要があります。特に、APIが壊れたり、アルゴリズムが悪い結果を出すなど、プロジェクトに問題が発生したときには警戒が必要です。
このような状況下では、人々は非常に反応的に行動する。「やっぱり前の方法にしよう」など。しかし、それは問題ではなく、症状に対処しているのです。エンジニアはより良いプラットフォームのサポート、可視化、抽象化、そして、レジリエンスを構築する必要がある。そして、エンジニアもまた物事を壊すのだということを認識するべきです。
プラットフォームエンジニアは、データサイエンスチームの先を行くことが絶対に必要なのです。どのようなサービス・フレームワーク・機能がどうしても必要になる前に、直感的に判断できる、非常に鋭いプラットフォームエンジニアが必要なのです。サイエンティストからエンジニアへの引き継ぎがないため、エンジニアはサイエンティストから出された要件に対応する余裕はありません。
エンジニアがレゴブロックを作り、データサイエンスチームがそれを組み立てていることを思い出してください。もし、データサイエンスチームが組み立てるべきブロックを持っていなければ、彼らはそれでも解決策を生み出すために邁進するでしょう。彼らは間違ったブロックを組み立てたり(丸い穴に四角い釘)、独自のブロックを作成して、無理やり解決するでしょう。通常彼らは大混乱を引き起こします。一度作ったものをもとに戻すのは難しい。
非効率を恐れない
データサイエンティストにこのような幅広いスタックを担当させると、エンジニアと同じように技術的に効率的なコードやソリューションを生み出すことができなくなります。私たちは、速度と自律性のために、技術的な効率を犠牲にしているのです。これは意図的なトレードオフであると認識することが重要です。
しかし、エンドツーエンドのオーナーシップによって得られる、あまり目立たない効率化もあります。データサイエンティストは、自分たちが作成する実装の分野の専門家である。そのため、技術コストやサポートコストと要求事項との間でトレードオフを行うことができます。例えば、特定の場所でデータをサンプリングする、近似的な手法を使用する、ビジネスへの影響はわずかであるが開発コストやサポートコストが非常に高い機能は使わない、といった判断が可能です。このようなことは、科学者とエンジニアの間で行われる組立式モデルにおいてはめったに起こらない(起こったとしても、通常は多くの交渉を必要とする)ことである。
全体として、データサイエンティストが自分のフルスタックを所有できるようにすることで、自律性のメリットとその結果として生み出されるイノベーションが、技術的な専門性の欠如による非効率性を上回ると期待されているのである。
dbtを初見で見た時は、何が便利なのかすぐには分からなかったけど、触ってみたらすごいよかった。
データ品質
dbtの最も優れた点は、同じコードを何度も書き直す必要がないところ。一度書いたモデルを他のモデルで参照することができる。全てのモデルで同じロジックを使用するため、より信頼性の高いコードを作成することが出来る。
分析に便利な一方で、企業の重要KPIにも利用できる。この指標を定義し、計算する方法は1つであるべきです。しかし、実態として、このようなKPIは同じようなSQLが散らばって異なる計算がされることが多い。
dbtはコードをモジュール化することで、再度書き直す必要がない。これによってデータ品質を高めるだけではなく、アナリストにとってもっとやるべきことへコストをかけれるようになる。
dbtのもう一つのデータ品質向上に一役買っているのが、ソースで直接キャストやリネームを行なうことを推奨すること。これはドキュメントで詳しく説明されている。
基本的には小さなデータの「ハウスキーピング」タスクはすべてのベースモデルで行なう。ベースモデルとは生のソースから直接選択するモデルのこと。そして、他のモデルは生データではなく、これらのベースモデルのみを山陽する。こうすることで、日付を間違って2種類のタイムスタンプにキャストしてしまったり、同じカラムに二種類の名前をつけてしまうといったエラーが起きなくなる。
スピード
基本データモデルと中間データモデルを整理することで、コアデータモデルの実行を大幅に高速化できる。
また、モデルはモジュール化されているため、一度実行すれば、他のモデルで参照できる。同じコードブロックを何度も実行するような無駄な時間とリソースを費やすこともない。
また、dbtのモデルはdbt runで並列実行される。(依存関係はもちろん考慮される)
これによって、スループットが向上し、実行時間が最短になる。またモデルはマルチスレッドと呼ばれる手法で並列実行sれる。事あるモデルは異なるスレッド実行されるため、一緒に実行できる。
dbt_project.ymlファイルにthread: 300とあるのは、同時に実行させるモデルの数を示しています。
ドキュメンテーション
ドキュメンテーションは、アナリティクスとデータモデルの世界において、最も過小評価されている差別化要因のひとつ。データをうまく文章化されているかによって、その有用性が決まる。
ドキュメントは新しいメンバーへのオンボーディングをスムーズにするだけではなく、チーム全員がデータをより深く理解できるようにする。
アナリティクスを正しく行っていれば、データに対して常に質問を投げかけているはずで、そのときにdbtのドキュメントがあれば、その答えを提供することが出来る。何年も働いていれば、たまにデータ定義を参照する必要があります。データに関するデータは多いに越したことはない。
この2つのコマンドを実行すると、ローカルサイトが作成され、閲覧することができる。
dbt docs generate
dbt docs serve
dbtプロジェクトの解剖学
profiles.yml
dbtがデータウェアハウスに接続するためのコネクション情報が含まれる。このファイルについては、dbtをローカルでセットアップする場合にのみ心配する必要がある。
このファイルには、プロジェクト名やデータベース認証情報などの機密情報が含まれている可能性があるため、dbtプロジェクト内には存在しません。デフォルトでは ~/.dbt/. になる。
プロジェクトをゼロから始める場合、dbt initを実行すると、このファイルが生成される。そうではない場合は、.dbtフォルダとprofiles.ymlファイルをローカルに作成しなければいけないかもしれない。
ローカルで複数のプロジェクトで作業する場合、異なるプロジェクト名(dbt_project.ymlファイルで設定)を使用すると、他のプロジェクト用に様々なプロファイルを設定することが可能になる。
dbt_project.yml
このファイルは、プロジェクトのメイン設定ファイルです。プロジェクトを作成する場合は、プロジェクト名とプロファイル名を変更します。(できれば同じにする)
また、モデルのセクションのmy_new_projectを新しいプロジェクト名で置き換えてください。
このプロジェクト内の全てのオブジェクトは、モデルレベルでオーバーライドされない限り、ここで設定された設定を引き継ぎます。これによって、何度も同じことを書かないで済む。
models
ロジェクト内のすべてのデータモデルが含まれます。このフォルダの中では、好きなフォルダ構造を作ることができます。
dbtの推奨しているスタイルガイドはこれ。
ここでは、modelsの下にmartsとstatgingのフォルダがあります。異なるデータソースはstagingの下に別のフォルダがあります。ユースケースや部門はmartsの下に別のフォルダを持ちます。
上の例では、.ymlと.docファイルに注目してください、これらはモデルのメタデータとドキュメントを定義する場所です。dbt_project.ymlファイルには全てを記述できますが、それぞれで定義した方がよりスッキリします。
data
このフォルダには、dbtによってデータベースにロードされる全てのマニュアルデータが含まれる。読み込むにはdbt seedコマンドを実行する必要がある。
バージョン管理されたリポジトリなので、あまりに大きいファイルや機密情報の入ったファイルは置かないようにしましょう。
macros
dbtのマクロはexcel関数に似ている。macrosフォルダにカスタム関数を定義したり、デフォルトマクロやパッケージのマクロを上書きすることも出来る。
マクロはJinjaテンプレートと一緒に使うことで、SQLでは利用できない多くの機能性を得ることが出来る。
-- This is hard to read
(amount / 100)::numeric(16, 2) as amount_usd
-- This is much easier
{{ cents_to_dollars('amount') }} as amount_usd
packages.yml
dbtの素晴らしい点の一つに、他の人が作ったパッケージを簡単に使えるという点。これにより車輪の再発明が減らせる。
書き方。
packages:
- package: dbt-labs/dbt_utils
version: 0.7.3
パッケージを使用する前に、dbt deps を実行して、これらの依存関係をインストールする必要はある。
snapshot
スナップショット機能がサポートされている。
tests
上記の例では、dbtテストを実行すると、dbtはorder_idがユニークでnot_nullであるか、statusが定義された値にあるか、customer_idのすべてのレコードがcustomersテーブルのレコードにリンクされているかどうかをチェックします。
しかし、時には、これらのテストでは十分ではなく、カスタムテストを書く必要があります。そのような場合は、tests フォルダにカスタムテストを保存します。行が返されなければテストは成功し、少なくとも1つ以上の行が返されれば失敗します。
dbtとアナリティクスエンジニア - 何を騒いでいるのか?
Best practice workflows
Version control your dbt project
dbtプロジェクトはバージョン管理しましょう。masterへマージする前にレビューしましょう。
Use separate development and production environments
targetを使うことでほんb何環境と開発環境を分けて管理することが出来ます。
Shopify事例
profile.yml
認定試験
forloop
SELECT
{% for item in list_of_items -%}
{{item}}
{%- if not loop.last -%}
,
{%- endif %}
{% endfor -%}
変更があったモデルだけをテストする
dbt run -m state:modified+ && dbt test -m state:modified+
jinja live parser
普段使っている技術スタックで、コードが書けるもの。
Photobox the ETL developer function is part of the data engineering team, therefore we wanted to come up with a tech stack that would allow:
Data engineering writing code rather than using a drag & drop tool
Analysts make use of the same tech stack, so data engineers could easily deploy their models in the reporting data layer, but especially, in order to have data lineage and documentation in the same place.
組織によってアプローチ方法はいろいろ
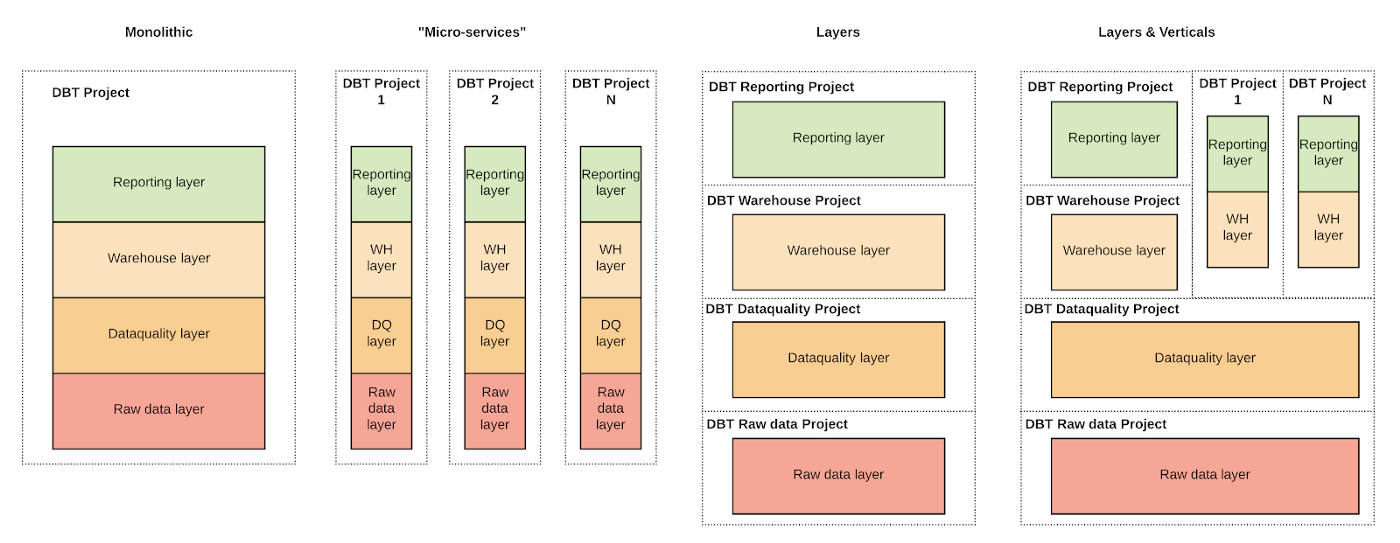
RAW Layer: No transformations and cleansing applied to the data. Available as soon as data is ingested but likely to have poor usability and performance.
DATA-QUALITY: Quality rules are applied. Data is in a tabular format cleaned and ready to be consumed. No data modelling is applied. Data not immediately available after ingestion since some processing is required.
WAREHOUSE: Where facts and dimensions are built. Due to the complexity tables in this layer are refreshed less frequently than the previous layers.
REPORTING: Contains optional further aggregation on the top of the warehouse. These tables are optimised to serve some specific reports faster than tables in WAREHOUSE but are less flexible.
従来のデータウェアハウスの手法の見直し。
過去はサロゲートキーに数値を使う傾向があった。理由は結合が速いこととキーとビジネスロジックを切り離すため。
従来はインクリメンタルな数値を生成しディメンションの集計を実行した後に、ファクトにに追加していた。
しかし、現代の列指向データウェアハウスでは、この戦略は良い手ではない。
更新操作にコストがかかる上、自動インクリメントがサポートされてないDWHがあり、ベンダーロックインなモデリングになる。
これの回避策としては、複数のフィールドの結合によるハッシュとしてのサロゲートキーの生成。
dbt makes you rethink some aspects of traditional data warehousing
In traditional data warehousing, there is the tendency to run your dimensions first and then your facts. One of the reasons for that is that joins are normally performed on surrogate keys instead of natural keys.
This is done both for performance reasons (join on a number is faster) but also to decouple the key from the business logic.
Traditionally these keys were generated as incremental numbers and added into the fact after the dimensions run was finished.
In modern column-oriented data warehouses, this strategy doesn’t work incredibly well.
Update operations are sometimes expensive and autoincrement is not widely supported or requires some workarounds.
With dbt there is the possibility to generate surrogate keys as the hash of the concatenation of multiple fields, as shown in the Fig-2.
dagを細かく切って再実行の単位を小さくする。
Compared to the entire project data lineage, this seems easier to understand and small enough to rerun in case of failure.
In Photobox we decided to orchestrate dbt sub-DAGs using Airflow.
Using external orchestration we can have better control over what we run. This allows us to rerun only part of the process that didn’t succeed without wasting computational resources.
Each pipeline we built is idempotent and can be re-executed anytime, assuming that all its dependencies are satisfied.
Also, breaking down a dbt project in multiple Airflow tasks, allows more flexibility on how to use Snowflake virtual warehouses. Different dbt sub-Dags can run on different virtual warehouses depending on the computational resources required.
ドキュメントのホスティング
Install dependencies
Build dbt docker image
Test dbt docker image
Upload dbt docker image on ECR
Create/Update ECS Task definition
Generate dbt documentation
Upload dbt documentation (S3)
サロゲートキーの生成
dbtのステップがわかりにくいやつの対策。
一つ一つ指定することになる。まあそれはそう。
backfill
Redshift
あなたはデータを扱う仕事をしていますか?dbtは、エンジニアやアナリストが簡単なSQLでデータ変換を定義できるようにすることで、「データチームがソフトウェアエンジニアのように働けるようにする」ことを目的としたツールで、ご存知の方も多いかと思います。
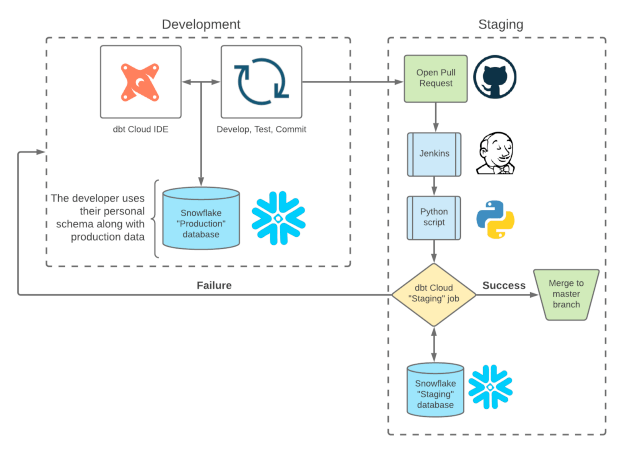
ローカルでの開発は、それ用のスキーマを作成する。
{% macro generate_schema_name(custom_schema_name, node) %}
{# if this model is created in prod or staging, use the schema designated in dbt_project.yml #}
{% if target.name == 'prod' and custom_schema_name %}
{{ custom_schema_name | trim | upper }}
{% elif target.name == 'staging' and custom_schema_name %}
{{ custom_schema_name | trim | upper }}
{# else, if this is created in dev, use the default (user) schema #}
{% else %}
{{ target.schema | trim | upper }}
{% endif %}
{% endmacro %}
CI流す時は、データをサンプリングする
{% macro dev_limit(sample_size=1000) -%}
{%- if target.name == 'prod' -%}
--if running in prod environment, run with all the records
{%- else -%}
--SAMPLE ({{ sample_size }} rows only to speedup dev/testing
SAMPLE ({{ sample_size }} ROWS)
{%- endif -%}
{%- endmacro %}
CIを早くする
つまり、サンプリングすればよさそう。
dbt staging bestpractice
dbt hands on
dbt example
サンプルプロジェクト
backfillコード
それぞれのレイヤーについて
dbtのユースケース別の記事
Slim CI
group by 1
gitlab
incremental
dbt tonic
cofiguration
- make
- snowflakeにアクセスできる
- home dirに.dbtフォルダを作成して、そこにプロファイルを作成して作業
- これらはonborlingスクリプトで行われる
profileとかをローカルに持ってきてるっぽい。
mkdir ~/.dbt
touch ~/.dbt/profiles.yml
curl https://gitlab.com/gitlab-data/analytics/raw/master/admin/sample_profiles.yml >> ~/.dbt/profiles.yml
これをzshrcに書くのなるほどだな
echo "export SNOWFLAKE_TRANSFORM_WAREHOUSE=ANALYST_XS" >> ~/.zshrc
echo "export SNOWFLAKE_LOAD_DATABASE=RAW" >> ~/.zshrc
echo "export SNOWFLAKE_SNAPSHOT_DATABASE='SNOWFLAKE'" >> ~/.zshrc
echo 'export PATH="/usr/local/opt/gettext/bin:$PATH"' >> ~/.zshrc
echo 'export RUBY_CONFIGURE_OPTS="--with-openssl-dir=$(brew --prefix openssl@1.1)"' >> ~/.zshrc
echo 'setopt nomatch' >> ~/.zshrc
Choosing the right Snowflake warehouse when running dbt
出来るだけ小さいウェアハウスでやってるっぽい。
大きくしたいなら、妥当性を検証しましょうってやつ。
大きい小さいやつを切り替えるのには、targetで切り替える。
gitlab-snowflake:
target: dev
outputs:
dev:
type: snowflake
threads: 8
account: gitlab
user: {username}
role: {rolename}
database: {databasename}
warehouse: ANALYST_XS
schema: preparation
authenticator: externalbrowser
dev_l:
type: snowflake
threads: 16
account: gitlab
user: {username}
role: {rolename}
database: {databasename}
warehouse: ANALYST_L
schema: preparation
authenticator: externalbrowser
dbt run --models @{model_name} --target dev_l
Sources
生データは、RAWデータベースに格納する。命名は、元のデータソースを示すスキーマ名が使われる。(ex: salesforce)
meta tag
The complete guide to building reliable data with dbt tests
incident level
dbt unit test