組織論
データチームは中央集権型と組み込み型のどちらで運営すべきなのか?
チームによっては、中央集権的であることが望ましい場合がある。
例えば、データエンジニアは、データパイプラインやツールの改善など、共通の目標に取り組むことで利益が得られる。つまり、水平方向に仕事した方がバリューが出る。
事業目的との不整合リスクは考慮した方がいい。
一方で、データアナリスト、データサイエンティスト、アナリティクスエンジニアについては、考える必要がある。
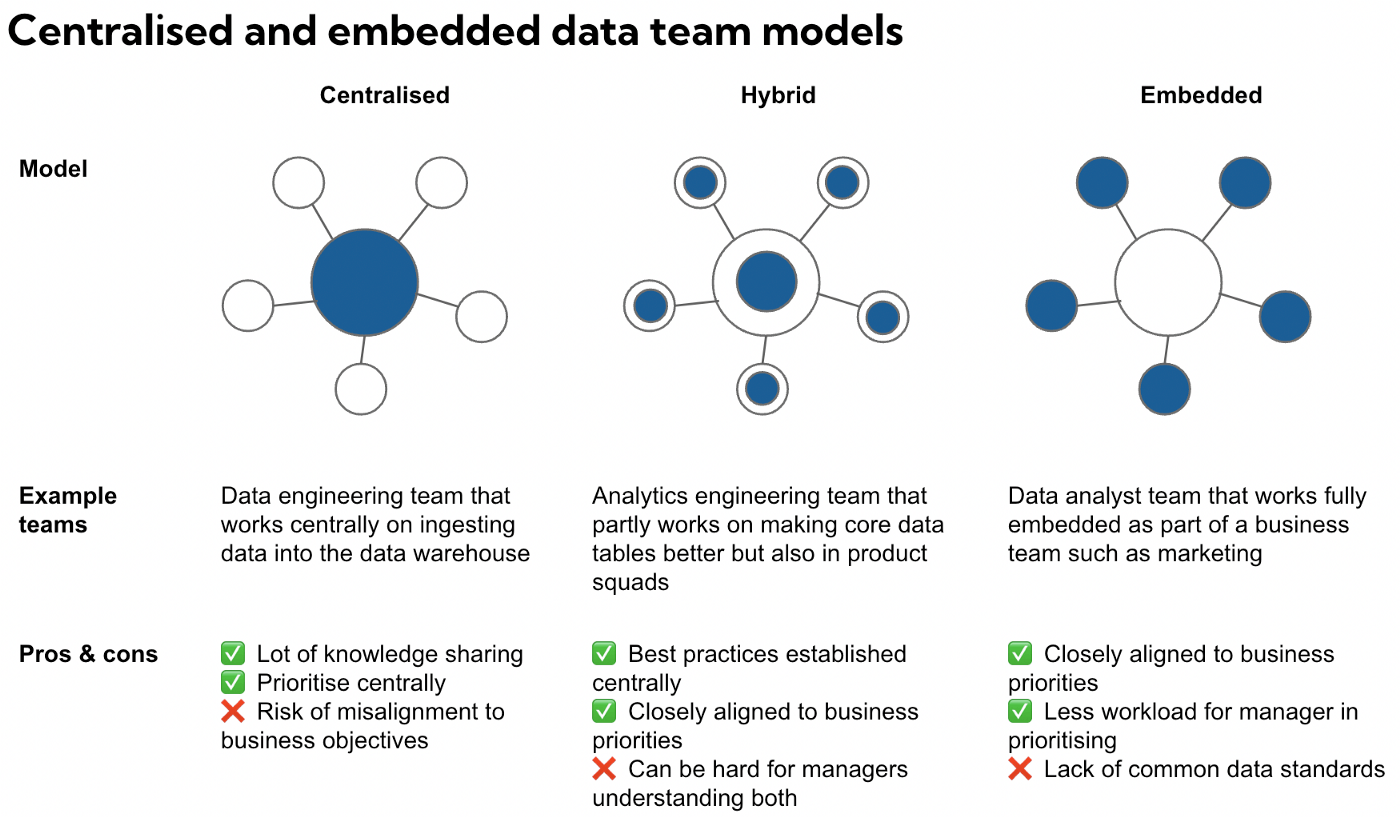
常に同じ形はうまくいかない。
例えば、データの品質が担保できていない時期は、集中的に中央集権的に運営した方がいいかもしれないし、データチームとビジネスがうまく認識が擦り合ってない場合は、分散化し密にコミュニケーションが必要かもしれない。
ほとんどの場合、この2つのモデルを交互にやっていく必要がある。
データのチーム編成は技術的課題でもある。
データの次の大きな課題は組織的である。 by Bryan Offutt
ありエンジニアがバックエンドのマイクロサービスへの変更を加えた結果、ダッシュボードがおかしくなる。よくある話しですが、バックエンドコードを直すのに5分で済むのに対して、データは数日かかって直すことになる可能性がある。

大規模なデータチームが数十のビジネスチームやプロダクトチームにまたがっているようなスケールアップ企業では、データの問題が発生したときに何が起こったのかを明らかにすることは、干し草の山の中から針を探すようなものです。
残念ながら、データチームが費やす時間の30%以上は、新しいインサイトを発見したり、目標を前進させたりするのではなく、このような作業に費やされていることを意味します。
データチームの適切なコンステレーションとは
大規模なデータチームでは、データエンジニア、分析エンジニア、データアナリスト、データサイエンティスト、機械学習エンジニアの何らかの組み合わせで構成されていることが多いようです。

それぞれの適切な比率とは
他の人の生活を楽にするために働く人(=データエンジニア)とKPIを推進するために働く人(=データサイエンティスト)の比率のバランスをとることの重要性。
経験則で、データエンジニアが100人のdbtユーザーに対してdbtを10%速くする変更を加えることが出来ても、それを優先することができなければ、恐らくデータエンジニアは足りてない。
データサイエンティストがアドホックなリクエスト振り回されていて、潜在的なROIの高い仕事を放置しているなら、もっと雇う必要がある。
いくつかの組織の比率。
How to think about the ROI of data work
1人を採用した時のROIの見積もり。
Mode AnalyticsのBennは、分析を完了するまでの時間が最良の尺度であると考えている。

すべてのROIが同じように作成されるわけではない
データ担当者は、アウトプットではなくインパクトに焦点を当てる。重要なKPIと連携し、データの外の世界を忘れないようにすべき。
データチームは、5つの役割がある。
左に行けばいくほど、システムに近く、右に行けばいくほどKPIに影響を与える役割になる。

Ƞ度と呼ぶ概念について考えてみましょう。Ƞは、トップレベルのKPIに影響を与えるまで何度離れているかを表します。
この概念を具体的に説明するために、いくつかの例を挙げます。
Ƞ = 0
0️⃣ 機械学習サイエンティストが不正を減らすモデルを出荷する → 0
💲💲💲
Ƞ = 1
0️⃣ データサイエンティストがサインアップ率を向上させるためにA/Bテストを実行する→ 󠄁 1
1️ȃ エンジニアが変更を実装する→→。
💲💲💲
Ƞ = 2
0️⃣ アナリティクスエンジニアがA/Bテスト用のデータモデルを改善する → ゙゙゙゙
1️⃣ データサイエンティストがA/Bテストを実行する→→。
2️⃣ エンジニアが変更を実行する → ⃣ エンジニアが変更を実行する
💲💲💲
Ƞ = 3
0️⃣ データエンジニアがdbtを改善する→→。
1️⃣ アナリティクスエンジニアが...を改善する→→。
2️⃣ データサイエンティストが...→→→。
3️ȃ エンジニアが... →→→。
💲💲💲
右にいけばいくほどに、仕事はトップラインKPIに直接影響を与える。左にいけばいくほど、下流のデータ消費者を効率的にすることでインパクトを与える。
Good work, bad work
機械学習サイエンティストがメトリックを所有することが良いことである理由
インパクトを最適化し、費やした時間を最小にする。
さっさと調べて、さっさと実装できる状況に持っていくと彼らはバリューが出せる。

左へ一歩踏み出す
機械学習サイエンティストは、1人のデータサイエンティストが使用するセンチメントモデルを構築している。機械学習サイエンティストから1度外れている。

KPIから遠いと価値がないのか?そうではない。
少数のエンドユーザーを担当するアナリティクスエンジニアが問題になりそうな理由
アナリティクスエンジニアがあるデータモデルを使いやすくする。このデータモデルは1人のデータサイエンティストの仕事を10%速くする。

ここまではいい。あなたの仕事は、誰かの生活を便利にしました。あなたは明らかにエンドユーザーを念頭に置いていましたし、製品チームはKPIに向かって作業しています - これらはすべて良いことです。
しかし、あなたの仕事は一人にしか影響を与えず(🎳 = 1)、あなたの仕事の時間コスト(⌛️)は高いです。これはインパクトのある仕事でしょうか?1週間かけたらそうかもしれません。1ヶ月かけたら、おそらくそうではないでしょう。
もしあなたが、自分の仕事の影響度を測るのが難しく、自分の仕事の恩恵を受けるデータ利用者の数が少ないデータ業務に就いているとしたら、最も影響力のある問題に取り組んでいるかどうか考えてみてください。
このアナリティクス・エンジニアは、他にどのように時間を使うことができたでしょうか。
規模に応じたアナリティクスエンジニア
あなたはアナリティクス・エンジニアで、5人のデータサイエンティスト(🏥)が毎日使うコアデータモデルを📎=10%使いやすくする。あなたは、前の例と比較して、5倍スケールしたことになります。

もしあなたがシステム担当者なら、自分の仕事が川下の消費者にどのような影響を与えるか(📎)、何人の消費者がいるか(🎳)、どれだけの時間を費やしているか(⌛)を常に評価しましょう。
データツールに投資すべき理由
あなたはデータエンジニアで、データチームの全員がdbtを5%高速化することができます。アナリティクスエンジニアは、より速く作業し、より多くのデータモデルを改善できるようになりました。データサイエンティストとアナリストは、より高品質のデータモデルから恩恵を受け、製品チームはより多くのアイデアを実装することができます。

5人のアナリティクス・エンジニアと15人のデータ・サイエンティストの生活を向上させたことになるのです。dbtのパフォーマンスを5%向上させただけで、大きなインパクトを与えたことになるのです。
では、システム担当者が常に最も大きな影響力を持つということでしょうか。そうとは限りません。すべては、冒頭で紹介した悪名高い方程式に帰結するのです。アナリティクス・エンジニアがデータモデルを改良して3人のアナリストの作業効率を30%向上させたとしたら、それはデータエンジニアが9人のdbtの速度を10%向上させたのと同じ価値があるのです。このように説明すると分かりやすいのですが、私の経験では、データチームがこのように考えているとは限りません。
私が働いているMonzoでは、システム担当者の行動をコアバリューとして体系化し、データチームの全員が役割を担っていると考えています。私たちはこれを「Act as force multipliers」と呼んでいます。
さて、グラフ理論を購入しました。さて、どうする?
すごい!こう考えるべき
システムズ・ピープル あなたの仕事の消費者の数を最大化すること(🎳)と、あなたの仕事が消費者一人一人に与える影響(📎)に焦点を当てる。
KPIな人。KPI担当者:自分とKPIの間のステップを減らし(Ƞ)、最もROIの高い機会に取り組む(💰)。
本当にエキサイティングなのは、上記の作業はすべて同じ方程式の一部であることです。KPI担当者がより高いROIの機会を選び、自分とKPIとの間のステップを減らすことができれば、システム担当者による上流作業のインパクトは比例して大きくなります。

さて、どうする?関係者に数式を見せたり、実際に数字を並べたりすべきでしょうか?おそらく、そうではありません。しかし、自分の仕事がどのようにすれば最も大きなインパクトを与えられるか、どのような糸を引くことができるかを考えるために、この式を利用することはできます。
誰もが役割を担っていることを忘れないでください。
データサイエンティストとデータアナリストは、高品質のデータと優れたデータモデルがあれば、より速く仕事をすることができます。アナリティクスやデータエンジニアは、自分のデータモデルが多くの人に利用されれば、多くの影響を与えることができます。
どういうロール、どういう責任範囲
攻めと守り
データ戦略
なぜデータリードは難しいか。
そもそも、ステークホルダー多いし、経営層がデータに詳しくないとか、色々・


- データチームリーダーの選定について
- ダッシュボード作成・分析重視のリーダーか、最新のデータスタック活用を重視するリーダーかの選択が重要
- T字型のスキルセット(幅広い業務経験と深いデータ分析・インフラの専門知識)を持つリーダーが理想的
- 理想的なリーダーの資質
- 楽観性:データの問題に前向きに取り組める
- 適応力:急速な変化に対応できる
- 技術的適性:データ分析、アーキテクチャの強い知識
- ビジネス感覚:業界理解力
- 自信と率直さ:健全なデータ戦略のために意見を述べられる
- オーナーシップ:責任を持って成果を出せる
- よくある誤解
- 経験重視の採用:データ分野は急速に進化しているため、古い経験よりも新しい技術への適応力が重要
- データサイエンティストやアナリストを最初に採用:基礎となるインフラ整備が先決
- 採用計画について
- まずはデータエンジニアリングから始めるべき
- その後、リードアナリストを採用
- 役割は柔軟に考え、組織のニーズに合わせて調整が必要
記事の著者のMarc Stoneは、データインフラの整備を優先し、その上でデータサイエンティストやアナリストを採用することで、より効率的なデータ活用が可能になると主張しています。
データ分析チームの主要ミッション:
- 実用的なデータ駆動型インサイトの提供
- データサイエンスタスクの自動化
- 製品への高度な分析機能の組み込み
- ビジネスユニット間のセンター・オブ・エクセレンス(CoE)の構築
チーム構造の3つのモデル:
- 集中型(Centralized)
- 単一の中央チームがすべてのデータリクエストを処理
- チーム間のコラボレーションが容易
- 知識共有が簡単
- 分散型(Decentralized)
- 各ビジネスユニットが独自のデータチームを持つ
- 特定のユースケースに適している
- 並行して分析が可能
- ハイブリッド型(Hybrid)
- 中央チームがベストプラクティスを提供
- 柔軟なスケーリングが可能
- ガバナンスとビジネスインテリジェンスのバランスが取れる
各ポジションの要約:
- データアナリスト
- 平均年収:$73,000
- 主な責任:
- リアルタイムデータの可視化
- ダッシュボード作成
- データ分析システムの開発・実装
- 必要スキル:
- データベースツール
- データウェアハウスソリューション
- 統計ツール
- ビジネスドメインの専門知識
- ビジネスアナリスト
- 平均年収:$82,000
- 主な責任:
- ビジネス運営の分析
- ビジネスレポートの作成
- 非技術的なステークホルダー向けの報告
- 必要スキル:
- 問題解決能力
- 分析ツールの知識
- データモデルの理解
- ダッシュボード作成能力
- データエンジニア
- 平均年収:$135,000
- 主な責任:
- データセットの設計
- 予測分析
- データベース管理
- データ品質の最適化
- 必要スキル:
- SQL
- データウェアハウジング
- ETL/ELTプロセス
- Python
- 機械学習の基礎知識
- データサイエンティスト
- 平均年収:$121,000
- 主な責任:
- アルゴリズムの作成
- データモデルの最適化
- 新しい可視化モジュールの作成
- 必要スキル:
- 統計分析
- 機械学習
- ディープラーニング
- データ可視化
- プログラミング
- 数学
- Chief Data Officer / Head of Data
- 平均年収:$200,000 - $1,000,000
- 主な責任:
- データ戦略の立案と実行
- チーム憲章の設定
- データイニシアチブの優先順位付け
- アナリティクスロードマップの策定
- 必要スキル:
- 強いコミュニケーション能力
- マネジメントスキル
- 分析的思考
- データ駆動の意思決定能力
- データウェアハウスの知識
- ビジネス成果の説明能力