スロー・チェンジ・ディメンション(Slowly Changing Dimensions)
スタースキーマ(基礎) の記事の知識を前提としています。
ディメンションテーブルのソースとなるデータは、運用している業務システムのものである。これらのデータは、データウェアハウスに移され、それぞれのディメンションテーブルに格納される。
しかし、この情報は運用の過程で変更されることがある。例えば、会員の生年月日を直したり、住所変更などである。この時に運用システム側は、変更履歴を追うようにする。または素直に上書きしてもよい。いずれにしても、ディメンションテーブルは、どのように分析をしたいかによって、変更に対応することが必要になる。
ディメンションの設計において、ソースデータの変更をどのように表現するかを決めることは重要で、これらを「スロー・チェンジ・ディメンション」と呼ぶ。これはファクトに比べるとディメンションはゆっくりと変更されることから由来している。
データ変更がされた場合、様々な対応が考えられる。要件によっては変更履歴の保存に価値がないこともあるだろう。またはそれが重要なこともある。

図1
図1は、販売管理業務システムの顧客情報のレコードで、データの変更が発生したことによって、3つの異なる状態を示したものである。この業務システムでは、2回の変更をどちらも上書きで更新している。
これらの履歴は、分析上重要ではないのであれば、分析システムでも同様に、顧客のレコードを更新すれば良い。逆に変更が分析で重要な意味を持つ場合はどうだろうか?分析システムにあるディメンションテーブルへは、変更をそのまま上書きするのではなく別の方法で対応する必要がある。例えば、生年月日の変更は重要ではなかったが、住所の変更は住所別分析をしていたため重要な場合があったとする。それぞれの変更に対してタイプ1とタイプ2という対応パターンを使用出来る。
タイプ1 古い値の上書き
ソースの変更があった時に、ディメンションに履歴を保持する必要がない時に、タイプ1が採用される。
ディメンションは単純に新しい値に上書きされる。これはソースデータが入力ミスなどに対して修正される場合に用いられることが多い。この方法はシンプルだが、変更前に関連しているファクトに影響を与える。
ディメンション値の上書きに副作用
例えば、図1の生年月日の変更。人の生年月日は変わることがない情報だが、これは恐らく正しい状態にするための変更が行われている。スタースキーマには、customerというディメンションテーブルがあり、テーブルにはナチュラルキーとしてcustomer_idがあり、顧客名、生年月日、現住所を持っているとする。
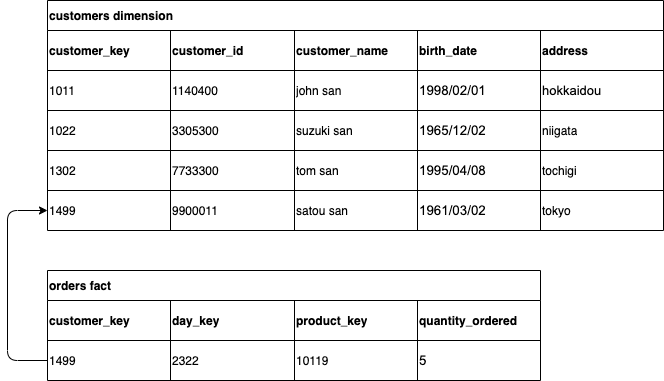
図2 変更前の状態。
図2は変更が行われる前の状態を示している。customerディメンションの4行目にはsatou sanの行がある。ordersファクトテーブルには、satou sanを示すcustomer_key 1499が含まれているレコードがある。これを読み解くと、day_key 2322が示す日付に、product_key 10119の製品を5個購入したことが分かる。

図3 タイプ1で生年月日が変更された状態。
図3は、生年月日がタイプ1の変更があった後のスタースキーマの状態を示している。customerディメンションテーブルのsatou sanの行が更新されている。
この時点で分かると思うが、タイプ1の変更は既存のファクトに影響を与える。これは見落とされがちだが重要なことだ。ディメンションテーブルが更新されると、既存のファクトの結果が変わる。これによって混乱が生じることがある。例えば、satou sanの生年月日の変更が行われたとして、以前の結果と変更後の結果は変わる。これは事実が変わったように見える。こういった混乱が起きないためには、そういうものだという認識をしている必要がある。組織によってはこれが好ましくない場合がある。その場合タイプ1の採用をさけるべきである。
ちなみに、タイプ1は、ファクトの結果が変わることに加え、ディメンションの履歴を追跡することも出来ない。
タイプ2 新しい追加レコードの作成
タイプ2は、変更前と変更後のそれぞれファクトが保存される。
ソースデータの変更の履歴を保持するために、ディメンションテーブルに新しいコードを追加している。これで既存のレコードはそのままになる。古い値に関連付けられたファクトはそのままになり、新しいファクトに関しては新しいものと紐付けることが出来る。
例えば、住所の変更が行われたとして、過去にtokyoに住んでいた時と変更後のosakaで住んでいる時で、明確に分けて分析が行える。もし、これがタイプ1の変更を適用していると、本当にほしい結果が取れなくなるだろう。
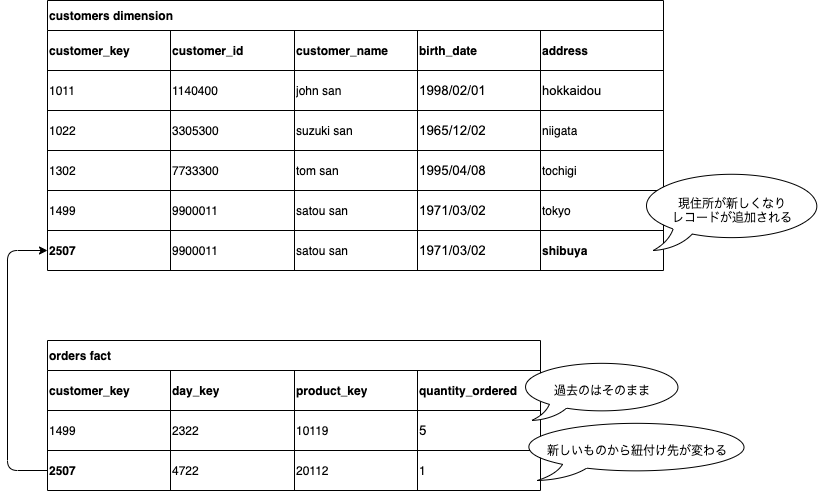
図4 タイプ2での変更後の状態。
ディメンションの履歴が部分的に維持される
タイプ2は、特定のナチュラルキーに対して複数のレコードが発生する。これは履歴を残すことに役立つが、新しい形の混乱を生むことがある。例えば、ディメンションテーブルに重複したレコードがあることにより、customer_id 9900011に関するディメンションを取得した際に2行返ってくることになる。この時にどちらが最新の行かを判定するには、現在のバージョンを示すフラグが必要になる。
ファクトの歴史情報は残るが、ディメンションにはそのような情報はない。ディメンション内に、あるナチュラルキーに紐付いたレコードが複数あることは分かるが、これらがいつ正しかったのかは分からない。これはファクトによってのみ理解することが出来る。satou sanの現住所が変更された後、ディメンションテーブルは、2つのバージョンを持っていることを示しているが、どの時点のsatou sanの話をしているかは分からない。例えば、2008年1月1日にどこに住んでいたかはディメンションから読み取れない。もし、2008年の1月1日に注文があれば、どこに住んでいたかは分かるが、その日に注文が入らなければわからないのである。この問題を回避するには、satou sanのそれぞれの状態にタイムスタンプで、どの時点の情報なのかを判別が出来るカラムが必要になる。これによってディメンションとファクトの両方に歴史情報を持つことが出来る。
まとめ
基本的にはタイプ2のが安全である。タイプ1は設計的に過去文脈が消えてしまうため混乱を生む可能性がある。しかし、タイプ2はディメンションのロード工程がややこしくなるため、ディメンションに設定されている値に重要性がないのであれば、無理してタイプ2にする必要はない。これはそれぞれの分析要件に合わせて考えていく必要がある。
ちなみに、タイプは1〜5まで存在している。タイプ1、2では、やりたいことを実現できなさそうな場合は、3〜5も調べてみてほしい。個人的にはあまり一般的ではないため、今回は割愛している。
Discussion