Pandas[GPU] vs Polars[CPU] vs Polars[GPU]
背景
NVIDIA AI Summit Japan (2024/11/12-11/13)に参加してきました。
刺激的なセッションが多く、非常によいイベントでした。参加したセッションの一つに 「データサイエンスの高速化: GPU で加速する Polars と競技における特徴エンジニアリング」 があり、Polarsの素晴らしさとGPU利用の手軽さをKaggle Grandmasterの小野寺さんと、Polars日本コミュニティの冨山さんに語っていただけました。
撮影禁止だったので、文字で簡単に発表の内容を要約すると、
・PolarsもGPU使えるよ!書き換える部分はたったこれだけ!でもLazyFrameでしか使えないよ!
・Polars[CPU]がクソ速すぎて、GPUの恩恵を感じるのは数億(?)行のテーブルデータくらいから!
・PolarsのGPU処理と、PandasのGPU処理は実はちょっと違うんだよ!
こんな感じでした。
講演後、ふと疑問に思いました。
「Polars[CPU]自体がめっちゃ早くて、Polars[GPU]のメリットがクッッッソ巨大なデータでしか得られないなら、基本的にPolars[CPU]でよくない?」
「Polars[GPU]とPandas[GPU]で、処理のされ方が違うのなら、Pnadas[GPU]とPolars[CPU]比較したら面白いのでは?」
というわけで、いくつか実験条件を設定してベンチマークを測ってみました。
なお、あくまで個人的な興味関心で実施しているため、多少実験が荒い点はご容赦ください。
実験
目的
1.GPUを使うメリットを体感する
2.Polars[CPU]とPandas[GPU]を比較して、Polars[CPU]の凄さを体感する
3.自分なりに各パッケージの使い分けの基準を模索する
内容
| 実験 | 処理内容 | polars[cpu] (秒) | polars[gpu] (秒) | pandas[cpu] (秒) | pandas[gpu] (秒) |
|---|---|---|---|---|---|
| #1 | 集約処理 (group by) | ||||
| #2 | 文字列処理 (結合, 置換, 抽出, 大文字化) | ||||
| #3 | 日付処理 (year, month) |
※結合(merge, join)は小野寺さん、冨山さんの発表の中で十分GPUの恩恵を受ける処理であることが自明だったので今回は省略しました。
処理速度を計測するためのデータセットは以下のコードで作成しました。
import pandas as pd
import polars as pl
import numpy as np
import random
from datetime import datetime, timedelta
import time
# データの行数
num_rows = 100_000_000
# データ生成関数
def generate_data(seed):
# 乱数のシードを固定
np.random.seed(seed)
random.seed(seed)
# USER_ID列の生成
user_ids = np.random.randint(1, 1001, size=num_rows) # 1から1000までのユーザーID
# DATE列の生成
start_date = datetime(2020, 1, 1)
end_date = datetime(2023, 1, 1)
date_range = end_date - start_date
dates = [start_date + timedelta(days=random.randint(0, date_range.days)) for _ in range(num_rows)]
# PRODUCT列の生成
products = np.random.choice(['商品A', '商品B', '商品C', '商品D', '商品E'], size=num_rows)
# PRICE列の生成
prices = []
for product in products:
if product == '商品A':
prices.append(random.randint(100, 200))
elif product == '商品B':
prices.append(random.randint(200, 300))
elif product == '商品C':
prices.append(random.randint(500, 600))
elif product == '商品D':
prices.append(random.randint(100, 150))
elif product == '商品E':
prices.append(random.randint(100, 300))
# データフレームの作成
data = {
'USER_ID': user_ids,
'DATE': dates,
'PRODUCT': products,
'PRICE': prices
}
return pd.DataFrame(data), pl.DataFrame(data), pl.LazyFrame(data)
# データフレームの生成
df_pandas1, df_polars1, lf_polars1 = generate_data(42)
CPU処理の場合は、上記のデータ作成後、以降のコードを実行してゆけばよいです。
GPU処理の場合は、いくつか変更する必要があります。
-
%load_ext cudf.pandasをデータ生成前に実行しておく
今回の実験はJupyterLabで行っていますが、Notebook形式の環境で行う場合は先頭のセルで%load_ext cudf.pandasを実行してください。
これを実行することで、pandasの書き方であっても自動的にcuDFで処理されるようになります。
但し、cuDFが対応していない処理の場合は、pandasで処理されてしまいます。
処理時間がやたらかかるときは、実行しているコードにcuDFが対応しているかを確認してください。
-
polarsのコードを一部変更する
polarsでGPUを使う場合は、pl.DataFrameではなく、pl.LazyFrameを使用してください。2024/11/15時点で、GPU処理が対応しているのはLazyFrameのみです。
そして、polarsの処理の最後に.collect(engine='gpu')をくっつけてください。
たったこれだけでpolarsでもGPUを使用した高速な処理が実現できます。
結果
結果1: 集約処理(group by)
print("実験1: 集約処理")
# pandas
start_time = time.time()
result_pandas = df_pandas1.groupby('PRODUCT').agg({'PRICE': ['mean', 'median']})
end_time = time.time()
print(f"pandas[cpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
result_polars = df_polars1.group_by('PRODUCT').agg([
pl.col('PRICE').mean().alias('mean'),
pl.col('PRICE').median().alias('median')
])
end_time = time.time()
print(f"polars[cpu]: {end_time - start_time:.3f} 秒")
print("実験1: 集約処理")
# pandas
start_time = time.time()
result_pandas = df_pandas1.groupby('PRODUCT').agg({'PRICE': ['mean', 'median']})
end_time = time.time()
print(f"pandas[gpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
result_polars = lf_polars1.group_by('PRODUCT').agg([
pl.col('PRICE').mean().alias('mean'),
pl.col('PRICE').median().alias('median')
]).collect(engine='gpu')
end_time = time.time()
print(f"polars[gpu]: {end_time - start_time:.3f} 秒")
実験1: 集約処理
pandas[cpu]: 10.735 秒
polars[cpu]: 2.656 秒
実験1: 集約処理
pandas[gpu]: 0.350 秒
polars[gpu]: 1.966 秒
結果2: 文字列処理(結合, 置換, 抽出, 大文字化)
print("\n実験2: 文字列処理-結合-")
# pandas
start_time = time.time()
df_pandas1['concat_product'] = df_pandas1['PRODUCT'].str.cat(df_pandas1['PRICE'].astype(str), sep='_')
end_time = time.time()
print(f"pandas[cpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
df_polars1 = df_polars1.with_columns(pl.concat_str([pl.col("PRODUCT"), pl.col("PRICE").cast(pl.String)], separator="_").alias("concat_product"))
end_time = time.time()
print(f"polars[cpu]: {end_time - start_time:.3f} 秒")
print("\n実験2: 文字列処理-結合-")
# pandas
start_time = time.time()
df_pandas1['concat_product'] = df_pandas1['PRODUCT'].str.cat(df_pandas1['PRICE'].astype(str), sep='_')
end_time = time.time()
print(f"pandas[gpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
lf_polars1_1 = lf_polars1.with_columns(pl.concat_str([pl.col("PRODUCT"), pl.col("PRICE").cast(pl.String)], separator="_").alias("concat_product")).collect(engine='gpu')
end_time = time.time()
print(f"polars[gpu]: {end_time - start_time:.3f} 秒")
実験2: 文字列処理-結合-
pandas[cpu]: 40.744 秒
polars[cpu]: 5.311 秒
実験2: 文字列処理-結合-
pandas[gpu]: 0.018 秒
polars[gpu]: 4.699 秒
# 実験2: 文字列処理 (結合, 置換, 抽出, 大文字/小文字)
print("\n実験2: 文字列処理-置換-")
# pandas
start_time = time.time()
df_pandas1['PRODUCT'] = df_pandas1['PRODUCT'].str.replace('商品', 'Product')
end_time = time.time()
print(f"pandas[cpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
df_polars1 = df_polars1.with_columns(pl.col('PRODUCT').str.replace('商品', 'Product'))
end_time = time.time()
print(f"polars[cpu]: {end_time - start_time:.3f} 秒")
print("\n実験2: 文字列処理-置換-")
# pandas
start_time = time.time()
df_pandas1['PRODUCT'] = df_pandas1['PRODUCT'].str.replace('商品', 'Product')
end_time = time.time()
print(f"pandas[gpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
lf_polars1_2 = lf_polars1.with_columns(pl.col('PRODUCT').str.replace('商品', 'Product')).collect(engine='gpu')
end_time = time.time()
print(f"polars[gpu]: {end_time - start_time:.3f} 秒")
実験2: 文字列処理-置換-
pandas[cpu]: 26.845 秒
polars[cpu]: 4.067 秒
実験2: 文字列処理-置換-
pandas[gpu]: 0.039 秒
polars[gpu]: 3.545 秒
print("\n実験2: 文字列処理-抽出-")
# pandas
start_time = time.time()
df_pandas1['extracted_duct'] = df_pandas1['PRODUCT'].str.extract(r"(uctB)", 1)
end_time = time.time()
print(f"pandas[cpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
df_polars1 = df_polars1.with_columns(pl.col("PRODUCT").str.extract(r"(uctB)", 1).alias("extracted_duct"))
end_time = time.time()
print(f"polars[cpu]: {end_time - start_time:.3f} 秒")
print("\n実験2: 文字列処理-抽出-")
# pandas
start_time = time.time()
#df_pandas1['extracted_duct'] = df_pandas1['PRODUCT'].str.extract(r"(uctB)", 1) # これはpandas[cpu]処理になってしまう
df_pandas1['extracted_duct'] = df_pandas1['PRODUCT'].str.extract(r"(uctB)", expand=True) # これはpandas[gpu]処理になる
end_time = time.time()
print(f"pandas[gpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
lf_polars1_3 = lf_polars1.with_columns(pl.col("PRODUCT").str.extract(r"(uctB)", 1).alias("extracted_duct")).collect(engine='gpu')
end_time = time.time()
print(f"polars[gpu]: {end_time - start_time:.3f} 秒")
実験2: 文字列処理-抽出-
pandas[cpu]: 61.742 秒
polars[cpu]: 5.621 秒
実験2: 文字列処理-抽出-
pandas[gpu]: 0.053 秒
polars[gpu]: 4.187 秒
print("\n実験2: 文字列処理-大文字-")
# pandas
start_time = time.time()
df_pandas1['uppercase_product'] = df_pandas1['PRODUCT'].str.upper()
end_time = time.time()
print(f"pandas[cpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
df_polars1 = df_polars1.with_columns(pl.col("PRODUCT").str.to_uppercase().alias("uppercase_product"))
end_time = time.time()
print(f"polars[cpu]: {end_time - start_time:.3f} 秒")
print("\n実験2: 文字列処理-大文字-")
# pandas
start_time = time.time()
df_pandas1['uppercase_product'] = df_pandas1['PRODUCT'].str.upper()
end_time = time.time()
print(f"pandas[gpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
lf_polars1_4 = lf_polars1.with_columns(pl.col("PRODUCT").str.to_uppercase().alias("uppercase_product")).collect(engine='gpu')
end_time = time.time()
print(f"polars[gpu]: {end_time - start_time:.3f} 秒")
実験2: 文字列処理-大文字-
pandas[cpu]: 18.240 秒
polars[cpu]: 3.295 秒
実験2: 文字列処理-大文字-
pandas[gpu]: 0.011 秒
polars[gpu]: 4.358 秒
結果3: 日付処理(year, month)
print("\n実験3: 日付処理")
# pandas
start_time = time.time()
df_pandas1['DATE'] = pd.to_datetime(df_pandas1['DATE'])
df_pandas1['YEAR'] = df_pandas1['DATE'].dt.year
df_pandas1['MONTH'] = df_pandas1['DATE'].dt.month
end_time = time.time()
print(f"pandas[cpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
df_polars1 = df_polars1.with_columns([
pl.col('DATE').dt.year().alias('YEAR'),
pl.col('DATE').dt.month().alias('MONTH')
])
end_time = time.time()
print(f"polars[cpu]: {end_time - start_time:.3f} 秒")
print("\n実験3: 日付処理")
# cudf.to_datetime がタイムゾーン非対応.この処理しておかないと、pandas[cpu]で処理されてしまう.
df_pandas1['DATE'] = df_pandas1['DATE'].str.slice(stop=-1)
# pandas
start_time = time.time()
df_pandas1['DATE'] = pd.to_datetime(df_pandas1['DATE'])
df_pandas1['YEAR'] = df_pandas1['DATE'].dt.year
df_pandas1['MONTH'] = df_pandas1['DATE'].dt.month
end_time = time.time()
print(f"pandas[gpu]: {end_time - start_time:.3f} 秒")
# polars
start_time = time.time()
lf_polars1_5 = lf_polars1.with_columns([
pl.col('DATE').dt.year().alias('YEAR'),
pl.col('DATE').dt.month().alias('MONTH')
]).collect(engine='gpu')
end_time = time.time()
print(f"polars[gpu]: {end_time - start_time:.3f} 秒")
実験3: 日付処理
pandas[cpu]: 6.469 秒
polars[cpu]: 1.940 秒
実験3: 日付処理
pandas[gpu]: 0.039 秒
polars[gpu]: 4.484 秒
考察
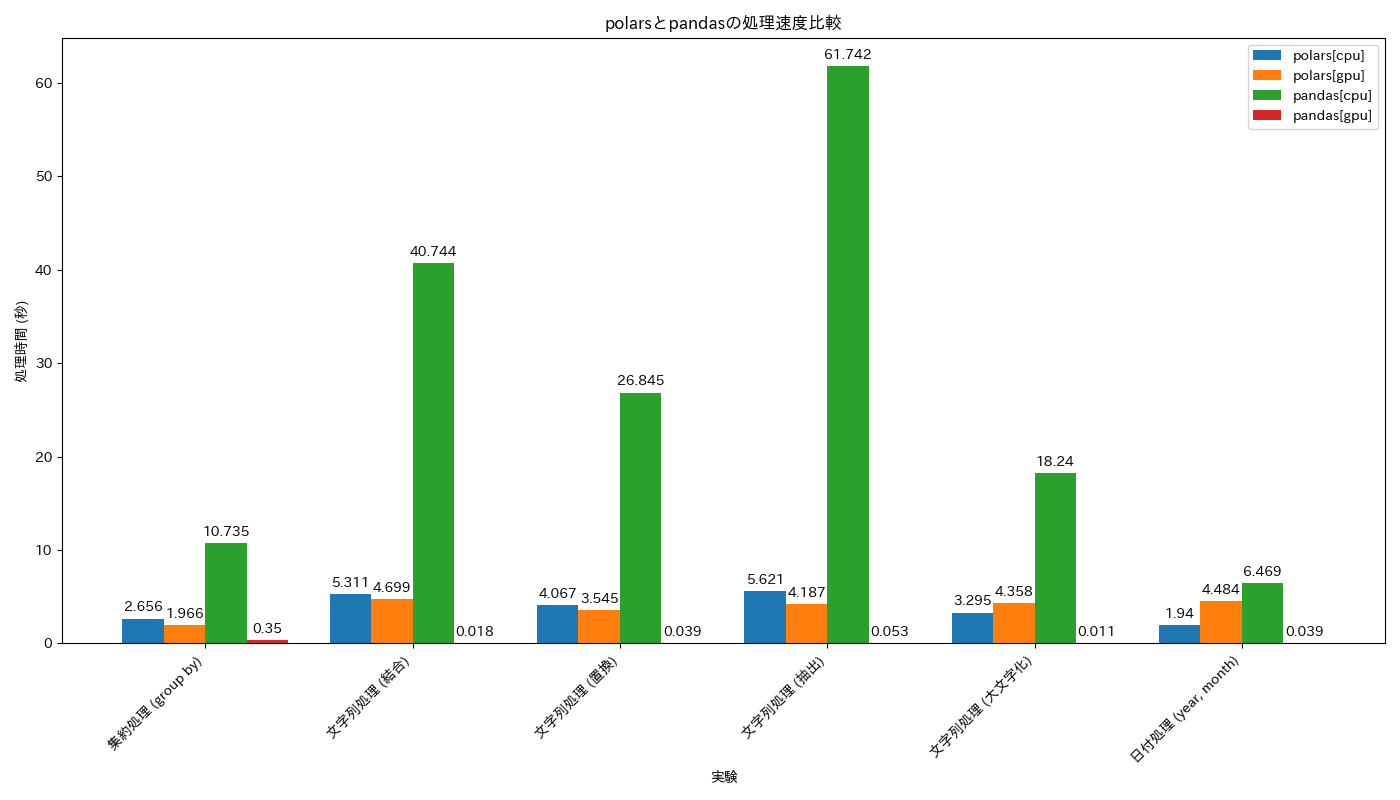
結果一覧
| 実験 | 処理内容 | polars[cpu] (秒) | polars[gpu] (秒) | pandas[cpu] (秒) | pandas[gpu] (秒) |
|---|---|---|---|---|---|
| #1 | 集約処理 (group by) | 2.656 | 1.966 | 10.735 | 0.350 |
| #2 | 文字列処理 (結合, 置換, 抽出, 大文字化) | 5.311 (結合), 4.067 (置換), 5.621 (抽出), 3.295 (大文字) | 4.699 (結合), 3.545 (置換), 4.187 (抽出), 4.358 (大文字) | 40.744 (結合), 26.845 (置換), 61.742 (抽出), 18.240 (大文字) | 0.018 (結合), 0.039 (置換), 0.053 (抽出), 0.011 (大文字) |
| #3 | 日付処理 (year, month) | 1.940 | 4.484 | 6.469 | 0.039 |
感想
まず、polars[cpu]がとにかく速いです。特にこだわりがなければpolarsを選んでおけば間違いはないです。一方で、GPU利用を考える場合は要注意です。結果一覧を見ての通り、明らかにpolars[gpu]のパフォーマンスが期待していたよりは優れません。一応行数を×10倍、×100倍...としていくとあるタイミングでpolars[gpu]のパフォーマンスがpolars[cpu]以上に格段に良くなることは実験して把握はしているものの、そんな巨大なデータを扱うシーンは少ないと思います。polars[gpu]を初手選ぶシーンは、かなり限定的 というのが私の感想です。
続いてpandas[gpu]にも目を向けてみましょう。pandas[gpu]と呼んでいますが、実態はRAPIDSのcuDFとなります。

グラフだと赤色の棒グラフのはずなんですが・・・見えませんね・・・
速い・・・予想以上に速すぎる・・・!!
これくらいpolars[cpu]やpolars[gpu]より速ければ、pandas[gpu]を選択する気持ちになりますね。
GPUを使える環境なら、pandas[gpu]を選ばない理由がないですね。
というわけで結論
1. GPUを使えるのなら、初手pandas[gpu]
2. GPUを使えないのなら、初手polars[cpu]
となりました。
もちろん使えるGPUのスペック次第では、初手polars[cpu]となる場合もありますが、上記の結論はほとんどのケースで採用できると思います。
余談
なぜpandas[gpu]とpolars[gpu]で差が生まれたのか?
ちなみに、polars[gpu]の性能が期待していたより微妙だった・・・というのはNVIDIAのイベントで紹介された結果の印象とほぼ変わりませんでした。
pandas[gpu] (=cuDF)は、全ての処理がCUDAをベースにしており、データフレームが完全にGPUメモリ上に展開され、CUDAの並列処理能力を最大限に活用しています。
一方、polars[gpu]は、まだオープンベータという扱いで、使える処理が限られていたり、チューニングが十分ではないと思われます。ドキュメントを読んだ限りでは「Polarsが最適化されたIR(中間表現)を構築した後、GPUエンジンに移行する」と書かれていたのでやはり処理の最初からGPUを前提としたpandas[gpu]とは設計・思想が異なるようです。このあたりを深堀すれば、polars[gpu]の処理速度が思ったほど優れてはいなかった理由が明らかになると思われます。
ただし、ご存じの通りpolarsはかなりクレイジーなスピードでアップデートされているので、いずれgpuを使っても爆速になるのではないかと期待しています。
巨大なデータはデータウェアハウスを使えばいいのでは?
巨大なデータを管理する場合、データベースにデータを登録することが多いと思います。私も巨大なデータを扱うときは、管理の面でデータベースやデータウェアハウスにデータを登録し、SQLでデータ抽出し、抽出データを適宜PythonやRで加工することがあります。
ふと、Pythonを扱えるデータウェアハウス製品に今回のデータを登録した場合、どれくらいの速度でデータの処理ができるのかも気になってきたので、追加実験を行いました。
実験にはsnowflakeを使いました。
snowflakeを採用した理由は 「データサイエンティストが普段慣れ親しんだNotebook上でPandasで作成したコードを、Snowflakeの高速な処理能力で実行する」ことが簡単に実現できるためです。
なおデータは、事前に今回の実験で使用したデータと全く同じものをテーブルに登録し、そちらを利用しました。
Snowflakeの処理性能を左右するウェアハウスは、一番安価なXSサイズを使用し、Snowflake Notebook上でSnowpark pandas APIを使用し以下のコードを実行しました。
# Import python packages
import modin.pandas as pd
import snowflake.snowpark.modin.plugin
import time
from snowflake.snowpark.context import get_active_session
session = get_active_session()
df_pandas1 = pd.read_snowflake('DATABASE_NAME.SCHEMA_NAME.TABLE_NAME') # 適宜読み込み名を変更してください
print("実験1: 集約処理")
start_time = time.time()
result_pandas = df_pandas1.groupby('PRODUCT').agg({'PRICE': ['mean', 'median']})
end_time = time.time()
print(f"pandas[snowflake]: {end_time - start_time:.3f} 秒")
print("\n実験2: 文字列処理-結合-")
start_time = time.time()
df_pandas1['concat_product'] = df_pandas1['PRODUCT'] + "_" + df_pandas1['PRICE'].astype(str)
end_time = time.time()
print(f"pandas[snowflake]: {end_time - start_time:.3f} 秒")
# 実験2: 文字列処理 (結合, 置換, 抽出, 大文字/小文字)
print("\n実験2: 文字列処理-置換-")
start_time = time.time()
df_pandas1['PRODUCT'] = df_pandas1['PRODUCT'].str.replace('商品', 'Product')
end_time = time.time()
print(f"pandas[snowflake]: {end_time - start_time:.3f} 秒")
print("\n実験2: 文字列処理-抽出-")
start_time = time.time()
df_pandas1['extracted_duct'] = df_pandas1['PRODUCT'].replace(
{r".*(uctB).*": r"\1", r".*": None}, regex=True
)
end_time = time.time()
print(f"pandas[snowflake]: {end_time - start_time:.3f} 秒")
print("\n実験2: 文字列処理-大文字-")
start_time = time.time()
df_pandas1['uppercase_product'] = df_pandas1['PRODUCT'].str.upper()
end_time = time.time()
print(f"pandas[snowflake]: {end_time - start_time:.3f} 秒")
print("\n実験3: 日付処理")
start_time = time.time()
df_pandas1['DATE'] = pd.to_datetime(df_pandas1['DATE'])
df_pandas1['YEAR'] = df_pandas1['DATE'].dt.year
df_pandas1['MONTH'] = df_pandas1['DATE'].dt.month
end_time = time.time()
print(f"pandas[snowflake]: {end_time - start_time:.3f} 秒")
以下、結果まとめです。
| 実験 | 処理内容 | polars[cpu] (秒) | polars[gpu] (秒) | pandas[cpu] (秒) | pandas[gpu] (秒) | pandas[snowflake] (秒) |
|---|---|---|---|---|---|---|
| #1 | 集約処理 (group by) | 2.656 | 1.966 | 10.735 | 0.350 | 0.252 |
| #2 | 文字列処理 (結合) | 5.311 | 4.699 | 40.744 | 0.018 | 0.416 |
| 文字列処理 (置換) | 4.067 | 3.545 | 26.845 | 0.039 | 0.241 | |
| 文字列処理 (抽出) | 5.621 | 4.187 | 61.742 | 0.053 | 0.198 | |
| 文字列処理 (大文字化) | 3.295 | 4.358 | 18.240 | 0.011 | 0.180 | |
| #3 | 日付処理 (year, month) | 1.940 | 4.484 | 6.469 | 0.039 | 0.813 |
pandas[gpu]には及びませんでしたが、軒並みpolars[cpu]よりは速い結果となりました。
なお、当然ながらデータサイズが大きくなるほどデータウェアハウスの恩恵が大きくなります。
データサイズによっては、このようにpythonでデータウェアハウスの処理性能の恩恵を受けられる製品を使うのも選択の一つですね。
特にGPUに載らないくらいの巨大なデータの場合は、データの高速処理の選択肢となるのではないでしょうか?
また、snowflakeであればウェアハウスのサイズを瞬時に変更できるので、XSサイズで処理に時間がかかる場合は、S、M、L、・・・6XLと大きくして「パワーでゴリ押す」ことで「巨大データ×高速処理」が容易に実現可能な点も魅力の一つだと感じています。
ただし、Snowpark pandas APIは一部のメソッドがまだ実装されておらず、今回の実験で言うと「Series.str.cat」と「Series.str.extract」が2024/11/24時点では未実装でした。そのため、コードの一部を変更しています。
このように使いたい処理がすべて実装されているとは限らない点、Snowflake Notebookの挙動がやや不安定な場合がある点、そして忘れてはいけませんがデータの保存とデータの処理にかかるコストには注意が必要です。
参考文献
Discussion