Snowflake×非構造データ ~Notebooksを添えて~
この記事の対象ユーザー
- Snowflakeユーザー
- 「Snowflakeで非構造データを取り扱う必要ってあるの?」と思っている人
- 非構造データから情報を抽出して何らかの仕事に利用している人
背景
「Data Cloud Summit 2024の発表見てると、やたらAIとの統合を推しているなぁ・・・」
弊社がSnowflakeを導入した当時は、「超高速でコスパの良いDWH、それがSnowflake」「データ共有方法が色々あって、特に社外とのデータコラボレーションが便利そう」という印象が強かったです。この印象は今なお変わっていませんが、それに加えて「データサイエンス」「AI」のキーワードがSnowflakeの顔の1つになってきました。
正直、データサイエンティストの端くれとして嬉しい反面、「Databricksにどんどん似てきているなぁ・・・」「これから製品の導入を検討する会社さんは、両製品の比較大変そう」と感じています。両製品触った経験がある身としては、一長一短なので、ますます今後の両社の製品展開からは目が話せません。
前置きはこれくらいにして、ここからが本題です。Data Cloud Summit 2024の報告を各所から聞きかじった限りでは 「Snowflake×AI、特にSnowflake×非構造データやSnowflake×LLM」 がホットトピックの1つであったように感じました。
確かにCortexやArcticといったサービスを展開している点を考慮すると、非構造データやLLMに力を入れていることはわかるのですが、一方で自身が携わる業務範囲で 「その非構造データ、わざわざSnowflakeで処理する必要性、ある?」 と自問したときに適したユースケースを見つけられませんでした。普段はローカルにしろサーバーにしろ、構築したPython環境下でテキストデータの処理や分析、モデル開発をしていたので、どうしても慣れ親しんだ環境からSnowflakeへ移行するためにはそれなりのメリットを見つける必要がありました。
本記事では、「このユースケースでならSnowflakeで非構造データを処理しよう」 と思い至った事例を中心に、個人的な感想を添えて共有します。
ユースケース
非構造データから必要な情報を抽出し、社内で共通利用するためのテーブルを作成する
このユースケースを選んだ理由は以下の通りです。
- 「Snowflakeにデータを貯めておきたい」という条件を満たすから≒複数の人間が同じデータから異なるユースケースを実施する可能性が高いから
- Snowflake内で処理を完結させられ、管理面で楽そうだったから
- Snowflake Cortex LLM関数が思ったより便利だったから
1.「Snowflakeにデータを貯めておきたい」という条件を満たすから
- 論文中に特定の技術、特許、遺伝子情報、医薬品etc・・・といった情報が含まれているかを知りたい
- 決算書から特定の製品の売上情報を抽出してほしい(そしてその値を使って売上予測をしてほしい)
こんなユースケースをみなさんも一度は目にしたことがあるでしょう。そしてこういったユースケースは大抵継続的に実施することになります。そのため抽出した情報を貯めていくデータベースが必要となります。Snowflake上で前処理~データベース化までシームレスに行えるので、ローカルやサーバ環境で解析したデータを逐一Snowflakeにアップロードするよりはるかに効率的だと思います。また、データがあちこち移動することをリスクと捉える企業においては尚更Snowflake上で完結してほしいのではないでしょうか?
また、個人的な経験ベースにはなりますが、特に論文データとSNSデータは非構造データの中でも多様な目的で使われている印象があります。よって、一度きりのユースケースで終わらないこのような非構造データをSnowflake上に使いやすい形で保存しておくことに少なくともデメリットは感じないと思います。
2.Snowflake内で処理を完結させられ、管理面で楽そうだったから
私個人の好みが出てしまいますが、データの処理のために色んなツールを使うのは好きではないです。というのも、データガバナンスの観点からもデータが点在するのは好ましくなく、またツールを適宜切り替える手間もなかなかにストレスです。特に非構造データの処理は複雑になりがちで、今まで複数のツールを使い分けて対処していました。
Snowflakeは様々なサービスが日々アップデートされており、2023年のアップデートを踏まえてデータの加工、保存、分析をすべてSnowflake内でできるようになったと感じています。
3.Snowflakeで扱えるLLMが思ったより充実していたから
こちらに関しては実際のコードをお見せしながら後ほど解説します。
シナリオ(手順)
- PDFファイルをSnowlakeのStageに投入する
- Stage上のPDFファイルの中身を読み込む
- 読み込んだ中身に対してLLM関数を実行し、必要な情報を抽出(生成)する
- 抽出(生成)した情報を含むテーブルを作成する
1.PDFファイルをSnowlakeのStageに投入する
まず、Stageを作成しましょう。なお、以降の作業はSnowflakeのTrialアカウント@北米リージョンで行っています。
use role accountadmin;
grant usage on warehouse compute_wh to role sysadmin;
use role sysadmin;
create database pdf_db;
create schema pdf_db.pdf_schema;
create stage pdf_db.pdf_schema.pdf_stage;
-- GUIでPDFをステージにアップロード
-- Snowsightの左のペインから「Databases」を選択し、作成したStageを探し出して、あとは雰囲気でファイルをアップロードする
Stageを見つけたら、右上の「+Files」をクリックして、アップロードしたいPDFを選択
アップロードが成功したか、念の為確認しておきましょう。
list @pdf_db.pdf_schema.pdf_stage;
2.Stage上のPDFファイルの中身を読み込む
2024年5月某日、公式からアナウンスがないのに突如Notebookが使用できるようになりました。これはデータサイエンティストにとっては慣れ親しんだインターフェイスでSnowflakeを操作できるので非常に嬉しい限りです。今回は折角なのでNotebookを使って以降の処理を進めていきます。
まず手始めに、1つのPDFファイルの中身をNotebookから確認してみましょう。
-- Create a java function to parse PDF files
create or replace function python_read_pdf(file string)
returns string
language python
runtime_version = 3.9
packages = ('snowflake-snowpark-python','pypdf2')
handler = 'read_file'
as
$$
from PyPDF2 import PdfFileReader
from snowflake.snowpark.files import SnowflakeFile
from io import BytesIO
def read_file(file_path):
whole_text = ""
with SnowflakeFile.open(file_path, 'rb') as file:
f = BytesIO(file.readall())
pdf_reader = PdfFileReader(f)
whole_text = ""
for page in pdf_reader.pages:
whole_text += page.extract_text()
return whole_text
$$;
-- PDF内のテキストを確認
select python_read_pdf(
build_scoped_file_url(
@pdf_db.pdf_schema.pdf_stage, -- ファイルが保存してあるstage名
'ステージにアップロードした特定のPDFファイル名.pdf'
)
)
as pdf_text;
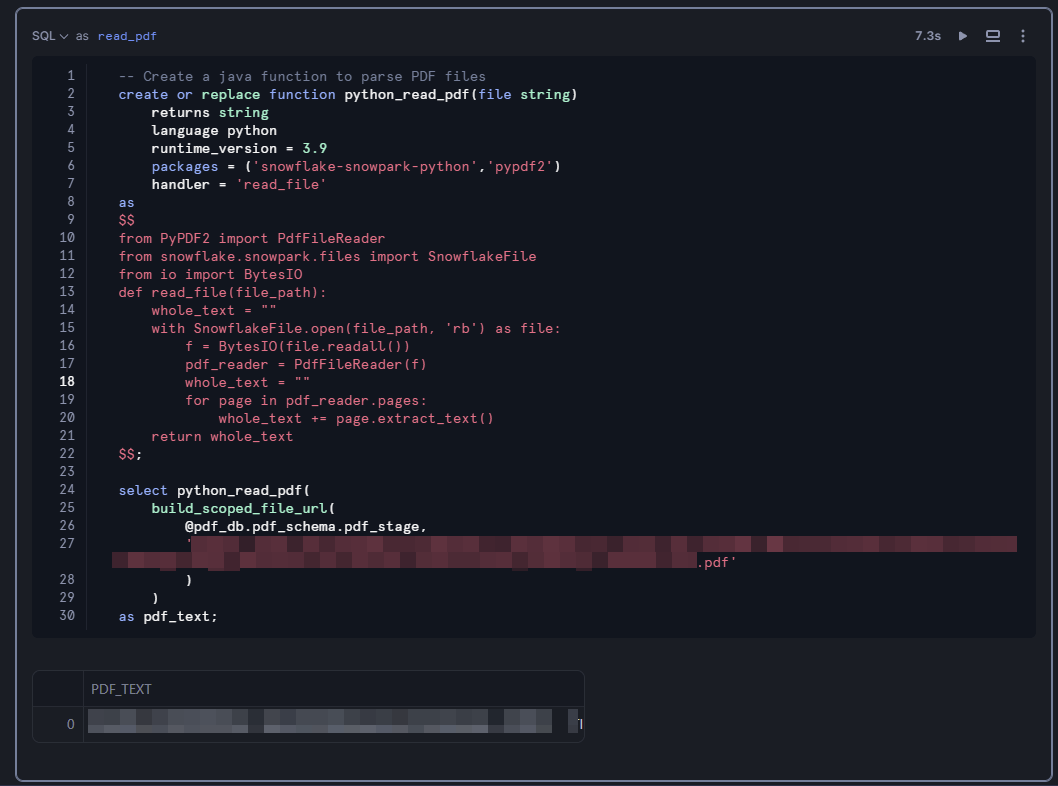
PDF_TEXTにPDFの中身が出力されたはずです。ちなみに出力された値のセルがアクティブな状態でもう一度クリックすると、PDFの中身全体を確認することができます。とは言ってもかなり見にくいと思いますので、見やすい形で中身を出力してみましょう。新しいセルを作成し、言語をpythonに切り替え、次のコードを実行してください。
read_pdf.to_pandas().PDF_TEXT[0][0:800]
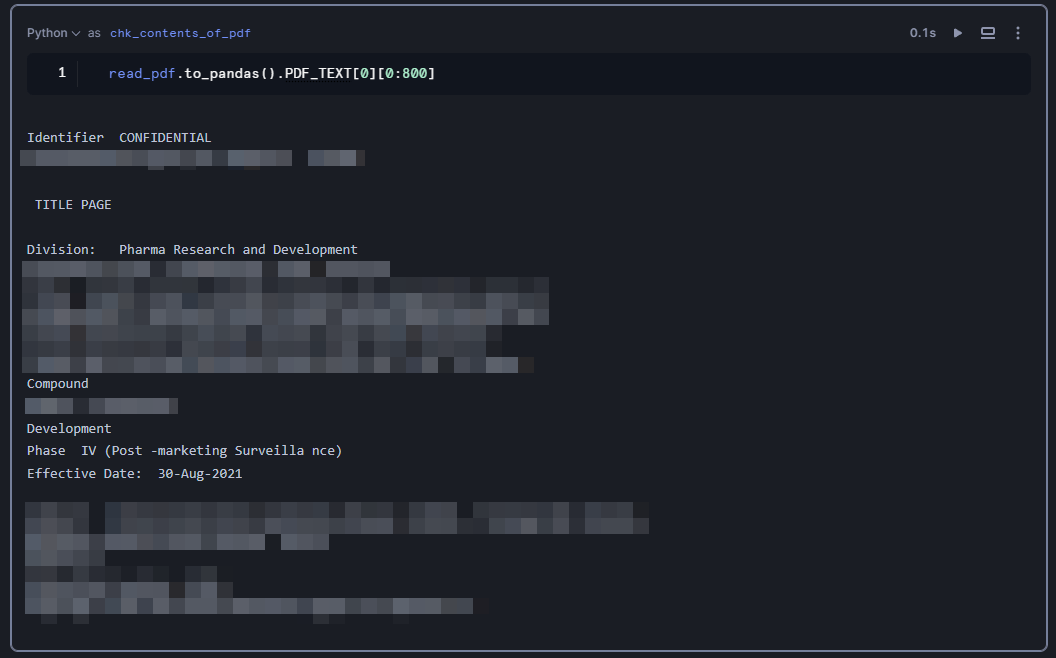
ここで重要なポイントが1つあります。それはread_pdf.to_pandas()のread_pdfという変数名はどこから来たのか?という点です。「直前まで私はSQLを書いていたはずなんだが・・・」と思ってしまうところですが、これがSnowflake Notebooksの良い点の1つです。実はPythonセルからSQLセルを参照することができるのです。SQLセルのセル名を指定することで、SQLセルの出力結果に対して処理を実行できます。今回はread_pdfセルで出力された結果を一旦to_pandas()でpandas DataFrameに変換し、中身を確認しています(詳しくは「参考」に記載したQiita記事を参照してください)。
3.読み込んだ中身に対してLLM関数を実行し、必要な情報を抽出(生成)する
さぁ、ついにCortexのLLM関数の出番です。現在提供されているLLM関数は、使用するモデルごとに異なる点、使用可能なToken数、コストが異なる点に注意が必要です。参考までに2024年6月8日時点の情報は以下のとおりです。
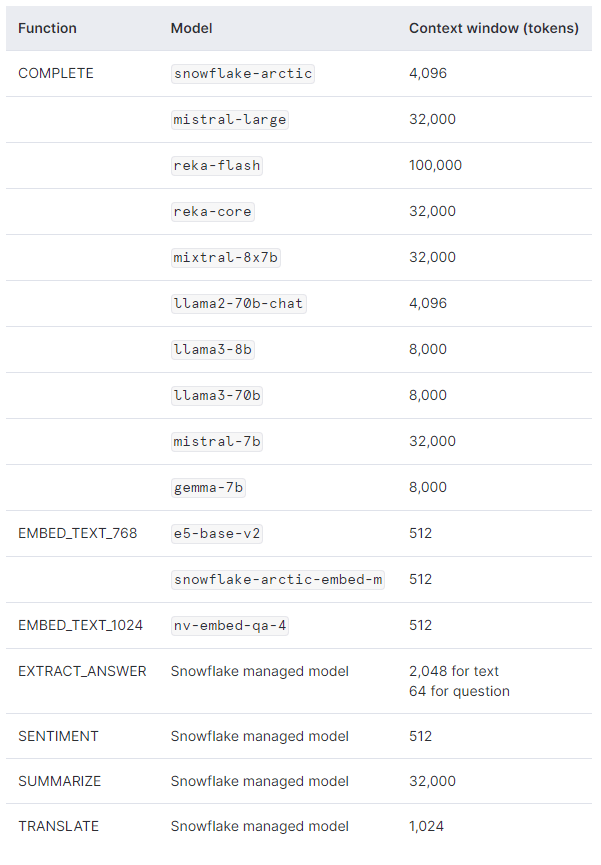
使用可能なモデルとToken数
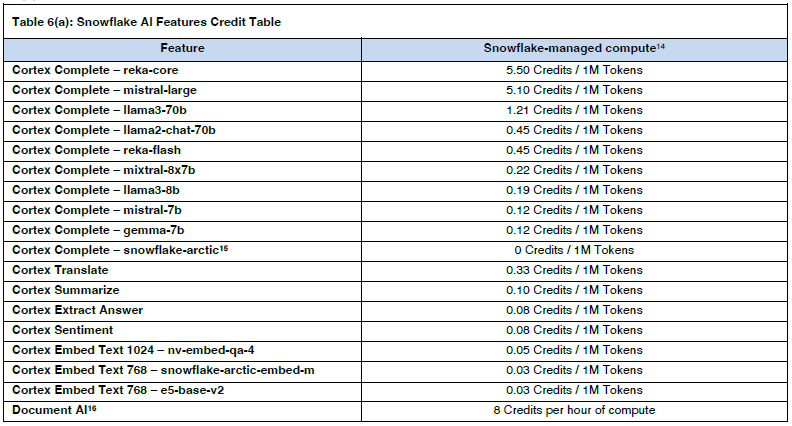
各モデルのコスト
では、まずEXTRACT_ANSWER関数を使ってみましょう。
select snowflake.cortex.extract_answer(
PDF_TEXT,
'What is the primary objective in this protocol?'
) AS OUTPUT
from {{cells.read_pdf}};
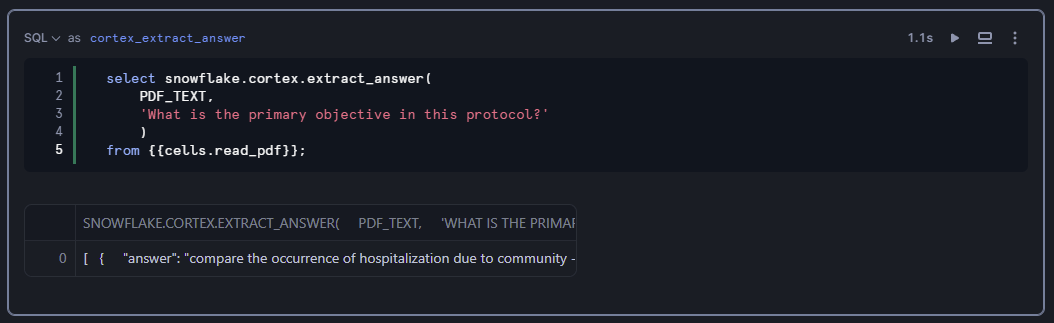
{{cells.read_pdf}}でSQLセルread_pdfの出力結果を参照しています。
次にCOMPLETE関数を使ってみましょう。COMPLETE関数は普段皆さんがChatGPTでプロンプトを書くように指示を出せるので、出力形式にこだわりがなければこちらを使うのが良いでしょう。
SELECT
PDF_TEXT,
SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large',
CONCAT(
'## Instruction: Tell me a primary objective of the research protocol. Use markdown format for your answer. ## Protocol:', PDF_TEXT) AS OUTPUT
)
FROM {{cells.read_pdf}};
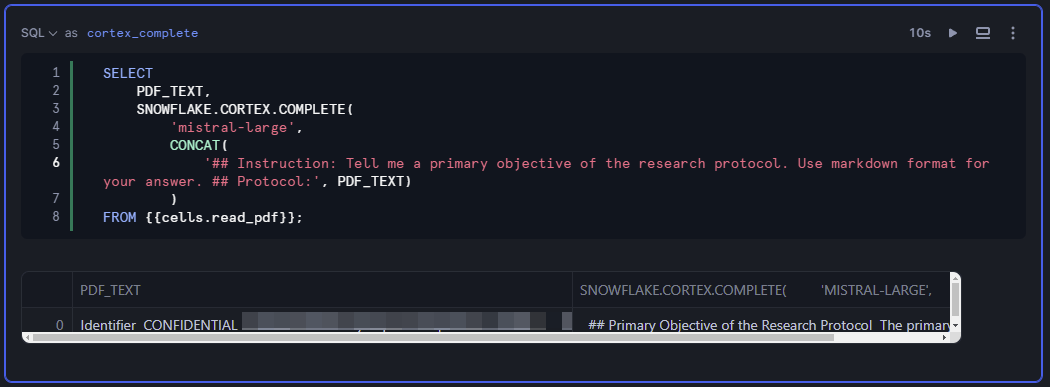
たったこれだけのコードでLLMを実行できるのはすごいですね。
もちろん、pythonセルでも実行できます。その場合はSnowparkでの実行となるので以下の書き方になります。
# snowpark for pythonでllm
# https://docs.snowflake.com/en/user-guide/snowflake-cortex/llm-functions#using-snowflake-cortex-llm-functions-with-python
from snowflake.cortex import Complete
from snowflake.snowpark.functions import col, lit, concat
# SQL`read_pdf`セルの出力結果をSnowpark DataFrameに変換(to_df())してから処理
read_pdf\
.to_df()\
.with_column(
'OUTPUT',
Complete('mistral-large',
concat(lit('## Instruction: Tell me a primary objective of the research protocol. Use markdown format for your answer. ## Protocol:'),
col('PDF_TEXT'))
)
)
4.抽出(生成)した情報を含むテーブルを作成する
ここまでPDFファイル単体に対する処理は、非常に簡単にできることがわかりました。あとはStage上にアップロードした複数のPDFファイルに対して処理を実施して、その結果をテーブル化するだけです。
単純に考えれば、Stage上のファイル名をリスト化しておき、これまで学んだ処理をループさせるだけです。ただし、以下の点を意識する必要があります。
- Notebookはセッション中、課金され続けるためWorksheetで処理を実行するとき以上にウェアハウスのサイズには気をつけた方が良い(とは言っても、他の従量課金制のNotebookサービスもそこは同じなのであまり気にはならないが)
- LLM関数を適用するDataFrameの変数(カラム)に含まれるすべての文字がToken数としてカウントされる(つまり、ループで処理させるファイル数が多いと一瞬でToken上限数に達する)
特に2は曲者で、マニュアルやガイドラインといった文字数の多い文書から情報を抽出させようとすると結構な頻度でToken上限に引っかかります。なので通常であれば事前にチャンク分けしたりするわけですが、今回はNLPの話をしたいわけではないので、とりあえず関連しそうな文章周辺の情報から欲しい情報を抽出することにしました。また、プロンプトは独立させておいて後で色々と試行錯誤しやすいようにしました。
import pandas as pd
from snowflake.snowpark.context import get_active_session
session = get_active_session()
# stageに格納されたPDF一覧を取得
relative_path_list = session.sql('SELECT * FROM directory(@pdf_db.pdf_schema.pdf_stage)')\
.to_pandas()["RELATIVE_PATH"]\
.to_list()
# 空のテーブルを作成
session.sql("""
CREATE OR REPLACE TEMPORARY TABLE pdf_table (
PDF_TITLE VARCHAR,
PDF_TEXT VARCHAR
)
""").collect()
# PDFテキストをテーブルに追加
for relative_path in relative_path_list:
snow_df = session.sql(
f"""SELECT
'{relative_path}' AS PDF_TITLE,
python_read_pdf(
build_scoped_file_url(@pdf_db.pdf_schema.pdf_stage, '{relative_path}')
) AS PDF_TEXT
"""
)
# snow_dfの内容をpdf_tableに挿入
snow_df.write.mode('append').save_as_table('pdf_table')
# pdf_tableの内容を表示
print('row count:', session.table('pdf_table').count())
session.sql('select * from pdf_table')
from snowflake.snowpark.functions import col, regexp_replace, lower, udf, lit, concat
from snowflake.snowpark.types import StringType, IntegerType
import re
# UDFを定義して特定のキーワード以降指定された文字数を抽出し、複数の箇所から抽出した場合は区切り文字を挿入する
def extract_text_after_keyword(text, keyword, length):
# キーワードを正規表現にエスケープし、複数形も検索するパターンを作成
keyword_pattern = re.escape(keyword) + r's?\b'
# キーワードでテキストを分割
parts = re.split(keyword_pattern, text)
result_parts = []
for i in range(1, len(parts)):
if len(parts[i]) > length:
result_parts.append(parts[i][:length])
else:
result_parts.append(parts[i])
return '|'.join(result_parts)
# 既存のUDFを削除
try:
session.sql("DROP FUNCTION IF EXISTS extract_text_after_keyword_udf(String, String, Integer)").collect()
except:
pass
# UDFを登録
extract_text_after_keyword_udf = session.udf.register(
func=extract_text_after_keyword,
return_type=StringType(),
input_types=[StringType(), StringType(), IntegerType()],
name="extract_text_after_keyword_udf"
)
# 改行を削除し、2つ以上の半角スペースを1つの半角スペースに置換、小文字化する処理を定義
processed_pdf_table = pdf_table.with_column(
"processed_text",
lower(regexp_replace(regexp_replace(col("pdf_text"), r'\n', ''), r'\s{2,}', ' '))
)
# UDFを適用して特定のキーワード(第2引数)以降指定された文字数(第3引数)を抽出し、区切り文字を挿入する
processed_pdf_table = processed_pdf_table.with_column(
"processed_text2",
extract_text_after_keyword_udf(col("processed_text"), lit("objective"), lit(1000))
)
# 投入した論文から欲しい情報を抽出してもらうためのプロンプト
PROMPT = """
## Instruction:
Tell me a primary objective of this research protocol, using the conditions below.
- Use markdown format for answers.
- Answer in 300 words or less.
- If there is no suitable answer, please says 'There is no suitable information.'
## Protocol:
"""
# Token数上限が大きいreka-flashで実行
processed_pdf_table = processed_pdf_table.with_column(
'OUTPUT',
Complete('reka-flash',
concat(lit(f'{PROMPT}'), col('processed_text2'))
)
)
processed_pdf_table.write.mode('overwrite').save_as_table('processed_pdf_table')
テーブルが生成された!
感想
どうでしょうか?非構造データから必要な情報を抜き出し、多様な目的で使用可能なテーブルを作成するというユースケースが簡単に実現できました。
個人的にはこのユースケースは非常に汎用性が高いと考えています。先に述べた通り、非構造データは膨大な情報を1つのドキュメント内に有していることから、多様な目的で利用されています。よって、非構造データからよく使われる情報を抽出しテーブル化し、一箇所に集約しておくと業務全体の効率化がはかれます。
例:
- 決算書の中からよく見る指標を抽出してテーブル化しておく
- ある人は売上予測に使用
- ある人は文書全体から企業に対する感情分析に使用
- 週報を読み込んで要約文テーブルを作成しておく
- ある人は要約文からハイパフォーマー分析をするために使用
- ある人は要約文の経時的変化とメンタルの状態を調査するために使用
しかも便利なLLM関数が準備されているので、目的に応じて各ユーザーが好きなように素早く調理できる点もGoodです。
良いことばかり書いているので、最後にいくつか懸念点も残しておきます。調査不足な点もあるので、もし間違っていたら指摘してください。
- 企業で利用する観点において、LLMや各種AIサービスがハイペースで増えてくると「事前にクレジット消費を予想しづらい」= 期初予算を立てにくい
- 複雑な(高度な)LLM処理をSnowflake内で実装するメリットはまだ見出だせていない(結局専用の環境でやったほうが効率的な事例のほうが現状は多い)
- 使用できるモデルが限定的(Fine-tuningできるモデルは更に限定的)
- 決して安いわけではない(※これに関しては正確に計算してから追って記載します)
また、おそらく今後はDocument AIの登場でもっと簡単に同様のシナリオを実現できるようになると思います。Document AIはまだ試せていないので、色々遊べるようになったらまた記事を書こうと思います(^^)
参考
PDFから情報を抽出するのに参考にした情報 Notebooksに関する情報 LLM関数に関する情報
Discussion