TL;DR
- Neural Vocoderはメルスペクトログラム等の音響特徴量から波形を復元するモジュール
- 従来の時間領域型 (HiFi‑GANなど) はエイリアシングを避けられず高F0などの条件で大きく劣化
- Wavehaxは時間周波数領域でConv2Dにより処理しiSTFTで合成することで、この問題を根本的に回避
- Harmonic Priorにより周期情報を明示的に与えるため1Mパラメータ未満でも高品質
- JVSコーパスによる評価で、学習範囲外の高F0を含む音声でも従来手法と比べて大幅な改善を確認
- 本記事ではNeural Vocoderとは何かから、従来手法の問題点・Wavehaxの改善点・再現手順・内部分析・派生研究までをまとめて紹介します!
はじめに
こんにちは、Parakeet株式会社リサーチャーの今井(X: Nuts)です。
普段は音声変換やテキスト音声合成の研究開発をしています。
本記事では、時間周波数領域で処理することにより高速に動作しつつ、従来手法で問題となっていたエイリアシングの問題を解決したNeural Vocoderである「Wavehax」について紹介していきます。
Neural Vocoderとは?
音声合成にあまり詳しくない読者のために、Neural Vocoderとは何かについてまずは軽く紹介します。
テキスト音声合成(Text-to-Speech、TTS)や音声変換(Voice Conversion、VC)、歌声合成(Singing Voice Synthesis、SVS)などの音声合成分野では通常、タスクに応じた入力からの音響特徴量の予測部分と音響特徴量から音声波形部分を予測する部分を分離し、モデルは音響特徴量の予測部分を学習します。
この音響特徴量としては、
- 声の高さ:基本周波数(F0)
- 声色:メルケプストラムやスペクトル包絡
- 非周期成分の強さ:非周期性指標(AP)・帯域非周期性指標(BAP)
- 上記4つがまとめて含まれている特徴量:メルスペクトログラム
などが使用されることが多いです。
そして、これらの音響特徴量からの音声波形の復元はVocoderというモジュールが担っており、従来は信号処理に基づく手法が用いられてきました。
例えば、上3つの特徴量から復元する場合はWORLDを使用することができますが、これは最小位相を仮定して合成することによる品質劣化が発生します。
また、メルスペクトログラムから復元する場合はGriffin-Limアルゴリズムが利用できますが、メルスケールから通常のスペクトログラムのスケールに戻す際の品質劣化、位相推定精度不足による品質劣化、100から1000回程度の反復を必要とすることによる合成速度の遅延などが発生します。
Neural Vocoderでは、音響特徴量から波形を復元する部分についてニューラルネットワークを使用することでこれらの問題を解決します。
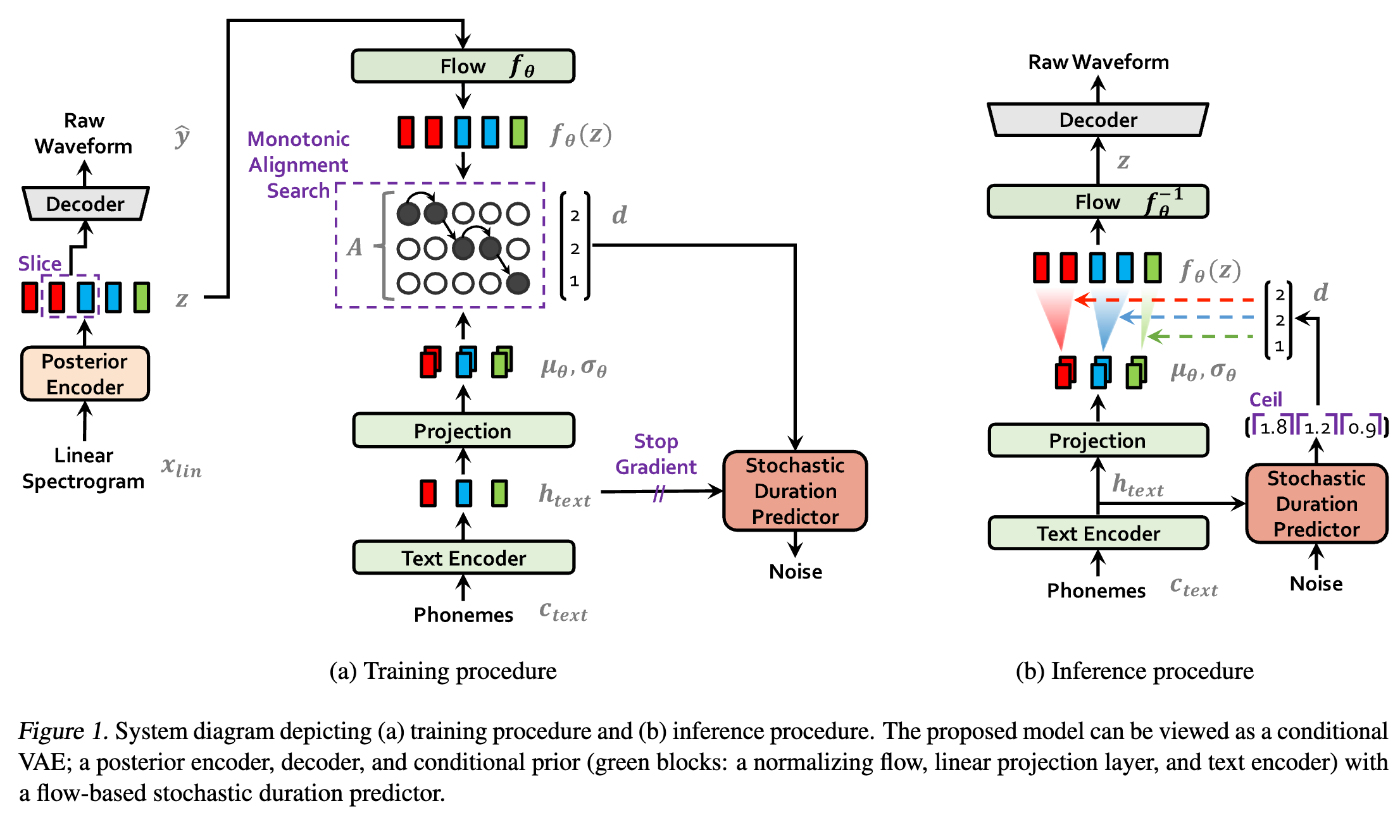
なお、近年ではTTSやVCでよく使用されるVITSのように直接波形を生成する手法が主流になってきていますが、これらの手法はNeural Vocoderを組み込みEnd-to-Endに学習にしています。
(下図はVITSのモデル構造で、Decoder部分がNeural Vocoderの1つであるHiFi-GANです)
また、VALL-Eに代表される自己回帰に基づく手法ではSoundStreamやEncodecに代表されるNeural Codec手法を音声の埋め込み・復元に使用しますが、これらも(潜在空間での圧縮の効率化を除き)学習方法やモデルアーキテクチャではNeural Vocoderの要素を多く取り入れています。
(下図はSoundStreamのモデル構造で、DecoderはNeural Vocoderの1つであるMelGANで、Encoderはそれを反転させたものになっています)

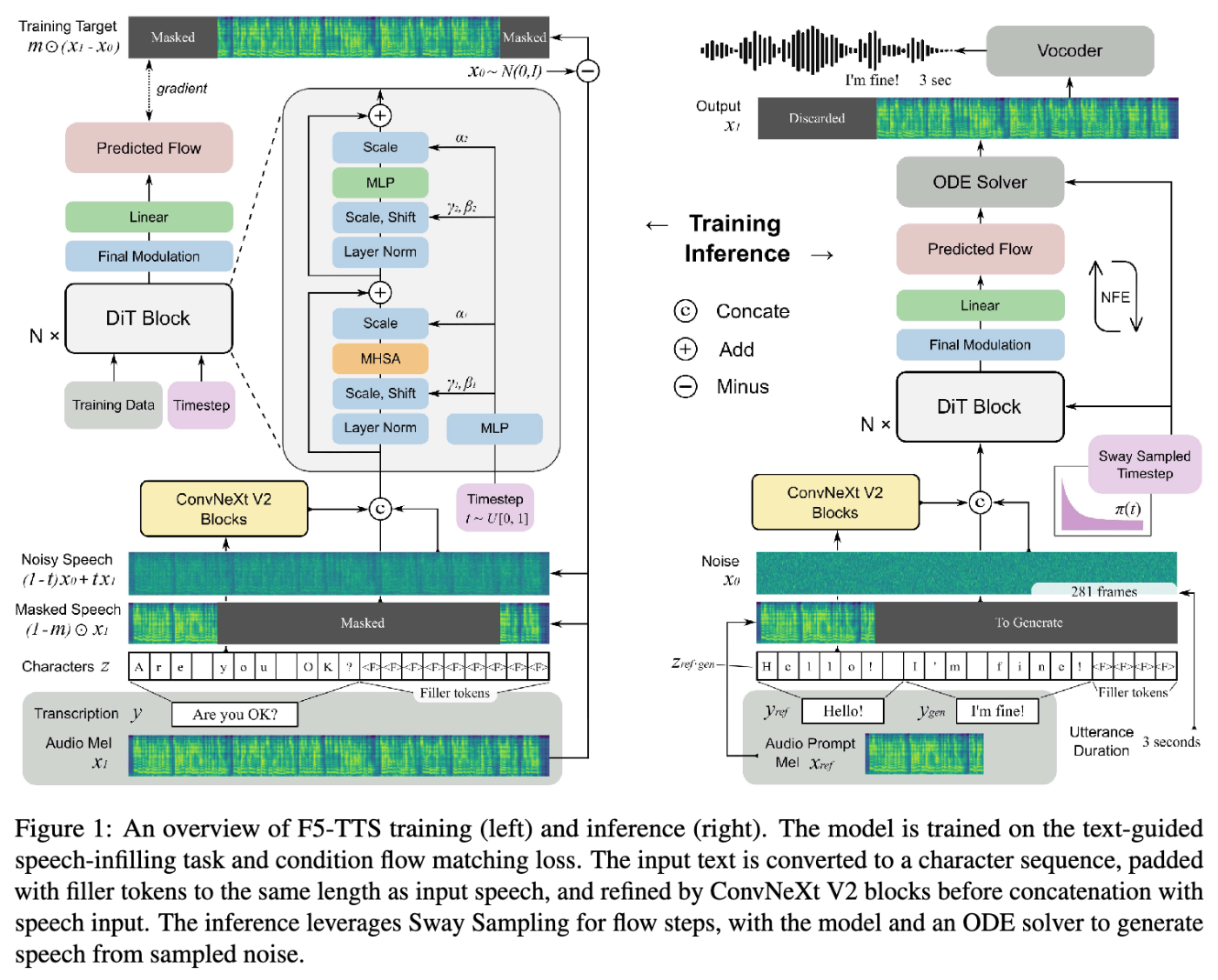
加えて、Codecモデルの埋め込み性能はモデル自体の表現能力や学習データの影響を受ける一方でメルスペクトログラムは影響を受けないこと、また取り扱いが簡単なことから、Flow Matchingを取り入れた手法(Matcha-TTS、CosyVoice2、F5-TTSなど)ではメルスペクトログラムを予測した後にNeural Vocoderで波形を復元しています。
(下図はF5-TTSのモデル構造で、Vocoderにより波形へと復元していることが確認できます)
このように、依然としてNeural Vocoderは音声合成の品質向上のための重要な研究分野の1つです。
Wavehaxの詳細
従来手法:時間領域で処理するNeural Vocoder
時間領域で処理する代表的なNeural VocoderとしてはParallel WaveGAN、MelGAN、HiFi-GAN、BigVGANなどがあります。
これらの手法では、音響特徴量に基づいて直接的に波形を生成します。
このうち、Parallel WaveGAN・MelGAN・HiFi-GANは本質的にエイリアシングノイズの問題を抱えています。
エイリアシングとは、高域に現れるはずの成分がサンプリングの影響でナイキスト周波数を超えた分だけ低域に折り返して現れる現象のことで、これによって引き起こされる歪みをエイリアシングノイズと呼びます。
これらの手法では「Conv1d→活性化関数」の繰り返しにより波形を生成しますが、このうち畳み込みは帯域通過フィルタの集合体であるためエイリアシングを引き起こしません。
一方で、活性化関数はエイリアシングを引き起こします。
Wavehaxの論文中では代表的な活性化関数であるReLUのフーリエ級数展開が示されています。

ここから、ReLUを適用することでその偶数倍の周波数成分が生成されることがわかります。
これは人間の声に含まれる基本周波数の高調波を生成する上では良いバイアスとして働きますが、その一方でエイリアシングノイズにより生成音声が歪みます。
これを改善する手法がBigVGANです。
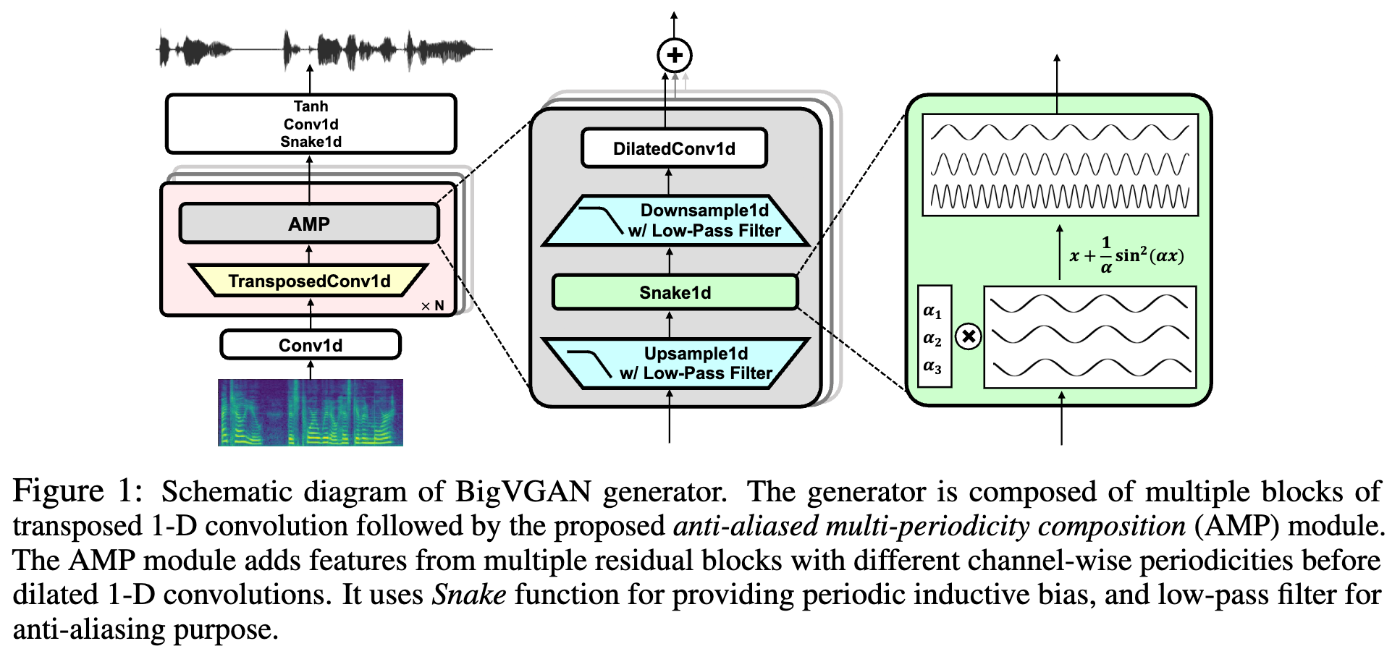
BigVGANはStyleGAN3のアンチエイリアシング機構を活性化関数の前後に導入しました(図はBigVGANの論文より引用)。
この処理の流れはWavehaxの論文中のFig.1で示されています。
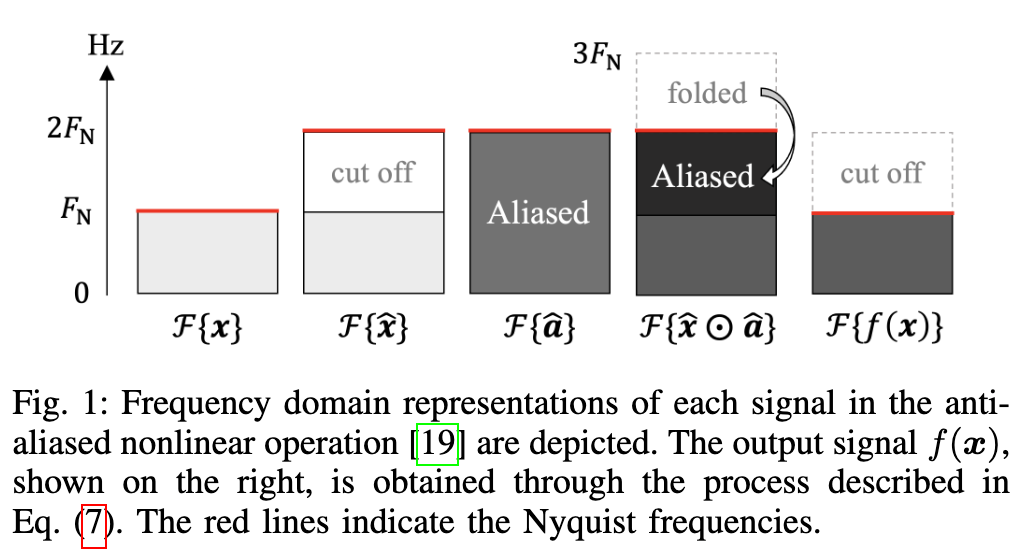
まず、入力信号
これに対し、エイリアシングを引き起こす非線形処理
最後にこれをローパスフィルタにより削ぎ落とした後にダウンサンプリングすることで、元々の信号
これにより、実際にBigVGANでは歪みの少ない綺麗な高調波を生成できています(図はBigVGANの論文より引用)。

しかしながら、これにもいくつかの問題があります。
- 計算コストの問題:追加の処理を必要とするため、計算コストが増加します。
- 品質の問題:フィルタサイズが小さいと、エイリアシングノイズを除去しきれません。一方で、エイリアシングの影響をできる限り小さくするためにはローパスフィルタのフィルタサイズを大きくする必要がありますが、大きくすればするほど計算コストが大幅に増加します。
このように、BigVGANのように時間領域で処理するNeural Vocoderに対してアンチエイリアシング処理を適用しても、原理的にエイリアシングノイズの影響を0にすることはできず、また計算コストと品質のトレードオフの問題が解決できません。
Wavehax:時間周波数領域で処理するConv2d型Neural Vocoder
Wavehaxは、時間周波数領域(スペクトログラム)で処理し、iSTFT(逆短時間フーリエ変換)で時間領域に戻すことで波形を生成することにより、時間領域で処理することで発生するエイリアシングノイズの問題を解決します。
モデル構造
Wavehaxのモデル構造を以下に示します。
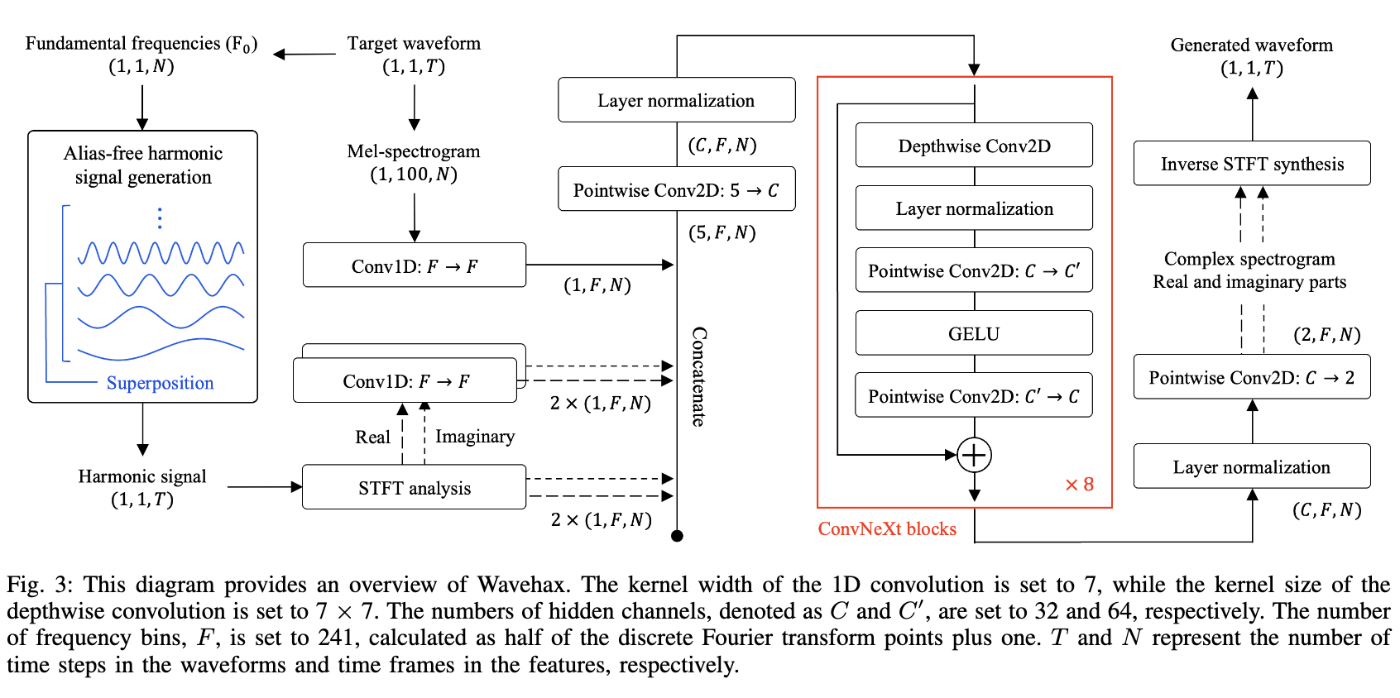
処理の流れを追うと、まずはメルスペクトログラムをメルスケールから通常のスペクトログラムのスケールにConv1dで射影したものに対し、F0に基づいて生成した周期信号の振幅・位相スペクトログラムとそれらをConv1dで射影をしたものをconcatして5チャネルにしたものを用意します。
これに対してPoint-wise Conv2dを用いてチャネル数を調整し、またLayerNormを適用した後に、8層の2次元のConvNeXt Blockを適用します。
最後に、LayerNormの適用と、Point-wise Conv2dでチャネル数を調整したのち、iSTFTで波形領域へと戻すことで合成音声を得ることができます。
続いて、ポイントとなっている2点を紹介します。
ポイント1つ目:時間周波数領域での2次元畳み込みによる処理
時間領域で非線形処理を適用すると、エイリアシングノイズが発生してしまい生成音声が歪むことを先ほど述べました。
一方で、周波数領域でConv2dにより処理をすると、ここまでで問題になっていたエイリアシングノイズは発生しません(Conv1dも使用されていますが、あくまでチャネルの調整等の役割のみです)。
なお、スペクトログラムを画像とみなした時のエイリアシングノイズは発生しますが、U-NetのようなDown/Upsamplingに基づく構造にはなっていないため、比較的この問題は表出しづらいのかなと思います(加えて、これは時間領域での処理によるエイリアシングノイズよりも人間の知覚的に致命的ではないと思われます)。
また、時間周波数領域でConv1dにより処理している手法としてVocosがありますが、これは2つ目でも述べますがWavehaxではHarmonic PriorとConv2dを併用することでConv2d部分はベース信号に肉付けするだけのネットワークになります。
Vocosではそのような構造になっておらず、大量のパラメータで力技により学習するため、未知の状況における頑健性が低いことがWavehaxの論文中の実験により確かめられています。
ポイント2つ目:Harmonic Priorによる周期情報の付与
時間領域で処理する場合は、非線形処理により自動的に高調波成分が生成されます。
しかしながら、Conv2dの場合は各周波数帯を局所的にしか見れないため、高調波のように「スペクトログラム上で等間隔に並んでいる縞模様」を作成することはできません(非常に大規模なネットワークを使えば不可能ではないかもしれませんが、速度が求められるニューラルボコーダには不向きです)。
そこで、事前に以下の式によりエイリアシングが発生しないように高調波を含めた信号を生成し、これをConv2d処理の入力に用います。

これにより、Conv2d部分は「ベース信号の上に声色や掠れ具合などを肉付けし、位相情報を調整するだけ」になり、小さいネットワークでも高品質・高速に動作することを実現できています。
実際、Wavehaxのパラメータ数は1Mもなく、Vocosには劣るもののCPUでも高速に動作することが論文中では示されています。

評価
Wavehaxの論文では、JVSコーパスを用いて評価しています。

このうち、Ⅲが学習データのF0分布上限よりも高いF0を含む発話での評価結果を意味しています。
HiFi-GANやVocos、またそれらに周期信号を導入したモデルでは「学習データに含まれるF0分布の範囲で発生するエイリアシングノイズのパターンを覚え、打ち消すような処理を内部で学んでいる」ために、このような非線形処理によりナイキスト周波数を超えやすくエイリアシングノイズの影響が大きくなりやすい学習分布外の高いF0を含むデータでは、品質が非常に劣化しています。
一方で、Wavehaxは品質劣化を大幅に抑制できていることが確認できます。
また、これは以下の結果からも確認でき、学習データの分布外についても歪みが少ないことがわかります。
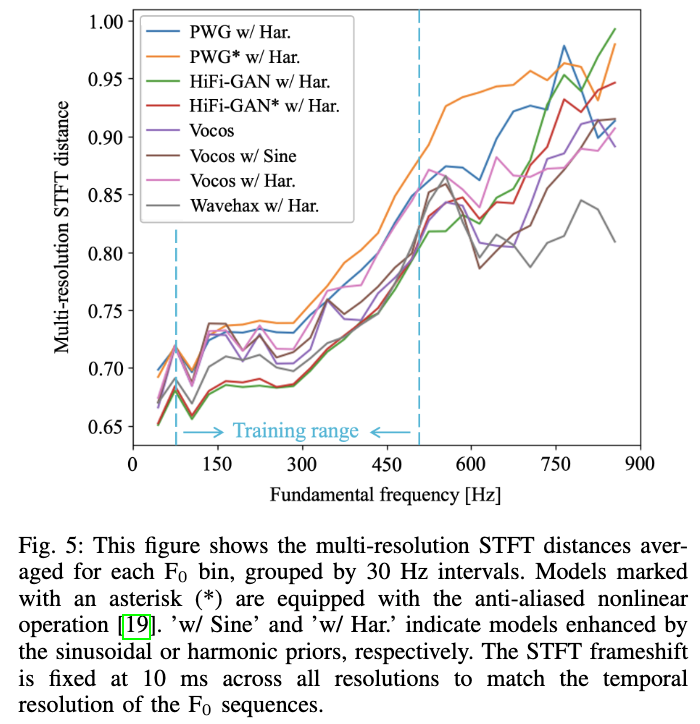
以上から、Wavehaxを合成時に使用することで、「学習データに含まれないF0レンジでも高品質に歌声合成する」「学習データに含まれないF0の声の高さに高品質に変換する」「CPUでも軽量に合成できる」などを実現することができます。
Wavehaxを試す
学習
Wavehaxは公式のリポジトリが公開されています。
これを使用して公式のレシピでJVSコーパスによる学習を行いました。
以下はuvで環境構築し、学習を行うまでの手順です(uvの事前インストールが必要です)。
# リポジトリのclone
$ git clone https://github.com/chomeyama/wavehax.git
$ cd wavehax
# uvによる仮想環境の構築とアクティベート
$ uv venv
$ source .venv/bin/activate
# 環境構築
$ uv pip install -e .
# 作業ディレクトリに移動
$ cd egs/jvs
# データセットの用意
$ uv pip install gdown
$ cd data
$ gdown --fuzzy https://drive.google.com/file/d/19oAw8wWn3Y7z6CKChRdAyGOB9yupL_Xt/view
$ unzip jvs_ver1.zip
# scp・listファイルをそのまま使用するにはデータセットのリネームが必要なため、処理
$ mv jvs_ver1 ver1
$ find ./ver1 -mindepth 3 -maxdepth 3 -type d -name 'wav24kHz16bit' \
-exec bash -c 'for d; do p=${d%/wav24kHz16bit}; [[ -e "$p/wav" ]] && { echo "skip: $p/wav exists" >&2; continue; }; mv "$d" "$p/wav"; echo "renamed: $d -> $p/wav"; done' _ {} +
# 音響特徴量の抽出
$ wavehax-extract-features audio_scp=data/scp/all.scp
# 音響特徴量の統計量の計算
$ wavehax-compute-statistics filepath_list=data/list/train_no_dev.list save_path=data/stats/train_no_dev.joblib
# 学習
## 論文では100万step学習していますが、READMEにはWavehaxは収束が早いと記載されており、デフォルトも50万stepだったため、これで実行
$ wavehax-train generator=wavehax.v1 discriminator=univnet train=wavehax train.train_max_steps=500000 data=jvs out_dir=exp/wavehax
# ロス等の監視
$ tensorboard --logdir exp/wavehax
学習にはH200GPU1枚を使用し、およそ8時間で完了しました。
なお、学習中は100000stepごとにwavehax/egs/jvs/exp/waevhax以下にcheckpointが保存されるため、途中のモデルを用いて推論することも可能です。
また、scp・listファイルを手持ちのデータセット用に作成することで、JVS以外のデータセットでも学習することが可能です。
また、今回学習したモデルはこちらで公開しています。
推論・評価
以下のコマンドを実行すると、wavehax/egs/jvs/exp/wavehax以下に論文中の「Ⅰ」の評価データセットの音声が合成されます。
$ wavehax-decode generator=wavehax.v1 data=jvs out_dir=exp/wavehax ckpt_steps=500000
評価データセットを変えたい場合は、コマンドを以下のように修正します。
# 論文中のⅡの評価データセットで推論したい場合
$ wavehax-decode generator=wavehax.v1 data=jvs out_dir=exp/wavehax ckpt_steps=500000 data.eval_feat=data/list/eval_low.list
# 論文中のⅢの評価データセットで推論したい場合
$ wavehax-decode generator=wavehax.v1 data=jvs out_dir=exp/wavehax ckpt_steps=500000 data.eval_feat=data/list/eval_high.list
なお、Hugging Faceで公開したモデルを使用する際は、まずこちらを以下の操作によりwavehax/egs/jvs/exp/wavehax/checkpoints/以下にダウンロードします。
# expディレクトリ以下が存在しない場合にディレクトリを作成
## wavehax/egs/jvs/にいる想定
$ mkdir -p exp/wavehax/checkpoints/
# ダウンロード
$ python
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="Parakeet-Inc/wavehax_jvs", filename="checkpoint-500000steps.pkl", local_dir="exp/wavehax/checkpoints/")
保存してから実行することで、学習不要で合成を試すことができます (ただし、データの用意と特徴量抽出・統計量の計算は必要です)。
今回学習したモデルを用いて論文中で評価に使用している以下の3つの評価データでPESQ・UTMOS・STOIを計測した結果を以下に示します(括弧内は論文で報告されているスコア)。
| 評価データセット | PESQ | UTMOS | STOI |
|---|---|---|---|
| Ⅰ(学習データのF0分布の評価データ) | 3.719(3.818) | 3.101(3.122) | 0.9574 |
| Ⅱ(学習データよりも低いF0を含む場合の評価データ) | 3.602(3.702) | 3.544(3.585) | 0.9613 |
| Ⅲ(学習データよりも高いF0を含む場合の評価データ) | 3.933(3.927) | 1.675(1.686) | 0.9312 |
論文内の結果は100万step学習時のものであるため、ⅢのPESQを除いて今回学習したモデルの方がスコアが若干低いですが、肉薄していることは確認できます。
またSTOIのスコアも、0.95前後で良いスコアになっているように感じられます。
内部の分析
Wavehaxのコアとなっている部分は2次元畳み込みによる時間周波数領域での処理ですが、この2D ConvNeXt Block(下図の赤の部分)でどのように学習されているのかが気になります。
これを分析するために、1から8層目(なお、ここでは1層=ConvNeXt Block1つを意味します)までの各層を抜いて処理した場合にどのように生成音声に影響が出るかを調査しました。
まず、元音声のスペクトログラムは以下です。
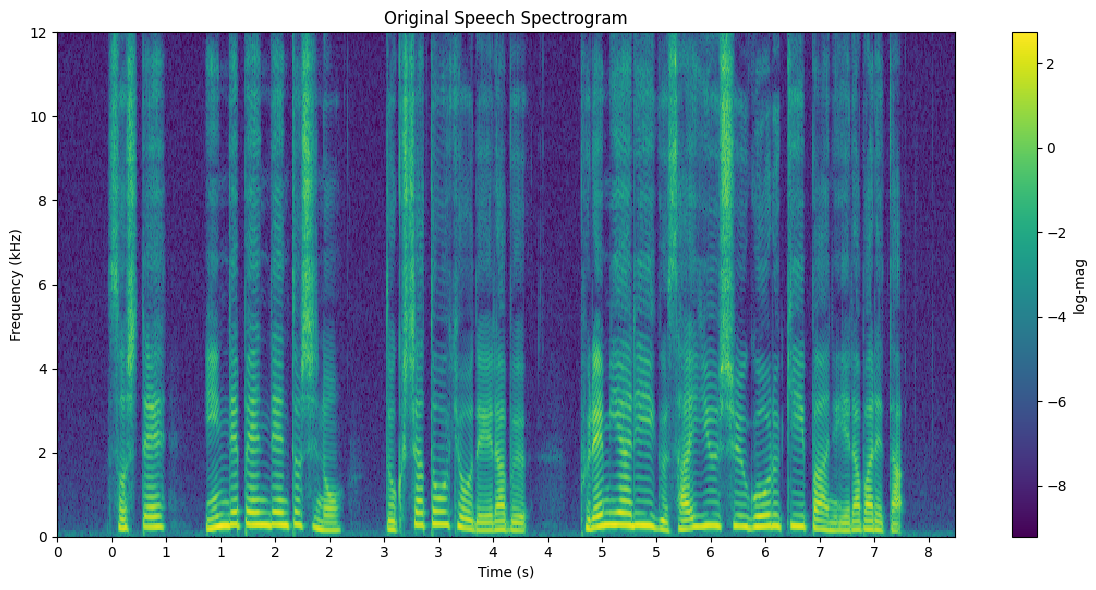
これに対し、何も操作していない通常のWavehaxにより分析合成された音声と、Wavehaxの特定の層を使用せずに生成された分析合成音声から計算されるスペクトログラムの差分を示します。

ここからいくつかわかることがありますが、そのうちの1つとして、およそ8kHz以上の高域成分に対し主に作用している層があることがわかります(特に5層目)。
これは、人間の音声のうち高域の成分については揺らぎが強く、そのモデル化のために特定の層が学習されていることを意味しています。
そのため、高域のモデル化に特化した層を低域にも適用することによる冗長性があるのではないかと考えられますが、実はこの点については既に著者の次の論文で解決されています。
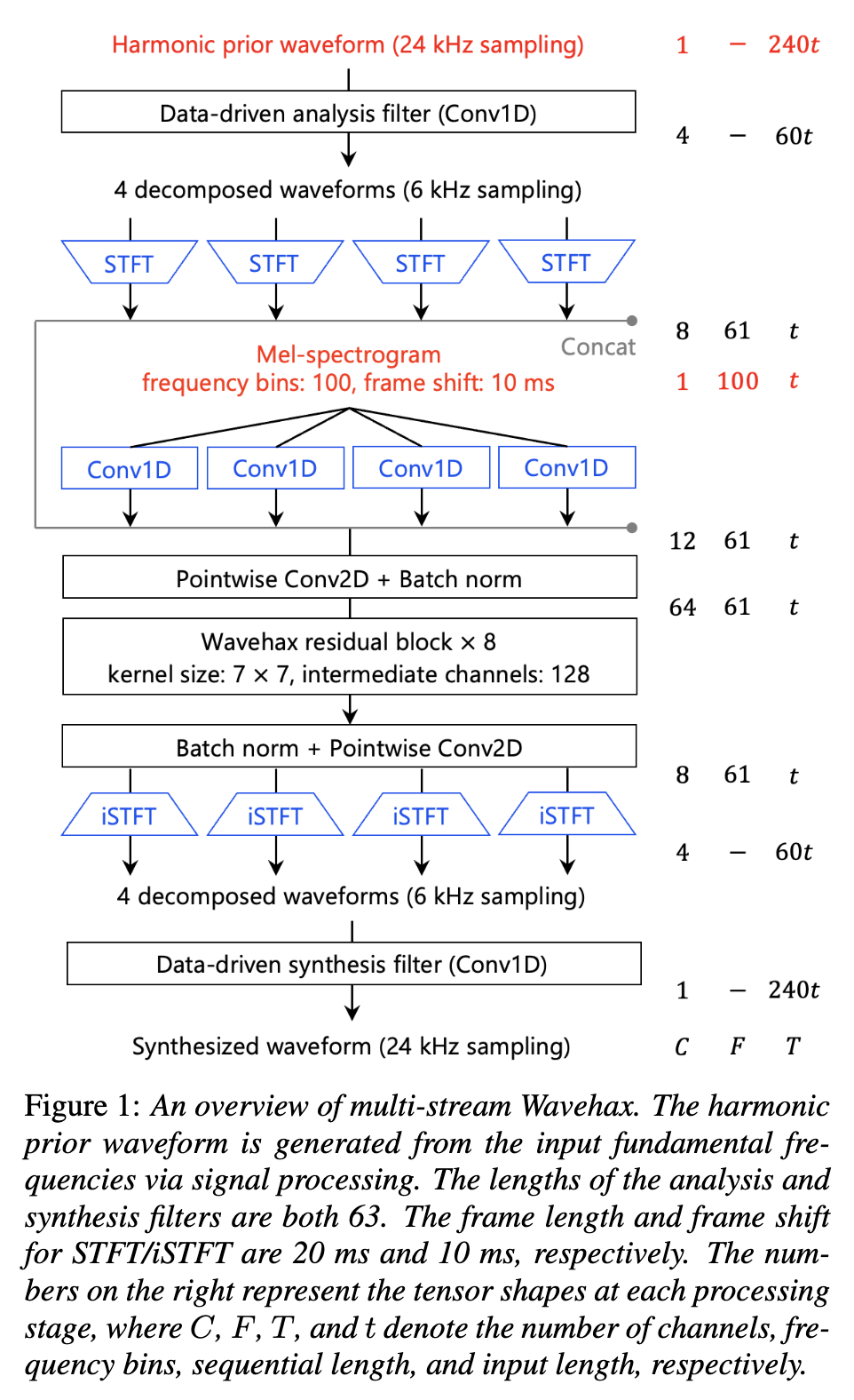
この論文では、先ほどの問題をサブバンド処理することで解決しています。
これにより、ある帯域に特化したフィルタが別の帯域に適用されるようなことはなく、結果として計算量の削減と品質向上を実現しています。
青がWavehaxで、また斜線がmulti-streamモデル(サブバンド処理を行っているモデル)を示しており、青色のバーの上2つを確認するとmulti-streamモデルの方が高品質であることが主観評価により確かめられています。
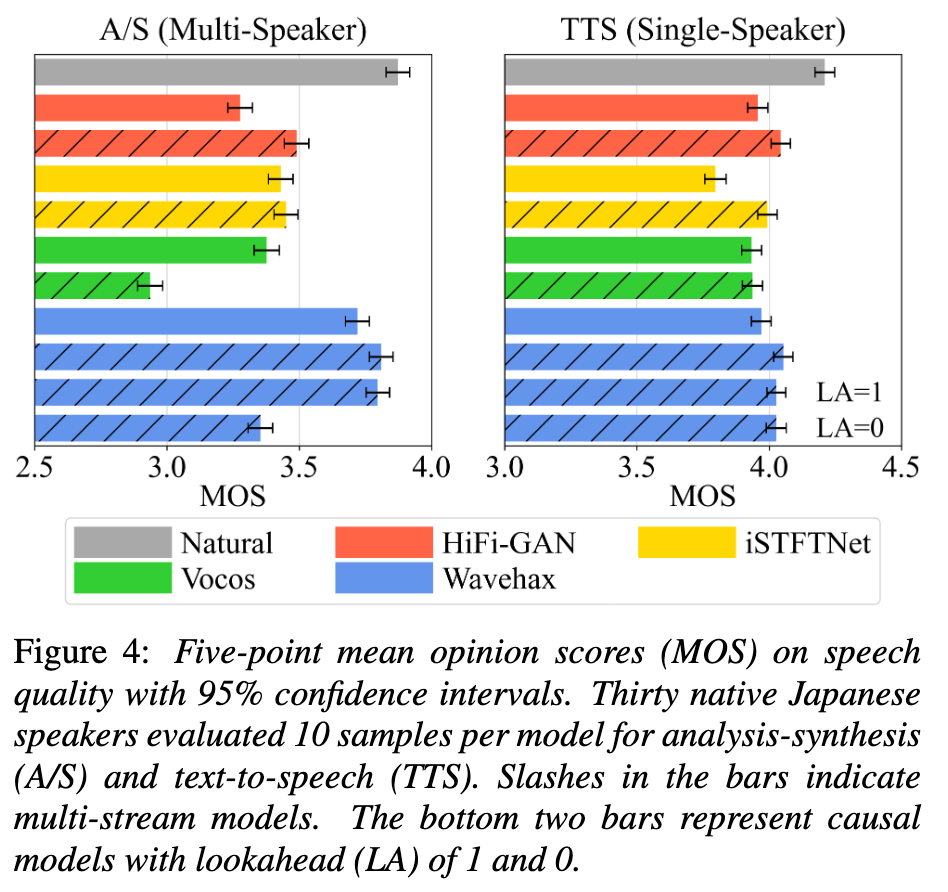
おわりに
今回は時間周波数領域で処理するNeural Vocoder、Wavehaxについて紹介しました。
本手法は高速・高品質に動作しつつ、F0のレンジについても頑健であるため、例えば弊社製品のボイスチェンジャー『Paravo』への応用も期待できます。
今後も隔週で論文紹介などをしていきますので、ぜひフォローしてお待ちください!

Discussion