はじめに
こんにちは、Parakeet株式会社リサーチャーの今井(X: Nuts)です。
4月に韓国ソウルで開催された音声・信号処理に関するトップカンファレンスICASSP2024にて発表されたニューラルボコーダの全論文9本と音声変換の全論文21本をまとめました(抜けがあったらご連絡ください)。
※本記事ではプレプリントとして投稿されている論文のみリンクを貼っており、また添付している画像もプレプリントから、もしくは公開されているデモページ等からのみ引用しています。
ニューラルボコーダ全論文まとめ
Fregrad: Lightweight and Fast Frequency-Aware Diffusion Vocoder
- paper: https://arxiv.org/abs/2401.10032
- code: https://github.com/signofthefour/fregrad
- demo: https://mm.kaist.ac.kr/projects/FreGrad/
- T. D. Nguyen, J. -H. Kim, Y. Jang, J. Kim and J. S. Chung, "Fregrad: Lightweight and Fast Frequency-Aware Diffusion Vocoder," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 10736-10740, doi: 10.1109/ICASSP48485.2024.10447251.
- まとめ
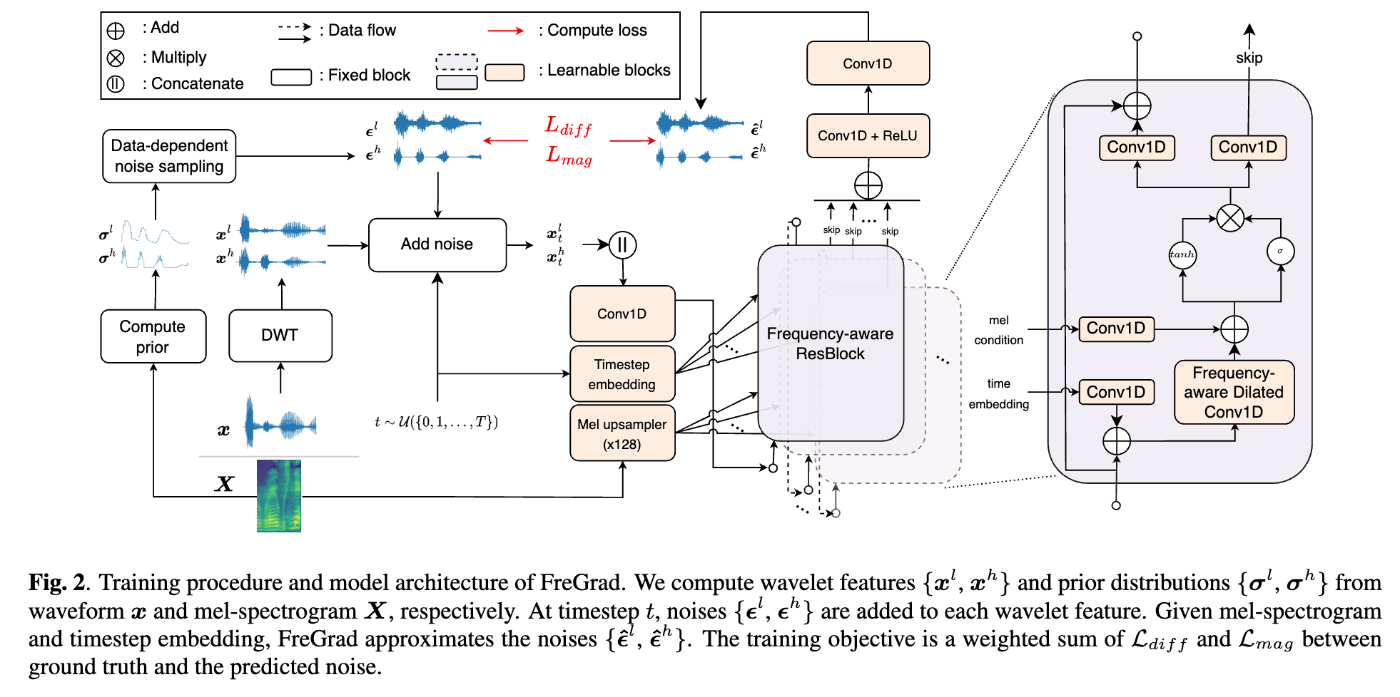
- 高速・軽量・高品質なDiffusionベースのニューラルボコーダを目指して、主に以下を提案。
- 離散ウェーブレット変換(DWT)を適用し、波形を低周波・高周波成分に分割してからネットワークを学習。
- Fre-GANやFre-GAN2、Multi-band MelGANと類似のアイディア。
- DWT→Dilated Conv→iDWTで効率的に受容野を広げ、かつ異なる帯域を独立して処理可能なFrequency-aware Dilated Convolutionを提案。
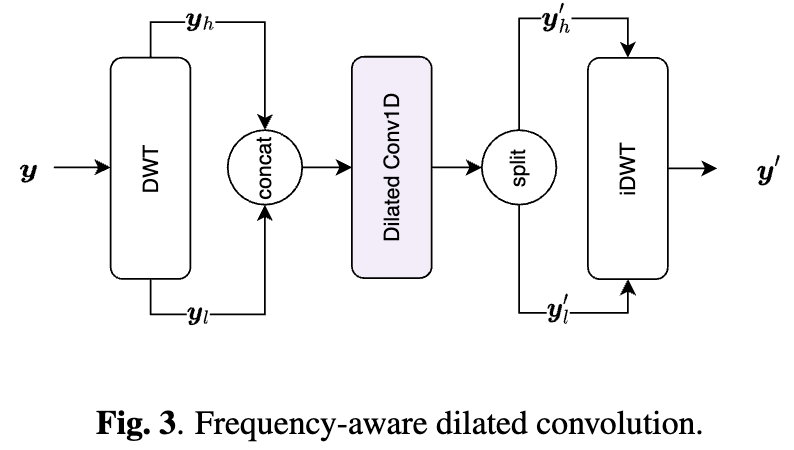
- 離散ウェーブレット変換(DWT)を適用し、波形を低周波・高周波成分に分割してからネットワークを学習。
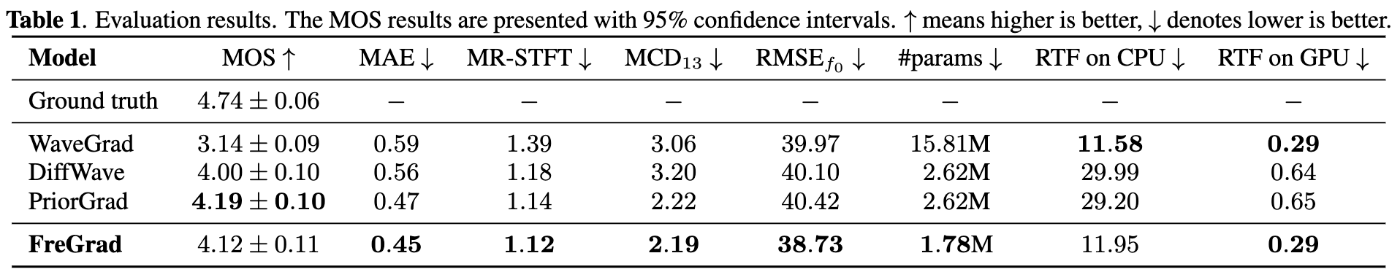
- 先行研究のPriorGradと比べてパラメータ数やRTFを改善しつつも品質はある程度維持。
- Ablation studyにより、特にFrequency-aware Dilated Convolutionの効果を確認。
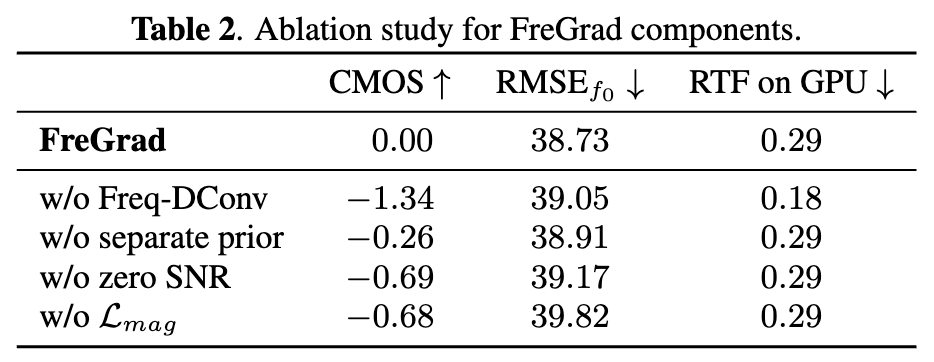
- ただし、推論時間は50%増加。
- 高速・軽量・高品質なDiffusionベースのニューラルボコーダを目指して、主に以下を提案。
PeriodGrad: Towards Pitch-Controllable Neural Vocoder Based on a Diffusion Probabilistic Model
- paper: https://arxiv.org/abs/2402.14692
- demo: https://www.sp.nitech.ac.jp/~hono/demos/icassp2024/
- Y. Hono, K. Hashimoto, Y. Nankaku and K. Tokuda, "PeriodGrad: Towards Pitch-Controllable Neural Vocoder Based on a Diffusion Probabilistic Model," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 12782-12786, doi: 10.1109/ICASSP48485.2024.10448502.
- まとめ
- 問題点:既存のDiffusionベースのニューラルボコーダは歌声の合成品質が低く、またF0制御ができない。
- 解決策:事前分布としてF0に基づく周期信号も考慮。
- GANベースで周期信号を考慮したニューラルボコーダであるPeriodNet(こちらも法野らの論文)には負けるものの、PriorGradと比べてF0制御性を改善。
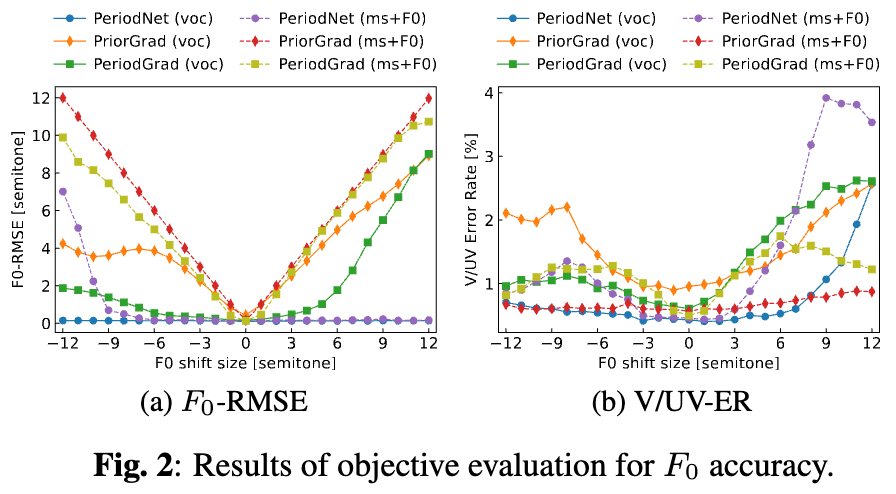
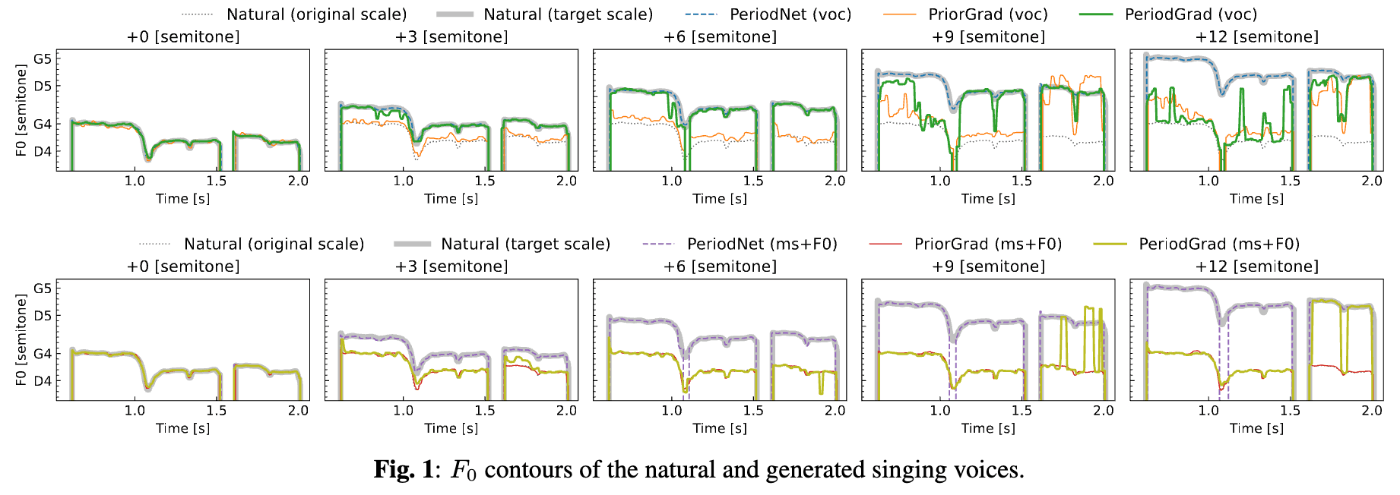
- メルケプストラム+BAPを使用した場合(voc)の方がメルスペクトログラムを使用した場合(ms+F0)と比べてF0制御性が高いことを確認。
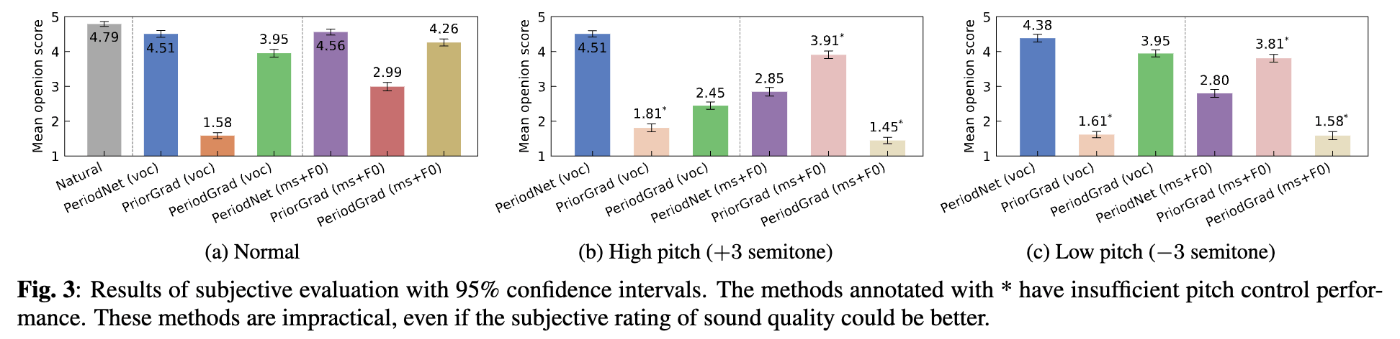
- PriorGradと比べてMOSは大幅に改善するが、PeriodNetには劣る。
Langwave: Realistic Voice Generation Based on High-Order Langevin Dynamics
- demo: https://shiziqiang.github.io/langwave/
- Z. Shi and R. Liu, "Langwave: Realistic Voice Generation Based on High-Order Langevin Dynamics," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 10661-10665, doi: 10.1109/ICASSP48485.2024.10447389.
- まとめ
- 3次ランジュバン動力学を解く新しいニューラルボコーダの提案。
- 既存のDiffusionに基づくニューラルボコーダよりも品質の向上を実現。
FIRNet: Fundamental Frequency Controllable Fast Neural Vocoder With Trainable Finite Impulse Response Filter
- paper: https://ast-astrec.nict.go.jp/release/preprints/preprint_icassp_2024_ohtani.pdf
- demo: https://ast-astrec.nict.go.jp/demo_samples/firnet_icassp2024/
- Y. Ohtani, T. Okamoto, T. Toda and H. Kawai, "FIRNet: Fundamental Frequency Controllable Fast Neural Vocoder With Trainable Finite Impulse Response Filter," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 10871-10875, doi: 10.1109/ICASSP48485.2024.10446960.
- まとめ
- F0制御性が高く高速に推論可能なニューラルボコーダを目指し、ネットワークで予測したFIRフィルタで混合励振源を複数回畳み込むことで音声波形を生成する仕組みを提案。
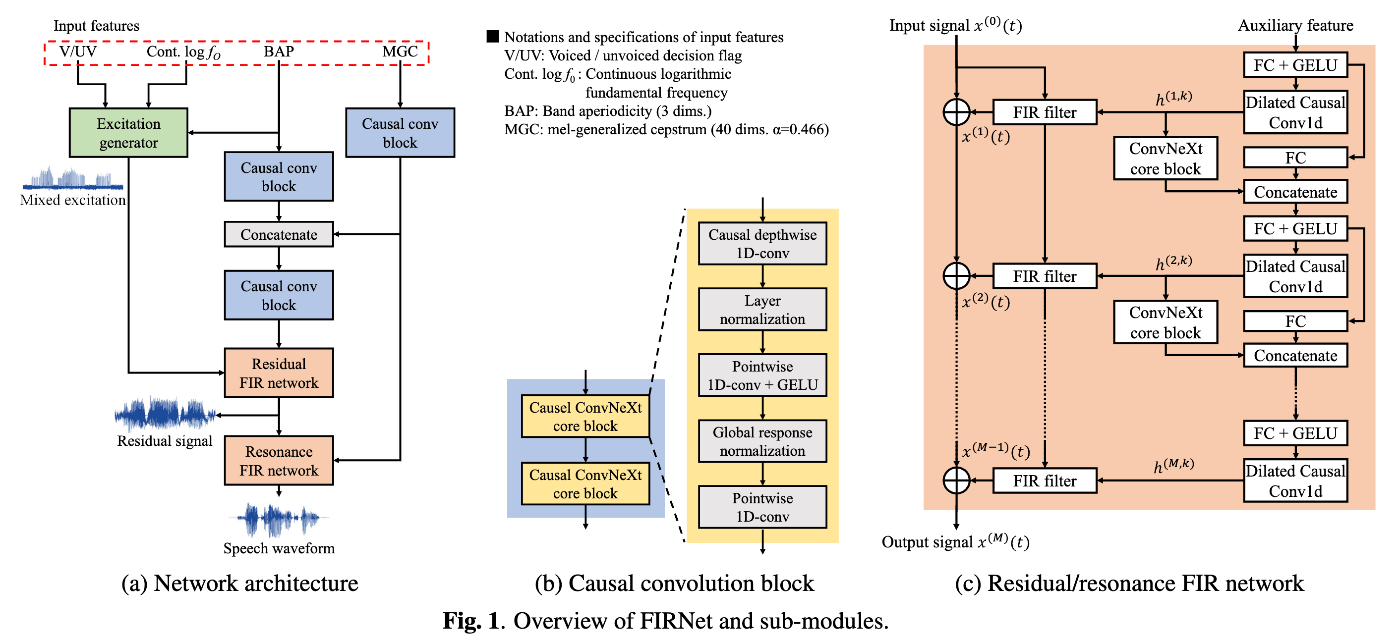
- FIRフィルタを畳み込むネットワークはResidual FIR networkとResonance FIR networkの2つに分割(先行研究かつ従来手法のSiFi-GANに類似)。
- Residual FIR network(FIRフィルタ8層)
- 声道情報が含まれないResidual signalを予測。
- ターゲットとなる自然音声のスペクトログラムからその包絡成分を引いたものがResidual signalのスペクトログラムとなるように損失関数を適用。
- 詳しくはSiFi-GANやHN-uSFGAN、HN-uSFGANの公式実装を参照。
- Resonance FIR network(FIRフィルタ8層)
- 声道情報(メルケプストラム)を用いてResidual signalに音色付け。
- Residual FIR network(FIRフィルタ8層)
- この2つのネットワークにより、段階的に波形が生成されることが確認できる。
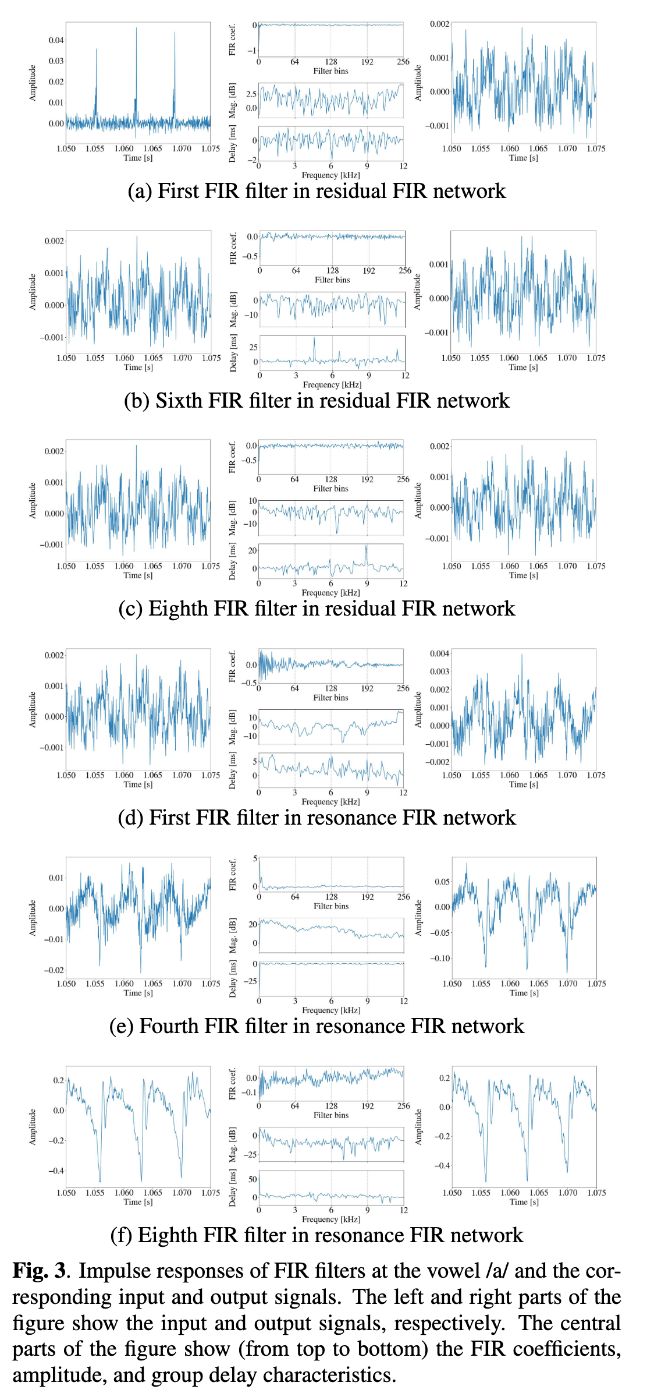
- FIRフィルタを畳み込むネットワークはResidual FIR networkとResonance FIR networkの2つに分割(先行研究かつ従来手法のSiFi-GANに類似)。
- 客観評価により、F0をシフトさせてもMCDが大幅に劣化しないことを確認。
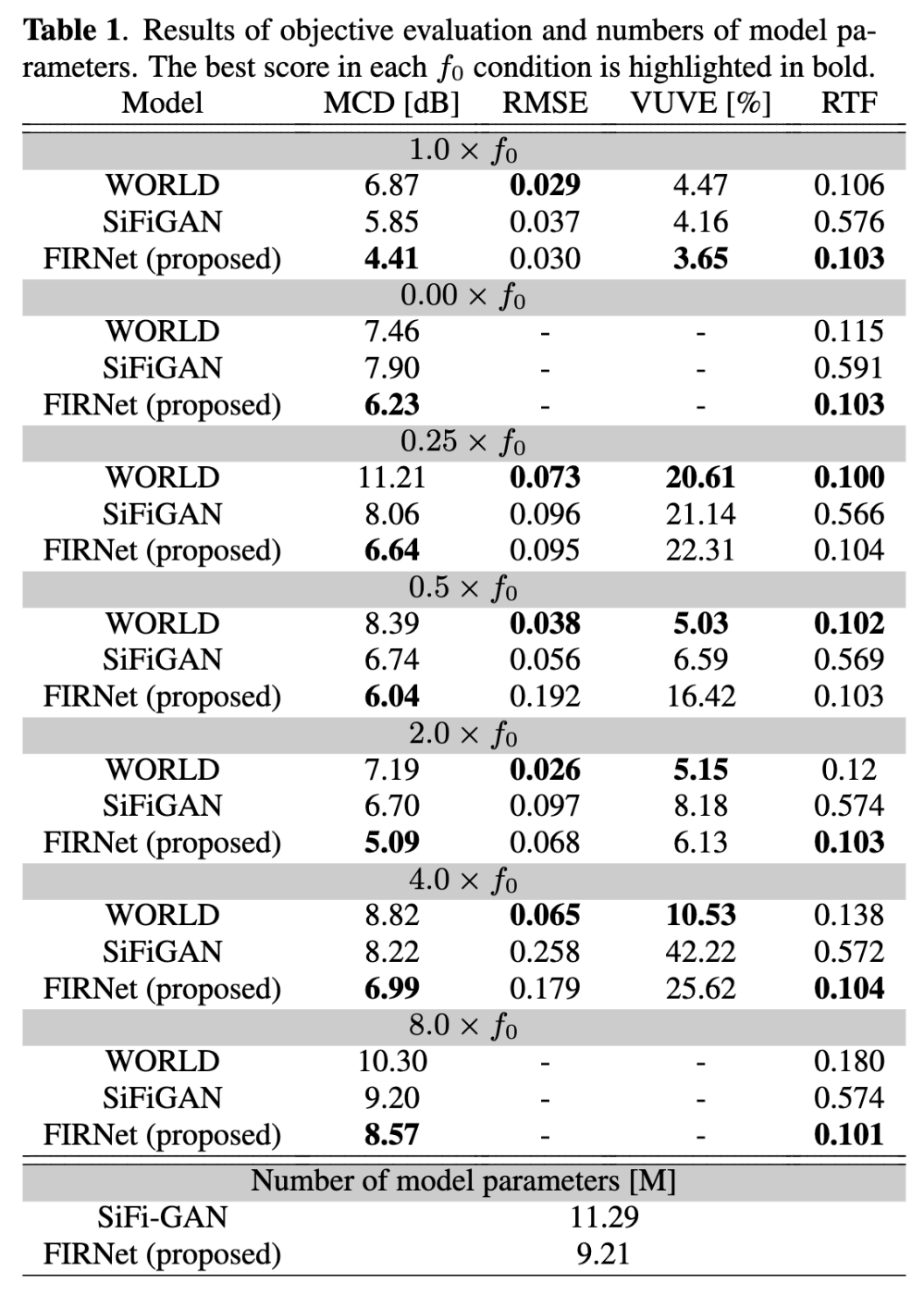
- なお、24kHzの音声生成において、AMD EPYC 7542の1コアを用いた場合に実時間の10倍速で波形が生成可能(従来法のSiFi-GANよりおよそ6倍近く高速)。
- 主観評価により、F0を極端に変化させるケースにおいてSiFi-GANよりも品質が高いことを確認。
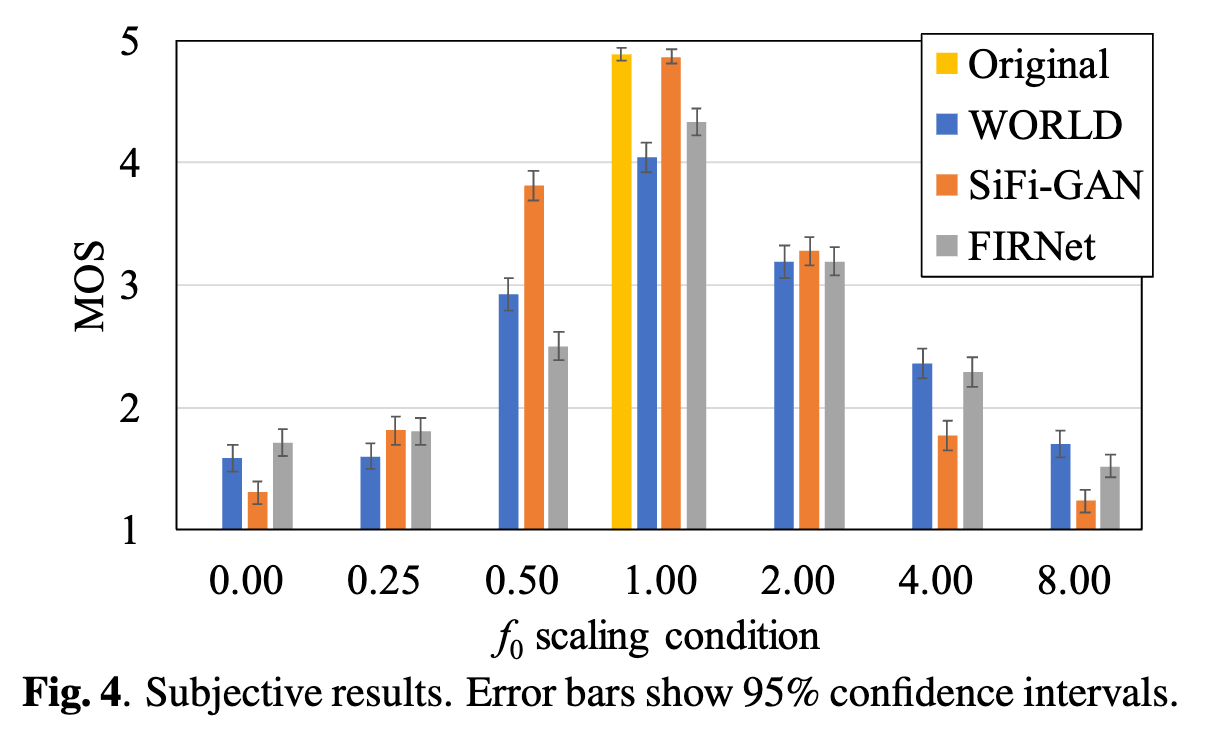
- ただし、F0制御しない場合や0.5~2.0倍程度の制御だと従来手法の方が高品質。
- F0制御性が高く高速に推論可能なニューラルボコーダを目指し、ネットワークで予測したFIRフィルタで混合励振源を複数回畳み込むことで音声波形を生成する仕組みを提案。
BigVSAN: Enhancing GAN-based Neural Vocoders with Slicing Adversarial Network
- paper: https://arxiv.org/abs/2309.02836
- code: https://github.com/sony/bigvsan
- demo: https://takashishibuyasony.github.io/bigvsan/
- T. Shibuya, Y. Takida and Y. Mitsufuji, "BIGVSAN: Enhancing Gan-Based Neural Vocoders with Slicing Adversarial Network," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 10121-10125, doi: 10.1109/ICASSP48485.2024.10446121.
- まとめ
-
BigVGANのGANの仕組みをSlicing Adversarial Network(SAN)に置き換えることで生成音声の品質改善。

- BigVGAN以外のGANベースのニューラルボコーダでも、SANを用いることの有効性をFADにより確認。
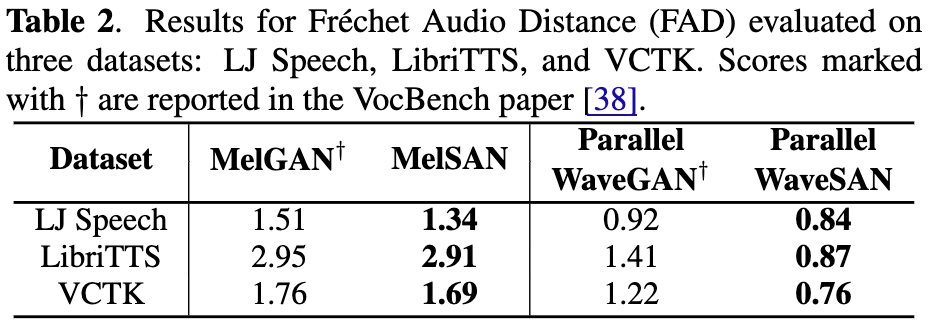
-
BigVGANのGANの仕組みをSlicing Adversarial Network(SAN)に置き換えることで生成音声の品質改善。
Multi-Scale Sub-Band Constant-Q Transform Discriminator for High-Fidelity Vocoder
- paper: https://arxiv.org/abs/2311.14957
- code: https://github.com/open-mmlab/Amphion/tree/main/egs/vocoder/gan/tfr_enhanced_hifigan
- demo: https://www.yichenggu.com/MS-SB-CQTD/
- Y. Gu, X. Zhang, L. Xue and Z. Wu, "Multi-Scale Sub-Band Constant-Q Transform Discriminator for High-Fidelity Vocoder," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 10616-10620, doi: 10.1109/ICASSP48485.2024.10448436.
- まとめ
- 歌声合成におけるGANベースボコーダの品質改善のために、定Q変換に基づくDiscriminatorを提案。
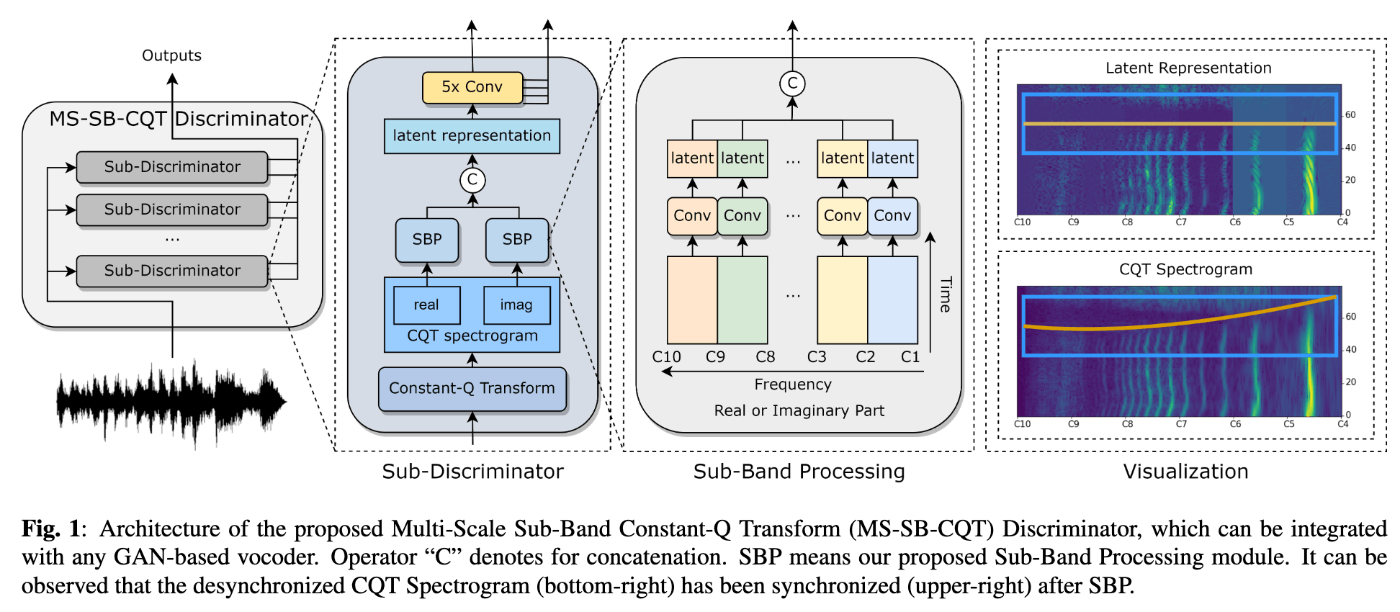
- 音声波形に対して、オクターブごとのbin数を24、36、48とした3つの定Q変換を実施し、対応したDiscriminatorに入力する。
- Discriminatorの内部では、各オクターブごとにサブバンドに分割してから帯域ごとの畳み込み層に入力することで、潜在変数の時間的同期をとる。
- この操作をしないと、baselineよりも悪化する。
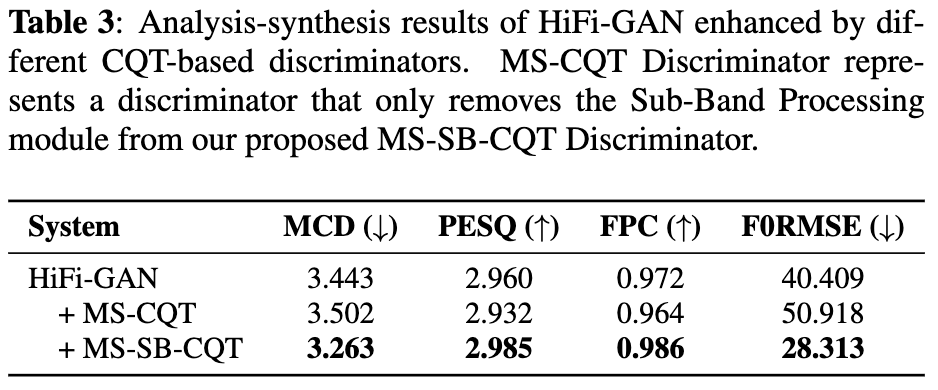
- この操作をしないと、baselineよりも悪化する。
- 歌声でも話し声でも、提案手法のDiscriminatorをBaselineのHiFi-GANのDiscriminatorに加えることで品質を改善。
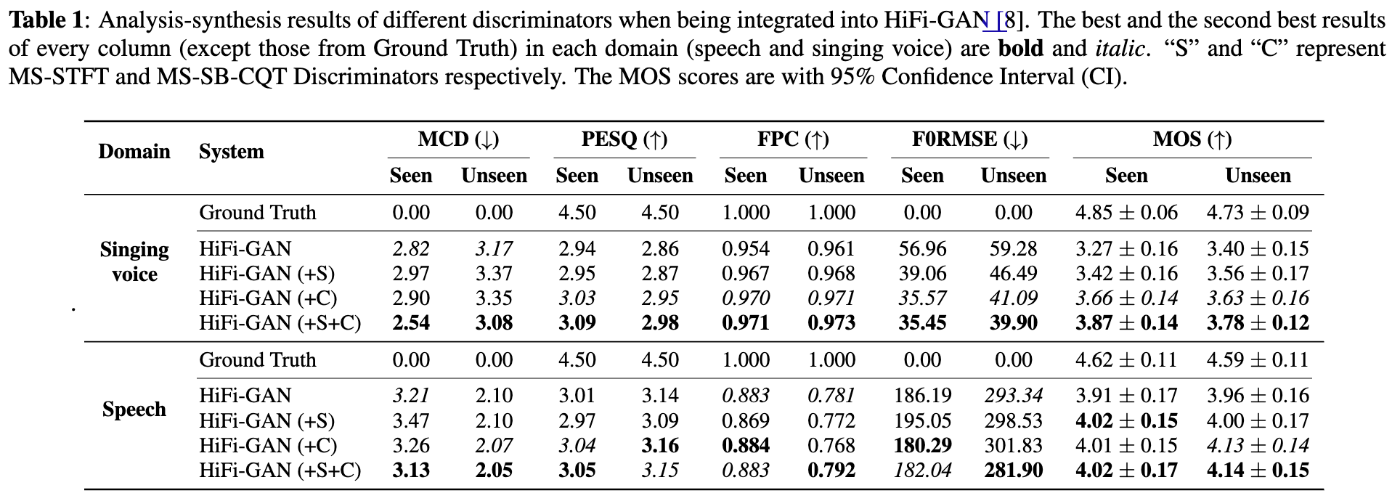
- なお、EnCodecのMulti-Scale STFT Discriminatorを追加することで品質はさらに改善。
- HiFi-GAN以外のニューラルボコーダでも効果を確認。
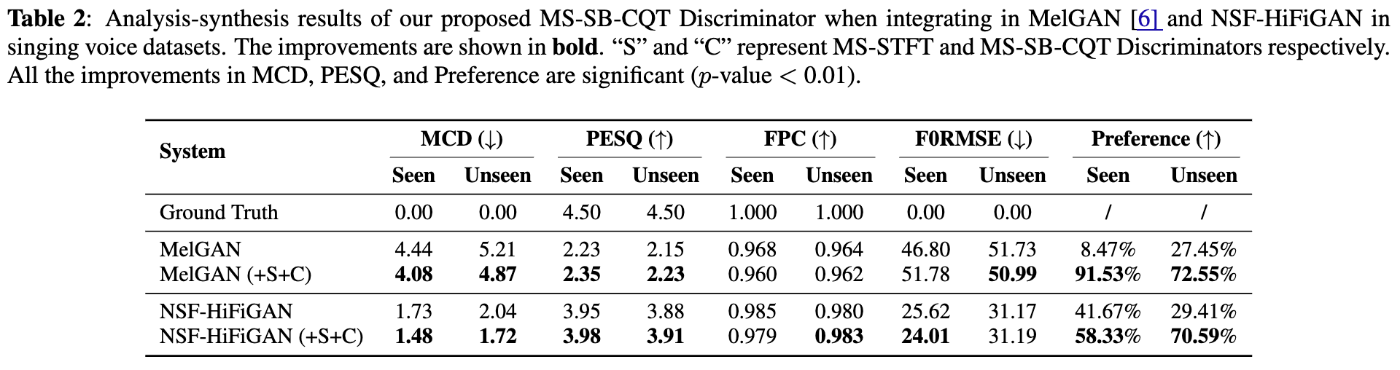
- 歌声合成におけるGANベースボコーダの品質改善のために、定Q変換に基づくDiscriminatorを提案。
Training Generative Adversarial Network-Based Vocoder with Limited Data Using Augmentation-Conditional Discriminator
- paper: https://arxiv.org/abs/2403.16464
- demo: https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/augcondd/
- T. Kaneko, H. Kameoka and K. Tanaka, "Training Generative Adversarial Network-Based Vocoder with Limited Data Using Augmentation-Conditional Discriminator," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 12561-12565, doi: 10.1109/ICASSP48485.2024.10445914.
- まとめ
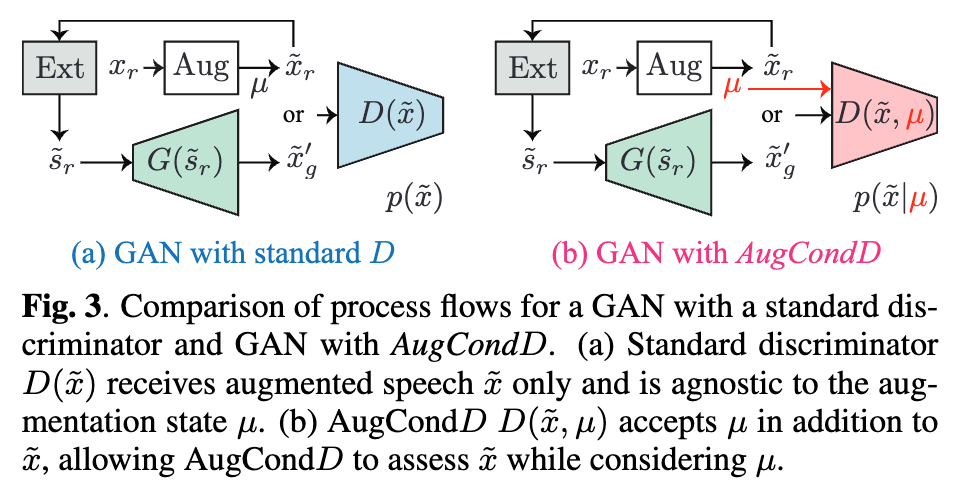
- 問題点:少量のデータでGANベースボコーダを学習する場合、augmentによりデータを水増ししたいが、Discriminatorがaugmentされた音声を自然音声だと判断し学習が適切に進まなくなる場合がある。
- 解決策:Discriminatorにaugmentに関する情報を与える。
-
mixupによりaugmentしつつ、混合の度合いに関する情報をDiscriminatorに入力する。
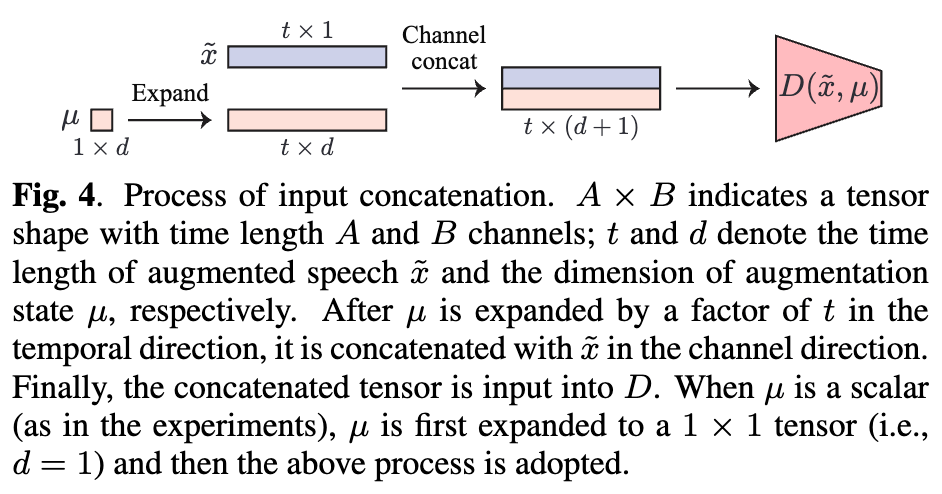
-
mixupによりaugmentしつつ、混合の度合いに関する情報をDiscriminatorに入力する。
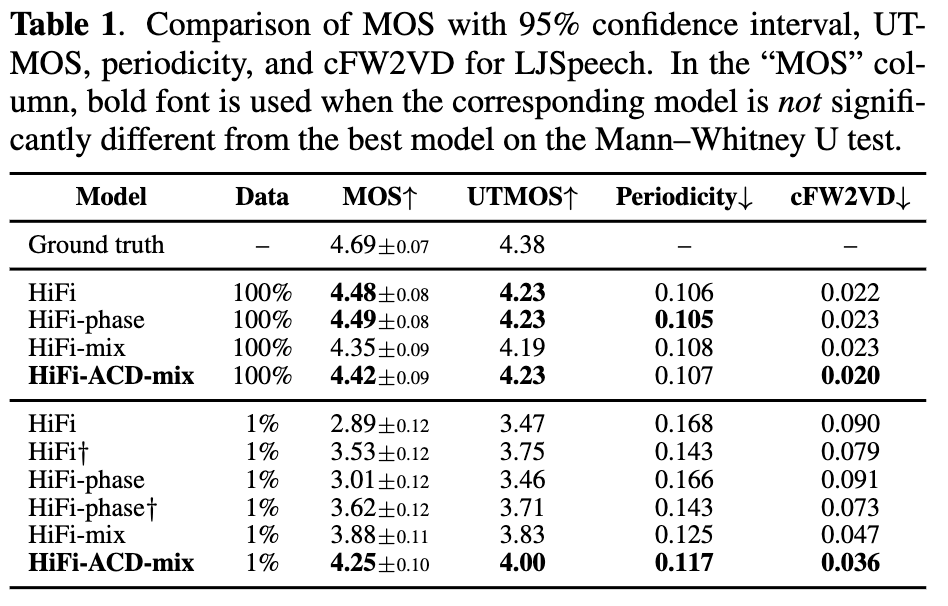
- 大規模データ(LJSpeech12950文、23.7h)で学習した場合の品質を落とさずに、小規模データ(LJSpeech130文、14.4m)で学習した場合の品質を大幅に改善。
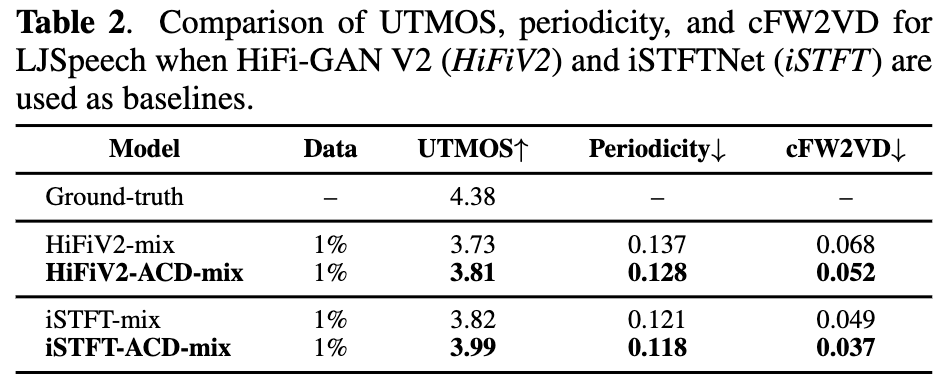
- 上記の実験に使用したHiFi-GAN V1以外のGeneratorアーキテクチャでも再現。
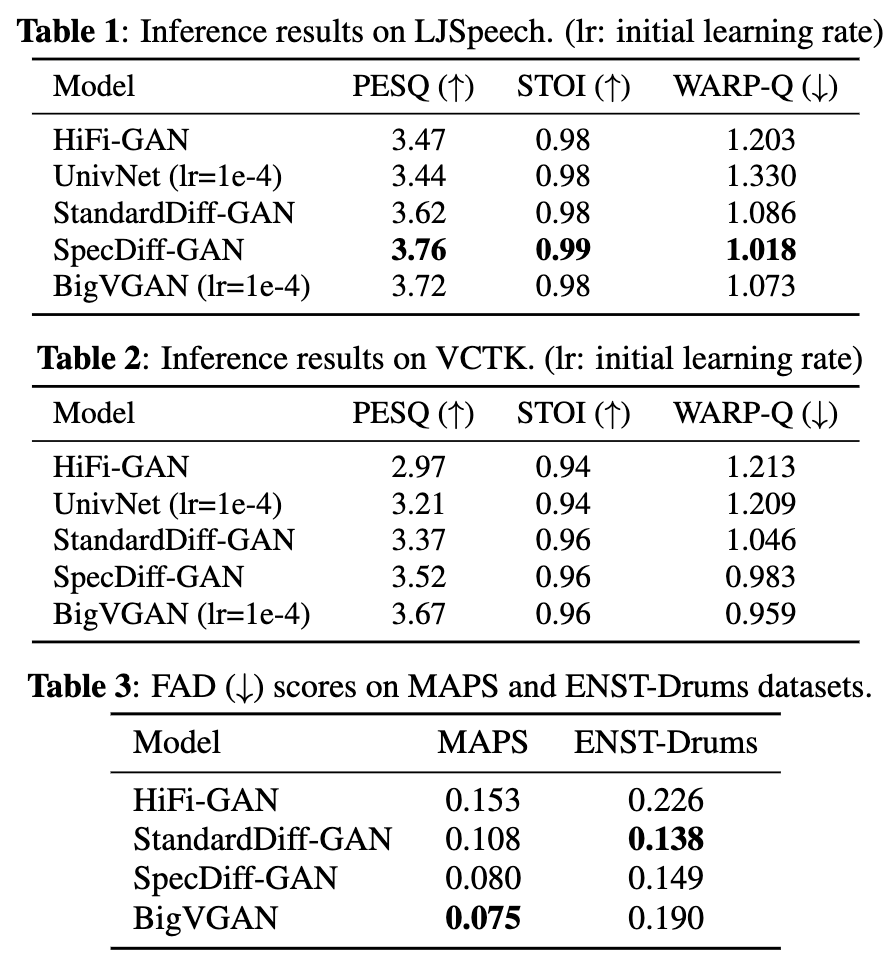
SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
- paper: https://arxiv.org/abs/2402.01753
- demo: https://specdiff-gan.github.io/
- T. Baoueb, H. Liu, M. Fontaine, J. Le Roux and G. Richard, "SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 986-990, doi: 10.1109/ICASSP48485.2024.10446830.
- まとめ
-
Diffusion-GANのアイディアをGANベースのニューラルボコーダに導入。
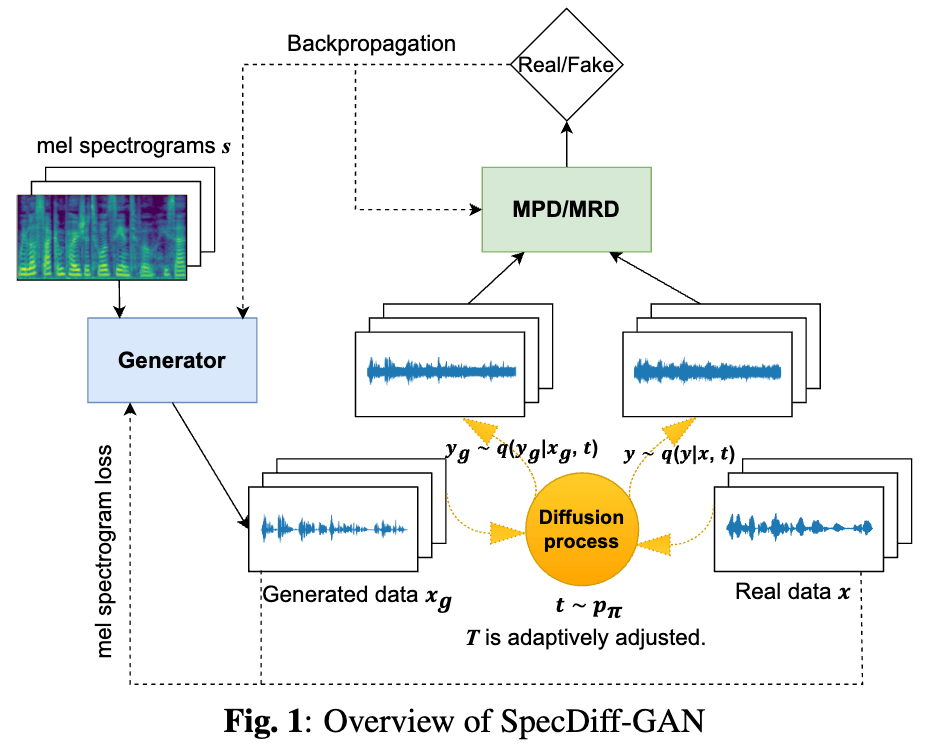
- なお、事前分布としてはSpecGradを参考に、スペクトル包絡に基づいて生成されたノイズを使用。
- GeneratorアーキテクチャはHiFi-GANまま、品質をBigVGAN並みに引き上げる。
-
Diffusion-GANのアイディアをGANベースのニューラルボコーダに導入。
Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
- paper: https://arxiv.org/abs/2401.10460
- demo: https://ddsp-vocoder.github.io/ddsp/
- P. Agrawal, T. Koehler, Z. Xiu, P. Serai and Q. He, "Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 10066-10070, doi: 10.1109/ICASSP48485.2024.10447948.
- まとめ
- DDSPボコーダをEnd-to-End TTSに適用してjoint-trainingをすることで、高速かつ高品質な音声を合成できることを示した。
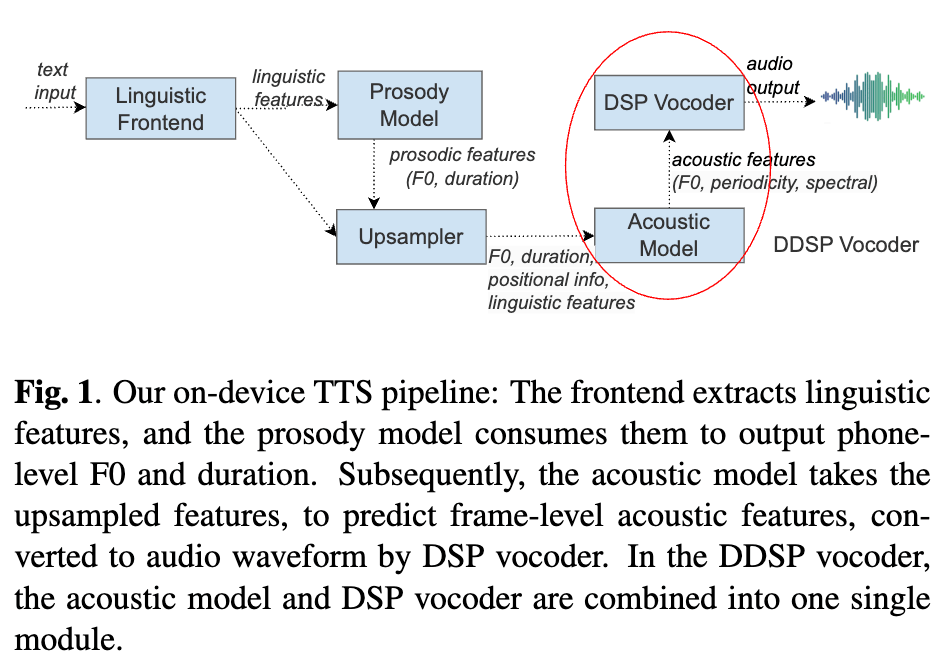
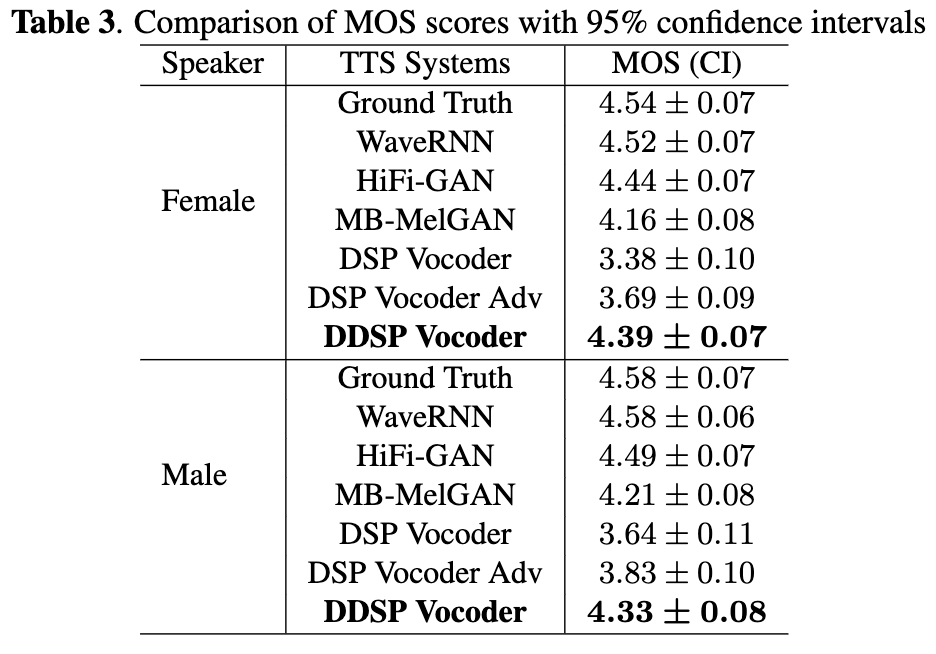
- DDSPボコーダをEnd-to-End TTSに適用してjoint-trainingをすることで、高速かつ高品質な音声を合成できることを示した。
音声変換全論文まとめ
弊社CEOの中村がICASSP2024の声質変換に関する論文のまとめをICASSP2024論文読み会にて発表しました。
資料は以下からアクセスできますので、ぜひこちらも合わせてご覧ください。

Discussion