はじめに
Parakeet株式会社リサーチャーの榎本 (X: @henomoto1025)です。純粋数学で博士号を取りポスドクをしていましたが、音声の分野に興味が移り、現在は音声界隈の研究のキャッチアップをしながら研究開発をしています。
今回は、弊社で開発している日本語音声合成エンジンParattsの質を向上させるために行った社内での取り組みについて紹介します。
短くまとめ
- 日本語TTSの学習データセットの中のあるテキストに「明日」という単語が入っていても、それが音声ファイルでは「アス」「アシタ」「ミョウニチ」のどの読みか分からず、従来の前処理では悪影響
- その解決のため、「音声」と「テキスト(漢字仮名交じり)」のペアを受け取り、そこから「音声で発話されているテキスト読み」を出力するモデル ふりがなWhisper を提案
- そのsmallモデルをHugging Faceに公開 🤗: https://huggingface.co/Parakeet-Inc/furigana_whisper_small_jsut
- ふりがなWhisperと、形態素解析器によるN-Best読み取得とを組み合わせて、音声と音素がきちんと対応する高品質な学習データを得るパイプラインの提案
こんな方におすすめ
- 日本語音声合成に興味がある人: 日本語音声合成AIを作るときに、どのような点に日本語特有の難しさがあるか、雰囲気を感じられると思います
- 日本語音声合成を学習させているエンジニア: この記事で紹介するふりがなWhisperやN-Best読みのテクニックをTTSデータの前処理に使えば、あなたのTTSの質が上がるかもしれません
- 日本語音声合成の研究者: 日本語の音声と音素と書記素との微妙で難しい問題について共感して、さらなる改善や研究や提案やコメントを行っていただけると幸いです
本稿の構成
本稿は以下のような構成になっています。
エンジニアの方は1-3を、より詳しく知りたい方は4, 5, 8をご覧ください。
- イントロ・問題意識: 日本語音声合成学習におけるテキストの音素変換処理の問題点を説明
- 提案: ふりがなWhisperの提案とその仕組みを説明
- エンジニア向け: 公開モデルの使い方とサンプルコード: ふりがなWhisperの公開モデルの使い方の説明とサンプルコード
- 研究者向け: 実験と結果: 具体的な詳しいふりがなWhisperの実験条件と評価結果
- 先行研究との比較: 記事冒頭で書いた、ふりがなWhisperとほぼ同じアイデアを持つ論文の紹介と比較
- 終わりに
- 参考文献
- 補遺
イントロ・問題意識
日本語のテキスト音声合成 (Text-to-Speech, TTS) の学習には、「音声とテキストのペアデータ」が必要です。例えば、次のような形式のCSVで表されるようなデータです。
audio_path,text
0001.wav,明日は晴れ。
0002.wav,明日は絵を描こう!
...
以下、このような形式の音声とテキストのペアデータが揃った状態で、日本語TTSを学習する際にどのような前処理が行われるかを見ていき、本稿で扱う問題点を説明します。
前提: 日本語TTS学習の前処理
日本語TTSモデルを学習するためには、通常、日本語の上記のような 漢字仮名交じり文 (以下 書記素列 (graphemes) と呼ぶ) をそのまま入力するのではなく、書記素列を一度 音素 (phonemes) 列に変換する 書記素音素変換 (Grapheme-to-Phoneme, G2P) と呼ばれる処理を行います。
これは、日本語の場合に簡単に言うと、「AIがちゃんと日本語を発音できるように、漢字仮名交じり文に対して ふりがな を振ってやる」という操作に対応します[1]。
こうしないと、日本語では書記素(通常の漢字仮名交じり文での1文字)の種類が(漢字を含めると)膨大な上、1つの書記素に対して音読み訓読みなど複数の読み方が存在するため、TTSモデルの学習が難しくなるからです。例えば、単純に書記素列「世 界は 美 しい」「美 術の授業は退屈だ」「この 世 は儚い」等だけで学習しようとすると、モデルは「世」や「美」をどう発音していいか悩んでしまうでしょう[2]。
このG2P処理は、通常は テキストデータのみを入力として、その音素列を出力する自然言語処理の範疇のタスク とみなされ、TTSの学習には、この G2P結果の音素列と音声データのペア (と場合によっては元のテキスト)が入力として与えられます。つまり、下の図で、TTSは「与えられた音素列から、与えられたwavの音声を生成する」ことを狙って学習します。
つまり典型的には、音声とテキストのペアデータセットが与えられた際のTTS学習は次のような流れとなります。
- G2P処理: 学習データの書記素列をG2P処理して、音素列を得る
-
TTS学習: 得られた音素列と音声データ(と場合によっては書記素列)を用いて、TTSモデルを学習する
- ここでモデルは、与えられた音素列から、与えられた音声を生成するように学習する
- 音声合成: 学習したTTSモデルに、書記素列を入力して、そのG2P結果の音素列(と場合によっては書記素列)をモデルに与えて音声を合成する
このG2P処理は、日本語テキストから読み含む品詞や構文解析をするいわゆる 形態素解析 と呼ばれる処理の一部で、よく使われるライブラリとして MeCab(のPythonラッパーのfugashi)や OpenJTalk(のPythonラッパーのpyopenjtalk)や Sudachi(のRust版 sudachi.rs やそのPythonラッパー)等が用いられることが多いです。
重要なのは、これらの形態素解析器は、先ほど述べた通り 音声を一切考慮せず、テキストのみから、(通常)ただ一つの読み列を出力する ということです。図にすると次のようになります。
これに従って、次のようなCSVファイルが途中で機械的に作られます:
audio_path,text,phonemes
0001.wav,明日は晴れ。,アシタワハレ。
0002.wav,明日は絵を描こう!,アシタワエヲエガコウ!
以下では、このように前処理をしてできたデータでの音素ラベルの誤りについて詳しく見ていきます。具体的には、通常の前処理では以下のような問題点があります。
- 音声とG2P結果の不一致
- そもそものテキストと音声との不一致
- 特殊な読みの固有名詞等
1. 音声とG2P結果の不一致
まず注目すべき点は、上で強調した通り、このG2P処理は音声を一切考慮していないということです。つまり、日本語における読みの曖昧性の問題により、実際の音声と、G2P結果の音素が食い違っている可能性があります。
実際、我々のデータセットの音声ファイルは実際には次のようになっているかもしれません:
| 音声ファイル | テキスト | G2P結果 | 実際の音声の発話 |
|---|---|---|---|
| 0001.wav | 明日は晴れ。 | アシタワハレ。 | アスワハレ。 |
| 0002.wav | 明日は絵を描こう! | アシタワエヲエガコウ! | アシタワエヲカコウ! |
図にしてみると、現在の状況は次のようになります。
何が問題なのか?
以上のような、機械的にG2Pを行って出来た次のデータで日本語TTSモデルを学習したとします。
audio_path,text,phonemes
0001.wav,明日は晴れ。,アシタワハレ。 <-- 実際の発話はアシタでなくアス
0002.wav,明日は絵を描こう!,アシタワエヲエガコウ! <-- 実際の発話はエガコウでなくカコウ
そうすると、TTSモデルは基本的に「学習データの音素列から、学習データの音を作ろうとする」ので、次のような問題が発生します。
-
0001.wavのデータでは、モデルはアシタという音素列から無理やりアスという音を出力することを学習しようとする- 🤖: 「アシタ」という音素は「アス」と発音するのが正しいのかな?
-
0002.wavのデータでは、モデルはエガクという音素列からカクという音を出力することを無理やり学習しようとする- 🤖: 「エガク」という音素は「カク」と発音するのが正しいのかな?
この例はデータが2件と少ない人工的な例ですが、実際に大規模な音声・テキストペアデータを扱う際に、次のような問題が起こり得ます。
- 学習データの中で、読み上げ調の音声データとセリフ調の音声データが両方存在して、「明日」という文字列に対応する音声が、
- 読み上げ調では(ニュースでよくあるように) アス と発音されている
- セリフ調では(会話でよくあるように) アシタ と発音されている
- しかし、G2Pではどれも アシタ として音素列に変換されている
- 結果として、
- 「明日」という文字列をTTSに入力したとき、TTSモデル🤖は アス と アシタ が混ざったような曖昧な発音を出力してしまう(
アスィタみたいな) - もしくは、音素列として👦 アシタ が与えて音声合成させても、その指示に従わずに🤖「アス」と発音されてしまったり、逆に音素列として👦 アス を与えて音声合成させても🤖「アシタ」と発音されてしまう
- 「明日」という文字列をTTSに入力したとき、TTSモデル🤖は アス と アシタ が混ざったような曖昧な発音を出力してしまう(
同様の現象は、日本語の多くの日常的な語彙で起こりえます。例えば:
-
日本: ニホン・ニッポン -
昨日: サクジツ・キノウ -
7日: ナノカ・ナナニチ・シチニチ -
明後日: アサッテ・ミョウゴニチ -
あちらの方: アチラノカタ(人物)・アチラノホウ(方角) -
何: ナニ・ナン -
他の: ホカノ・タノ -
私: ワタシ・ワタクシ(私どもなど) -
身体: シンタイ・カラダ
最近のTTSモデルは、このような学習データの音素ラベル誤りにある程度頑健なモデルも多いですが、上記のような悪影響が考えられるため、学習データの精度を上げるに越したことはありません。
2. そもそものテキストと音声との不一致
1.で取り上げた問題では、学習データのテキストがそもそも音声ときちんと対応していることを前提としていました。
しかし、最近のTTSのデータセットは機械的な処理によって得られることも多く(音声のみのデータからの書き起こし等や、テレビの音声と字幕等)、そのようなデータでは そもそもテキストと音声にズレが発生している こともあります。
例えば以下のような状況で起こりえます。
- 日本語音声データのみがある状況でから書き起こしをさせて作ったデータセットでは、書き起こしモデルの特性により、「あの」「えっと」等のフィラーが省略される場合があったり、逆に書き起こしでミスや繰り返しエラーが発生しうる
- テレビの音声と字幕を組み合わせるなど機械的に音声とテキストを取得したデータセットでは、重要でない単語の字幕が省略されていたり、取得ミスによりそもそも音声とテキストがずれている場合がある
- たとえある台本コーパスを読み上げた音声データセットであっても、読み間違いはたいてい紛れ込んでいる
3. 特殊な読みの固有名詞等
またG2P処理の他の問題として、特殊な読みの固有名詞等はG2Pで正しく読み取得できず、G2P処理をしてしまうと発話内容とズレが生じる点があります。
例えば、日本語音声コーパスで有名なJSUTコーパス [3]には、「月印」と書いて、「ルナグラム」と発話している1文が存在します(BASIC5000_3740.wav)。
これをもしそのままG2Pして「ツキシルシ」でTTS学習に用いてしまうと、🤖「ツキシルシという音素は実はルナグラムと発音するのかな?」とモデルが混乱してしまいます。
提案
前節での、日本語TTSの前処理における問題に対処するために、我々は ふりがなWhisper と呼ばれるモデルを提案します。
この節では、ふりがなWhisperの着想に至るまでのナイーブなアイデアを説明し、そこからふりがなWhisperの発想が自然に出てくることを説明します。
以下の表がそのまとめです。
| アイデア | 入力 | 出力 | 問題点 |
|---|---|---|---|
| ASRを使う | 音声のみ | 書記素列 | ASRモデルは通常音素列を出力しない |
| 音素列を出力する日本語ASRモデルを作る | 音声のみ | 音素列 | 書記素列の情報が考慮されない |
| ふりがなWhisper | 音声と書記素列 | 音素列 |
アイデア1: ASRを使う
そもそも、前節での問題は、G2P処理の際に音声が考慮されないことが原因でした。なので、ナイーブな発想として、逆に 音声のみから音素列を取得する という方法が考えられます。
このタスクはまさに 音声認識 (Automatic Speech Recognition, ASR) の一種です。これはつまり、音声ファイルを入力として受け取り、その発話内容を書き起こすものです。
ただし、最近の日本語のASRモデルは、ほとんどが音素単位ではなく書記素列を出力するよう学習されています。例えば上記例では:
問題点
こうしたASRモデルは、通常の人間が読みやすいテキストを生成してくれるという点では重要で使いやすいですが、本来ASRモデルが持っているはずの音素に関する情報が出力から失われてしまっているという問題があり、そのままでは使用できません。
アイデア2: 音素列を出力する日本語ASRモデルを使う
ならば、単純に 音声から音素列を出力するような日本語ASRモデルを学習すればよいのではないか? という発想が考えられます。
実際、そのような先行研究が去年のINTERSPEECH2024の論文で提唱されています ([4])。そこでは、音声認識モデルWhisperのsmallモデルをファインチューニングして、日本語から音素列とアクセント上昇下降記号を出力するモデルを提案しています。アクセントについては本記事では省略することとして[3]、つまり次のような流れになります。
この発想に基づき有志が学習したWhisperモデルがHugging Faceにありますので紹介しておきます。
また、WhisperのようなEncoder-Decoder型でなく、CTC型のASRの場合で、いくつかの音素列(カナ列)出力のモデルがHugging Face🤗上に公開されています。
- prj-beatrice/japanese-hubert-base-phoneme-ctc
- slplab/wav2vec2-xls-r-300m-japanese-hiragana
- snu-nia-12/wav2vec2-xls-r-300m_nia12_phone-hiragana_japanese
- vumichien/wav2vec2-large-xlsr-japanese-hiragana
さらに、補遺記載のふりがなWhisperのデコード時の工夫で述べる通り、通常のWhisperモデルに抑制トークンを設定し、デコード時にカタカナやひらがな以外の文字を出力しないようにすることで、Whisperモデルに音素出力を強制させることもできます。試したところ、なかなかの精度で音素出力をしてくれました。
問題点
まず問題なのは、そもそもこのような音素出力ASRモデルを学習するには、「音声とその発話されている音素の正確なペアデータ」が必要です。上記で紹介したいくつかの音素出力ASRモデルでは、単純なG2Pにより擬似的に音素データを作成し学習しているため、G2Pミスを学習してしまう現象が確認できました(例えば「明日(アス)」と発話されている音声に対して、音素出力が「アシタ」となってしまう)。そもそもそこが問題点だったので、そのようなモデルは今回の目的には適しません。
また、より根本的な問題として、ASRモデルは音声のみから音素列を出力するのであって、そこでは一切元の書記素列の情報が考慮されていません。
そのため、簡単な文章やよくあるフレーズについては問題なく音素列が出力されるケースが多いものの、元の書記素列との食い違いが生じることがあります。
例えば、ROHANコーパス [5]の一部の音声を音素出力Whisperに入力すると、次のような音素列が出力されます(これは後で触れるふりがなWhisperに書記素列を与えずに書き起こした結果です)。
| 音声ファイル | 書記素列 | 音素出力ASR結果 |
|---|---|---|
| ROHAN4600_3616.wav | クェーサーの観測を務めたのは、アマチュア天文家でした。 | クエサーノカンソクヲツトメタノワ、アマチワテンモンカデシタ。 |
| ROHAN4600_3751.wav | そんでぇー、しこたまの土砂から、手水舎を引っこ抜きゃオッケーだ。 | ソンデイ、シコタマノドシャカラ、チョウズヤヲヒッコヌケアオッケイダ。 |
| ROHAN4600_3793.wav | ぎゅうぎゅう詰めのミュージアムで、早急にグァバ茶を飲むのは、初だ。 | ギュウギュウズメノミュウジヤムデ、サッキョウニガワチャヲノムノワ、ハツダ。 |
これらの結果は、実際に音声と音素を比べるとそう聞こえなくもないので、あながち間違いとはいえません。しかし、元の書記素列とは整合性がなく、例えば次のような点であまり望ましくありません。
- TTSモデルが音素と書記素列の明確なアライメント(どの書記素がどの音素と対応するかの情報)を必要とする場合、このような食い違いがあるとそこでエラーが生じる
- 例えば最後の例で「早急」の音声が、はっきり「サッキュウ」と言っているがサッキョウにも聞こえなくも無い状態だとして、もしその音素を「サッキョウ」だとして学習してしまうと、以下のような誤った学習をしてしまう可能性がある
- 🤖「サッキョウという音素列は、サッキュウみたいな音声を出すべきなんだな」、あるいは逆に
- 🤖「早急という書記素列は、サッキョウって発音するのが正しいんだな」
ふりがなWhisperの提案
ではどうすればよいでしょうか?以上のアイデアの問題点を踏まえると、次のようなモデルを作ればよいことになります:
- モデルは入力として音声と書記素列を両方受け取る
- その結果として、書記素列を考慮した音素列を出力する
このモデルの具体的な実装として、我々は ふりがなWhisper と呼ばれるモデルを提案します。
まず前提として、多言語対応している性能が良いASRモデルとしてWhisperというOpenAI社のモデルがあります [6]。
このWhisperには 初期プロンプト (initial prompt) というものがあり、音声とともに、書き起こしを始める際の文脈情報を挿入することができます。例えば「句読点付きのセリフ例」をプロンプトに入れるときちんと句読点がついたり、「音声に入っているかもしれない固有名詞」をプロンプトに入れると、その固有名詞を使って書き起こしをしてくれる、というものです。
なので、単純に Whisperの初期プロンプトに、書記素列を挿入してやれば、Whisperがそれを考慮して音素を書き起こしてくれる(ふりがなを振ってくれる) のではないか、という発想に至りました。
この仕組みを、音声と漢字仮名交じり文からふりがなを振る、という意味でふりがなWhisperと名付けました。
ふりがなWhisperの学習は、既存モデルに対して「音声を与えてプロンプトに書記素列を与えると音素列を出力する」という振る舞いをするようファインチューニングをする形で行います。
ここで、Whisperや初期プロンプトの詳細については、補遺のWhisperの構造と初期プロンプトの仕組みを参照してください。
N-Best読み取得との組み合わせの提案
実は、ふりがなWhisper単独ではまだいくつか問題が残っており、そこでN-Best読み取得と呼ばれるMeCabの機能を組み合わせるパイプラインを提案します。
ふりがなWhisperの音素取り違えの修正
ふりがなWhisperは書記素で条件づけているので、もともとの書記素のひらがなやカタカナの部分はかなり書記素に沿った形で音素を書き起こしてくれることが観察できましたが、一部漢字等について、上記アイデア2での問題点と同様、「確かにそう聞こえるかもしれないが、書記素列の日本語読みとしては不適切」な読みを出力することがありました。
なので、書記素列をG2Pした結果と、ふりがなWhisperの結果を比較して修正することが考えられます。しかし、通常のG2Pの設定では読みは1つしか出力されないため、例えば冒頭で述べた「明日」の読みをどうすればよいか問題が発生します。
このため、MeCabのN-Best結果取得機能を使用することにしました。これは、MeCabがテキストの最終形態素解析結果だけでなく、他にもありえる形態素解析結果(読み含む)をN個出力してくれる機能です。
このNを十分大きく取れば、書記素列の可能なあらゆる読みを(特殊な固有名詞等以外は)網羅できるはずです。よって、ふりがなWhisperの結果と、MeCabのN-Best読み候補とを比べて、最も編集距離が小さいものを選ぶことで、書記素列に対して適切な読みを得ることができると考えました。
不適切なデータの除外
上記問題意識で述べた通り、学習データの中には、そもそも音声とテキストが対応していないデータや、特殊な読みの固有名詞等が入った発話が存在することがあります。
そのような場合でも、ふりがなWhisperにより音素列を得ることはできますが、その結果が書記素列と整合性を持っていないこととなり、TTSモデルの学習に悪影響を及ぼす可能性があります。
ここでも、先ほどと同様にMeCabのN-Best読みを用いることができます。具体的には、先ほどと同様に、ふりがなWhisperの結果と、MeCabのN-Best読み候補とを比べて、編集距離の最小値を計算します。この値は、「音声の発話と書記素列の可能な読みがどれほど整合性があるかを表している指標」だと思うことができます。もし編集距離が0ならば、ふりがなWhisper結果の音素列と音声はほぼ確実に対応しており、逆にもし編集距離が大きい場合は、そもそもふりがなWhisperが繰り返しやスキップ等のミスを犯しているか、一般的な読みではない固有名詞が含まれているか、または音声とテキストが対応していない、という状況だと考えられるからです。
よって、この編集距離に閾値を設定して、編集距離が高いデータを除外し、データセットのフィルタリングを行うことができます。
提案パイプライン
以上の流れを踏まえたパイプラインを図にすると次のようになります。
機械的なG2P処理では「アシタワハレ」という音声と対応しない読みとなってTTS学習に使われていましたが、上記のパイプラインにより、きちんと「アスワハレ」という音声と対応する読みを使ってTTS学習を行うことができます。
このように、前節の問題意識で述べた問題に対し、この提案は次のような解決策を提供します。
- 1. 音声とG2P結果の不一致: ふりがなWhisperの結果とN-Best読み候補を比較することで、G2P結果のうち音声ともっとも整合性のあるものを選び、その音素を学習データに用いることができる
- 2. テキストと音声との不一致、3. 特殊な読みの固有名詞等: ふりがなWhisperの結果とN-Best読み候補の編集距離を計算することで、音声とテキストが対応していないデータや、特殊な読みの固有名詞等が入った発話を検出し、必要に応じて除外することができる
実際、以下で述べる通り、このパイプラインを用いて、一般的な音声データセットから、約8割以上のデータを確実に音声と音素の対応がとれた高品質なデータセットに変換することができました。
エンジニア向け: 公開モデルの使い方とサンプルコード
この説では、理論的な話や実験の詳細は置いておいて、まずふりがなWhisperを使ってみたい、実際にデータの前処理を高品質にしたいという方を念頭にして、公開しているsmallなふりがなWhisperの使い方とサンプルコードを紹介します。
ふりがなWhisperの実行
uv等で仮想環境を作成し、いつものように(GPU環境に合わせた)torchと、 🤗 Transformers ライブラリを入れます。
uv venv
uv pip install torch --index-url https://download.pytorch.org/whl/cu128
uv pip install transformers
次に、Transformersの pipeline を使えば、自動的にモデルがダウンロードされ、すぐにふりがなWhisperを使うことができます。
from transformers import pipeline
from pathlib import Path
pipe = pipeline(
"automatic-speech-recognition",
model="Parakeet-Inc/furigana_whisper_small_jsut",
)
def transcribe_with_prompt(pipe, audio_path: str | Path, prompt: str) -> str:
prompt_ids = pipe.tokenizer.get_prompt_ids(
prompt, return_tensors="pt"
).to(pipe.device)
generate_kwargs = {"prompt_ids": prompt_ids}
result = pipe(str(audio_path), generate_kwargs=generate_kwargs)
return result["text"]
# 実行例
audio_path = "path/to/your/audio.wav"
prompt = "明日は晴れ。"
transcription = transcribe_with_prompt(pipe, audio_path, prompt)
print(transcription) # アスワハレ。
この関数により、音声ファイルと共に、その音声の書記素列をプロンプトとして与えると、ふりがなWhisperによる読み推定を得ることができます。
N-Best読み候補の取得
N-Best読み取得にはいろんな選択肢があると思われますが、ここではMeCabのPythonラッパーであるfugashiを使用する例を紹介します。
まずfugashiのREADMEに従いfugashi(とjaconv)をインストールします。
uv pip install 'fugashi[unidic]' jaconv
uv run python -m unidic download
以下は、読み候補(ふりがなWhisper結果)と、書記素列から、MeCabのN-Best読みの中で最も読み候補に近いものを選ぶ関数のコード例です。
import re
import jaconv
from fugashi import Tagger
tagger = Tagger()
_katakana_re = re.compile(r"[\u30A0-\u30FF]+")
def _extract_katakana(text: str) -> str:
"""テキストからカナ部分をカタカナで抽出する"""
return "".join(_katakana_re.findall(jaconv.hira2kata(text)))
def _extract_yomi(node) -> str:
"""MeCabのノードからカタカナ読みを抽出する"""
feat = node.feature
kana = feat.kana
pron = feat.pron
pos1 = feat.pos1
surf = node.surface
if kana == "ハ" and pos1 == "助詞":
return "ワ"
if kana == "ヘ" and pos1 == "助詞":
return "エ"
if kana == "コンニチハ":
return "コンニチワ"
if kana == "コンバンハ":
return "コンバンワ"
if kana and kana != "*":
return kana
if pron and pron != "*":
return pron
if surf in {"。", "、"}:
return surf
return _extract_katakana(surf)
def _levenshtein(a: str, b: str) -> int:
"""文字列レベルの編集距離を計算する"""
m, n = len(a), len(b)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(m + 1):
dp[i][0] = i
for j in range(n + 1):
dp[0][j] = j
for i in range(1, m + 1):
for j in range(1, n + 1):
cost = 0 if a[i - 1] == b[j - 1] else 1
dp[i][j] = min(
dp[i - 1][j] + 1,
dp[i][j - 1] + 1,
dp[i - 1][j - 1] + cost,
)
return dp[m][n]
def get_best_match_yomi(text: str, yomi_pred: str, n: int = 512) -> tuple[str, int]:
"""
textのN-Best読み候補から、yomi_predに最も近い読みを取得する。
"""
best_dist = float("inf")
best_yomi = ""
for nodes in tagger.nbestToNodeList(text, n):
# 候補の読み文字列を組み立て
yomi_cand = "".join(_extract_yomi(nd) for nd in nodes)
# 文字列レベル編集距離を計算
dist = _levenshtein(yomi_pred, yomi_cand)
if dist < best_dist:
best_dist = dist
best_yomi = yomi_cand
if dist == 0:
break # 完全一致なら終了
if best_dist == float("inf"):
raise ValueError("No valid yomi candidates found.")
best_dist = int(best_dist)
return best_yomi, best_dist
if __name__ == "__main__":
sample_text = "明日は晴れ"
yomi_pred = "ミョニチワハレ"
match_yomi, distance = get_best_match_yomi(sample_text, yomi_pred)
print(f"Best match: {match_yomi} (distance={distance})")
これを実行すると、ふりがなWhisperの推測「ミョニチワハレ」に対して、一番近い読みである「ミョウニチワハレ」が距離1で得られます。
注意
- 音声の長さは30秒以下でないとうまく動きません。
- 公開しているsmallモデルはそこまで精度が良いとは言えず、後述のG2Pマッチ率(データセットに対してフィルタリングを行った後に残るデータ量)が40%程度となっています。より精度の高いモデルを使いたい方はデータを揃え、ベースモデルもwhisper-smallより大きいモデルにして自分で学習を行うことをおすすめします。
- 上記例では単純な文字レベルの編集距離を使用していますが、ふりがなWhisperは母音と撥音でのミスが多いため、それらのコストを下げ、それら以外のコストを上げるような編集距離を使用し、例えば母音1つのミスくらいは許容するような工夫をすると、実用上より多くのデータが得られます。
- 学習データでのプロンプトは、全て「句読点が、。のみ」「最後に必ず。が付く」と正規化されています(補遺参照)。よって、与えるプロンプトも同様の形式にしたほうが精度が高くなります。
研究者向け: 実験と結果
この節では、実際にこのふりがなWhisperモデルを学習した手順や実験結果について述べます。
実験条件
ベースモデル
社内の実験では openai/whisper-large-v3-turbo をベースモデルとして使用しました。これは openai/whisper-large-v3 モデルのDecoderを32層から4層に削減したモデルで、軽量ながらも高い精度を持つモデルです。
公開モデルには、小さいモデル openai/whisper-small をベースモデルとして使用しました。
また、補遺のふりがなWhisperのデコード時の工夫で述べる通り、Whisperモデルには抑制トークンを設定し、デコード時にカタカナと句読点「、。」以外の文字を出力しないように設定しました。
学習データ
社内の実験では以下を用いました。
今回公開するモデルでは、上記のうちJSUTコーパスのみを使用しています。
データセット作成手順
ふりがなWhisperの学習には、音声とテキストだけでなく、正解の読み情報も必要です。以下の手順で、正解の読みと、プロンプトとして与える書記素列のデータ準備を行いました。
- ROHANコーパスには読み情報が付与されているため、まず初期検証として、ずんだもんのROHANコーパスを用いて、試作モデルを作成
- 次に、JSUTコーパスをこの試作モデルを用いて音声から書き起こしを行ったものに対して、アノテーターによるフィルタリングと修正を行い、JSUTコーパスのデータセットを作成
- No. 7のROHANコーパスに関しては、発話誤り情報が付与されているため、それを除外したデータを使用
- 最後に句読点の使用等についてデータセット全体で統一(句読点を「。、」のみに統一、プロンプトと正解の最後には必ず「。」を付ける等)(補遺参照)
- 結果として得られたデータのうち、ROHANコーパスの最後の1000文相当のデータを、検証データとして使用
最終的に、合計で train: 21,645, valid: 3,995 件の音声とテキストと読み情報のデータが得られました。
このうち公開モデルの学習データはJSUT部分のみの 7,275 件となりました。
学習ハイパラメータ等
| 設定項目 | 値 / 詳細 |
|---|---|
| 学習率 | 1e-5 |
| バッチサイズ | 256 |
| 学習エポック数 | 57エポック |
| 学習時間 | NVIDIA H200で約2.5日 |
| その他 | Encoderの重みを凍結しDecoderのみ学習 |
Encoder凍結について
- WhisperのEncoderはすでに音声から十分な特徴量を抽出する能力を獲得しているため、Decoder部分のみをファインチューニングすることで学習効率・精度向上を図っています。
- Distil-Whisper [7] および日本語特化Whisperの kotoba-whisper でも同様にEncoder凍結戦略が採用されています。
- Encoderを凍結せずに学習を行った場合、過学習が発生し、とくにドメイン外データに対する精度低下が観察されました。
評価指標
評価指標としては、以下を使用しました。
- Closed条件(同ドメインの検証データ)
-
CER (Character Error Rate): 正解音素列に対して、予測された音素列がどれだけ一致していたかの文字誤り率。以下の2つを算出:
- プロンプトを与えずに、音声のみから音素列を出力した場合のCER
- プロンプトを与えた場合のCER
- 完全正解したデータの割合
-
CER (Character Error Rate): 正解音素列に対して、予測された音素列がどれだけ一致していたかの文字誤り率。以下の2つを算出:
- Open条件(学習ドメインとは違うドメインのプライベートデータ)
-
G2Pマッチ率: ふりがなWhisperの出力音素列が、書記素列に対するG2P結果と一致していた割合。以下の2つを算出:
- N-Best読み未使用でのG2Pマッチ率: N-Best機能を使わない通常のG2P結果と、ふりがなWhisper結果とが一致していた割合[4]
- N-Best読み使用でのG2Pマッチ率: 書記素列のN-Best読みのいずれかとふりがなWhisper結果とが一致していた割合
- 両者共に、完全一致率と、母音撥音の1個のミスを許容した場合のマッチ率を算出
-
G2Pマッチ率: ふりがなWhisperの出力音素列が、書記素列に対するG2P結果と一致していた割合。以下の2つを算出:
G2Pマッチ率について
CERはASRで標準的な指標ですが、後者のマッチ率は今回特有の指標なので、少し補足をします。
実データにふりがなWhisperを適用して提案手法でデータセットを作る際、正解の音素情報が存在しないことを踏まえると、1つの「音声とテキストのペア」データに対して、次の2つのミスが起こり得ます。
- ふりがなWhisperの結果に繰り返しや母音置換等のエラーが含まれる(ふりがなWhisper側の読み推定ミス)
- 例えば「料理」を「リョウリ」でなく「リュウリ」と書き起こしたり、途中から繰り返しエラーが発生する等
- 正解のはずのテキストにエラーや非標準的な読みが含まれ、音声の正解音素をMeCab N-Bestで求めることができない(MeCab N-Best側の読み推定ミス)
- 例えば「月印」を「ルナグラム」と発話しているデータに対しては、MeCab N-Bestはそもそも読み候補に「ルナグラム」が存在しない
- また、音声とテキストが正確には対応しておらず一部に誤りが含まれている場合もこちら
CERは、「正解テキストに対する、予測テキストの文字誤り率」ですので、今回のOpen条件での設定のような、「どちらかが必ず正解だと仮定はできない」状況では、CER(のN-Best候補での最小値)を計算することは適切ではないと考えました。
ただ、後者(N-Best側のミス)の割合は少ないと考えられ、またモデルによらずデータに対して一定であるため、ふりがなWhisperの性能を見るには、どれだけふりがなWhisperの結果がN-Best読みのいずれかと一致しているかの割合を見るとよい考えられ、このマッチ率を採用しました。
またこの割合は、提案手法で実際にデータをフィルタリングする際、編集距離0のもののみを使用、もしくは母音と撥音のミス1つは許容するというふうに閾値を定めた場合の、「全データに対する使えるデータセットの割合」とも言え、実用上の有効な指標となります。
実験結果
以下は断りがない限り、公開しているsmallモデルではなく、社内モデルでの実験結果です。
検証データに関する指標
まず、学習は30エポック程度でロスや勾配がほぼ収束し、最終的な指標は次のようになりました。
| 指標 | 値 |
|---|---|
| プロンプトを与えなかった場合のCER (Closed) | 6.43% |
| CER (Closed) | 0.19% |
| 完全正解率 (Closed) | 94.72% |
この結果から、ふりがなWhisperは、学習ドメインの読み上げ調の音声に対して、かなりの精度で正解の音素列を出力できることがわかります。また、プロンプトを与えることで明確にCERが下がることから、プロンプトによる条件付けも有効であることがわかります。
実際、先ほど例に挙げた例では、プロンプトを入れることで、書記素列を反映した完全な正解を得ることができました。
| 音声ファイル | 書記素列 | プロンプト無し | プロンプト有り(=正解) |
|---|---|---|---|
| ROHAN4600_3616.wav | クェーサーの観測を務めたのは、アマチュア天文家でした。 | クエサーノカンソクヲツトメタノワ、アマチワテンモンカデシタ。 | クェーサーノカンソクヲツトメタノワ、アマチュアテンモンカデシタ。 |
| ROHAN4600_3751.wav | そんでぇー、しこたまの土砂から、手水舎を引っこ抜きゃオッケーだ。 | ソンデイ、シコタマノドシャカラ、チョウズヤヲヒッコヌケアオッケイダ。 | ソンデェー、シコタマノドシャカラ、チョウズヤヲヒッコヌキャオッケーダ。 |
| ROHAN4600_3793.wav | ぎゅうぎゅう詰めのミュージアムで、早急にグァバ茶を飲むのは、初だ。 | ギュウギュウズメノミュウジヤムデ、サッキョウニガワチャヲノムノワ、ハツダ。 | ギュウギュウヅメノミュージアムデ、サッキュウニグァバチャヲノムノワ、ハツダ。 |
また、プロンプトの効果を見るため、実際にモデルが各トークンを出力する際のセルフアテンションを可視化したところ、ちょうどデコードする音素と対応する書記素のプロンプト部分に強くアテンドしているという傾向も確認することができました。
参考までに、公開しているsmallモデルでは以下のような結果となりました。
| 指標 | 値 |
|---|---|
| プロンプトを与えなかった場合のCER (Closed) | 9.9% |
| CER (Closed) | 1.23% |
| 完全正解率 (Closed) | 71.7% |
Open条件での指標
次に、Open条件での指標(G2Pマッチ率)は次のようになりました。
| 完全一致 | 母音・撥音ミス1個許容 | |
|---|---|---|
| N-Best読み未使用 | 57.9% | 63.6% |
| N-Best読み使用 | 76.6% | 82.8% |
母音・発音のミス1個については、ふりがなWhisper側の軽微なミスであり、ミスを確認してもほとんどがN-Best読みを使用することで修正可能なものです。
このことから、提案手法を用いることで、プライベートデータのなかから、音声と書記素列と音素列との整合性がほぼ確実に取れているデータが、全体の約8割以上は得ることができることがわかりました。
また、N-Best読みを使用しない場合、一致率が20%ほど下がることから、少なくとも 20%程度のデータについては、単純なG2Pでは音声と対応しない間違った音素が得られてしまう(しかしN-Best読みにより正しい音素に修正可能) ということが分かります。
計算の補足
全体のデータは、次のように分割することができます:
- ふりがなWhisperがエラーを起こしているデータ
- ふりがなWhisperは正解音素を出力しているが、N-Best読みでも正解音素が出せないデータ(月印: ルナグラムなど)
- ふりがなWhisperは正解音素を出力し、N-Best読みで正解音素が出せるが、通常G2Pのみでは正解音素が出せないデータ
- ふりがなWhisperは正解音素を出力し、通常のG2Pで正解音素が出せるデータ
このとき、N-Best未使用でのG2Pマッチ率は全体のうち4のみが占める割合を、N-Best使用時のG2Pマッチ率は3と4を合わせた割合を示していると考えられます。なので、その差分が20%ということは、全データの 約20% が3のデータであることを意味します。
参考までに、公開しているsmallモデルでは、G2Pマッチ率は完全一致率が約 48.6% 、母音・撥音ミス1個許容で約 63.4% となりました。
TTSへの応用
提案の「ふりがなWhisperとN-Best読みパイプライン」を用いることで、上で見たように、元々のデータのうち約8割程度は音声と書記素列と音素列との整合性がほぼ確実に取れている高品質なデータが得られます(その分データ量は若干減ってしまいます)。
実際、社内で開発しているTTSモデルに対して、今回の提案パイプラインによって学習データを絞り音素の質を上げることで、読みが曖昧な単語等の発音や自然性が明確に改善されることが確認できました。
限界・展望
TTS用の学習データを作るという点では、Open条件でのG2Pマッチ率をできるだけ高くすることが重要です。しかし、現状のモデルでは8割となっており、逆にいうと2割程度のデータは捨ててしまうことになります。
この原因として、まず、先ほど述べた通り、ふりがなWhisper単独では音素の取り違えミス等がどうしても一定数は発生してしまいます。また、Whisperにありがちな削除や繰り返しミスの発生も確認されています(公開しているsmallモデルでより顕著に見られます)。
原因としては、そもそもWhisperの自己回帰的な生成の特性上、生成誤りはおそらく完全には防げないことと、Decoderの暗黙的な言語モデルには明示的には日本語辞書が組み込まれていないこと、また学習データの音声のドメイン(全て読み上げ調)と推論ドメインとの不一致等が考えられます。
ただ、今回のモデルを使ってさらに学習データを増やしたり、TTSを使った合成データを学習に用いることで、これらのミスは軽減されると考えられます。
また、この点について、次節で紹介する2論文のようにデコード時にも辞書と組み合わせるなどの工夫を行なったり、さらなるアーキテクチャの改善等を行うことで、より精度の高いモデルが得られるかもしれません。
先行研究との比較
INTERSPEECH 2025にアクセプトされた次の2本の論文では、似たようなモチベーションから、「書記素列」「音声」を受け取り「音素列とアクセントラベル」を出力するモデルが提案されています。(本稿の研究はこれら2本の論文とは独立に行われたものです。)
[1] Grapheme-Coherent Phonemic and Prosodic Annotation of Speech by Implicit and Explicit Grapheme Conditioning
この論文では ASRモデルとして OWSM-CTC というCTCベースのモデルを使い、それに日本語書記素で条件づけを行うことで音素列を出力しています。
工夫やふりがなWhisperとの違いとして、以下の点が挙げられます。
- ベースとするASRモデルの違い
- ふりがなWhisperは自己回帰型のWhisperモデルを使用しているのに対し、こちらは非自己回帰型のCTCベースのモデルを使用
- Whisperを使用しなかった理由として、論文内では「Whisperでは繰り返し等の誤りが多かった」ことが挙げられています
- 書記素列の条件づけの仕方
- この論文では書記素列そのままではなく、書記素列をBERTに通した結果を条件づけに使用しています
- ふりがなWhisperでは、Whisperの初期プロンプトとして入れるだけです
- 辞書を用いたデコード
- この論文では、CTCでのデコード時に、「1つの書記素に対する可能な読み」の辞書を用いて、CTCスコアが高いものの中で「辞書とマッチするもの」をデコードするようにしています
- ふりがなWhisperでは、デコード時には抑制トークンでカタカナ以外の出力を抑制する以外はせず、辞書ベースとの組み合わせは、後段のN-Best読み候補取得で行っています
- 出力ラベル
- この論文では、音素列だけでなくアクセントラベル(アクセント上昇下降記号とアクセント句区切り)を同時に出力するようにしています
- 学習データの工夫
- この論文では、TTSを使って学習データのデータ拡張を行っています
また論文では応用として、学習したモデルを用いて日本語テキストからのアクセント推定のデータセットを作成してアクセント推定モデルを学習し、その結果の精度を評価しています。
[2] Transcript-Prompted Whisper with Dictionary-Enhanced Decoding for Japanese Speech Annotation
この論文では、ふりがなWhisperと同様に openai/whisper-large-v3-turbo をベースモデルとして、Whisperの初期プロンプトに書記素列を与えることで音素列とアクセントラベル情報を得るモデルを提案しています。
工夫やふりがなWhisperとの違いとして、以下の点が挙げられます。
- デコード形式の違い
- この論文では、音素列(とアクセントラベル)だけでなく、同時に(おそらく)アクセント句ごとの書記素列も出力するようにしています
- 辞書を用いたデコード
- この論文では、Decoderが自己回帰的に出力をデコードする際、書記素列の音素候補のなかから最も編集距離が小さい音素を出力するようにしています
- ふりがなWhisperでは、デコード時には抑制トークンでカタカナ以外の出力を抑制する以外はせず、音素候補との比較は後段のN-Best読み候補取得で行っています
- 出力ラベル
- この論文では、書記素列、音素列、アクセントラベルを同時に出力するようにしています
また論文では応用として、実際にこのモデルを用いてTTS学習データを作り、TTSモデルを学習させ、結果の出力音声のMOS比較等も行っています。
ふりがなWhisperとの違いのまとめ
大きくは、以下の点がふりがなWhisperと2論文との違いとして挙げられます。
- 出力ラベルの違い: 音素のみ(ふりがなWhisper)でなく、音素とともにアクセントラベルを出力する(2論文)か否か
- デコード時の辞書使用: 結果のデコード時に明確に辞書を使ってデコードを行うか(2論文)、ASR段階では辞書を使わず後段で辞書を使うか(ふりがなWhisper)
ただ、後者の点に関しては、2論文では「デコード時に辞書を用いている」ことから、少なくとも私の理解では以下のようなデメリットがあると考えられます。
- 与えられる書記素列が正しいことを前提としている➡️「テキストと音声との不一致」には対応できない
- テキストと音声の対応が完全ではないデータに対しては、特に[2]では(私の理解では)必ずテキストの形態素解析結果が出力されてしまうため、「テキストと音声が対応していない」ことを検知できない
- 与えられる書記素列の読みは全て辞書でカバーされていることを前提としている➡️「特殊な読みの固有名詞等」には対応できない
- 例えば、辞書に「月印: ルナグラム」が存在しない限り、2論文の手法では「月印」と書いて「ルナグラム」と読んでいるデータを正しく読み付与することはできず、おそらく「ツキシルシ」等の音声と全く対応していない読みが付与されてしまうはず
- ふりがなWhisperを使えば、そのデータに対して「ルナグラム」という読みを得ることができるし、またそれがイレギュラーな読みであることを編集距離で検出し、必要ならばデータから除外できる
これらのことを考えると、ふりがなWhisperとN-Best読みの単純なアプローチの方が、辞書を参考にしてデコードする2論文より、綺麗なデータに対する正解率は下がるかもしれないが、イレギュラーデータを除外したいという目的には適していると考えられます。[5]
終わりに
今回のふりがなWhisperは、言ってしまえば「Whisperの初期プロンプトに漢字仮名交じり文を与えれば、それを反映して読みの書き起こししてくれるんじゃ?」という素朴な発想から生まれたものです。
最後に紹介した2本の論文は、条件付けの工夫やデコード時の工夫やデータセット拡張などさまざまなアイデアが試されており、すごいなあ、そして先を越されるとはこういうことか、と思いました。
ただ、実際にTTSの品質を上げる目的で開発したふりがなWhisperにより、自社TTSの品質がきちんと向上していくことが確認できたのは、目に見える成果であり、非常に嬉しく思っています。
最後に、今回の実験や開発や学習にあたりアドバイスをくださったParakeetのメンバーたちに深く感謝いたします。
宣伝
Parakeet会社では、法人様向けにテキスト音声合成APIサービス Paratts(パラッツ) を提供しています。Parattsは、この記事で紹介したふりがなWhisperをはじめとする最新の技術を活用し、自然で高品質な音声合成を実現しています。特に、他社製品と比較し、以下の優れた特徴を持ちます。
1. 100秒の音声を1秒で合成する、デジタルヒューマン利用特化の爆速なレスポンス

2. 高サンプリングレートに裏付けられた高音質な合成音声
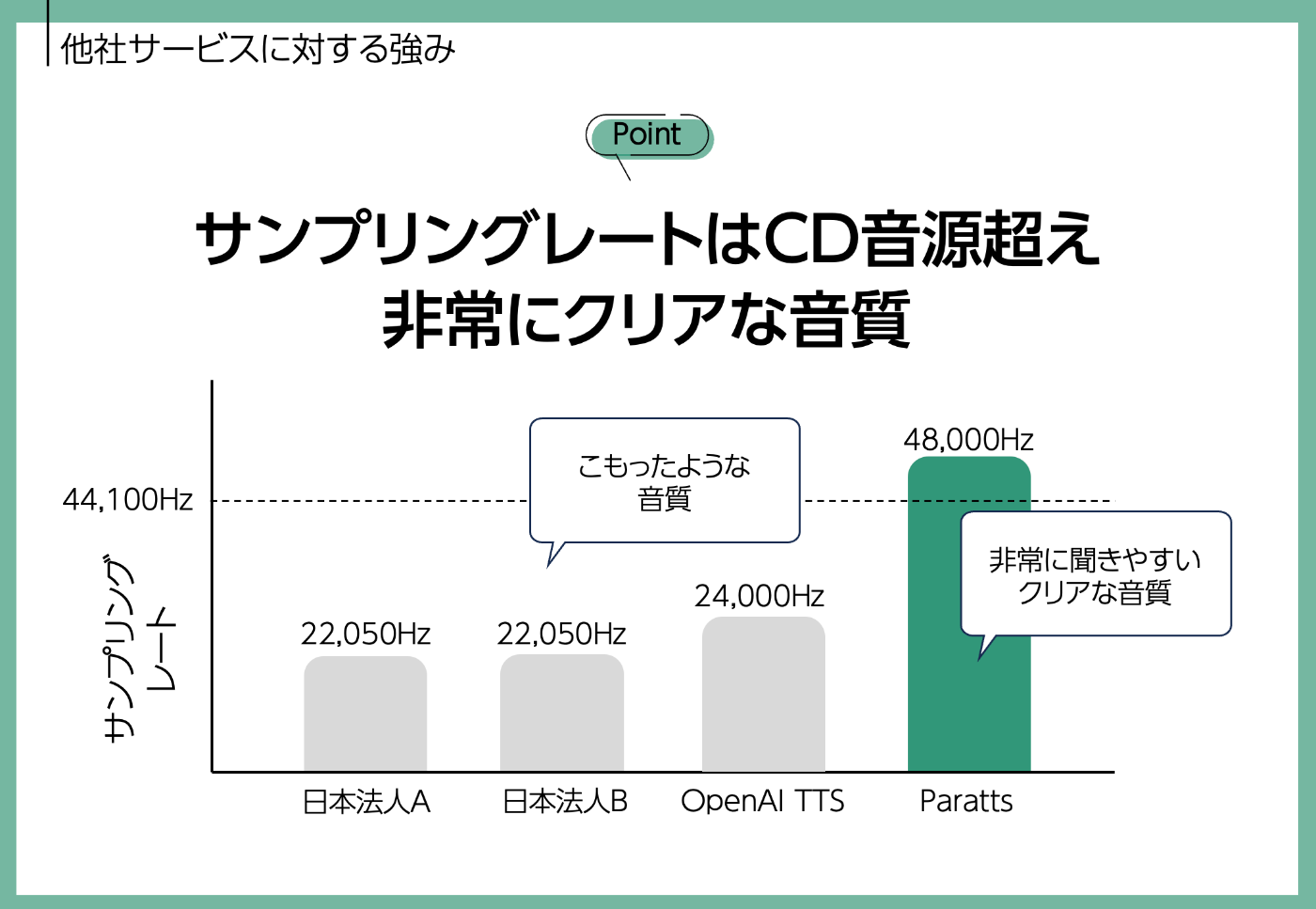
3. 漢字の読み間違いが極端に少なく、感情豊かで自然なイントネーション
オフライン、ローカルマシンで動作するエッジTTSモデルもご相談可能です。
パラッツのご利用、詳しいお話を希望する法人のお客様は、以下のお問い合わせからお気軽にご相談くださいませ。
参考文献
補遺
Whisperの構造と初期プロンプトの仕組み
Whisperは、Encoder-Decoder構造のTransformerモデルで、以下のようなプロセスで動作します。
- Encoderが音声を処理して特徴量列を抽出する
- Cross-attentionを通して自己回帰的にDecoderがトークン列を生成する
- Tokenizerがトークン列からテキストへデコードする
簡単に言えば、「英語から日本語への翻訳タスクをEncoder-Decoder Transformerでやる、ただし英語の代わりに音声(特徴量列)を入力とする」というイメージをするとよいと思います。
 OpenAIの公式サイトより
OpenAIの公式サイトより
ここで、Decoderが生成するトークン列は、実際にはいくつかの特殊トークンが含まれています。例えば上記図右上と右下のトークン列内部の EN は入力言語が英語であることを示すトークン、 TRANSCRIBE は書き起こしタスクを表すトークン、 0.0 は書き起こし時刻を表すタイムスタンプトークンです。
初期プロンプトも特殊トークンに挟む形で実現されます。
具体的には、今回のように 明日は晴れ。 というプロンプトを挿入して、音声から アスワハレ。 という音素列を出力させたい場合、次のようなトークン列が学習に用いられます(正確にはトークン列をデコードしたものが以下です)。
<|startofprev|> 明日は晴れ。<|startoftranscript|><|notimestamps|>アスワハレ。<|endoftext|>
生成の段階では、 <|startofprev|> 明日は晴れ。<|startoftranscript|><|notimestamps|> までがすでに与えられ、そこから自己回帰的にそれに続くトークン列を生成していき、EOTトークン <|endoftext|> が出力されたら終了、というふうに動作します。
ふりがなWhisperデコード時の工夫
ふりがなWhisper学習時は、出力が「カタカナと句読点2種類 、。」のみとなるように学習データを正規化して学習をしています。これは、他の句読点 !?!?…・・,.や空白等がデータに含まれていたり、それらの間で表記揺れがあるとノイズとなるので、モデルの学習をできるだけ単純にするためで、実際句読点統一前より統一後のほうが結果はよくなりました。
推論時にも、カタカナと句読点2種以外の、例えば通常のWhisperのように漢字を出力しようとしてしまうことは望ましくありません。そこで、Whisperのカタカナと句読点2種以外のトークンを全てWhisperの 抑制トークン (suppress token) というものに設定することにしました。これは、特定のトークンが書き起こしに決して出力されないようにする(デコード時の出現確率を0にする)ものです。Hugging FaceのTransformersライブラリのASRパイプラインでは設定ファイルに抑制トークンが書き込めるため、実際にモデルを使用する際は自動的にこの抑制トークンが適用されます。
(厳密には1トークン1文字ではなく、カタカナ2文字で1トークンとなっていたり、逆に1文字が複数トークンに分かれている場合があるので、カタカナと句読点2種からなる文のトークナイズ結果として現れるトークンの集合を求める際は、複数文字の組み合わせも考慮して計算を行いました。)
-
言語学的に言うと、日本語のテキストのよみ「セカイワウツクシイ。」は、音素列よりも粗い区切りのモーラ列と呼ばれるものに対応し、普通音素列と言ったら
s e k a i w a u ts u k u sh i iのような子音と母音まで分割した形を指しますが、本記事ではモーラ単位しか扱わないので、便宜上モーラと音素を区別しないこととします。 ↩︎ -
最近のTTSモデルには、G2P処理を行わずに、直接日本語の書記素列のみを用いて学習してしまおう、というものもいくつかあります。AIにG2P相当の操作を暗黙的に学習させてしまおうというものです。人手やルールベースでの処理を排除して全てAIに任せよう、といういわゆるEnd-to-Endへ向かう音声合成という流れからすると自然ではありますが、日本語の場合は例えば英語に比べて読みの曖昧性が非常に高いため、また誤った読みを修正したい等のニーズが頻繁にあるため、まだG2P処理を行うモデルが多い印象です。 ↩︎
-
もっともこの論文での念頭にある新規性は、古典的ASRでよくある音素出力ではなく、アクセント情報も出力することだと考えられます。 ↩︎
-
通常のG2Pとして、ここではMeCabのデフォルトの読みを使用しました。 ↩︎
-
といいつつ、実際これらの2論文でのデコード時の辞書使用はもちろん容易に無効化することが可能だと考えられるため、そのように無効化した結果を今回のようなN-Best読みと組み合わせれば、結果的には本稿の提案手法と同じようなことが実現できると考えられます。 ↩︎

Discussion