AI 支援型質的データ分析のための下準備
REFI-QDA 標準に従って作成した質的データ分析ファイルは、ZIP アーカイブの.qdpx ファイルである。その中身は以下のプレーンテキストになっている。
- .qde ファイル:データ以外の全ての情報が入っている XML
- .txt ファイル:データ本体
これらはテキストファイルであるので AI に読ませることも簡単である。現在の Saboten では、ボタンをクリックするとワーキングディレクトリに.qdpx ファイルを解凍したうえで、そのディレクトリでターミナルを開き、Claude Code / Gemini CLI を呼び出せるようにしている。
つまり、プロジェクトファイルをコンテキストに与えて AI CLI と壁打ちができるわけだが、いかんせん.qde ファイルの行数が長くなるので、AI が一度に読めないことが多い。XML という形式自体、AI が読むには冗長だが、さらにメモからコードブック、コーディングまで全ての情報が入っているため、余計長くなっている。
そのため、AI Supported QDA(AI 支援型質的データ分析) を進めるためには、単純に.qdpx ファイルを解凍するだけでなく、AI にコンテキストとして与えやすいようなファイル構成を自動生成する仕組みが必要となる。
たとえば研究の目的やデータ収集方法などは、自動で生成する CLAUDE.md / GEMINI.md に記載しておくと、CLI が立ち上がったタイミングですでに AI が研究の概要を把握した状態にできる。
Description 属性を使う
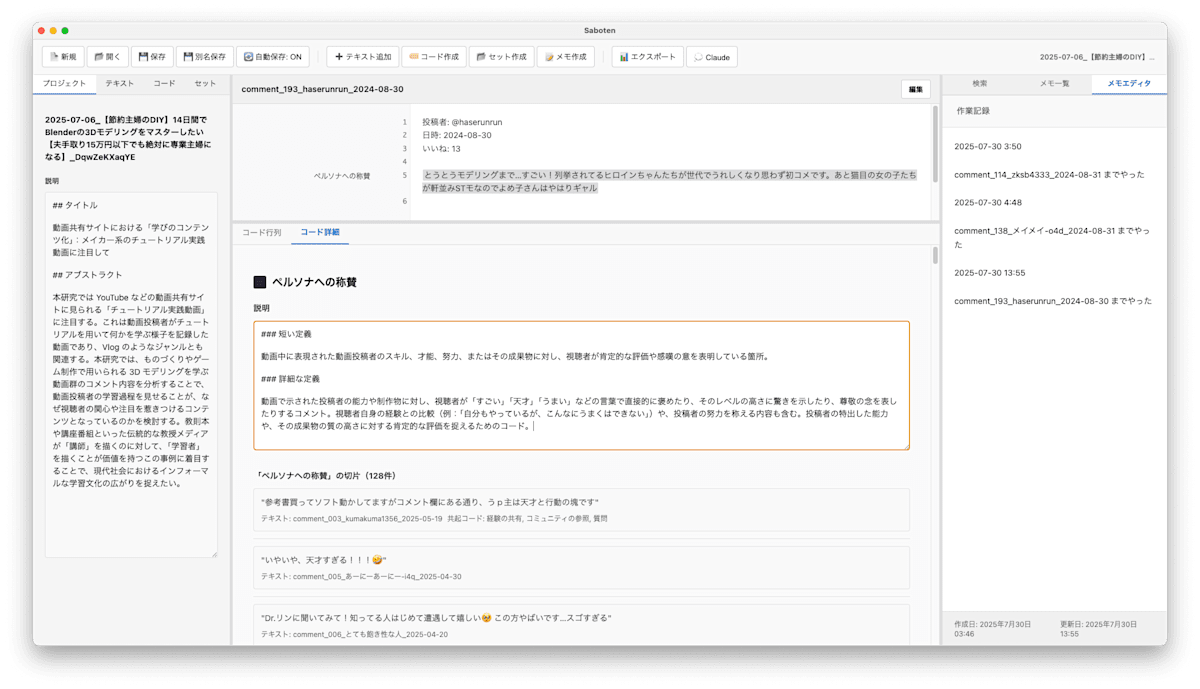
では Saboten ではどこにそれを書いておけばいいのか。最初はメモに書いておき、「研究概要」のようなタイトルのメモから引っ張ってくるのがいいかと思った。だが、REFI-QDA の仕様を見ていると、各オブジェクトに Description というテキスト型の属性があることに気づいた。
プロジェクトにもコードにも Description があるので、研究概要やコードの定義はここに書くことができる。これならば特定のメモタイトルを予約する運用をしなくても、Description への記入内容を引っ張ってくるだけでいい。
というわけで、とりあえずプロジェクトとコードの Description を編集できるテキストボックスを実装した。MAXQDA だとコードの定義もすべて「メモ」として書く必要があったが、それよりも扱いやすいと思う。
質的データ分析のためのコンテキストエンジニアリング
ここからどう AI に与えやすいファイルに切り出すか、そのファイルをどんなプロンプトで読ませるのか、は今後の作業である。
AI Supported QDA に関する先行研究 [1] [2] をいくつか読んでみると、ただデータを AI に渡すのではなく、研究の目的や分析の手順などをコンテキストとして与えるのが重要、とだいたい書いてある。
いわゆるコンテキストエンジニアリングを質的データ分析のために行うにはどうすればよいか。次の試行錯誤である。
-
Al-Fattal, A., & Singh, J. (2025). Comparative Reflections on Human-Driven and Generative Artificial Intelligence-Assisted Thematic Analysis: A Collaborative Autoethnography. International Journal of Qualitative Methods, 24, 16094069251337870. https://doi.org/10.1177/16094069251337870 ↩︎
-
Naeem, M., Smith, T., & Thomas, L. (2025). Thematic Analysis and Artificial Intelligence: A Step-by-Step Process for Using ChatGPT in Thematic Analysis. International Journal of Qualitative Methods, 24, 16094069251333886. https://doi.org/10.1177/16094069251333886 ↩︎

Discussion