レコメンドについてまとめる
参考資料
書籍
- 仕事で始める機械学習
- Hands-On Data Science for Marketing
- Pythonではじめる教師なし学習
- Practical Recommender Systems
- Hands-On Recommendation Systems with Python
記事
- これから推薦システムを作る方向けの推薦システム入門|masa_kazama|note
- 実装して理解するレコメンド手法〜協調フィルタリング │ キヨシの命題
- LGBMRankerを使ってAmazonのレビューデータセットでランク学習してみる │ キヨシの命題
- 協調フィルタリング入門
- ディープラーニングを活用したレコメンドエンジン改善への取り組み - ZOZO TECH BLOG
- レコメンドエンジンの性能の違い: 進化の歴史で振り返る | SILVER EGG TECHNOLOGY
- 推薦アルゴリズムの今までとこれから
企業事例
推薦システムの難しさ
- 推薦システムの難しさはデータが非常に疎(Sparse)である点
- 映画を例にすれば映画は人によって見るものがバラバラであるため、人気の映画には評価が集まり、そうでない映画には情報が集まらない
明示的データと暗黙的データ
- 明示的データ(Explicit Data)
- ユーザに直接好き嫌いや関心のあるなしを質問して得られた答え
- 暗黙的データ(Implicit Data)
- ユーザが商品を購入したり閲覧したりといった行動により得られたデータ
暗黙的データのほうが集まりやすいが、誤ってクリックした場合なども集計されてしまうため正確性は低い。そのため、例えば映画であれば一定時間以上見たなどの条件を設けてフィルタリングするなどの前処理が重要になる。
また、暗黙的データは未評価と不支持の区別がつかないという問題もある。(見なかった=嫌いとすることはできない)
推薦システムのアルゴリズム
アルゴリズムはCollaborative FilteringとContent-based Filteringに大きく分けられる。
Collaborative Filteringではユーザの過去における挙動と、そのユーザに類似した他のユーザの挙動からレコメンドを行う。
- 協調フィルタリング(Collaborative Filtering)
- User-based Collaborative Filtering
- Item-based Collaborative Filtering
- Model-based Collaborative Filtering
- 内容ベースフィルタリング(Content-based Filtering)
User-based Collaborative Filtering
「あなたと同じ商品を買った人はこんな商品を買っています」という推薦をする方法。
- ユーザ×アイテムの評価値行列があるときに、データに欠落のある(つまりまだ買ったことのない)アイテムの評価値を予測する
Item-based Collaborative Filtering
アクティビティが少ないユーザにもレコメンドを提示できるため、登録してすぐのユーザにもアプローチしやすい。
Model-based Collaborative Filtering
教師あり学習や教師なし学習のモデルを作ることでデータの規則性を元に予測する方法。
ここでいうモデルには以下のようなものがある。
- クラスタリング
- 嗜好が似ているユーザのグループを作成し、ユーザが所属するグループに好まれるものを推薦する方法
- 評価値を回帰などで予測するモデル
- トピックモデル(Topic Model)
- PLSA(Probabilistic Latent Semantic Analysis)やLDA(Latent Dirichlet Allocation)など評価値行列を次元削減することで潜在的な特性を表現することによるレコメンドを行う方法
- 行列分解(Matrix Decomposition)
- 有名なのがMatrix Factorizationと呼ばれる方法で暗黙的データに対しても活用できる
内容ベースフィルタリング
映画のタイトルや監督、ジャンルや俳優など、アイテムを表現する情報に着目しそれらのデータからレコメンドを行う
それぞれのメリットデメリット
- Collaborative Filtering
- メリット
- 明示的なデータじゃなくても(暗黙的データでも)レコメンドが行える
- ジャンルやテキストなどアイテムとしての情報が似ていなくても良い
- ドメイン知識を管理する必要がない
- デメリット
- 新規ユーザや新アイテムに対するデータが少なくレコメンドを出すのが困難(コールドスタート問題)
- メリット
- 内容ベースフィルタリング
- メリット
- 過去のデータがなくてもレコメンドを出せる
- デメリット
- 内容を分析するのが大変
- メリット
内容ベースフィルタリングはそれほど現実では使われていない。
というのも内容ベースフィルタリングでは個々のアイテムの性質を理解しなければならなく、現時点でのAIではレコメンドの役に立つようなレベルの理解を行うのは難しいため。
そのため、上記のメリットデメリットに記載したとおりユーザの挙動に関するデータを大量に集めて分析し、それに基づいて予測を行うほうがはるかに簡単であり、現実世界ではCollaborative Filteringの方がはるかに多く用いられている(NetflixのレコメンドもCollaborative Filteringが用いられている)
評価指標
- 分類
- 正解率(Accuracy)
- 適合率(Precision)
- 再現率(Recall)
- 順位相関
- レコメンドするアイテムの並びを評価する指標
Factorization Machine
Matrix Factorizationを一般化したアルゴリズム。
- Matrix Factorizationではユーザとアイテムの情報しか扱えなかったが、それ以外の情報も扱うことができる
- Logistic Regressionなどと異なり、疎な行列を扱うことができる
- 特徴量の間で影響を与え合う交互作用(Interaction)を考慮できるため、相関関係がある特徴量も適切に扱うことができる

仕組み
ユーザとアイテムからなる行列を2つの低次元行列に分解する。
ユーザとアイテムはより低次元の潜在変数空間(latent space)で表現されることになる。
具体的にはUserの情報とMovieの情報はOne-Hot Encodingされたベクトルとして表現される。
実装
Factorization Machineの実装としてはlibFMというライブラリが有名だが、Python実装としてfastFMというライブラリが提供されている。
種類
評価値予測なら二乗損失によるRegression、アイテム推薦ならBayesian Personalized Rankingによるランキング予測を行う。
推薦システムのためのOSSたち | takuti.me
とコメントがあるが、他にもClassificationもある?
Solver
以下3つのSolverがあり、用途に応じて選択する。
- ALS(Alternated Least Squared)
- SGD(確率的勾配法)
- MCMC(Markov Chain Monte Carlo Methods)
潜在因子
潜在因子kの数がモデルの容量を決める。kが大きくすると個々のユーザに対して特化した予測ができるようになるが、大きくし過ぎると過学習の可能性が高くなる。
実装
MovieLens100kを使用。
データの整形
- FastFMがインプットとして想定しているのはSparseデータなので、変換が必要
- OneHotEncodingするので、各データの項目数はUserの数 + Itemの数になる
import sklearn.preprocessing as sp
# UserとItemの情報を出力
print(f'Number of unique users: {n_users}') # 943
print(f'Number of unique movies: {n_movies}') # 1682
print(f'Number of total ratings: {n_ratings}') # 100000
print(f'Average number of ratings per user: {round(avg_ratings_per_user,1)}') # 106.0
# 訓練データ90%、テストセット5%、検証セット5%に分割する
X_train, X_test = train_test_split(lens, test_size=0.10, \
shuffle=True, random_state=42)
X_valid, X_test = train_test_split(X_test, test_size=0.50, \
shuffle=True, random_state=42)
# モデルの訓練用にmovie_idとuser_idを疎行列に変換する
enc = sp.OneHotEncoder(sparse=True)
enc.fit_transform(lens[['movie_id', 'user_id']])
X_train_spr = enc.transform(X_train[['movie_id', 'user_id']])
X_test_spr = enc.transform(X_test[['movie_id', 'user_id']])
X_valid_spr = enc.transform(X_valid[['movie_id', 'user_id']])
# 訓練セットの形式を表示 943 + 1682 = 2625
X_train_spr.shape # (90000, 2625)
参考資料
生成教師なしモデル
生成教師なしモデル(generative unsupervised model)とは元のデータセットの確率分布を学習し、それを用いて未知のデータに対する推測を行うもの。
Logistic Regressionや決定木、k平均法や階層クラスタリングなどの識別モデル(discriminative model)はデータから確率分布を学習しない。
制限付きボルツマンマシン
最も簡単な生成教師なしモデル。
制限なしのボルツマンマシンは学習効率が非常に悪く、ビジネス面で大きな成果を上げることが出来なかった。
制限付きボルツマンマシン(RBM)はその改良版。
RBMはデータの背後にある構造を学習する際に確率的(stochastic)な手法を取る。
一方オートエンコーダなどは決定的(deteministic)な手法を取る
推薦システム
Practical Recommender Systems より
Recommenderとは?
- 毎日八百屋にいっておすすめの野菜をレコメンドしてもらう
- 野菜の場合には何度も同じものをおすすめしてもらっても大丈夫(映画、音楽、本などではだめだけど...)
- メールで送られてくる大量のセール情報など。これはレコメンドではなく、広告
A recommender system isn’t only a fancy algorithm. It’s also about understanding the data and your users.
Longtailとの関係性
Chris Andersonが提唱したLong-tailとレコメンドの関係性は深い。
Long-tailのアイデアは店で売れる商品の数と顧客の数に制約がなくなれば、人気ではない商品を売ることができるというものだった。
しかし、商品数が増え続ければユーザが自分が欲しい商品を見つけることが難しくなり、この問題を解決するためにレコメンドの仕組みが必要とされるようになった。
扱う商品数が膨大であり、レコメンドに巨額の投資をしているという点でAmazonとNetflixがこれの良い例。
Netflixの事例
Recommendは点数を予測するだけではない
点数を予測する部分は一部で、顧客にレコメンドを行う一連の流れをシステムとして考えないといけない。
Taxnomy
色々な種類のレコメンドシステムの分類に使う観点をまとめたもの。
この書籍の著者がIntroduction to Recommender Systems: Non-Personalized and Content-Based | Coursera を元に作ったもの。
Domain
レコメンドの対象となる領域のこと。
例えば、映画、音楽、医療系の情報ではそれぞれでレコメンドが期待はずれだった時の影響が全然違う。
Context
Personalization Level
- Non-personalized
- 最も人気の作品など、特定のグループに依存しないレコメンド
- Semi-personalized
- セグメントの情報を元に行うレコメンド
- Personalized
- 一人ひとりの情報を元に行うレコメンド
Privacy and trustworhiness
多くの人がレコメンドは一種の操作だと考えている。
特定の商品などをスポンサーの関係などで提示することもできる。
そうしたレコメンド結果が信頼できないと考えられたらお客さんは離れていってしまうはず。
Interface
- Input
- 以下の2つに分かれる
- explicit input
- レーティングなど、ユーザが明示的に良い悪いを数値として表現したもの
- implicit input
- ユーザの行動(動画を見て1分でやめたなど)を元にユーザの意図を推測する
- explicit input
- 以下の2つに分かれる
- Output
- ページの構成
- organic presentation
- それがレコメンドだとわからずに、ページに埋め込まれているもの
- non-organic presentation
- organic presentation
- 理由の説明
- black-box recommender
- この本を買ったからこれを表示していますなど、理由を説明しているもの
- white-box recommender
- black-box recommender
- ページの構成
Algorithms
- Collaborative Filtering
- 色々なやり方がある
- Content-based Filtering
- レコメンド対象のアイテム自体の情報(メタデータ)を使ってレコメンドを行う
- Hybrid Recommender
- Collaborative FilteringとContent-based Filteringを組み合わせたもの
MovieGEEK's Website
この本ではレコメンドシステムについて学ぶための題材として、架空の映画サイトを使う。
以下がそのアーキテクチャ。
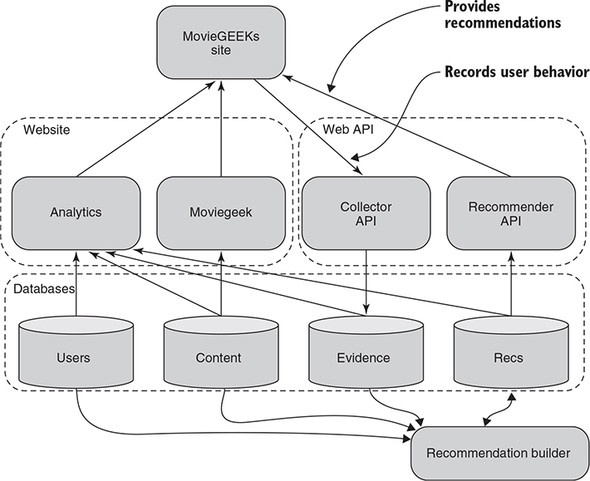
MovieGeekのリポジトリ
データセットとして使用しているMovieTweetingsのリポジトリ
Practical Recommender Systems より
Collaborative Filtering in the neighborhood
データセットとしてsidooms/MovieTweetings: A Live Movie Rating Dataset Collected From Twitter を使う。
使うアルゴリズムは Amazonで2003年から使われているitem-item collaborative filtering(G. Linden et al., Amazon.com Recommendations: Item-to-Item Collaborative Filtering. Available online at http://ieeexplore.ieee.org/abstract/document/1167344/.)
Item-to-Item Collaborative Filteringのアイデアは顧客が購入やレビューしたアイテムと似た傾向があるアイテムをレコメンドするというもの。
Collaborative Filteringの歴史
以下の2つに分類できる。
- User-based
- Item-Based
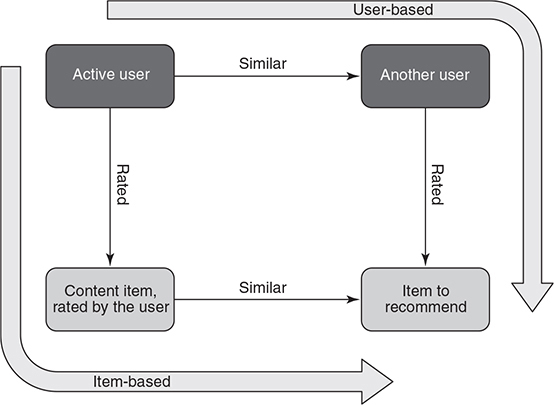
どっちを使うべき?
- 一般的なユーザはあまり多くの商品にレビューをしていない。そのため、ユーザ同士の類似度を事前に計算することはあまり良い選択ではない(代わり映えのしない(パーソナライズできない)結果しかでない)
- 一方、一般的に同じ好みを持つユーザは同じタイプのアイテムを好きになるはずなので、アイテムベースの方がより確かな結果がでる
The reason why people are still talking about user-user-based filtering is that it’s a better way to give recommendations. If you do item-to-item filtering, you’ll find items similar to what user A, for example, has already rated, but similar items won’t provide the serendipity that similar ratings can provide.
データの要件
- だれもレビューをしていなければ、何もレコメンドはできない
- ユーザが他のユーザと似た傾向を示していなければ、良いレコメンドはできない
Practical Recommender Systems より
Finding hidden genres with matrix factorization
Latent Factorsに着目してCollaborative Filteringについてまとめる。
アプローチとして色々あるが、時間的な制約等も加味して現実的にそれを実現する方法がMatrix Factorization.
Netflix Prize
The winner was an ensemble recommender algorithm, which means mixing many different algorithms to produce the final result (and, incidentally, the topic of chapter 12). The winning ensemble was so complicated that it never went into production. Instead, another solution made by Simon Funk became famous for getting close to winning because he blogged about it. His finding has been the basis for many other solutions since.
Practical Recommender Systems より
Basic Idea
The basic idea is that by looking at the behavioral data of users, you can find categories or topics that let you explain users’ tastes with much less granularity than with each movie but more detail than genres
...
Talking about hidden things makes it sound as if there’s always something there, so it’s worthwhile to point out that if your data is random or it doesn’t have any signal, the reduction won’t provide any additional information. But by extracting factors from the data, you’ll use more of the data collected for a user.
モデルの予測結果の活用法
- 根本的にすべてのアイテムに対する予測結果を得られるようになったのが違い
Brute force
各ユーザのすべてのアイテムに対する予測を行い、その中で評価が高いN個のアイテムをレコメンドとして提示するなど。
Neighborhoods
User behavior and how to collect it
最初っからデータがそろっていることはまず無いので、どのようなデータが使えるのかを考えないといけない
- explicit
- レーティングやLikeのように明示的なフィードバックを返したデータ
- implicit
- ユーザの行動を観察することにより得られたフィードバックとなるデータ
この違いについては以下でより詳細に述べられている。
http://guidetodatamining.com/.
Netflixの事例
- 集めるデータ
- evident collector
Finding useful user behavior
- ユーザが商品を知ってからの一連の流れをプロセスにまとめるとレビューなどのexplicit feedbackが得られるのはほぼ最後になる。そのため、その前のフェーズでユーザの行動を計測し、理解できるようにしておかないといけない
Browse
Page view
興味を持ってみているかもしれないし、ランダムや間違ってみた可能性もある。後者の場合はクリック数が増えてもポジティブなことにはならない。
Page Duration
時間の長さによって意味が変わってくる(と推測される)
Expansion Link
以下のような行動を取ったら、商品に興味がある
- Read Moreなどを開いた
- レビューや技術使用を見る
Monitoring the System
ユーザの行動やレーティングなど、レコメンドの判断基準となるデータが集められたらそれをレコメンドに繋げるために2つのステップが必要。

なぜダッシュボードを加えることがいいアイデアなのか
うまくやっているのか、レコメンドを導入したことによる効果は?
こうした質問に答えるためにダッシュボードは非常に有効。
分析の実行
Web
- Off-site
- サイトの外
- On-site
Basic
Another thing to consider when creating your dashboard is that if you want to keep an eye on how it develops, it can be a good idea to display a chart that shows the values of KPIs over a historical period, such as the last six months, rather than one value.
Conversions
基本的な考えはサイトを訪れた人のうち、ゴールと定める(自分たちがしてほしいと思っている)成果を挙げた数。
オンライン上でのマーケティングにおける基本的な概念。
Conversionの考えはconversion funnelから来ている。
Conversionの考え方は事業内容にもよる。
- Amazonの場合
- サイトを訪れる度に買い物(Conversion)をしてほしい
- カーディーラーの場合
- より長いスパンでConversionしてほしい
Ratings and how to calculate them
- 集めたユーザのデータをレコメンドシステムに渡すためのインプットに変換する工程を扱う
- User item matrixからほとんどのシステムが始める
- 前述のとおりWeb上でのユーザの行動はimplicit ratings
- implicit ratings はexplicit ratingsよりデータを集めやすいというメリットがある
- ImplicitにしろExplicitにしろ、Ratingはユーザとアイテムを紐付ける手がかりであり、レコメンド時に使うことができる。
User-item preferences
Userを行、itemを列にしたものがuser-item matrixであり、これを利用してユーザの嗜好を把握することができる。
データが疎になる可能性ある
Explicit or implicit ratings
現実世界ではimplicitとexplicitそれぞれがデータとして入ってくる。
実際ユーザが満足しているかどうかを理解するにはドメイン知識が必要で、なおかつユーザの行動をクリティカルに見る必要がある。
例えば似た映画を2つみたけどどちらも低いレートをつけた場合など。(そのジャンルは好きだけど、見た映画がつまらなく感じたことを示唆する?)
On a movie site such as MovieGEEKs, if a user bought something and then rated it, the rating is probably trustworthy. Or is it? I’ve enjoyed films that I rated low, so what if the user buys two similar films and rates both low? How much would you then trust the ratings?
These are domain-specific questions, so it isn’t easy to give general answers. But since the user keeps buying films that he rates low, then you should probably show more films that he would rate low also. But an HBO user (another subscriber-only online streaming service) rates something that’s only available on HBO, so without seeing it, do we trust it? Always have a critical eye on what data is showing you.
Implicit ratingsとは
以下のような明示的なレーティングをしていないが、ユーザの嗜好を示す可能性がある情報をimplicit ratingという。
- 商品を買った
- 映画を見た、音楽を聴いた
- プロダクトの詳細ページをみた
- 商品を返品した
データの使い方は色々ある。
ニューヨークタイムズはレーティングの仕組みがないのでimplicit ratingのみを使っている。具体的には過去の閲覧履歴を使って次に読む記事をレコメンドしている。
Buy EventsやLike Eventsを使うことで簡単にUser-Item matrixが作れる。
Time-based approach
例えばAmazonで本を4年間買っているとして、最初の2年間と次の2年間で買う本が全く変わったとしたら、最近の本の方を重視してほしい。
User-Item matrixは作るのは簡単だが全てを好きかそうでないかで白黒をつけてしまう。もう少し細かなニュアンスを盛り込めないだろうか。
Therefore, a way to make the matrix more nuanced is to use a function based on the purchase date. You could go as far as to add the production time of the item also
Hacker Newsはこれに似たアルゴリズムを採用している。
Behavior-based Approach
Amazonのような巨大なサイトならいいが、多くのサービスでは購入だけを判断基準にするとマトリックス上は空のデータだらけになってしまうはず。
そのため、ユーザが嗜好を示した基準として購入など直接的な行動以外を取り入れる必要がある。
Implicit ratingを実際に取り入れる
計算したいのはユーザが商品を購入する可能性であって、ユーザがその商品に高い評価をつけるかではない。
- 購入-> トップレート
- 詳細ページの閲覧 + より詳細を見るをクリック -> 非常にポジティブ
Implicit Rating Functionの計算
- ネガティブイベント
- Dislikeボタン
- 途中で見るのをやめた
形としては最適化問題だが、あくまで推測に基づく計算であることに注意。
計算にあたって考慮すべきか検討が必要なのは一定以上の回数に意味を持たせるか。(カットラインを設けるか)
10回商品詳細を見るのと20回商品詳細を見るのに大きな違いは存在するか?
Machine Learningの問題
実装
人気でないItemの方が価値がある?
人気のある商品はよくレコメンドの対象として候補にあがるが、2つの商品を買った時、その人の嗜好を示してくれる度合いは話して同じだろうか。
以下の2つの購入データがあった時、どちらがよりその人の嗜好を示してくれるだろうか。
- その当時一番人気だったロードオブザリングを購入した人
- ロードオブザリングの中でも限定100個しか生産されていないコレクターズエディションを買った人
このように他の人(全体の傾向)と違うイベントについてはその人独自の嗜好を示すものとして、レコメンド時に重み付けして考慮することが考えられる。
Non-Personalized Recommendations
個別のユーザの嗜好について一切知る必要がないため始めやすい。
以下について扱う。
- charts
- ordering
- association rules
Non-personalized recommendations
commercialとrecommendationの違いについて。
- commercial
- 自分たちが見せたいもの(売りたいもの)をユーザに提示すること
- コマーシャルは使い方に気をつけないとユーザを離反させることになるので使い方に注意が必要
- recommendation
- ユーザが自分が求めているものを提示する
- commercialと異なりデータをもとに提示する
- 閲覧数に基づいて最も人気のあるカテゴリを提示するのはrecommendation
Charts and Orderinga
- ハードコードして特定の記事や商品を表示する
- 新しさ(Recency)で
- top10
Seeded recommendations
検索、閲覧、購入などのユーザの行動に応じて関連するものをレコメンドする。
- Frequentey Bought Together(FBT)
- Amazonなどのウェブサイトでよく見られるもの
- associationを作る方法をaffinity analysisやshopping basket analysisと呼ぶ
多くの商品は単純にポピュラーなアイテムと一緒に買われるので、それを考慮に入れる必要がある。
Association Rules
一緒に購入された商品のリストを眺めてみる。
試しに商品を選んで、それと一緒に購入されているものを探す。
ミルクはどの商品を選んでも買われているので参考にならない。
常に一緒に買われている商品の組み合わせ(itemset)を探す。
ルールを決める。
The User
Cold Start Problem
ユーザのことを知らなければパーソナライズはできない。
ユーザをリピート顧客にしたいのに、その情報がなくてできないことは非常に大きな問題であり、Cold Startという名前がついている。
同じような問題にgray sheepというものがあり、これは好みが独特であるためデータがあったとしてもそのユーザと同じ商品を買う人がいないというもの。
Personalized Recommendationsはレコメンドするアイテムとユーザを紐づける情報をもとにしている。
紐付け方には以下の3種類がある。
- Content
- Collaborative
- Demographic
このどの方法も使えないのが、cold-startの時と、gray sheepに対して。
Cold Products
ある程度既存プロダクトがあると新しいアイテムが入ってきたときにその中に埋もれて、存在に気づかれない。
そのため、存在に気づいてもらうために何らかの対応をしないといけない。
具体的には以下の方法が考えられる。
- メールで知らせる
- サイトを訪れる人にはNewArrivalsなどで知らせる
ColdUser
新しいユーザ(その人の好みを知らない)もCold-startの一種。
Many scientific papers say that recommendations can’t be calculated before a user has rated at least 20 to 50 items. Normally, the customer expects sites to start delivering recommendations long before that.
Cold Startへの対処
Keep track of visitors
初めてサイトを訪れたユーザについて、登録してくれたらベストだけど戻ってきたときに識別できるようにIDを付与しておきたい。
While you’ll prefer users to register, you’ll still want to save an ID for the anonymous sessions, so that you can recognize them if they do return
Recognizing users means that you can accumulate information about the person, which will make the system calculate recommendations even before you know who they are.
昔はCookieを登録しておけばよかったけど、ユーザがブラウザやデバイスを変更したら意味がなくなってしまう。
Djangoではannonymous sessionsという機能があり、Cookieの管理や送受信を行ってくれる。
CookieにはsessionIDが含まれており、ユーザIDをセットして保存しておくことでシステムとしてユーザを識別することが可能になる。(デバイスを使うのが一人という前提)
セッション情報のサーバサイドでの管理には注意が必要。
なぜなら、4000万人のユーザがいれば、ストレージとセッション情報の取得は問題になりかねない。
algorithms
-
Cold-Startに対する明確な解決策は確立されていない
-
Machine Learningもデータがなければ解決策になり得ない
-
解決策は結局のところ少ないデータ(sparse data set)から有益な情報を見つけ出すことになる
-
具体的には既に持っているデータ
-
セグメントを作っていつ時点で特定のセグメントに割り当てられるかを考える
参考資料
Finding Similatiries among users and among content
なぜ類似度を算出するか
類似度の種類
- Cosine Similarity
- Jaccard Similarity
Clustering
類似度の算出を全ユーザに対して行うよりも、より少ないユーザのグループに対して行う方が計算効率の面では良い。
Collaborative Filtering in the neighborhood
Evaluating and testing your recommender
レコメンドの仕組みを導入した後、正しい方向に進んでいるか計測、評価する必要がある。
Business
One thing that’s often forgotten is that all data applications are living things (not in the AI sense) and require maintenance and monitoring
Performance is a product of the data being used, which is updated constantly. The behavior of the system changes if the data changes, and the system’s performance and predictive power might diverge or degrade.
レコメンドのシステムの評価は以下のステップを踏む。
- Verify Algorithms
- Refression Tests
- Offline Algorithms tes
- Friends and family
- A/Bテスト
- Exploit/Explore
評価の重要性
実際のところデータで計測してもそこから導き出した推測が正しいかはわからない。
More to the point, though, the goal might not be immediately measurable, and the things that are measurable might not uniquely indicate what you want to know.
実際に試してみるしかなく、そのためには自分が答えるべき質問をはっきりさせておく。
そのためには、仮説(Hypothesis)を誰に説明してもわかるような形で立てておく。
A hypothesis describes the goal of the test. For us, that could be “Recommender B produces recommendations that are clicked more often than recommendations from Recommender A.” The click event is also called the click-through rate (CTR).
どのようにユーザの行動を計測するか
何を計測するか
Content-based Filtering
- Ex Machinaを見て面白かった
- それと同じジャンルの映画を探す
- そのジャンルの中で一番条件に当てはまるものとしてTerminatorをレコメンドする
同じ映画が好き
- タグ
- テキスト(Description)
NLPを使って重要なTopicのリストを作るようにsルウ
Content-based filtering
以下3つの仕組みで成り立つ。
- content analyzer
- user profiler
- item retriever
content analyzer
contentの内容を有益な情報を含むvectorに変える。
- Metadata
- Facts
- 公開年や出演者など客観的な事実
- Tags
- 主観的
- 人によってつける基準が異なる
- 同じ内容を違う言葉で表していたりもする
- 主観的
- Facts
- Description
特徴を示すVector(Table)を作っていくと非常にたくさんの項目が入る。
Content-based filteringにおいてはどの項目が重要でどの項目が重要でないかを判断するのが重要になる。
この項目が重なるものを複数見た場合には、同様の傾向を持つコンテントをレコメンドすることができる。
DescriptionからMetadataを抜き出す
ニュース記事などはお互いの関連性が薄く、Collaborative Filteringによるレコメンドが難しい。
TF-IDFを使って重要な単語を抜き出すことができる