Scrapingについてまとめる
参考資料
Webページの取得
まず基本としてWebページの情報の取得から。
ここではrequestsライブラリを使用してWebページを取得してみる。
コードとしては以下で指定したURLのHTMLを取得できる。
import requests
r = requests.get('https://gihyo.jp/dp')
r.status_code # 200
r.headers['content-type'] # text/html; charset=UTF-8
r.encoding # UTF-8
# textでstr型にデコードしたレスポンスボディを取得できる
r.text
# contentでbytes型のレスポンスボディを取得できる
r.content
エンコーディングについて
r.encodingでWebサイト側で指定したエンコーディングの情報が取得でき、r.textでstr型の文字列を取得した際には、このエンコーディングを使ってデコードされた結果が返される。
このエンコーディングは正しくない場合もあり、その場合にはr.encoding = 'cp932'のように上書きすると、text属性にアクセスしたときには指定したエンコーディングでデコードを行ってくれる。
文字コードの扱い
requestsで取得した時のようにHTTPでページの情報を取得する場合、中身はバイト列として表現される。
人間から見た言葉としては同じでもエンコーディングによってバイト列の中身は以下のように異なる。
print('あ'.encode('utf-8')) # b'\xe3\x81\x82'
print('あ'.encode('cp932')) # b'\x82\xa0'
print('あ'.encode('euc-jp')) # b'\xa4\xa2'
そのため、「エンコーディングについて」で触れたように正しいエンコーディングでデコードする必要があるが、そのためには使用されたエンコーディングの種類を知る必要がある。
日本語を含む多様なサイトをクロールする場合には複数なエンコーディングが入り混じる可能性がある。
そうしたケースでの対処法として以下3つが考えられる。
- HTTPレスポンスのContent-Typeヘッダーのcharsetで指定されたエンコーディングを取得する
- HTTPレスポンスボディのバイト列の特徴からエンコーディングを推定する
- HTMLのmetaタグで指定されたエンコーディングを取得する
requestsのオプション
requestsにはさまざまなオプションの指定が可能であり、状況に応じて色々なリクエストを行うことができる。
# HTTPヘッダーとしてUser Agentの情報を追加
r = requests.get('http://www.example.com',
headers={'user-agent': 'my-crawler/1.0 (+foo@exmaple.com)'})
# Basic認証の情報を追加
r = requests.get('http://www.example.com',
auth=('<ID>' : '<PASSWORD>')
# paramsでクエリパラメータの指定を行う
r = requests.get('http://www.example.com',
params={'Kye1' : 'Value1'})
また、requestsの機能としてSessionオブジェクトというものがあり、複数のページや共通の情報(HTTPヘッダーや認証情報)を使い回すのに便利。
s = requests.Session()
# HTTPヘッダーを設定して複数のリクエストで使い回す
s.headers.update({'user-agent': 'my-crawler/1.0 (+foo@exmaple.com)'})
# Sessionオブジェクトにはgetやpostなどのメソッドがあり、requests.getと同様に使える
r = s.get('https://gihyo.jp/')
r = s.get('https://gihyo.jp/dp')
Webページからデータを抜き出す
Webページの取得ができたら次は情報を抜き出す部分。
主な方法として以下の2つがある。
- 正規表現
- HTMLパーサー
正規表現によるスクレイピング
Pythonではreというライブラリで正規表現を使うことができる。
reの基本的な使い方
-
re.search
- 第二引数の文字列が第一引数の正規表現にマッチするかテストできる
- マッチする場合にはMatchオブジェクトが、マッチしない場合にはNoneが返される
- 第三引数でオプションを指定できる。
-
Matchオブジェクト
-
groupメソッドでマッチした値を取得できる - 引数に0を指定すると、正規表現全体にマッチした値が得られる
- 引数に1以上を指定すると正規表現の()で囲った部分(キャプチャ)にマッチした値を取得できる。
-
-
re.findall
- 正規表現にマッチするすべての箇所を取得する
-
re.sub
- 正規表現にマッチする箇所をすべて置換する
# re.searchでマッチするのでMatchオブジェクトが返される
re.search(r'a.*c', 'abc123DEF') # <re.Match object; span=(0, 3), match='abc'>
# マッチしないのでNoneが返される
re.search(r'a.*d', 'abc123DEF') # None
# IGNORECADEで大文字小文字の違いを無視したため、マッチする
re.search(r'a.*d', 'abc123DEF', re.IGNORECASE) # <re.Match object; span=(0, 7), match='abc123D'>
# 正規表現での検索結果からgroupメソッドを使ってマッチした値を取得
m = re.search(r'a(.*)c', 'abc123DEF')
m.group(0) # abc
# 1を指定してキャプチャにマッチした値を取得
m.group(1) # b
# \w はUnicodeで単語の一部になり得る文字にマッチする。
# 以下は2文字以上の単語をすべて抽出している
re.findall(r'\w{2,}', 'This is a pen')
#
re.sub(r'\w{2,}', 'That', 'This is a pen')
reを使ったスクレイピング
HTMLパーサーによるスクレイピング
スクレイピングに用いるライブラリでは以下のどちらかを使うことが多い。
- XPath
- CSSセレクター
XPathとCSSセレクター
- XPath
- XMLの特定の要素を指定するための言語。
//body/h1という表記でbody要素の直接の子であるh1を指定できる
- XMLの特定の要素を指定するための言語。
- CSSセレクター
- CSSでスタイリングを行うのと同様の記法で要素を指定するもの
-
body > h1という表記でbody要素の子であるh1を指定できる
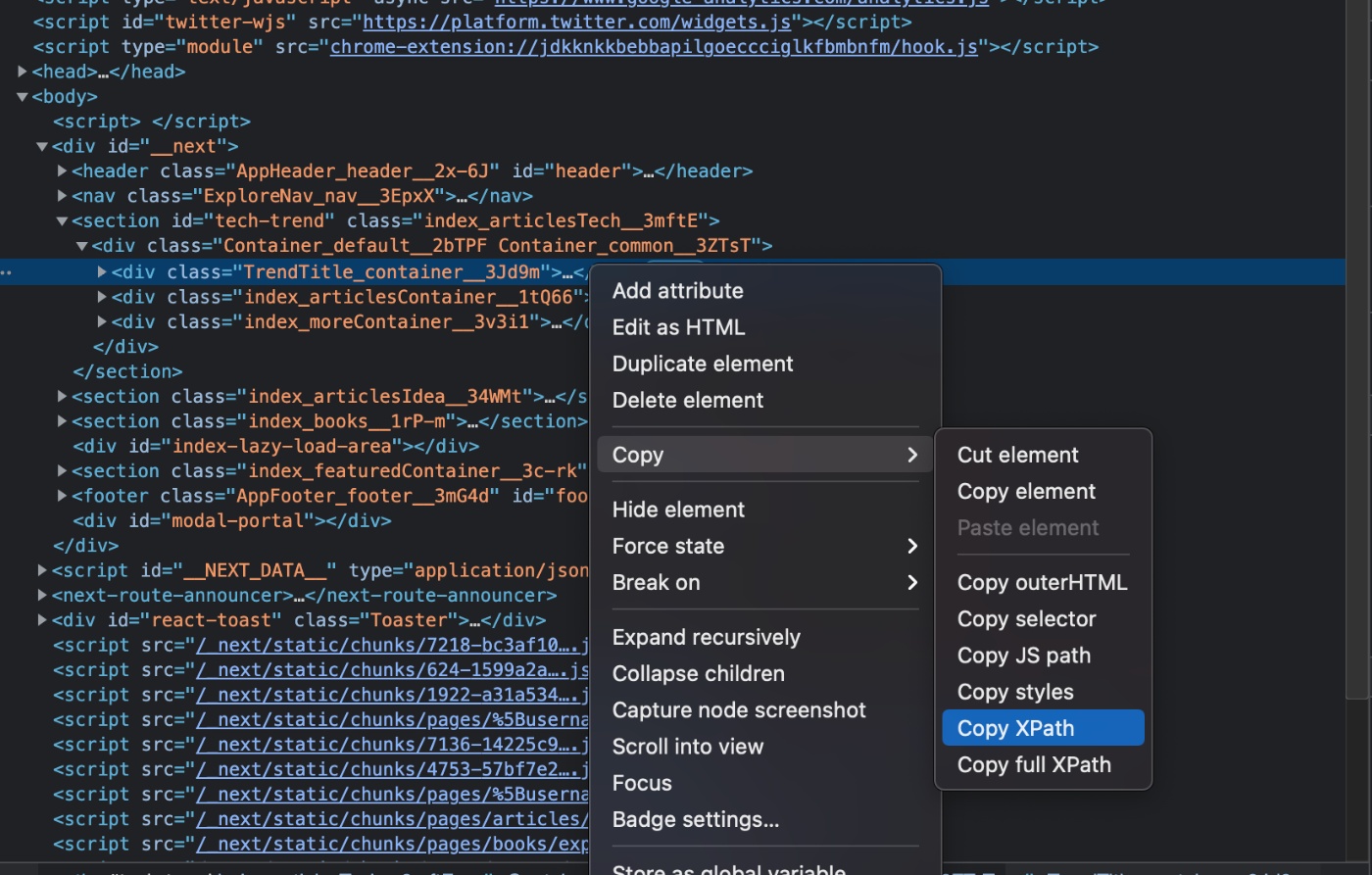
開発者ツールの活用
Google Chromeなどで提供されている開発者ツールを用いてXPathやCSSセレクターの値をコピーできる。
以下のスクショの通りCopy XPathでXPathが、Copy selectorでCSSセレクターがそれぞれコピーできる。
lxmlによるスクレイピング
import lxml.html
tree = lxml.html.parse('dp.html')
html = tree.getroot()
# 引数のURLを基準として、全てのa要素のhrefを絶対URLに変換する
html.make_links_absolute('https://gihyo.jjp/')
# CSSセレクターでa要素のリストを取得して、個別のa要素(書籍の情報)に対して処理を行う
for a in html.cssselect('#listBook > li > a[itemprop="url"]'):
# a要素のhref属性から書籍のURLを取得する
url = a.get('href')
# 書籍のタイトルは
p = a.cssselect('p[itemprop="name"]')[0]
title = p.text_content()
print(url, title)
>>>
https://gihyo.jjp/dp/ebook/2021/978-4-297-12236-2 無料で作る! お店・会社のためのホームページ作成超入門
https://gihyo.jjp/dp/ebook/2021/978-4-297-12266-9 レシピ集 C#コードレシピ集
...
スクレイピングの一連の流れをまとめる
ページの取得からスクレイピングの流れで言えば、これまではファイルに保存したhtmlファイルをインプットとしてきたが、ここではrequestsで取得したページの文字列をそのままlxmlのfromstringに渡すことでhtmlElementを取得しているところがポイント。
import csv
from typing import List
import requests
import lxml.html
def main():
"""
メインの処理。fetch(), scrape(), save()の3つの関数を呼び出す。
"""
url = 'https://gihyo.jp/dp'
html = fetch(url)
books = scrape(html, url)
save('books.csv', books)
def fetch(url: str) -> str:
"""
引数urlで与えられたURLのWebページを取得する。
WebページのエンコーディングはContent-Typeヘッダーから取得する。
戻り値: str型のHTML
"""
r = requests.get(url)
return r.text
def scrape(html: str, base_url: str) -> List[dict]:
"""
引数htmlで与えられたHTMLから正規表現で書籍の情報を抜き出す。
引数base_urlは絶対URLに変換する際の基準となるURLを指定する。
戻り値: 書籍(dict)のリスト
"""
books = []
html = lxml.html.fromstring(html)
html.make_links_absolute(base_url) # 全てのa要素のhref属性を絶対URLに変換する
# CSSセレクターでa要素のリストを取得して、個別のa要素(書籍の情報)に対して処理を行う
for a in html.cssselect('#listBook > li > a[itemprop="url"]'):
# a要素のhref属性から書籍のURLを取得する
url = a.get('href')
# 書籍のタイトルは
p = a.cssselect('p[itemprop="name"]')[0]
title = p.text_content()
books.append({'url': url, 'title': title})
return books
def save(file_path: str, books: List[dict]):
"""
引数booksで与えられた書籍のリストをCSV形式のファイルに保存する。
ファイルのパスは引数file_pathで与えられる。
戻り値: なし
"""
with open(file_path, 'w', newline='') as f:
writer = csv.DictWriter(f, ['url', 'title'])
writer.writeheader() # 1行目のヘッダーを書き出す
# writerowsで複数の行を一度に書き出す
writer.writerows(books)
if __name__ == '__main__':
main()
ライブラリによるクローリング、スクレイピング
HTMLのスクレイピング
Beautiful Soup
Beatiful Soupでは目的に合わせて内部のパーサーを選択できる。
- html.parser
- lxmlのhtmlパーサー
- lxmlのxmlパーサー
- html5lib
pyquery
クローラーとURL
クローラーの作成
メモ
次の要素を取得する
# soupの要素を直接指定してその次の要素を取得
print(soup.p.next_sibling.next_sibling)
# findで条件を指定した要素の次の要素を取得
result = soup.find('h3', text='Sample').next_sibling.next_sibling
値の取得方法
- tag.get_text()
- Tagのテキスト要素を取得
- tag.get('href')
- 指定したアトリビュートの値を取得?
links = [{ "title": url.get_text(), "url": url.get('href')} for url in soup.find_all('a')]
get_textのオプション
- 第一引数として文字列を渡すことで、要素ごとの区切り文字を挿入できる
- stripを指定することで自動で挿入される改行コードが削除される
# soup.get_text("|")
'\nI linked to |example.com|\n'
# soup.get_text("|", strip=True)
'I linked to|example.com'
[text for text in soup.stripped_strings]
# ['I linked to', 'example.com']
URLの結合
以下のようにos.path.joinではなく、urllibを使う。
import urllib.parse
absolute_link = urllib.parse.urljoin(BASE_URL, relative_link)
PDFを保存
ポイントとしてはcontentを指定してバイト形式で書き込みを行うこと。
res = requests.get('https://...')
with open('/tmp/metadata.pdf', 'wb') as f:
f.write(res.content)
参考資料
Pythonを利用して任意の形式のファイルをダウンロードする - Qiita
Download and save PDF file with Python requests module - Stack Overflow
拡張子の取り扱い
os.path.splitext()でpath名と拡張子を分離できる。
temp_path = 'data.pdf'
os.path.splitext(temp_path)
>>> ('data', '.pdf')
# 以下のようにして受け取ればOK
path, ext = os.path.splitext(file_path)
参考資料
要素の取得方法
- find系
- select系
select系
# Attributeの条件を指定して検索
item_divs = soup.select("div[data-cy='sample']")
条件検索
BeautifulSoup - kinds-of-filtersに記載があるようにBeautifulSoupで検索条件の指定方法として以下がある。
- 文字列
- 指定した文字列と完全一致の条件で探す
- 正規表現
- 指定した正規表現の条件で探す
- List
- Listに含まれる要素全ての条件で探す(試してないが文字列だけでなくここで挙げられている指定方法全てが指定できる?)
- Boolean(True)
- Function
これを要素の取得方法(selectやfind)と組み合わせることで色々な条件を指定して要素の取得ができる。
任意の文字列で始まるクラス名を取得する
クラス名が固定されていればシンプルにクラス名をそのまま指定すれば問題ないが、対象ページが使用しているCSSライブラリによってはクラス名の末尾にランダムな文字列が付与されていることがある。
<p class="ArticleContent__32L1P znc">...</p>
<p class="ArticleContent__2cL6D nc">...</p>
<p class="ArticleContent__9sL1F znc">...</p>
...
こうしたケースでは完全一致でクラス名を指定しても検索に引っかからないので、その他の条件検索方法を利用する必要がある。
このケースではクラス名が特定の文字列(ArticleContent)で始まることを条件とすればいいので、BeautifulSoup - kinds-of-filtersに記載の通り正規表現ライブラリのreをimportして正規表現の検索条件をクラス名に対して指定すればOK。
import re
soup.find_all('div', class_=re.compile("ArticleContent"))
参考資料
Beautiful Soup のfind_all( ) と select( ) の使い方の違い - ガンマソフト株式会社
要素の削除
- clear
- タグの中身のみを削除する
- decompose
- タグ自体とその中身を削除する
- extract
Tag.decompose() removes a tag from the tree, then completely destroys it and its contents:
PageElement.extract() removes a tag or string from the tree. It returns the tag or string that was extracted:
Attributeでの検索
data-xxxだったり、Attributeの条件を指定して検索するときはそのままfind_allに条件を指定してもエラーになってしまう。
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>', 'html.parser')
data_soup.find_all(data-foo="value")
# SyntaxError: keyword can't be an expression
こういう時はattrsでキーバリューのペアを渡して対応する。
data_soup.find_all(attrs={"data-foo": "value"})
# [<div data-foo="value">foo!</div>]
クッションページの対応
対応方法
いくつか対応方法はあるが、結局のところ対象となるページがどのような仕組みで対応しているか次第。
- Selenium等を使う
- requestsのsessionを使う
- Cookieを設定する
参考資料
Selenum
取得したページ自体や、タグからHTMLを取得できる。
取得した後はBeautifulSoupに渡して解析を行えるので、それがいいかな?
# ページからHTMLを取得
html = driver.page_source
# 要素からHTMLを取得
element.get_attribute('innerHTML')
環境構築
- 【Python】seleniumでWebElementからhtmlを取得する | 研究所で働くエンジニアのブログ
- AWS Lambda上でSelenium+Webdriverを動かしたときの覚書 - taaaka.tokyo
- 4. Locating Elements — Selenium Python Bindings 2 documentation
###エラー対応
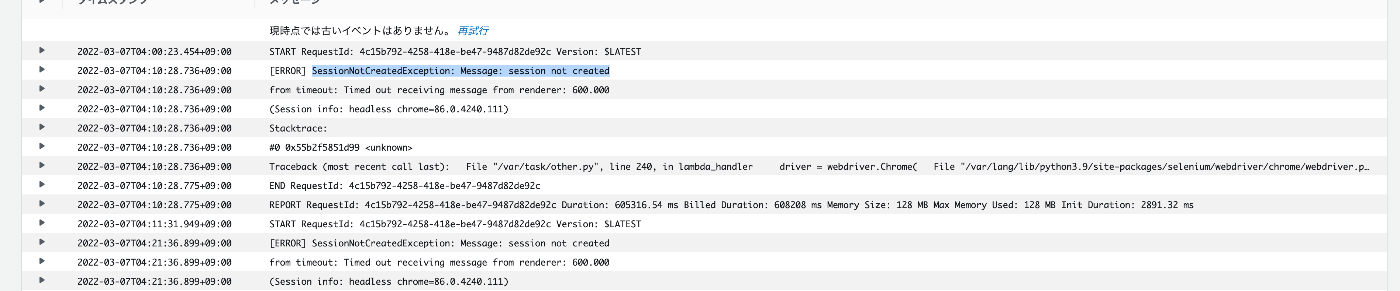
【2021年度版】Python + Selenium よく使う操作メソッドまとめ - Qiita
以下のページで各オプションが必要な理由について解説してくれている。
python - Selenium gives "Timed out receiving message from renderer" for all websites after some execution time - Stack Overflow
また、上記はdriver.getで結果が返ってこないことが直接的な原因のようだが、タイムアウトの時間を設定することもできる。
# 10秒まで待つ
driver.set_page_load_timeout(10)