Robust(頑強)なPythonコードの書き方
以下の書籍を通じて学んだRobustなPythonコードについてまとめる
GitHub
1. まとめ
Robustnessの必要性
If your software is “good enough,” why add even more complexity? To answer that, consider how often that piece of software will be iterated upon. Delivering software value is typically not a static exercise; it’s rare that a system provides value and is never modified again. Software is ever-evolving by its very nature. The codebase needs to be prepared to deliver value frequently and for long periods of time. This is where robust software engineering practices come into play. If you can’t painlessly deliver features quickly and without compromising quality, you need to re-evaluate techniques to make your code more maintainable.
Shift Errors Left
Type Annotationsによる型チェックは開発中やTypecheckerによる静的解析により、エラーの検知を早めにすることにつながる。
これにより品質を上げるだけでなく生産性もあげられる
The central theme of robust code is making it easier to detect errors. Errors are an inevitable part of developing complex systems; you can’t avoid them. By writing your own types, you create a vocabulary that makes it harder to introduce inconsistencies. Using type annotations provides you a safety net, letting you catch mistakes as you are developing. Both of these are examples of shifting errors left; instead of finding errors during testing (or worse, in production), you find them earlier, ideally as you develop code.
Future Proof
現在の実装がRobustであるかだけでなく、将来にあたってRobustなコードを保証するような仕組みになっているか(Future Proof)が重要であり、Type Annotationはその実現に大きな力を発揮する。
- Dictionaryからある要素がもし削除されると機能しなくなる関数があるなら、そういうケースが発生した場合に検知できる仕組みが欲しい
- 関数の返り値として新しい型がもし将来的に追加された場合、関数のCallerで適切にハンドリングできていないなら検知したい
その他
設計とType Annotationを組み合わせてRobustなソフトウェアを作る。
その上で、TestやStatic Analysis(Typechecker を含む)でセーフティネットを作って、バグが混在しないようにする。
2. ユースケース
定数の定義
Finalを定義して、値の変更ができないようにする。
値の制御
特定の値を使うことが決まっているなら、Literalを使う。
コレクションの定義
コードの堅牢さの指標
- 理解しやすさ
- テストしやすさ
- 依存関係の少なさ
- 機能の追加しやすさ
- 既存機能に影響する事なく(与える影響をできるだけ少なく)機能を追加できるか
- 機能追加の際にコードの修正が必要な箇所が少ない事、また必要な箇所がまとまっている事、修正を忘れたらそれに気づける事
- Future Proof
Introduction to Python Types
Typeとは
numbersやstringsといった具体的な型について言及せずにTypeとは何かどう説明すればいいだろうか。
ここではTypeは**コミュニケーションの手段(communication method)**と定義する。
具体的にはTypeは開発者やコンピュータが判断をするための情報を提供する。
以下2つに分解する。
- Mechanical Representation
- 振る舞いと制約を言語自体(コンピュータ)に伝える
- Semantic Representation
- 振る舞いと制約を開発者に伝える
Mechanical Representation
Semantic Representation
Types tell a user what behaviors they can expect when interacting with that entity. In this context, “behaviors” are the operations that you associate with that type (plus any preconditions or postconditions). They are the boundaries, constraints, and freedoms that a user interacts with whenever they use that type.
While an error won’t reach production, they are still expending time in looking through the code, which prevents value from being delivered as quickly.
The root cause is that the semantic representation was not clear for the parameter. As you write code, do what you can to express your intent through types. You can do it as a comment where needed, but I recommend using type annotations (supported in Python 3.5+) to explain parts of your code.
You are conveying semantic representation to future developers, without ever directly talking to them.
型の情報をコードに付け足すことで、どのような振る舞いを期待しているのかの情報を未来の開発者に伝えることができる。
Typing Systems
Strong versus Weak
Dynamic Versus Static
Python
PythonはStrongでDynamic
- 実行されるまで型はわからない
Type Annotations
前述の通りPythonはDynamicなので実行されるまで型はわからない。
Typeが値自体に埋め込まれているため、開発者は自分が今触っているのがどんな型なのか知るのが難しい。これはRobust Codeを書く上で障壁になる。
この障壁を取り除く上で重要なのがPython3.5から導入されたType Annotationの機能。
Type Annotationsとは
Type Annotationは以下のように変数に期待する型の情報を追加できる機能。
Type Annotationはtype hintsとして動作して開発者に型の情報についてのヒントを与えてくれるが、Pythonの実行時には使用されない。そのため、ヒントを完全に無視することもできる。
def close_kitchen_if_past_close(point_in_time: datetime.datetime):
...
PythonはType Annotationと異なる型を使用してもエラーを出さない。
These type annotations still serve a crucial purpose: informing your readers of the expected type. Maintainers of code will know what types they are allowed to use when changing your implementation.
Type Annotationがなかったら...
新しく入った職場で新しいコードの修正にとりかからないといけなくなって以下のコードを見た時、この関数がどんな型を受け取るのかを想像するか、実装を見るしか無い。
def schedule_restaurant_open(open_time, workers_needed):
実際のコードにType Annotationがあれば型の情報を知るために実装を見たり想像する必要がなくなる。
import datetime
import random
def schedule_restaurant_open(open_time: datetime.datetime,
workers_needed: int):
workers = find_workers_available_for_time(open_time)
※そもそもの話として、関数の命名が受け取る情報を正しく表していないという問題もある。(workers_neededがnumber_of_workersだったらより理解しやすいコードになる)
返り値にType Annotationをつける
返り値には->でType Annotationsをつけることができる。
def find_workers_available_for_time(open_time: datetime.datetime) -> list[str]:
変数自体にType Annotationsをつける
以下のように変数自体にType Annotationsをつけることもできる。
numbers: list[int] = []
num:int = 0
Type Annotationsの使い所
Type Annotationsの使い所については色々な考え方があると思うが、必ずしも全ての変数につける必要はない。
例えば以下のtextという変数にType Annotationをつけても何か開発者に追加で与えられる情報は何もない。
text: str = "意味がない"
開発者が一般的に想定するのと違う使い方をしている箇所などで使うと効果的だと考えられる。
Type Annotationのメリット
コードの意図を伝えられる
型情報について意図を伝えることでバグをなくしたり、コードの内容を理解するまでの時間を短くしたりできる。
Autocomplate
VSCodeなど一般的なコードエディターであれば、Type Annotationの情報を利用して対象の型で利用できるメソッドなどをAutocomplateしてくれ、開発速度の向上が期待できる。
Typechekers
バグを発見してくれる。
前述の通りPythonではType Annotationと異なる型を使用してもエラーは出さないので、Typecheckersを使うことで初めてセーフティネットとしての働きを持つことができる。(コミュニケーションの方法からセーフティネットに変換してくれる)
また、生産性の面でも、Runtimeで起きるエラーをBuild時(静的解析時)のエラーに変換してくれ、開発速度を向上させることができる。
PythonのTypecheckersとして最もポピュラーなのはmypy。
インストールをまず行う。
pip install mypy
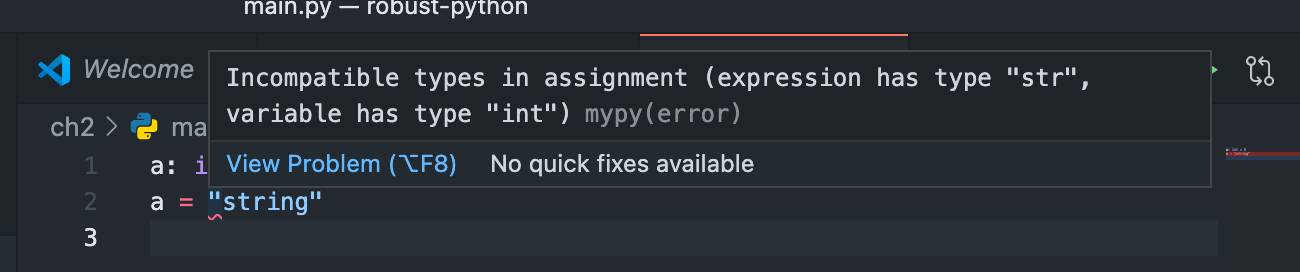
次に以下のように意図的にType Annotationと異なる型を使っているコードを作る。
a: int = 5
a = "string"
このファイルに対してmypyコマンドを実行すると以下のようにエラーを出してくれる。
% mypy main.py
main.py:2: error: Incompatible types in assignment (expression has type "str", variable has type "int")
Found 1 error in 1 file (checked 1 source file)
ローカルやCI/CDでmypyでのチェックを行うことで、意図しない型を使っている場合には問題に気づくことができる(セーフティネットとして働く)
また、VSCodeなどのエディタではmypyを自動で適用してくれる。
まとめ
- Type Annotationはコミュニケーションの手段として開発者の意図を正しく他者に伝え、コードの品質を高めるために利用できる
- それだけでなく、Type Checkersと組み合わせることでセーフティネットとしての働きを持つこともできる
Remember, in order for your code to be robust, it has to be easy to change, rewrite, and delete if needed. The typechecker can allow developers to do that with less trepidation.
企業でのType Annotationの活用
Google Python Style Guide - type-annotated-code
Googleでは型定義のチェックツール(静的解析ツール)としてpytypeの使用が推奨されている。
pytype:型ヒントなしでも使えるPython用静的型検証ツール - ぬいぐるみライフ?
Dropbox
Our journey to type checking 4 million lines of Python - Dropbox
Constraining Types
Optional Type
問題
Nullの参照は「billion-dollar mistake」としてプログラムにバグを発生させる可能性がある問題だが、PythonでもNoneの扱いで同様にバグが発生しやすくなっている。
例えばホットドッグをお客さんに提供するまでの流れをプログラムで表すとすると、以下のように簡単なコードで実現できる。
しかし、これはハッピーパスのみを考えたものであり、robust codeを考えるとエラーも考慮に入れなければならない。
def create_hot_dog():
bun = dispense_bun()
frank = dispense_frank()
hot_dog = bun.add_frank(frank)
ketchup = dispense_ketchup()
mustard = dispense_mustard()
hot_dog.add_condiments(ketchup, mustard)
dispense_hot_dog_to_customer(hot_dog)
例えば、お客さんが注文をキャンセルした、材料がないなどの問題が起こった時に各処理がNoneを返すとすると、プログラムはエラーで落ちてしまう。
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
AttributeError: 'NoneType' object has no attribute 'add_frank'
def create_hot_dog():
bun = dispense_bun()
if bun is None:
print_error_code("Bun unavailable. Check for bun")
return
frank = dispense_frank()
if frank is None:
print_error_code("Frank was not properly dispensed")
return
...
上記のようにすべての関数呼び出しでNoneが返されたかチェックしなければならなくなる。
すべての開発者がこの考慮を行ってくれるとは限らず、これは非常にエラーを招きやすい設計だと言える。
Optionalを使うメリット
1. 意図をより明確に伝えられる
2. 返り値の違いによって意図を伝えられる
3. Typecheckerによってエラーとして検知できる
このようなケースでもmypyを実行しておけばエラーを出してくれる。
def dispense_bun() -> Bun:
if not are_buns_available():
return None
return Bun('Wheat')
$ mypy optional.py
optional.py:16: error: Incompatible return value type (got "None", expected "Bun")
Found 1 error in 1 file (checked 1 source file)
これは返り値としてOptionalを指定すればエラーを回避できる。
このように返り値の型情報で明示的に伝えない限りはNoneを返さないという約束事を強制できる。
def dispense_bun() -> Optional[Bun]:
Union
複数の型を許容できる。
ユースケース
- ユーザのインプットなどによって返り値の型が変わる場合
- エラーハンドリングでエラーメッセージやエラーコードなど追加の情報を扱う時
- 後方互換性などで型の変更があったときに複数の型を返したい場合
メリット
- 複数の型が返されることを伝えることができる。関数の返り値でUnionにより複数の型が定義されている場合には、開発者はその関数を使うときに複数の型に対応しなければならないことを知れる。
実例
関数dispense_snackでユーザのインプットに応じてHotDogかPretzelという型を返す。
そのとき、この関数を呼び出すplace_orderという関数ではdispense_snackの返り値の型としてHotDogかNoneのどちらかのみを想定しているとする。(つまり、実際にはPretzelという型で返される可能性があるが、呼び出し側でその考慮ができていない状態)
def dispense_snack(user_input: str) -> Union[HotDog, Pretzel]:
# Hotdogを返すケース
if user_input == "Hot Dog":
return dispense_hot_dog()
# Pretzelを返すケース
elif user_input == "Pretzel":
return dispense_pretzel()
raise RuntimeError("Should never reach this code,"
"as an invalid input has been entered")
def place_order() -> Optional[HotDog]:
order = get_order()
# dispense_snacllを呼ぶ。返される値としてHotDogかNoneを想定する
result = dispense_snack(order.name)
if result is None:
print_error_code("An error occurred" + result)
return None
# Return our HotDog
return result
この状態でmypyのチェックをかけるとエラーが出てくれる。
% mypy union.py
union.py:40: error: Incompatible return value type (got "Union[HotDog, Pretzel]", expected "Optional[HotDog]")
Found 1 error in 1 file (checked 1 source file)
このように型の定義をしておくことで、今後関数側で返す型が増えたとしても、呼び出し側でその考慮ができていない場合にはエラーとして検知することができる。
これはFutur Proofな設計であり、今後もコードがRobustであり続けるための重要な要素だと言える。
Product and Sum Type
以下のdataclassがあるとして、それぞれ記載した通りの値を取りうると仮定すると取りうる値のパターンとして3 * 4 * 6 * 2 = 144通りが考えられる。こうした考え方をproduct typeと呼ぶ。
from dataclasses import dataclass
@dataclass
class Snack:
# 3つの選択肢があるとする
name: str
# 4つの組み合わせがあるとする
condiments: Set[str]
# 0から5の6つの選択肢があるとする
error_code: int
# TrueかFalseの2つの選択肢があるとする
disposed_of: bool
Snack("Hotdog", {"Mustard", "Ketchup"}, 5, False)
問題なのは、実際に取りうる値の組み合わせは決まっており、144通りもないということ。
例えば、disposed_ofがTrueになるのはerror_codeの値がゼロ以外の場合のみなど。
現実では開発者がこうした取りうる値を考慮して処理を書いていくが、これは極めて脆弱(robustではない状態)であり、また問題が起きたときに見つけるのに非常に時間がかかる。
classやdataclassなど状態を保持するオブジェクトで不正な(想定していない)状態を保持することを許容してしまうと、将来的に問題を招く可能性があり、またそうなったときに問題を検知するのが難しい。
そこで型の定義方法を変え、以下のようにする。
@dataclass
class Error:
error_code: int
disposed_of: bool
@dataclass
class Snack:
name: str
condiments: Set[str]
snack: Union[Snack, Error] = Snack("Hotdog", {"Mustard", "Ketchup"})
print(snack) # Snack(name='Hotdog', condiments={'Ketchup', 'Mustard'})
snack = Error(5, True)
print(snack) # Error(error_code=5, disposed_of=True)
このとき、snackの型はSnackまたはErrorのどちらかのみを取る。
そのため、取りうる値のパターンは12 + 10 = 22通りに限定できる。
Literal Type
Literalを使うことで各変数が取りうる値を指定できる。
from typing import Literal
@dataclass
class Error:
error_code: Literal[1,2,3,4,5]
disposed_of: bool
@dataclass
class Snack:
name: Literal["Pretzel", "Hot Dog", "Veggie Burger"]
condiments: Set[Literal["Mustard", "Ketchup"]]
# この3つはエラーになる
Error(0, False)
Snack("Invalid", Set())
Snack("Pretzel", {"Mustard", "Relish"})
# 以下の3つはLiteralの条件にしたがっているためエラーにならない
Snack("Pretzel", {"Mustard"})
Snack("Pretzel", {"Ketchup"})
Snack("Pretzel", {"Mustard", "Ketchup"})
mypyを実行するとLiteralで定義した組み合わせ以外を使用している場合にはエラーを出す
% mypy union.py
union.py:96: error: Argument 1 to "Error" has incompatible type "Literal[0]"; expected "Union[Literal[1], Literal[2], Literal[3], Literal[4], Literal[5]]"
union.py:97: error: Argument 1 to "Snack" has incompatible type "Literal['Invalid']"; expected "Union[Literal['Pretzel'], Literal['Hot Dog'], Literal['Veggie Burger']]"
union.py:98: error: Argument 2 to <set> has incompatible type "Literal['Relish']"; expected "Union[Literal['Mustard'], Literal['Ketchup']]"
Found 3 errors in 1 file (checked 1 source file)
Annotated Types
Literalは便利だが、全ての箇所で指定可能な値を一つづつ定義していくのは非常に労力がかかる。
こうしたケースに対応できるのがAnnotated Typesだが、残念ながらTypecheckとしては動作せず、コミュニケーションの方法(意図を伝える目的)としてしか現時点では利用できない。
x: Annotated[int, ValueRange(3,5)]
y: Annotated[str, MatchesRegex('[0-9]{4}')]
NewTypes
HotDogの事例でHotDogの状態として以下2つを区別できるようにしたいとする。
- お客さんに提供できる状態になったもの(
ReadyToServeHotDog) - まだお客さんに提供できる状態ではないもの(
HotDog)
後者のお客さんに提供できないものが、お客さんに渡されることがないようにしたいが、同じ型で定義した状態だと開発者が処理の流れを見て判断しないといけない(Future-Proofではない状態)。
この解決策として利用できるのがNewType
NewTypeとは
NewTypeはその名の通り既存の型を受け取って新しい型を定義するのに使える。
NewTypeで定義した方は既存の型のフィールドとメソッドを全て受け継ぐ。
コードで表すと以下のようになる。
from typing import NewType
class HotDog:
''' Used to represent an unservable hot dog'''
# ... snip hot dog class implementation ...
ReadyToServeHotDog = NewType("ReadyToServeHotDog", HotDog)
def dispense_to_customer(hot_dog: ReadyToServeHotDog):
# ...
NewTypeで重要なのはNewTypeで定義した型と既存の型は全く別のものであり、交換不能(not interchangeable)であること。
上記のコードで言えば、顧客にHotDogを定義する処理で受け取る型としてReadyToServeHotDogを指定しておけば、未完成の状態の型(HotDog)を渡してもエラーになる。
つまり、型を明示的に使い分けることで開発者に強制的に特定の型で渡すよう指定ができる。
また、一方向での型の変換を強調することも重要であり、型の変換を行う関数を定義することで型の変換はこの特別な関数でのみ実施することを伝えることもできる。
def prepare_for_serving(hot_dog: HotDog) -> ReadyToServeHotDog:
assert not hot_dog.is_plated(), "Hot dog should not already be plated"
hot_dog.put_on_plate()
hot_dog.add_napkins()
return ReadyToServeHotDog(hot_dog)
残念ながら、Pythonでは実際に型の変換をその関数でのみ実現できるよう強制する機能はないので、コメントなどで補う必要がある。
ユースケース
Final Type
Finalを指定することでその変数の値を変更できないようにできる。
from typing import Final
FINAL_VARIABLE: Final[str] = "Test"
print(FINAL_VARIABLE)
# Finalで定義した変数を変更
FINAL_VARIABLE = 'Test2'
print(FINAL_VARIABLE)
前述の通りType Hintとして動作するので問題なく動作するが、mypyでチェックを行うとエラーが発生する。
$ mypy final.py
final.py:7: error: Cannot assign to final name "FINAL_VARIABLE"
参考資料
Collection Types
List, Dictionary, SetなどのCollection TypeでどのようにRobustなコードを実現するか。
Annotating Collections
以下のように単純にType Annotationをつけただけだと色々と問題がある。
def create_author_count_mapping(cookbooks: list) -> dict:
counter = defaultdict(lambda: 0)
for book in cookbooks:
counter[book.author] += 1
return counter
- Collectionsの具体的な使い方について何も情報がない
- Collectionの中身がどのようなものかわからない。例えば、レビューしていても中身が分からないので、
book.authorというアクセスの仕方が正しいのかわからない
- Collectionの中身がどのようなものかわからない。例えば、レビューしていても中身が分からないので、
- Future-Proofではない
- 将来的にCollectionの中身の形式が変わった時、コードが壊れてしまう
単純な解決策として、[]を使ってCollectionの中身の型を指定することができる。
AuthorToCountMapping = dict[str, int]
def create_author_count_mapping(
cookbooks: list[Cookbook]
) -> AuthorToCountMapping:
...
また、前述の問題がすべて解決するわけではない。
Homogeneous VS Heteroreneous
Collectionのデータについて考える上ではHomogeneous collectionsとHeteroreneous collectionsの違いについて理解する必要がある。
- Homogeneous collections
- すべての値が同じ型を持つコレクション
- Heteroreneous collections
- 異なる型を持つ値が存在するコレクション
使い勝手の面からするとlists, set, dictionariesなどのコレクションはHomogeneous collectionsである方が良い。
Heteroreneous collectionsである場合にはユーザは特別な注意を払って取り扱う必要があると指し示すべき。
例としてこれまでに出てきた以下の関数を見てみると、recipeという引数でHeteroreneous Collectionsを受け取っていることがわかる。
- Collectionの中でそれぞれで型が異なる(
single typeではない)ので、値や順番を見て操作方法を変えないといけない() - Typecheckingが効かない(docstringは書いてあるが、docstring自体は正しいことを保証してくれない)
- 誤った使い方をするようにしてもそれに気付けない(Future-Proofではない)
def adjust_recipe(recipe, servings):
"""
Take a meal recipe and change the number of servings
:param recipe: A list, where the first element is the number of servings,
and the remainder of elements follow the (name, amount, unit)
format, such as ("flour", 1.5, "cup")
:param servings: the number of servings
:return list: a new list of ingredients, where the first element is the
number of servings
"""
...
# こんな形で呼び出す
adjust_recipe(("flour", 1.5, "cup"), 3)
上記のコードを直すとすれば以下のようにUnionを使うようにする。
そもそも引数の渡し方を変えたほうが良いが、どうしてもこのような形式で表さないといけない場合にはTypeでデータを表現してTypecheckerが使えるようにする。
Ingredient = tuple[str, int, str] # (name, quantity, units)
Recipe = list[Union[int, Ingredient]] # the list can be servings or ingredients
def adjust_recipe(recipe: Recipe, servings):
# ...
Heteroreneousなデータの表し方
- TupleはよくHeteroreneous Collectionのデータを表すのに使われるが、可読性やメンテナンス性の面で良くない
- Dictionaryでそのまま表すと制約がある
- そこでHeteroreneousなデータをDictionaryで表現したい場合にはTypedDictを使う
Typed Dict
HeterogeneousなデータをDictionaryに格納する場合に使える機能。
新しいコレクションの作成
既存のCollection Typeで表せない方がある場合にはgenericsの機能が使える。
受け取った型と同じ型を返り値に求める
class全体を定義する
その他のユースケース
既存の型の振る舞いを変える
ABCの活用
PythonのABCを型定義とともに使えるようにしたもの。
基本的な仕組みは同じだが、元となる定義が提供されており、それを継承して使う。
Q. 旧来のABCは使う必要がなくなった?
Typechecker
Typecheckerの設定
Typecheckerの厳格さ(どれぐらい厳しくチェックをするか)は設定で変えられる。
厳しくするほど厳格なドキュメントが残りバグも減ると考えられるが、その分だけ変更に時間がかかるようになる。
指定方法
設定は以下の3つの方法で指定できる。
- コマンドライン
- インライン
- 設定ファイル
設定
mypyコマンドを実行したカレントディレクトリのmypy.iniファイルを探しに行く。
(コマンドラインの--config-fileオプションで設定ファイルの場所を指定することもできる)
mypyファイルのサンプルは以下。
# Global options:
[mypy]
python_version = 3.9
warn_return_any = True
# Per-module options:
[mypy-mycode.foo.*]
disallow_untyped_defs = True
[mypy-mycode.bar]
warn_return_any = False
[mypy-somelibrary]
ignore_missing_imports = True
User-Defined Types
ListやDictなどのPythonであらかじめ定義された型ではなく、自らが型を定義することでドメイン知識をコードで表現することができる。
他の開発者がコードベースに関するメンタルモデルを構築する助けになる。
ドメイン知識を型で表現する
The most readable codebases are those that can be reasoned about, and it’s easiest to reason about the concepts that you encounter in your day to day. Newcomers to the codebase will already have a leg up if they are familiar with the core business concepts
User-Defined Types: Enum
PythonのENUM
-
Immutable
-
新しい値を追加しようとするとエラーになる
-
意図を明確に伝えられる
-
Typeで型を指定できる
User-Defined Types: Data Classes
まとめ
以下のようなメリットがあるため、Pythonのバージョン等の制約がなければ基本的にはnamedtupleやDictionary, TypedDictではなくData Classesを使ったほうが良い。
- 引数に対して明示的にType Annotationを行える
- Immutability, Comparability, Equalityのコントロールが行える
- Function(Method)を型の中で簡単に定義できる(振る舞いを追加できる)
ただし、Data Class内のmemberがそれぞれに独立しているという前提においてのみData Classは有効。特定のmemberの値によって他のmemberの設定値が決まってくる場合などでは、Data Classesは開発者が自由に値を変更可能なため不正な状態を作ってしまいかねない。
そうしたケースではClassesを活用する必要がある。
User-Defined Types: Classes
ClassはData Classes
DictionaryやData Classesにはできない、invariants(不変条件)を伝えられるという利点がある。
数学的な決まりやビジネスルールなどの変わることがない決まりや値のこと?
Classesの特色
Classを使うよりもData Classを使う方が簡単でBuilt-inのメソッドも活用できて良いように感じられる。
以下の例のようにインスタンス化もData Classの方が簡単にできる。
class Person:
name: str = ""
years_experience: int = 0
address: str = ""
john = Person()
john.name = "John"
print(john.name) # John
# john2 = Person("John", 3, "住所1-2-3") # TypeError: Person() takes no arguments
@dataclass
class Person2:
name: str = ""
years_experience: int = 0
address: str = ""
# 簡単に使える
tom = Person2("Tom", 2, "住所1-2-3")
print(tom) # Person2(name='Tom', years_experience=2, address='住所1-2-3')
print(tom.name) # Tom
しかし、まずインスタンス化について言えばclassの制約は意図されたものであり、Constructorを利用してしかできないようになっている。
そしてこの制約が前述のinvariants(不変条件)を伝えられるというClassの利点につながっている。
先ほどの例をConstructorを利用して定義すると以下のようになる。
今回の例のように簡単なものであればData Classを使った方が簡潔にかける。
class Person3:
def __init__(self, name: str, years_experience: int, address: str):
self.name = name
self.years_experience = years_experience
self.address = address
john3 = Person3("John", 3, "住所1-2-3")
Invariantsとは
対象のエンティティで永続的に変わらないもの(ビジネスルールなども含む)。
具体例
ピザ屋のシステムを作っていて、作るピザには以下のルールがあるとする。
- ソースはトッピングの上には載せられない
- トッピングはチーズの上にも下にも載せられる
- ピザにかけられるソースは一つだけ
- ピザの大きさは整数だけ
- ピザの大きさは15cmから30cmの間
Constructorを使って以下のように表現できる。
from pizza.sauces import is_sauce
class PizzaSpecification:
def __init__(self,
dough_radius_in_inches: int,
toppings: list[str]):
assert 6 <= dough_radius_in_inches <= 12, \
'Dough must be between 6 and 12 inches'
sauces = [t for t in toppings if is_sauce(t)]
assert len(sauces) < 2, \
'Can only have at most one sauce'
self.dough_radius_in_inches = dough_radius_in_inches
sauce = sauces[:1]
self.toppings = sauce + \
[t for t in toppings if not is_sauce(t)]
Avoiding Broken Invariants
- Exceptionをあげる
- Dataを整形し直す
Exceptionを出したくない時には
Classを作成する関数を作る(Factory Method)
使い所
- データに関してType Annotatiosでチェックできない制約はないか
- 相互に影響し合う項目はないか
- データに関して保証したいことはないか
上記の質問のどれかに当てはまったらInvariantsがあるということであり、Classを定義するべき。
Benefit
意図を正しく伝え、呼び出し側に不確かな解釈をさせないことでバグを少なくできる。
- DRY
Interfaces
Protocols
Duck TypingにTypecheckを適用できない。
この問題を解決するためにPython3.8で導入されたProtocolが使える。
Runtime Checking With pydantic
Type AnnotationとTypechecker等による解析で捕まえられるエラーは限られており、実行時にしかわからないものが沢山ある。
外部のデータ(DB、config file, ネットワークリクエスト等)を処理する時には、不正なデータが送られてくるリスクがある。
解決策としてValidation Logicを書くことが思い浮かぶが、Validation Logic(たくさんのIF分など)を沢山書くと逆に可読性を下げ、開発がしづらくなるという問題(ジレンマ)がある。
こうした問題を解決するためにpydanticというライブラリが活用できる。
pydantic
pydanticはRuntimeでのチェックを可能にしてくれる仕組み。
pydanticで型を定義することでValidation Logicを書かずにRuntimeのエラーをキャッチできる。
However, this is user-configurable data and I want errors to be caught as early as possible in runtime. You should prefer catching the errors at data injection over first use. After all, the first use of these values might not happen until you are in a separate system, decoupled from your parse logic.
TypedDictの利用
- TypedDictの初期化時に値の検証が出来ない
- TypedDictはmethodを持てない
- 形式の暗黙的な検証は行わない
Pydantic
Extensibility
Extensibility is the property of systems that allows new functionality to be added without modifying existing parts of your system
特に重要なのが頻繁に変更が入る可能性が高い部分をextensibleにすること。
Shotgun Surgey
一つの変更がいろいろな箇所に影響を及ぼす。
そもそも機能追加をするのに既存のコードを変更する必要があり、ミスをする可能性が高くなる。
Complexity
この事例は本来不要であるaccidental complexityが実装の仕方によって導入されてしまっている。
再設計
emailをパラメータとして入れたことから問題が発生している。
- 複数の関心事が含まれている
- 関心事を分離する
- 関数を肥大化させない
- 通知を送る処理を分離。通知の種類を追加する時には新しいclassを追加して、Unionで受けとる型として指定する
- Necessary Complexityは受け入れる(条件分岐が増えてもしょうがない点)
Open-Closed Principle
既存機能に与える影響をできるだけ少なくしながら機能追加ができる事が重要。
これはOpen-Closed Principleと呼ばれ、Extensibilityの鍵となる要素である。
The Open-Closed Principle (OCP) states that code should be open for extension and closed for modification. This is the heart of extensibility.
You’ve already been exposed to the OCP in this book. Duck typing (in Chapter 2), subtyping (in Chapter 12), and protocols (in Chapter 13) are all mechanisms that can help with the OCP. The common thread among all these mechanisms is that they allow you to program in a generic fashion. You no longer need to handle every special case directly where the functionality is used. Instead, you provide extension points for other developers to utilize, allowing them to inject their own functionality without modifying your code.
The OCP is the heart of extensibility. Keeping your code extensible will improve robustness. Developers can implement functionality with confidence; there is one place to make the change, and the rest of the codebase is all geared up to support the change. Less cognitive overhead and less code to change will lead to fewer errors.
OCPのデメリット
- リーダビリティが下がる
- 密結合になる
上記のデメリットもあり、適切な頻度で使う必要がある(頻度が低すぎると変更に時間がかかりすぎ、バグを生み出しやすくもなる)
Dependency
全く依存していないプログラムを作ることはできないが、依存関係を管理しないとすぐにスパゲッティコードになる。
Relationship
コードの再利用に恩恵を得るため依存関係を作る(他のFunctionを呼んだり、モジュールをimportしたり)
- コードの再利用によるメリット
- 時間の節約
- バグの減少(すでにテスト済みのコードなので)
- バグの発見しやすさ(色々な人が見ることになる)
- デメリット
- 密結合につながる(互換性のない形で変更が行われれば、コードの変更が合わせて必要になる)
Composability
Event-driven Architecture
- producersとconsumersを分ける事でお互いが疎結合になり、システムが柔軟になる
- event-driven systemを作る方法はいくつもあり、シンプルなObserver Patternもあれば、Message Brokerを導入したりreactiveにすることもある。
Pluggable Python
Safety Net
TestとStatic Analysisの組み合わせでセーフティネットを作る。
現在バグがなかったとしても、将来的にどのタイミングでバグが混在するかわからない。
そのため、ソフトウェア開発のライフサイクルとしてセーフティネットを作っておく必要がある。
Static Analysis
- Linting
- Complexity Checkers
Linting
Linterとはよくあるプログラミングのミスなどを検知してくれるもの。
Pythonで最もメジャーなツールとしてはPylintがある。
- Styleについて(PEP8)
- 使われないコードや変数
- docstringの有無
- アクセスに関する違反(private memberへのアクセスなど...)
Pylintを使ってみる
以下のコードがある
def findAuthor(name): # snake_caseじゃない
return name
def Add_authors_cookbooks(author_name: str, cookbooks: list[str] = []) -> bool:
author = find_author(author_name)
if author is None:
assert False, "Author does not exist"
else:
for cookbook in author.get_cookbooks():
cookbooks.append(cookbook)
return True
class sample: # 先頭が大文字じゃない
name = ''
pylintコマンドで指定すると以下の通りスタイルやdocstringの有無、一般的なプログラミングのエラーについて警告を出してくれる。
$ pylint ch20_static_analysis/pylint.py
************* Module pylint
ch20_static_analysis/pylint.py:1:0: C0114: Missing module docstring (missing-module-docstring)
ch20_static_analysis/pylint.py:1:0: C0103: Function name "findAuthor" doesn't conform to snake_case naming style (invalid-name)
ch20_static_analysis/pylint.py:1:0: C0116: Missing function or method docstring (missing-function-docstring)
ch20_static_analysis/pylint.py:4:0: W0102: Dangerous default value [] as argument (dangerous-default-value)
ch20_static_analysis/pylint.py:4:0: C0103: Function name "Add_authors_cookbooks" doesn't conform to snake_case naming style (invalid-name)
ch20_static_analysis/pylint.py:4:0: C0116: Missing function or method docstring (missing-function-docstring)
ch20_static_analysis/pylint.py:6:13: E0602: Undefined variable 'find_author' (undefined-variable)
ch20_static_analysis/pylint.py:14:0: C0103: Class name "sample" doesn't conform to PascalCase naming style (invalid-name)
ch20_static_analysis/pylint.py:14:0: C0115: Missing class docstring (missing-class-docstring)
ch20_static_analysis/pylint.py:14:0: R0903: Too few public methods (0/2) (too-few-public-methods)
W0102: Dangerous default value [] as argumentについて、詳細はmutable-default-arguments - The Hitchhiker's Guide to Python参照
オリジナルPluginの作成
Typechekers
mypy
Complexity Checkers
mccabe
Security Analysis
Leaking Secrets
AWSのアクセスキーなどの秘匿情報
ソフトウェアの脆弱性など
bandit
参考資料
Testing Strategy
テストは最も重要なセーフティネットの一つ。
難しいのはテストに使う時間を最適に配分する事。
テストケースが多すぎれば負担になる(開発スピードが落ちる)し、少なすぎればプロダクションに影響を与えてしまう(ビジネス価値を害ってしまう)。
テスト戦略の定義
テストを書く前にテスト戦略を考える。
- どのような種類のテストを書くか
- どのようにテストを書くか
- どの具体の時間をテストに使うか
テスト戦略を考える前に
テストとは?
テストは
However, a company that markets tools to other developers might have a completely different strategy. Developers at that company may choose to write tests to make sure they are not regressing any functionality so that the company does not lose customers (which would translate to a loss of profit). Each of these projects needs a different level of testing.
- エラーがあれば検知するため
- 自信を持ってコードをプロダクションに反映させるため
- システムに関する質問に応えるため
与える影響からテストを書くか判断する。
Once you’ve identified who receives the value of your system, you need to measure the impact when something goes wrong. For every test that is not run, you lose a chance to learn whether you are delivering value. What is the impact if that value is not delivered? For core business needs, the impact is pretty high. For features that lie outside of an end user’s critical path, the impact may be low. Know your impact, and weigh that against the cost of testing. If the impact’s cost is higher than the test, write the test.
Testing Pyramid
重要なのはコスパがいいものの数を増やすこと。
コミットの間に沢山テストができ、順調にっているというフィードバックが得られるといい。
Make tests fast so that developers run them multiple times between commits to verify that things are still working. Keep your less valuable, slower, or more costly tests for testing on each commit (or at least periodically
テストのコストを減らす
テストが増えてコストがかかりすぎると感じたら、コストを減らす方法を考える。
- initial cost
- running cost
- maintenance cost
Acceptance Testing
Unit TestやIntegration Test、UI Testは開発者が期待した通りに動作するかを検証するためのものであり、間違ったものを作ってしまう可能性を減らすことはできない。(ユーザが期待している通りに動くかを検証することは出来ない)
この課題を解決するのがAcceptance Testであり、Acceptance Testは正しいプロダクトを作っていることを確かめるためのもの。
Behavior-Driven Development
顧客が期待するものと実際のソフトウェアの振る舞いのミスマッチをどう防ぐか。
それを目的としてBehavior-Driven Developmentが作られた。
The Gherkin Language
コミュニケーションにフォーカス。
要件の仕様をGiven-When-Then(GWT)の形式で記載する。
Feature: Name of test suite
Scenario: A test case
Given some precondition
When I take some action
Then I expect this result
メリット
- 平易な文章で表現できる
- 共有知識を関係者間で持てる
- 要件がテスト可能になる
behave
behave というライブラリがPythonでBDDを実現する方法として提供されている。
基本的には以下のような構成を持ち、GWTフォーマットでの要件を保持するfeatureファイルと、テスト内容を記載するstepsファイルの2つでテストが構成される。
.
└── features
├── food.feature
└── steps
└── steps.py
Feature: Vegan-friendly menu
Scenario: Can substitute for vegan alternatives
Given an order containing a Cheeseburger with Fries
When I ask for vegan substitutions
Then I receive the meal with no animal products
class CheeseburgerWithFries():
def substitute_vegan_ingredients(self):
pass
def ingredients(self):
return []
def is_vegan(ingredient):
return True
class Meatloaf:
pass
from behave import given, when, then
@given("an order containing {dish_name}")
def setup_order(ctx, dish_name):
if dish_name == "a Cheeseburger with Fries":
ctx.dish = CheeseburgerWithFries()
elif dish_name == "Meatloaf":
ctx.dish = Meatloaf()
ctx.dish = Meatloaf()
@when("I ask for vegan substitutions")
def substitute_vegan(ctx):
if isinstance(ctx.dish, Meatloaf):
return
ctx.dish.substitute_vegan_ingredients()
@then("I receive the meal with no animal products")
def check_all_vegan(ctx):
if isinstance(ctx.dish, Meatloaf):
return
assert all(is_vegan(ing) for ing in ctx.dish.ingredients())
@then(u'Then a non-vegan-substitutable error shows up')
def step_impl(context):
pass
behaveの機能
パラメータ化
Table
正規表現によるマッチング
テストライフサイクル
タグの活用
Reportの作成
Property-Based Testing
Mutation Testing
The central theme of this book is that software will always change. You need to make it easy for your future collaborators to maintain your codebase in spite of this change. You need to write tests that catch not only errors in what you wrote, but errors other developers make as they change your code.
Shift Errors Left
SHIFT ERRORS LEFT
One of the common tenets of the DevOps mindset is to “shift your errors left.” I mentioned this when discussing types, but it applies to static analysis and tests as well. The idea is to think of your errors in terms of their cost. How expensive is it to fix an error? It depends on where you find that error. An error found in production by a customer is costly. Developers have to spend time away from their normal feature development, tech support and testers get involved, and there are risks when you have to do an emergency deployment.The earlier in the development cycle you are, the less expensive it is to address errors. If you can find errors during testing, you can avoid a slew of production costs. However, you want to find these issues even earlier, before they ever enter into the codebase. I talked at length in Part I about how typecheckers can shift those errors even further left, so that you find the errors right as you develop. It’s not just typecheckers that allow you to do this, but static analysis tools such as linters and complexity checkers as well.
These static analysis tools are your first line of defense against errors, even more so than tests. They aren’t a silver bullet (nothing is), but they are invaluable in finding problems early. Add them to your continuous integration pipeline and set them up as pre-commit hooks or server-side hooks in your version control system. Save yourself time and money and don’t let easy-to-detect errors ever enter your codebase.
Static Analysisについて
特定のエラーを防ぐには、色々なツールを組み合わせる必要がある。
Think about each tool as a piece of Swiss cheese.1 Each individual piece of Swiss cheese has holes of various widths or sizes, but when multiple pieces are stacked together, it is unlikely that there is an area where all holes align and you can see through the stack.
Likewise, each tool you use to build a safety net will miss certain errors. Typecheckers won’t catch common programming mistakes, linters won’t check security violations, security checkers won’t catch complex code, and so on. But when these tools are stacked together, it’s much less likely for a legitimate error to squeak by (and for those that do, that’s why you have tests). As Bruce MacLennan says, “Have a series of defenses so that if an error is not caught by one, it will probably be caught by another.”2