この記事は Panda株式会社 Advent Calendar 2023 18日目の記事です。
Panda株式会社は東京大学松尾研究室・香川高専発のスタートアップで、AR技術とAI技術を駆使したシステム開発と研究に取り組んでいます。
このアドベントカレンダーでは、スタートアップとしての知見、AI・AR技術、バックエンドなど、さまざまな領域の記事を公開していきます。
自己紹介
筑波大学修士1年の山浦です。普段はWeb3のベンチャー企業でエンジニアをしながらHCI系の研究室で力覚ディスプレイの研究をしています。Panda株式会社には、Webフロントエンド開発のお手伝いという形で関わらせていただいています。
この記事は、そのフロントエンド開発のお話です。
背景・課題意識
背景 ~高度なGUI操作を行うSPA開発~
今回、テキスト入力、クリック、ダブルクリック、ドラッグアンドドロップなどのGUI操作で構造データを作る、少々高度なSPAの制作を行いました。こういったSPAは複雑性が高いため、処理をどこで実行するかやソースファイル内のどこに書くかを丁寧に設計してから実装してあげないと、保守性が一気に落ちてしまい新規機能開発もままならなくなってしまいます。
これは一定程度成熟したプロダクトには必ず起こり得る問題でもあるので仕方ない面があり、テストを書いて適宜リファクタをかけてあげるのが一番多く採られている対処法かと思います。
しかし、一からプロダクトを作るとなれば話は別です。設計思想からディレクトリ構造まで、Layerd Architecture の考え方を導入してガチガチに縛ってあげれば、複雑な機能開発を高い保守性を維持したまま行えるのではないか?と思いついたのが始まりでした。
モダンフロントエンドのプログラミングパラダイム(手続型と宣言型)
昨今のフロントエンドは、Vue.js や React などで宣言的にコンポーネントを作成する書き方が主流です。これらの技術は、AjaxによるAPI callなどの非同期処理の実行が多いこともあり、「データとその状態によってViewが決まればUIの管理が楽になる」よね、という思想のもとに作られています。
これはほとんどのケースにおいて正しいですが、複雑な処理ステップを要求するUIデザインを実装する場合、その限りではありません。例えばアニメーションなどがこれに当たります。状態に対して処理を実行する宣言的なUIプログラミングは美しいですが、逐次的な処理を書くには全く適していないのです。
オブジェクト指向は素晴らしいですが、純粋な振る舞いを記述するだけではプログラムを動かすことはできません。マネージャクラスやタスクの実行を行うコントローラクラスはできるだけ避けるべきだと言われますが、どこかしらで必要な場面は出てきます。DDDで書くバックエンドだって、Domainを使用するusecase層と、それを呼び出すhandlerがあって初めて動作します。
こういった役割のプログラムは、同期処理をシーケンス図に書き起こしてある程度手続的に書いた方が明瞭で保守性が高まりますが、残念ながら現代のフロントエンド開発ではその手法があまり確立していません。(アニメーションを実装するめちゃくちゃ読みづらいソースコード、見たことありませんか?)
目的
今回の目的は、DDDをフロントエンドに導入することによる機能実装の速度と保守性の向上です。それを実現するために、シーケンス図を saga-task に書き起こすといったアプローチをとることで、設計から実装へのシームレスな移行を実現します。
事前知識と先行事例
(そもそも SPA ってなんぞや、という人は、本記事の対象読者ではないです🙇♂️)
この記事はソフトウェア設計の話ですが、今回は React を採用します。
Layerd Architecture って?
Layerd Architecher は、バックエンド開発で主に採用されている考え方です。詳しくはここらへんを読んでみてください。今回は Layerd Architechture + DDDの考え方を採用しました。
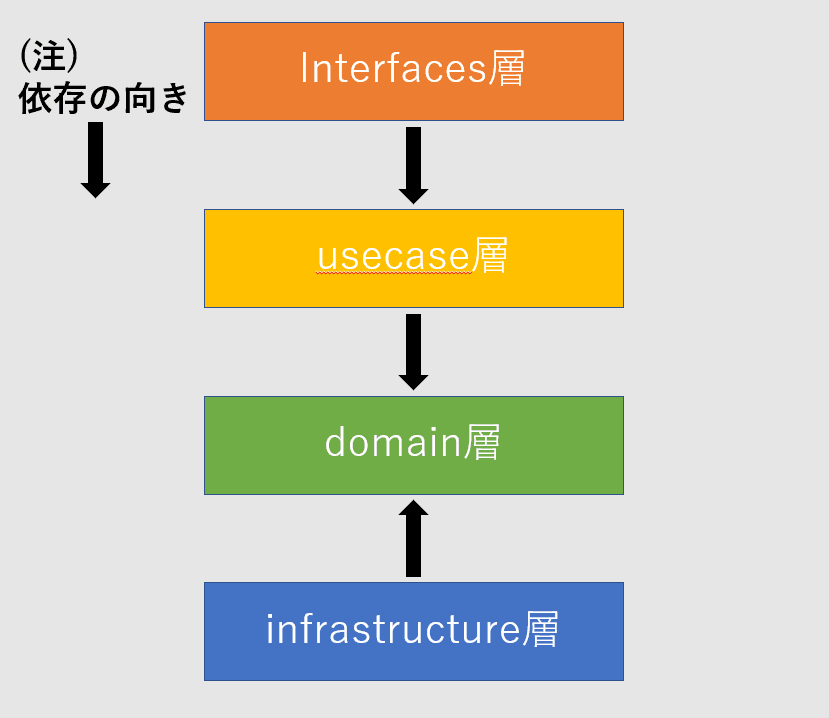
この絶対にパワポで作ったであろう画像が全てです。この図はプログラムの依存関係を表しています。まあ今回は難しいことは考えずに、import文の方向の縛り、ぐらいに捉えてくれればいいです。
なぜ DDD?
MVCだとよくおこる「このロジックはどこに書けばいいんだっけ...」という迷いが出ないので、プログラム設計がサクサクできる
これは先ほど挙げた2つ目の記事に書いてあるDDDのメリットその1です。DDDは主にバックエンド開発で用いられる考え方ですが、冒頭にも書いた通り私はSPA開発において全く同様の問題意識を以前から持っており、それを解決する可能性があると見て、今回の開発に取り入れました。逆に言えば、一般的なDDDで得られる他のメリットのことは今回考えていません。
DDD x Frontend
なんでも先駆者はいるものです。別にDDDはバックエンド限定の思想ではなですし、恐らく似たような問題意識のもとDDDに辿り着いたのでしょう。ただこの記事の内容では、ちょっとフロントエンドに取り入れるには全体として使い勝手が悪そうに見えます。
一方で、Entity周りの話は参考になります。JavaScript / TypeScript は class の扱いがそれほど得意ではないので、極力副作用のない純粋関数やプリミティブな値を扱っていこう、という方向性は正しいと感じます。私はこの記事の内容を読んで、もっとバリデーション等をdomain層で書きたいなと思いました。
こちらの記事では、かなり実践的にフロントエンドにDDDを導入しています(結構読みづらいですが)。一点、EventPubSubをdomain層に持っているのが引っかかりました。ここはViewから直接叩いてもいいんじゃないかな?
redux
redux って?という人は是非調べてください。
オーバースペック故に昨今不要論が唱えられがちな redux ですが、複雑なSPAを書く際にはまだまだ現役だと思います。というか、現状フロントエンドのデータ管理において redux を超えるプラクティスが存在しないです。
また、複雑性の高いSPAを書く際には正規化の考え方も重要です。ピンと来ない方は、下記の記事を読んでみてください。
要するに、フロントエンドのデータストアが redux で、正規化を考えて設計してあげればバックエンドの開発思想に近づくことができます。
redux-saga
詳細は後述しますが、今回はロジックの実装にredux-sagaを使用しました。API呼び出しに使うやつでしょ?と思われるかもしれませんが、本来はreduxでsaga-taskを実装するために作られたものです。知らない人はここら辺を読んでみてください。
設計
ここからは本記事独自の内容です。実際に DDD を使ってSPAを設計していきます。今回は例として、サークルのOBOGの職業リストを作成するようなアプリケーションにしてみました。
repository層(DDD x Redux)
参照するデータストアが redux に決まったところで、どう DDD を組み合わせるかです。
今回、アプリケーションにとって重要な構造データを保持する redux を完全にDBかのように扱うことにしました。DDD でいうところの infrastructure層に該当します。ただ実態としては redux-toolkit を使用して書くので、repository層も内包します。
domain層
domain層は、データオブジェクトとそこに関連するドメインロジックを定義してあげます。といっても、表示するデータの整合性を保つのに必要なロジックがメインになるかと思います。先ほど紹介した記事の内容のEntity周りの話を参考にしつつ、repository層のインタフェースも書きます。
export type Occupation = {
id: Id;
name: string;
};
export const NewOccupation = (name: string) => ({ id: NewId(), name });
type GetOccupation = (id: Id) => Occupation | null;
...
export type OccupationRepository = {
getOccupation: GetOccupation;
...
};
export type OccupationRepositoryForReducer = {
addOccupation: (state: State, action: { payload: Occupation; }) => void;
...
};
export type Person {
id: number;
age: number;
name: string;
occupationId?: Id;
}
export const NewPersonn = (age: number, name: string) => ({ id: NewId(), age, name });
export const isRetired = (p: Person) => !Boolean(p.occupationId) && p.age > 65;
export const isNeet = (p: Person) => !isRetired(p) && !Boolean(p.occupationId);
// ...other validations... ///
type GetPerson = (id: number) => Person | null;
type GetPersonsByAge = (id: age) => Person[];
...
export type PersonRepository = {
getPerson: GetPerson;
getPersonByAge: GetPersonByAge;
...
};
export type PersonRepositoryForReducer = {
addPerson: (state: State, action: { payload: Person; }) => void;
updatePerson: (state: State, action: { payload: Person }) => void;
removePerson: (state: State, action: { payload: Id }) => void;
...
};
repository層の実装
type State = {
occupations: Occupation[];
persons: Person[];
};
export type Reducer = OccupationRepositoryForReduce && PersonRepositoryForReducer && ...
const dataSlice = createSlice<State, Reducer>({
name: "data",
initialState: {
occupations: [],
persons: [],
},
reducers: {
...personRepositoryForReducer
...
},
});
export const DataAction = dataSlice.actions;
export default dataSlice.reducer;
redux-toolkit を使用する都合上、データストアを更新するPOST系のものと参照するGET系のもので別で定義してあげる必要があります。面倒なのでここでは詳細は省略しますが、適宜domain層のロジックを参照してあげると良いです。
ポイントは、GET系のものをusecase層からもpresentation層からも参照しやすい様にそれぞれラップしているところです。(usecacse層、presentation層の詳細は後述。)
export const personRepositoy = (state: State): PersonRepository => {
return {
getPeson: (id) => {
const page = state.pages.find((p) => p.id === id);
if (page === undefined) return null;
return { ...page };
},
...
};
};
// for usecase
export function* getPersonRepositoy(): Generator<object, PersonRepository> {
const { data } = yield* select();
return personRepositoy(data);
}
// for presentation
export const usePersonRepositoy = (): PersonRepository => {
const state = useSelector((s: RootState) => s.data);
const pr = useMemo(() => personRepositoy(state), [state]);
return pr;
};
const addPerson: PersonRepositoryForReducer["addPerson"] = (state, { payload }) => {
state.persons = [...state.persons, payload];
}
export const pageRepositoryForReducer = {
addPerson,
...
};
usecase層 と redux-saga
さて、infrastructure層とrepository層、domain層が決まったら、次に考えるのはusecase層とpresentation層です。バックエンド開発であれば、HTTPハンドラを用意して、requestを各usecaseに渡せばよいですが、フロントエンドはそうはいきません。
今回は、時系列的な操作を実行可能なUIを作る必要があったので、一連の機能をシーケンス図に書き起こし、それをusecase層として実装することにしました。
背景はこちらです。宣言的なコンポーネントに処理を乗せまくるのにはうんざりです。君はデータを適切に描画してさえくれればそれで良いんだよ、ということで、presentation層の債務も以下に決定しました。
presentation層が行うこと
- データの描画
- UserActionイベントの通知
この2つだけに絞ります。
データストア更新、API callといったその他の処理の一切をusecase層以下に委譲します。
さて、肝心の usecase層はどう書くのでしょうか。
シーケンス図を書いてその通りにデータ処理を行うわけですが、それを実現するのにredux-sagaを使用します。非同期処理を含む逐次的な処理を簡単に書ける上に、全ての action event を listen できるので、コンポーネントはデータの描画と user action の dispatch のみに集中できます。(呪文のように聞こえるかもしれませんが、頑張ってついてきてください🙇♂️)
これを考えついた際にシーケンス図を使ってredux-sagaを書く前例を調べたところ、この記事を見つけました。middleware でビジネスロジックを完結することを目指していて、似た様なことを考える人はどこにでもいるんだなあと再認識しました。
今回実際に書いたシーケンス図はこんな感じです。OccupationコンポーネントをドラッグしPersonコンポーネント上でドロップすることで、該当するPerson.occupationIdを更新します。
これを redux-saga で実際に書くとこのようになります。
const Events = {
dragStart: "DRAG_START",
drop: "DROP",
...
} as const;
export const DragStart = (id: Id) => ({
type: Events.dragStart,
payload: { id },
});
export const Drop = (id: Id) => ({
type: Events.drop,
payload: { id },
});
....
export type DragStart = ReturnType<typeof DragStart>;
export type Drop = ReturnType<typeof Drop>;
export function* setOccupation () {
while (1) {
const { id: oId } = yield* take<DragStart>(Events.dragStart);
const or = yield* getOccupationRepositoy();
const occupation = or.getOccupation(oId);
if (occupation === null) {
continue;
}
// dragEnter / dragLeave の処理は省略
const { id: pId } = yield* take<Drop>(Events.drop);
const pr = yield* getPersonRepositoy();
const person = or.getPerson(pId);
if (person === null) {
continue;
}
person.occupationId = oId;
yield* put(DataAction.updatePerson(person));
}
}
シーケンス図の一連の流れを、UserAction を受け取りながら進めていって適宜presentation層にフィードバックするイメージです。saga-task内で並列でUserActionを待てるため、同様に各機能ごとに個別にsaga-taskを書くことができます。
この書き方で書いている時は、redux-sagaのポテンシャルを引き出せている感覚がありかなり開発者体験が良かったです。実際、新たに機能実装する際は新しくsaga-taskを生やすだけで済むのでロジックの棲み分けができ、保守性が格段に上がりました。また実装はシーケンス図をsaga-taskに書き起こすだけなので、設計->実装の流れも非常にスムーズでした。
presentation層
最後に残ったpresentation層ですが、先ほど述べたように役割を以下の2つに絞ったため、何も特別なことはしません
- データの描画
- UserActionイベントの通知
1.は repository層で定義したuse<model>repositoryとprops.idなどからデータを取得していつも通りコンポーネントを書くだけです。2. はUserActionイベントの dispatch を行わないといけないため、そこはuseDragのようなcustom Hooksを書いて呼び出しましょう。
export const useDrag = (id: Id) => {
const dispatch = useDispatch();
const onDragStart = useCallback(() => {
dispatch(DragStart(id));
}, [id]);
... // dragEnter, dragLeave, etc...
return {
onDragStart,
...
};
};
const Occupation = ({ id: Id }) => {
const or = useOccupationRepository();
const occupation = or.getOccupation(id);
if (occupation === null) return <></>;
const { onDragStart } = useDrag(id);
return (
<Container onDragStart={onDragStart} draggable>
<p>{ occupation.name }</p>
</Container>
);
};
もちろんclick event なども全く同様に記述できます。Personコンポーネントも全く同様です。
以上で、機能実装の速度と保守性の向上を実現できました。
今後の課題
もちろん本手法にも課題や問題点はあります。備忘録も兼ねて思いつく限り列挙します。
-
開発チームに要求する知識レベルが高い。
今回はまず私1人での開発だったので、他のメンバーのスキルセットを考慮する必要がなかったため、このような設計思想を実装に落とし込むことができました。保守性の高いコードを書けたとは思っていますが、見慣れない人から見るとディレクトリ構成から通常のフロントエンドと結構異なるので、New Joinerに優しくないのはひとつ問題かと思います。また、redux-sagaの扱いも単純に難易度が高いです。今回は適切に処理の棲み分けをしているとはいえ、知らない人が初めて触ると簡単に無限ループを実装してしまうようなライブラリなので、使用歴が全くない人にとっては若干ハードかなと思います。 -
redux の action が追いづらい
今回は UserEvent を全て action に変換して redux に投げているので、logger を適切に設定してあげないとかなり読みにくいログが出来上がります。UserEvent の action は全部切ってしまえばいいじゃない、と言いたいところですが、問題の原因がそこに存在することもままあるので難しいところです。 -
無駄な処理を実行してしまうことがかなり多い
UIコンポーネントは基本的にロジックの呼び出ししか行わない、という設計や、ガチガチに型システムで縛った結果、かなり無駄なバリデーションや action の dispatch を各所で行なっています。UIコンポーネントをクライアント、redux-middleware をサーバに例えると、ほとんど404のリクエストをバンバン投げて、サーバはそれを高速で捌いているような状態です。ちょっとタチが悪いですね。これを避けるにはUIコンポーネントにロジックを委譲するのが最善手ですが、それは従来のSPA開発となんら変わりません。これは詰まるところ、コードの保守性・可読性とシステム最適化のトレードオフ問題であり、ソフトウェア開発における永遠の課題です。我々はその中で一番良い落とし所を見つける仕事を日々しているわけですが、今回のアプローチはかなりマシな方だと個人的に思います。 -
バックエンドの DDD と常に整合性を取れるわけではない
これはバックエンド開発でも DDD を導入している場合に起こりうるデメリットです。今回はDDDで得られるメリットのうち保守性や処理の棲み分けができることのみを考慮してフロントエンド設計を行いました。なのでユビキタス言語の文脈にある様なDDDのメリットはあまり考えていません。バックエンドのDDDはそうではないと思うので、当然モデルの振る舞いや記述内容に差が出てくることはあると思います。同じ名前のドメインモデルで振る舞いに差が出てくるとコミュニケーションコストが高まってしまう恐れがあり、必ずしも良いアプローチとは言えなくなってしまいます。もし逆になんらかの方法で内容を揃えて整合性を取ることができたならばこの上ないシステム開発ができるとは思いますが、バックエンドとフロントエンドではそもそもの役割が異なるため、そう簡単なことではないと思います。(ドメインエキスパートがいればなんとかなるのだろうか...?)
おわりに
今回は「SPA を DDD と redux-saga で書いてみたら実装・保守が楽になった」というテーマでPanda株式会社 Advent Calendar 2023 18日目を執筆させていただきました。
本記事では、Panda株式会社の実際のプロダクトで取り入れた新しい開発方法の紹介を行いました。複雑なGUI操作を行うSPA開発を行う際は、ぜひ参考にしてみてください。
明日は、雨海によるMixed Reality の定義とその変化 (A Texonomy of mixed reality visual displays)です。お楽しみに!

Discussion