
はじめに
AWS Summit Tokyo 2023 Day1 (4/20 (金)) に参加してきました!
「インシデントを起点に考える、システム運用のユースケースご紹介(AWS-04)」のセッションレポートを投稿します。
アーカイブ
以下にアーカイブがありますので、自由に視聴可能です。
セッション概要
インシデント対応、AWSリソース状況の把握、トラブルシューティング・・・。システム運用の仕事はつきません。そんなお仕事をAWSのサービスで楽にしましょう。このセッションでは、インシデント発生という激動の一日を追いながら、その対応やトラブルシューティングといった非日常の運用、またその備えのための日常運用を、マルチアカウント・マルチリージョンといった複雑な環境下において、AWS Systems Manager などの AWS のサービスを使って楽にする方法をご紹介します。
レポート
インシデント対応
-
全体像
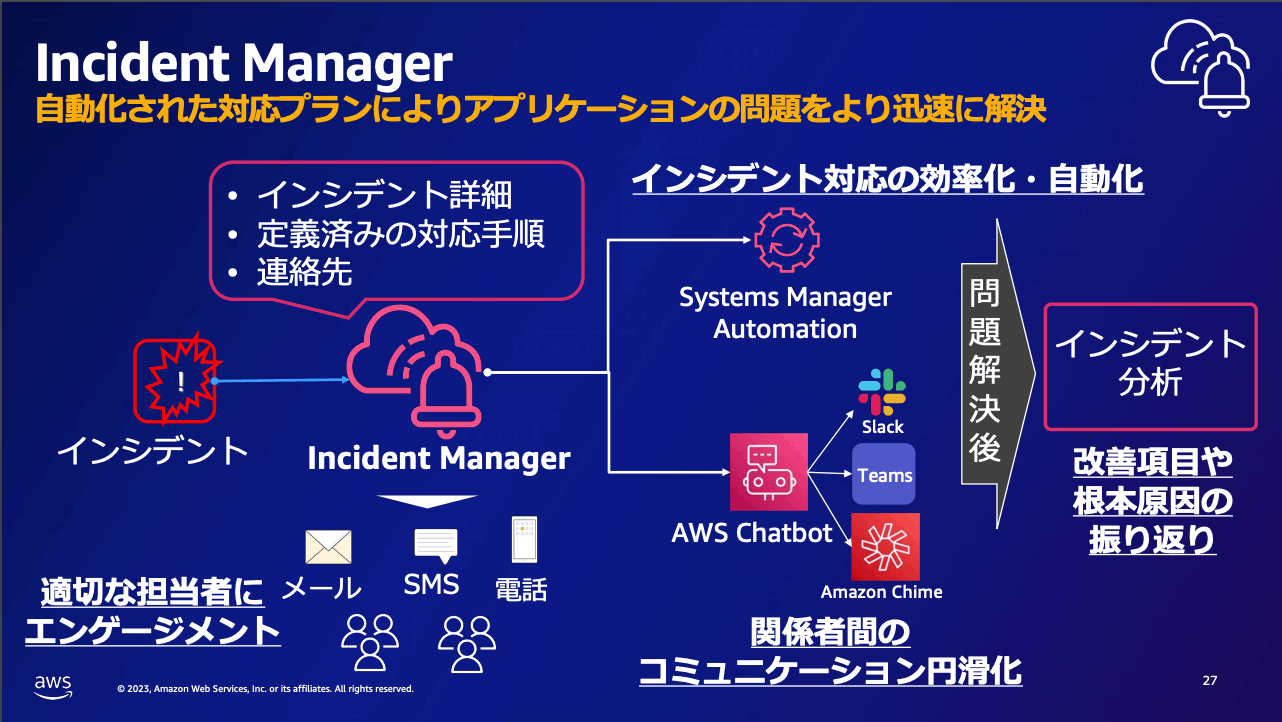
-
エスカレーション
- E メール、SMS、電話が選択可能
- エスカレーションフローを定義して、一定時間で応答がない場合は次の担当者に連絡するといった定義が可能
- 期間による担当者のローテーションを定義可能
-
対応 (トラブルシューティング)
- Runbook が用意されており、自動対応や手順の提示などが可能
- インシデント対応⽤の Runbook テンプレートが提供されている
- 影響判断
- 診断
- 緩和
- リカバリー
-
対応中の情報共有
- インシデントの更新はチャットチャネルに通知される
- slack、Teams、Amazon Chime が選択可能
-
問題解決後
- インシデントの分析を行い改善活動する (ポストモーテムが支援される)
トラブルシューティング
- 全体像
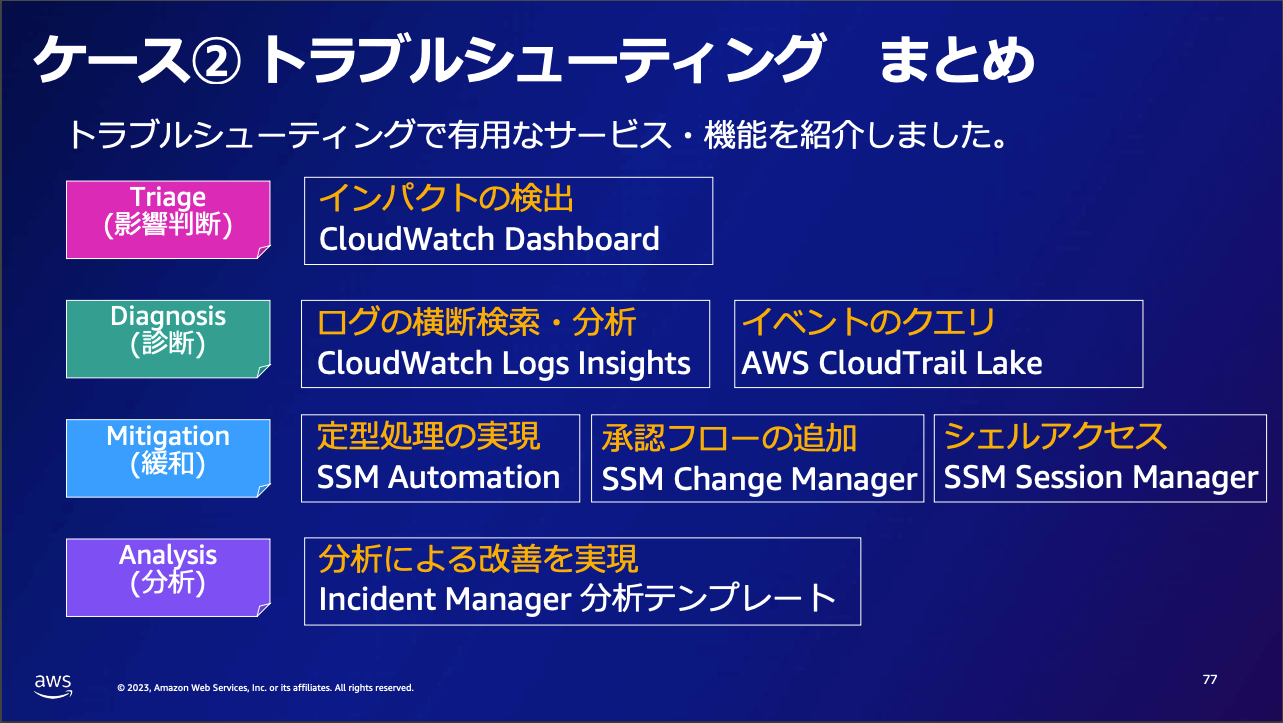
以下の記事に影響判断と診断についての詳細がわかるセッションのレポートもありますので合わせてご覧ください。
- 影響判断
- Amazon CloudWatch dashboards で全体の状況を俯瞰する
- よりエンドユーザー側の影響を確認するために
- CloudWatch Synthetics による統合監視
- CloudWatch RUM (Real User Monitoring) で実ユーザーの体験を分析
- CloudWatch Internet Monitor でインターネットからアクセスした際の可用性と性能を分析
- 診断
- CloudWatch Logs Insights でログの分析
- AWS CloudTrail による直前イベントの分析、AWS Config による構成変更履歴の分析
- AWS CloudTrail Lake で SQL ベースのクエリによる分析が可能 (Athena を使うより楽な可能性がある)
- 緩和
- テンプレートとして用意されている Runbook の活用
- AWSSupport-TroubleshootSSH (EC2 に SSH で接続できない場合のトラブルシューティングを⾏う。)
- AWSSupport-ResetAccess (EC2 で OS のパスワードや SSH キーを紛失した場合に再設定を⾏う。)
- AWSSupport-UpgradeWindowsDrivers (Windows の EC2 のドライバーをアップグレードする。)
- AWS-UpdateLinuxAmi(AWS-UpdateWindowsAmi) (最新のパッチを、Linux AMI (Windows AMI) に適⽤する。)
- AWSEC2-CloneInstanceAndUpgradeWindows (Windows Server のインプレースアップグレードを⾏う。)
- AWS Systems Manager Change Manager で分析に必要な一時的な対応を適切に管理できるようにしておく
- 一時的に特権アクセス許可をする承認付きワークフローを定義しておく
- AWS Systems Manager Session Manager で EC2 にログインして調査する
- テンプレートとして用意されている Runbook の活用
- リカバリ
- 影響判断や診断で利用した分析方法を再度活用して回復したことを確認する
- 分析
- 各対応時の改善ポイントや予防策を分析して次に活かす
- 検討する観点や質問などをテンプレートとしておくことができ、それに従って分析が可能
- デフォルトテンプレートの設問例
- 検知 検知時間を半分にするには?
- 診断 正しい連絡先に素早く連絡するには︖
- 緩和 Runbook の改善要素は︖
- 予防 「5つのなぜ」 - 問題の調査
普段の運用からやっておいて欲しいこと
- まず可視化 : AWS 全体
- AWS Systems Manager Explorer
- まず可視化 : 各サーバー
- AWS Systems Manager Inventory
- ベースラインの構築 : AWS 全体
- AWS Security Hub
- ベースラインの構築 : 各サーバー
- AWS Systems Manager Patch Manager
- 定型作業の⾃動化の整備
- Runbook の作成、更新
感想
インシデント対応は緩和とリカバリの部分も大変ですが、エスカレーションや情報共有、対応内容の記録なども合わせて行わないといけないのが難しいポイントだと感じています。自分の経験則的には実対応する人以外にそういった各所との連携などをする人を別に立てるべきだと考えているのですが、AWS Systems Manager Incident Manager はその人の代わりを担ってくれそうで良さそうに感じました。
また、サービスの復旧とは別にユーザー周知なども適切にかつ早急に行われるべきですが、そう言った部分も Runbook に記録しておくことでオペレーションミス少なくスピーディにできそうだなと感じました。
なにより、組織内でのインシデント対応というのは経験を蓄積しながら育てていくものだと考えているのが、このサービスを利用することでうまく回りそうだなという点に期待が持てました。

Discussion