Rで日本語テキストをいい感じに折り返す方法
この記事で説明すること
この記事では、Rで長めの日本語テキストの「いい感じの位置」に改行を入れて折り返す方法を紹介する。
次にあげるブログ記事が見つかるように、まれにこういった需要があるらしいのだが、これは日本語などスペースによって単語が区切られていない言語に特有の問題のように思われているため、インターネットで調べても有用な情報にアクセスしづらい。あと、この手の情報はR言語に関連する知識とはほぼ関係ないので、そもそも知っている人がいなさそう。
- ggplotのfacet日本語テキストを折り返す - まずは蝋の翼から。
- gtパッケージの表を便利にするための小技 - 戯言日記
- nonentity data scientist - QuartoのReveal.js上でBudouXを利用できる拡張機能を作ってみた
ggplot2のグラフなどで日本語テキストを折り返す
とりあえず、適当な日本語文字列を含むデータを用意する。audubon::polanoは、宮沢賢治の「ポラーノの広場」という小説を段落ごとに一つの要素とした文字列ベクトル。ここでは、そのうち3つの要素だけをtidytext::unnest_tokens()で適当に分かち書きして、dplyr::count()で段落内での単語(のようなもの)の出現頻度の列をつくっている。
dat <-
tibble::tibble(
doc_id = 4:6,
text = audubon::polano[doc_id]
) |>
tidytext::unnest_tokens(token, text, drop = FALSE) |>
dplyr::count(text, token, name = "freq")
dat
#> # A tibble: 156 × 3
#> text token freq
#> <chr> <chr> <int>
#> 1 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 ころ 1
#> 2 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 した 1
#> 3 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 その 1
#> 4 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 て 1
#> 5 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 に 1
#> 6 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 の 1
#> 7 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 は 1
#> 8 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 ま 1
#> 9 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 り 1
#> 10 そのころわたくしは、モリーオ市の博物局に勤めて居りました。 わたくし 1
#> # ℹ 146 more rows
このデータについて、とくに意味のあるグラフではないが、次のようにtext列でfacetして散布図を描く。すると、長いテキストについては一部が見きれてしまう。
library(ggplot2)
dat |>
ggplot(aes(x = token, y = freq)) +
geom_jitter(show.legend = FALSE) +
facet_wrap(~ text) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
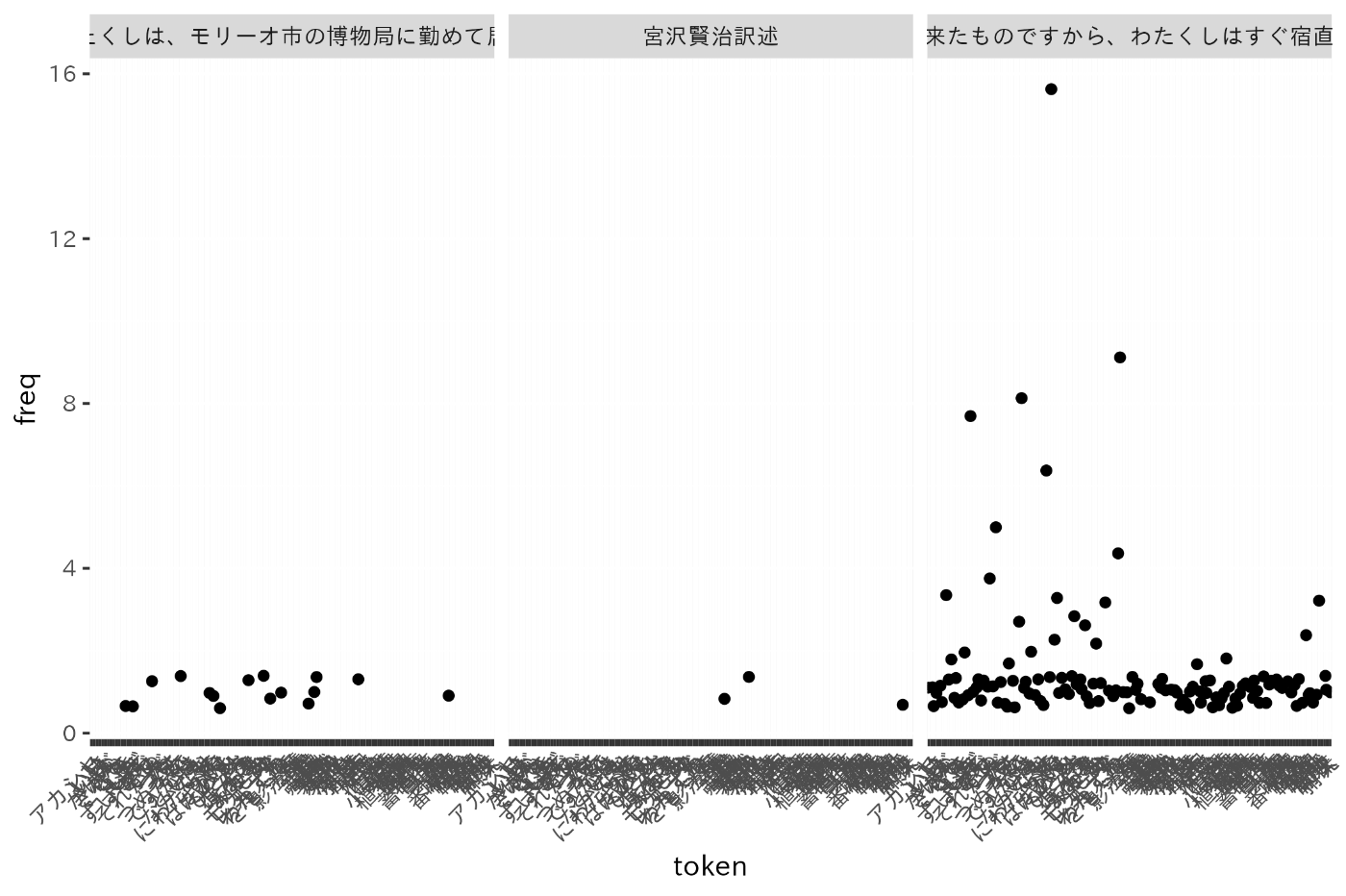
ここで、次のことを実現したいとする(X軸の軸ラベルもなかなか見栄えが悪いが、それはここでは無視する)。
- こうした見きれている日本語テキストに「いい感じの位置」で改行を挿入して、折り返す
- そもそも長すぎる文字列については、適当な字数で切り詰めてしまって、すべては表示しない
これを実現するためには、たとえば次のような関数を用意すればよい。
consective_id_by_cumsum <- \(x, threshold) {
id <- 1L
cum_sum <- 0
idx <- integer(0)
for (i in seq_along(x)) {
cum_sum <- cum_sum + x[i]
idx <- c(idx, id)
if (cum_sum >= threshold) {
id <- id + 1
cum_sum <- 0
}
}
idx
}
split_label <- \(x, wrap = 16, trunc = 50, collapse = "\n") {
pos <-
stringi::stri_locate_all_boundaries(
x,
opts_brkiter = stringi::stri_opts_brkiter(locale = "ja@lw=phrase;ld=auto")
) |>
purrr::map(\(.x) {
ret <-
as.data.frame(.x) |>
dplyr::mutate(
nchar = end - start + 1,
id = consective_id_by_cumsum(nchar, wrap)
)
split(ret, ret[["id"]])
})
purrr::imap_chr(pos, \(ids, i) {
purrr::map_chr(ids, ~ {
stringi::stri_sub(
x[i],
from = head(., n = 1)[["start"]],
to = tail(., n = 1)[["end"]]
)
}) |>
paste0(collapse = collapse) |>
stringr::str_trunc(width = trunc)
})
}
facet_splitter <- \(x, wrap = 16, trunc = 50, collapse = "\n") {
dplyr::mutate(
x,
across(where(is.character), ~ split_label(., wrap, trunc, collapse))
)
}
記事を投稿したときに書いたコード
この下のコードだと文節区切り内であってもふつうに改行されることがあるため、上のコードに差し替えた。
strj_segment <- \(x, engine = c("icu", "budoux")) {
engine <- match.arg(engine, choices = c("icu", "budoux"))
if (engine == "budoux") {
audubon::strj_segment(x)
} else {
stringi::stri_split_boundaries(
x,
opts_brkiter = stringi::stri_opts_brkiter(locale = "ja@lw=phrase;ld=auto")
)
}
}
facet_splitter <- \(x, wrap = 21, trunc = 50, temp_char = "\u200b", collapse = "\n") {
reg_pat <- paste0("(.{1,", wrap, "})")
dplyr::mutate(
x,
across(where(is.character),
~ strj_segment(.) |>
purrr::map_chr(\(.x) paste0(.x, collapse = temp_char)) |>
stringr::str_extract_all(reg_pat) |>
purrr::map_chr(\(.x) stringr::str_remove_all(.x, temp_char) |> paste0(collapse = collapse)) |>
stringr::str_trunc(trunc))
)
}
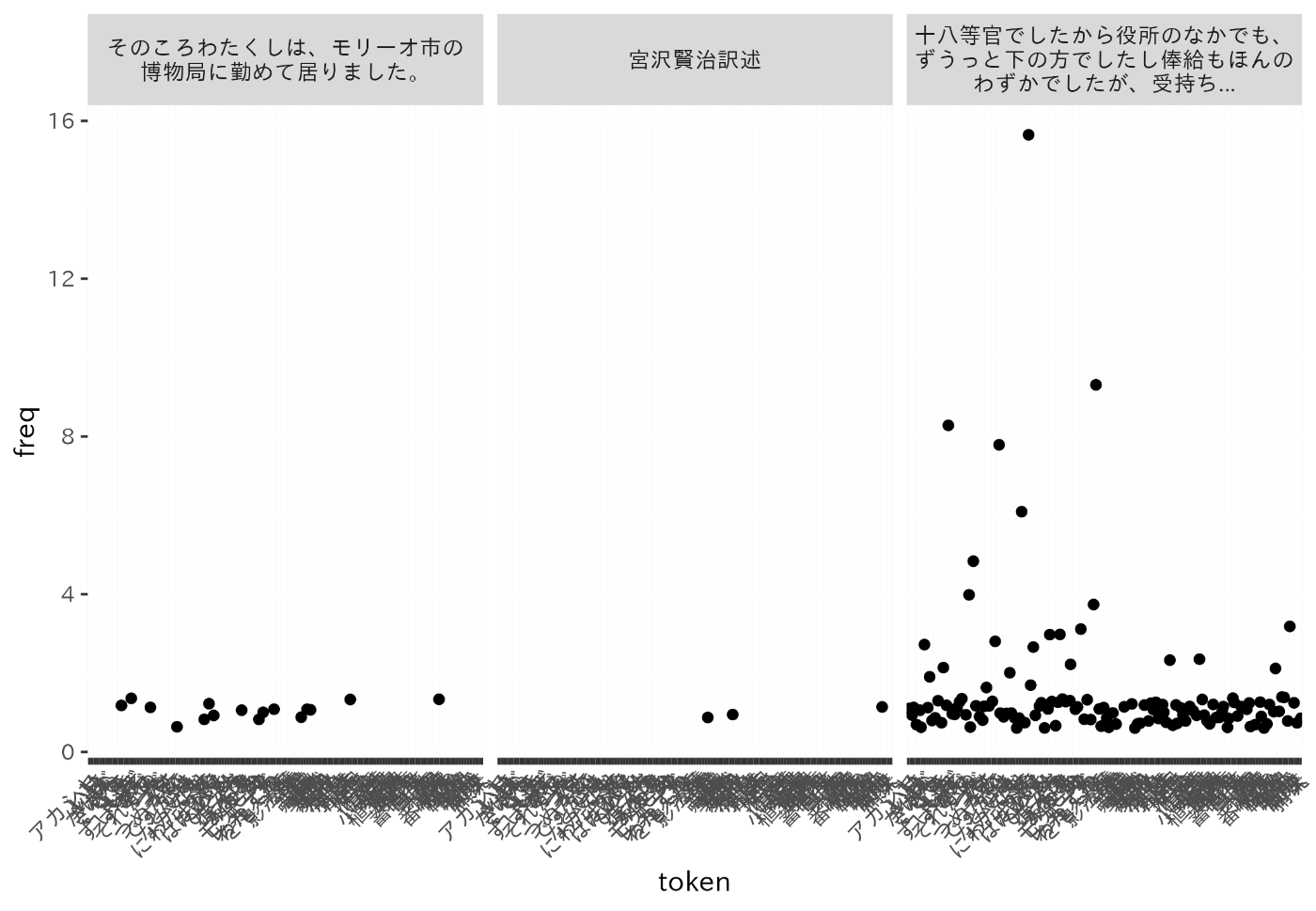
この関数を下のコードブロックと同様にして使った場合、次のようなプロットになる。
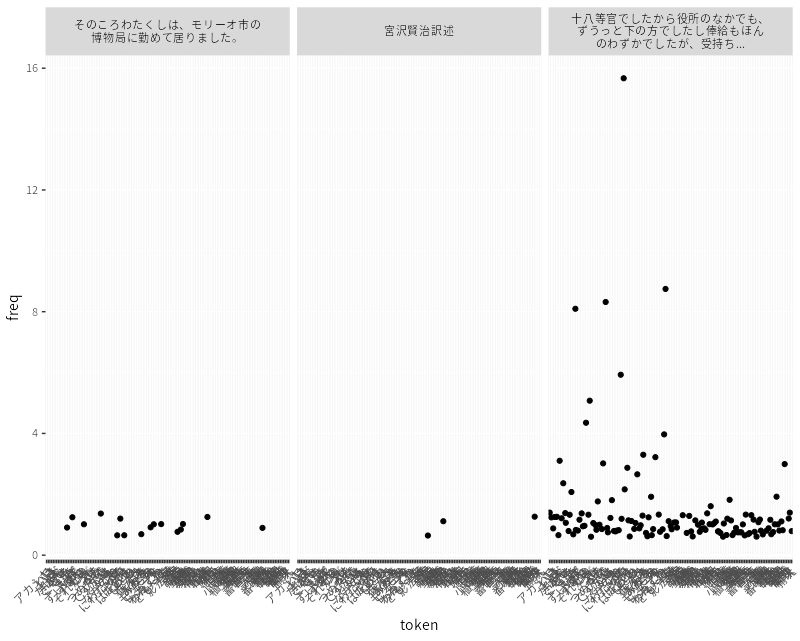
facet_splitterをggplot2::facet_wrap()のlabeller引数に渡すと、おおむね期待したような挙動をするはず。
dat |>
ggplot(aes(x = token, y = freq)) +
geom_jitter(show.legend = FALSE) +
facet_wrap(~ text, labeller = facet_splitter) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
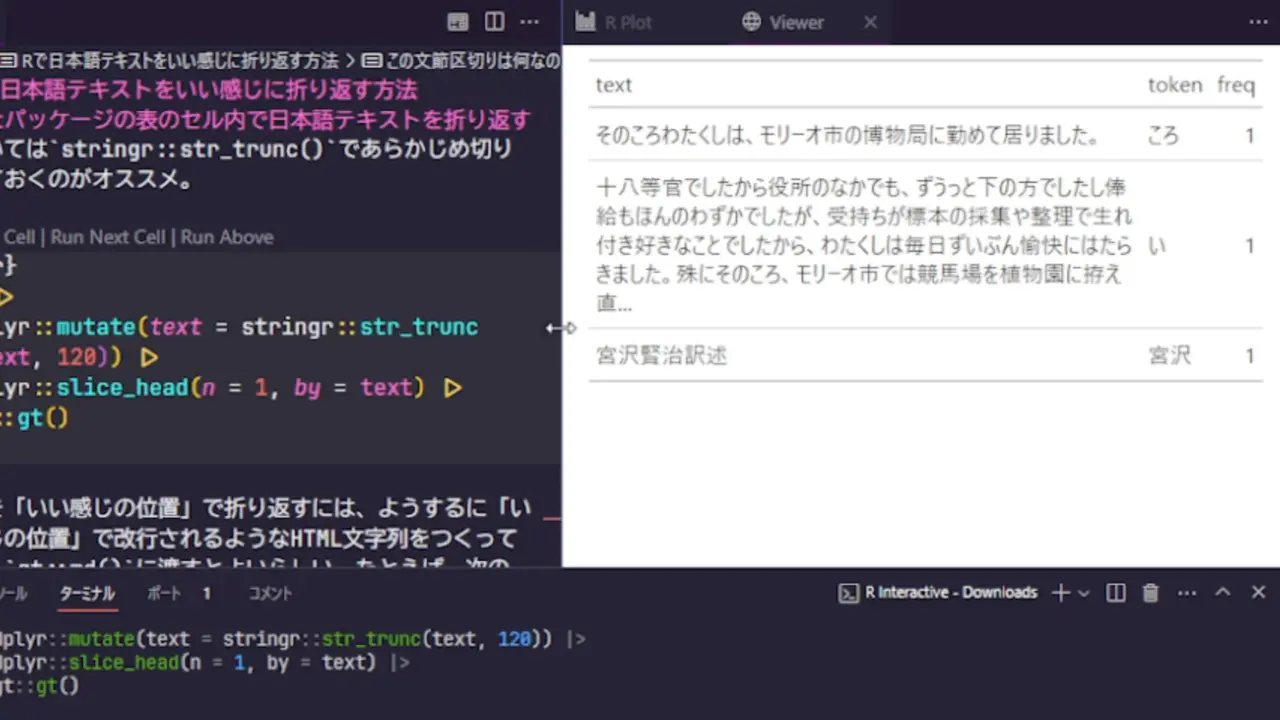
gtパッケージの表のセル内で日本語テキストを折り返す
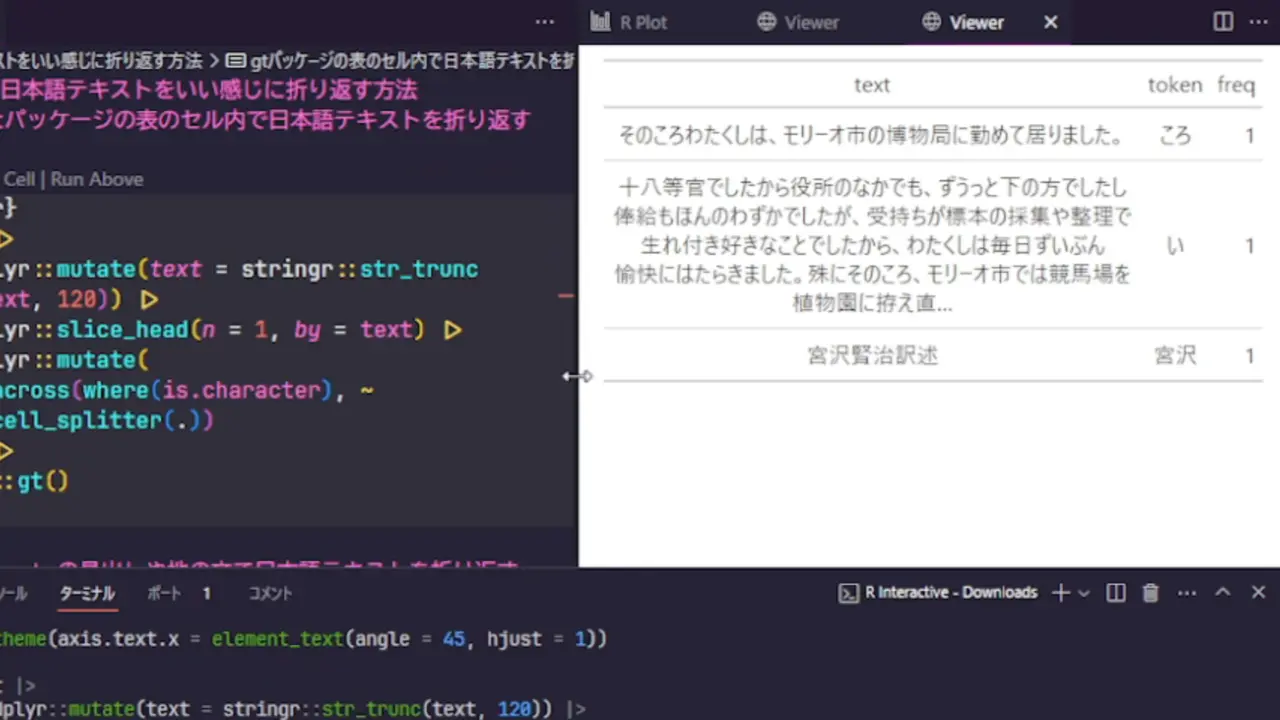
そういう需要もあるらしい。まずそもそも長すぎるテキストについてはstringr::str_trunc()であらかじめ切り詰めておくのがオススメ。
dat |>
dplyr::mutate(text = stringr::str_trunc(text, 120)) |>
dplyr::slice_head(n = 1, by = text) |>
gt::gt()
これを「いい感じの位置」で折り返すには、ようするに「いい感じの位置」で改行されるようなHTML文字列をつくってから、gt::md()に渡すとよいらしい。たとえば、次のような関数を用意するとよい。
strj_segment <- \(x, engine = c("icu", "budoux")) {
engine <- match.arg(engine, choices = c("icu", "budoux"))
if (engine == "budoux") {
audubon::strj_segment(x)
} else {
stringi::stri_split_boundaries(
x,
opts_brkiter = stringi::stri_opts_brkiter(locale = "ja@lw=phrase;ld=auto")
)
}
}
cell_splitter <- \(x) {
strj_segment(x) |>
purrr::map(~
paste0(
'<span style="word-break: keep-all; overflow-wrap: anywhere;">',
paste0(., collapse = "<wbr />"),
"</span>",
collapse = ""
)
) |>
purrr::map(gt::md)
}
これを次のように使うと、たぶん「いい感じの位置」で改行されるようになる。なお、この方法では「いい感じの位置」をすべてspanタグでくくりながら保持しているので、HTMLウィジェットとして表示している場合、表の表示幅にあわせて折り返し位置も変化する。
dat |>
dplyr::mutate(text = stringr::str_trunc(text, 120)) |>
dplyr::slice_head(n = 1, by = text) |>
dplyr::mutate(
across(where(is.character), ~ cell_splitter(.))
) |>
gt::gt()
Quartoの見出しや地の文で日本語テキストを折り返す
ここでは、HTMLとしてレンダリングする場合を想定している。Word文書やLaTeXとして出力する場合にどうすればよいのかはよくわからないが、それはどちらかというと最初に紹介した改行を挿入するケースが参考になるのではないかと思う。
HTMLとしてレンダリングする場合、冒頭に貼った「nonentity data scientist - QuartoのReveal.js上でBudouXを利用できる拡張機能を作ってみた」で紹介されている拡張機能を使えば、JavaScriptで「いい感じの位置」に区切りを挿入することができる。
あるいは、古いブラウザでの表示に対応する必要がない場合、最近のブラウザではCSSだけでも同じような位置で自動的に改行されるようにすることができる。たとえば、Quarto(Presentations)のタイトルスライド要素(#title-slide)内においてこのような区切り位置で改行されるようにしたい場合、YAMLフロントマターでlang: jaを指定したうえで、次のようなスタイルを書いたSCSSファイルをincludeするとよい。
/*-- scss:rules --*/
#title-slide {
word-boundary-detection: auto(ja);
word-break: auto-phrase;
}
CSSやSCSSをincludeする方法については、出力フォーマットによっていくつかの方法があるようなので、ここでは紹介しない。詳しくはQuartoのドキュメントを読んでもらいたい。
注意点として、word-break: auto-phrase;はこの記事を書いている2024年3月の時点でSafariやFirefoxではサポートされていない。このCSSプロパティのサポート状況については次のページなどで確認できる。サポートされていないブラウザで同じような表示をしたい場合には、拡張機能を使ったほうがよい。
この文節区切りは何なのかという技術的な話
この記事で紹介したような「長めの日本語テキストの「いい感じの位置」に改行を入れて折り返す」という課題は、Web技術の界隈で「日本語改行問題」としてしばしば言及されるもの。これをいい感じに実現するマークアップの方法については、簡単にググると次のような記事がヒットする。
この記事でも紹介されているように、「いい感じの位置」に区切りを与えるタスクそれ自体については、BudouXというJavaScriptライブラリが開発されていて、これで解決できる。READMEの説明によると、このライブラリでは、AdaBoostを用いて各々の文字境界について区切り位置にあたるかを2値分類するように学習したモデルを利用しているらしい。
このBudouXをもとにしている実装が、実はICUに取り入れられていて、ICU 73.2からすでに利用できるようになっている。その経緯については、次のWebページでなんとなくうかがい知ることができる。
この日本語テキストに文節区切りを与える機能は、どうやらChromiumベースのブラウザにおいて、先ほど書いたようなCSSプロパティを使ってこれを利用できるようにすることを念頭に取り入れられたものらしい。
R言語の文脈でいうと、BudouXについては従来から、筆者が開発しているRパッケージaudubonのaudubon::strj_segment()という関数を使って、V8経由でJSスクリプトを呼ぶことで利用することができた。一方で、同じことを実現する機能がICU4Cにすでに取り入れられているため、この記事ですでに見たように、stringi::stri_split_boundaries()を使っても、同様の文節区切りを与えることができるようになった。
ただし、ICU 73.2というのは比較的新しいバージョンであるため、stringiをビルドするときにリンクされたICU4Cのバージョンによっては、この機能が使えず、期待したような出力が得られない可能性がある。その場合には、stringi 1.8.1のソースパッケージにはすでにICU 74.1がバンドルされているため、以下のページで案内されている方法にしたがって、バンドルされているICU4Cを使ってビルドされるように設定するとよい。
Discussion
consective_id_by_cumsumはもっとRっぽい書き方ができないかと思って、r-wakalangで質問したところ、次のように書くことができそうだとわかりました。purrr::accumulate()のなかでdplyr::if_else()しているのが賢いですね。また、たぶんfor文で書くよりも処理が速いと思います。