短歌時評のテキスト解析


この記事について
以下の二誌のサイトから、2020年5月21日現在においてネットに公開済みの時評を収集し、テキスト解析したものです。
なお、本記事の筆者は所属としては無所属であり、いずれの短歌会の会員でもありません。本記事は個人的な関心からできる範囲で短歌時評のテキスト解析を試みたものであり、分析の対象として『未来』と『塔』の両誌の時評を選定した特別な理由はありません。
分析に使用したRのソースコードは、以下の外部記事から一部を参照することができます(ソースコードはMITライセンスで公開しています)。ソースコードを実行できる環境を準備し、同じコードを実行することで、本記事で掲載しているのとほぼ同じ図表などを作成することができますが、実行する時期などによって必ずしも再現性はありません。
分析の狙い
-
時評を掲載誌でグルーピングして分析し、それぞれの雑誌の時評について特徴的な語彙を確認します。
-
LDA(Latent Dirichlet Allocation)によってトピック・モデリングをおこない、短歌時評がどのような話題を扱っているかを概観します。
-
単語埋め込み(GloVe)によって、どのような語彙同士が近い文脈のなかで用いられているかを概観します。
分析の対象・前処理
上記のサイトから2020年5月21日現在で収集できる時評を分析の対象としました。具体的には、『未来』誌から2014年2月号掲載分から2020年5月号掲載分までのものを、『塔』誌から2009年5月号掲載分から2020年4月号掲載分までのものを収集しています。収集された時評は『未来』から60本と『塔』から132本で、あわせて192本でした。
これらの時評の記事本文について句読点などの記号類を削除するといった正規化をおこない、atilika/kuromoji(IPA辞書)で形態素解析して表層形の分かち書きに加工したものを分析しています。
特徴的な語彙
はじめに、両誌の時評でよく使われている語をワードクラウドで見てみます。

『未来』よりも『塔』のほうが掲載されている時評の時期の範囲が広く、『塔』からの分析対象には東日本大震災前後の時評も含まれているためか、『塔』でよく使われている語彙として「震災」や「被災」といった語彙が目にとまります。『未来』でよく使われている語彙のなかで目立っている「〇」という記号は、漢数字の縦書きで用いられるゼロにあたる字です。
次に、keynessという指標にもとづいて、それぞれの誌面において特徴的な語彙を見てみます。
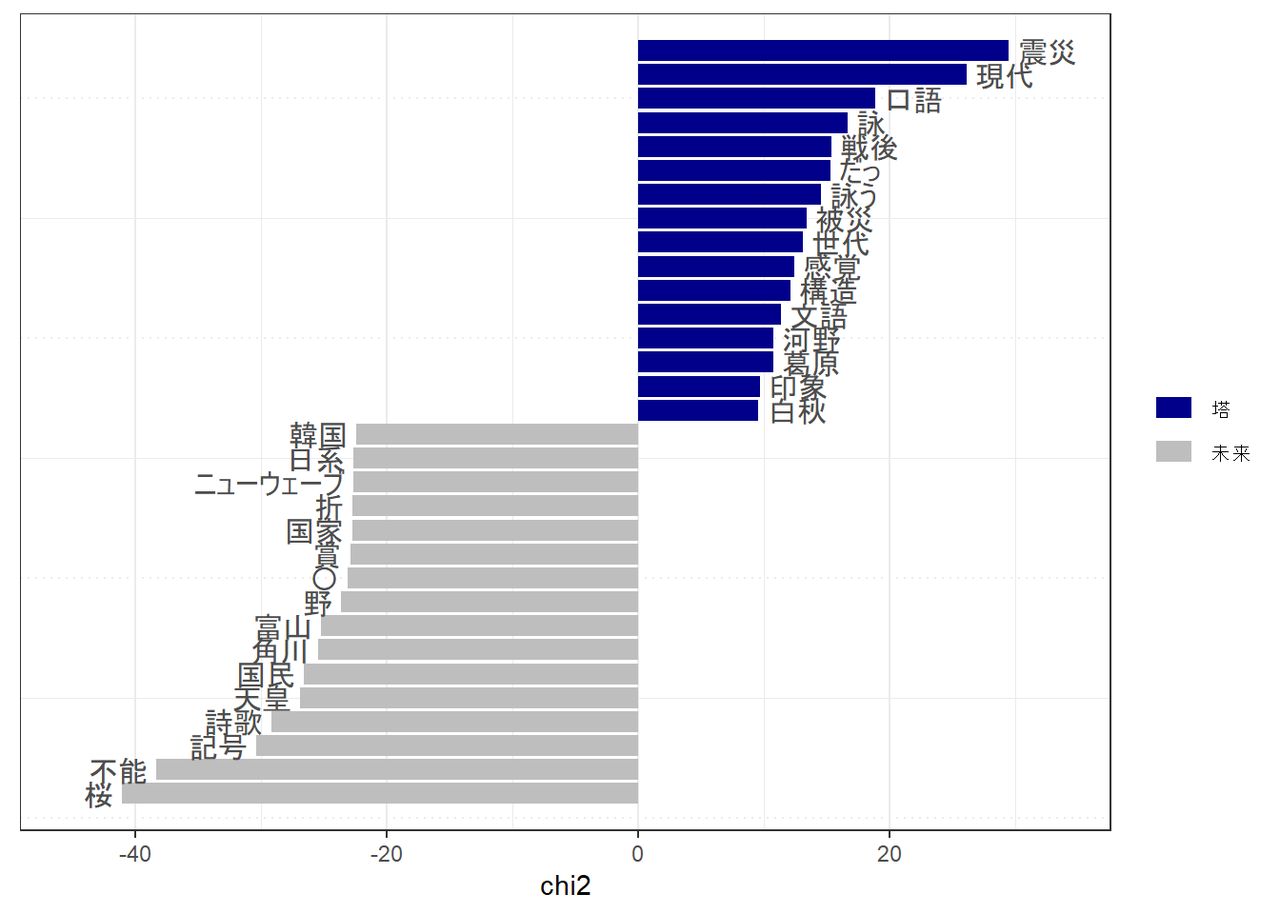
これを見ると、『塔』ではやはり「震災」や「被災」といった語彙が特徴的な語として挙げられるようです。その他に「戦後」や「現代」といった語彙については複数の書き手の文章のなかに繰り返しあらわれていることが確認でき、「塔」の時評の書き手がよく使っている語彙は比較的似たようなものであるらしいことがうかがえます。
『未来』では「桜」や「不能」といった語が頻出しているようです。ただ、これは高島裕「桜咲く頃に」(2018年6月号掲載分)や高島裕「ニューウェーブ=記号短歌?」(2019年8月号掲載分)のなかでこれらの語が繰り返し用いられているためで、『未来』の時評全体を通じてよく用いられている表現ではありません。高島はひとつの文章のなかでキーワードとなる語をしばしば繰り返し用いるタイプの書き手のようで、ここで『未来』に特徴的な語とされるものの一部は高島の書いた一つの時評のなかに偏って出現している場合があります。
次に、共起ネットワーク図を見てみます。共起ネットワークは、順番の前後を問わず、ひとつの文章のなかで共起している語彙同士を線で結んだ図です。線が太いほど共起した頻度が多いことをあらわしています。線が混み合っているため共起関係について何らかの傾向を読み取るのは難しいかもしれませんが、たとえば「当事者」のように片方にしか出現していないらしい語彙が見つけられます。
『塔』の共起ネットワーク図
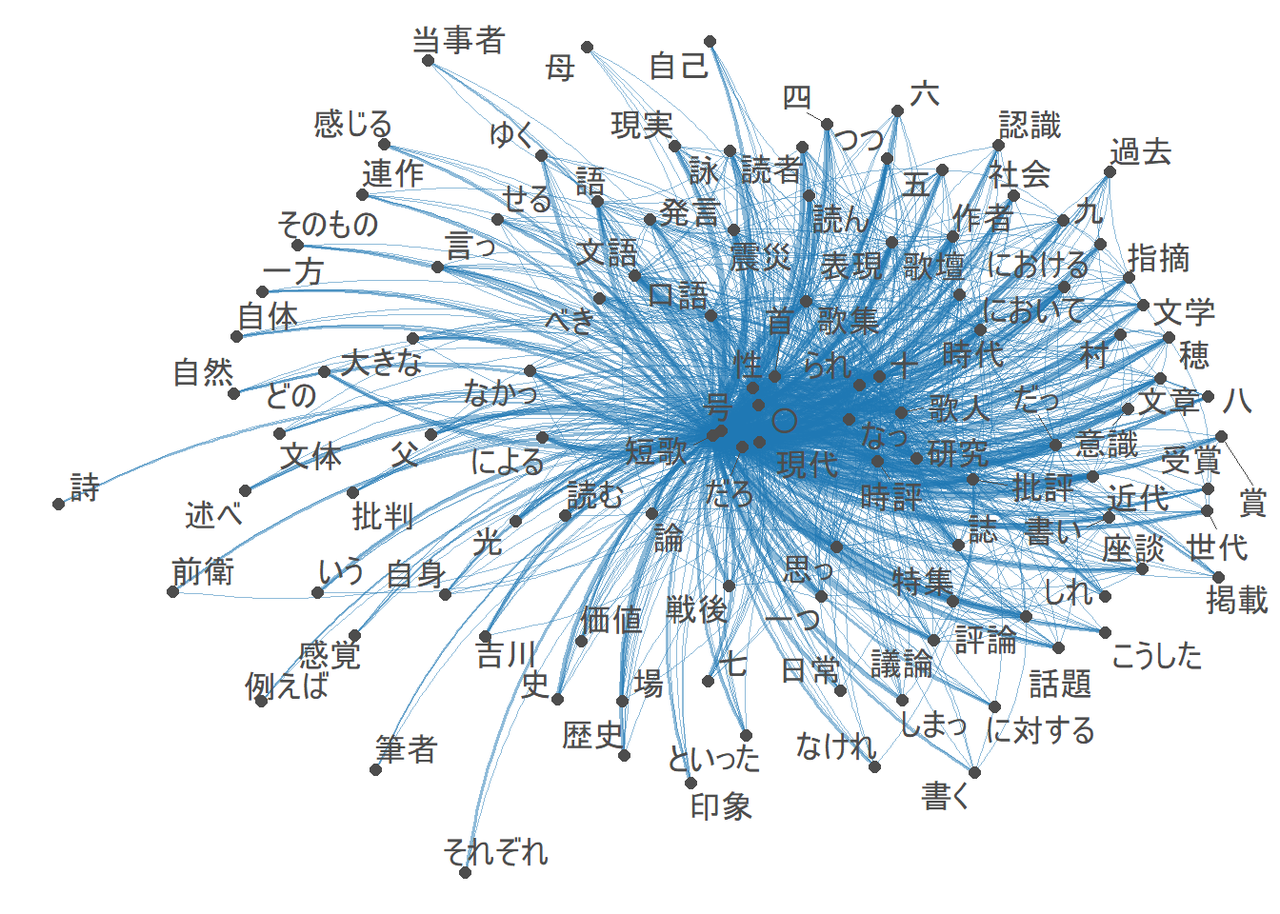
『未来』の共起ネットワーク図

この図はあくまでネットワークの中心付近をクローズアップしたもので、たとえば「当事者」という語彙が『塔』の時評にしか出現しないということではありません。しかし、共起ネットワーク図では一般的によく使われる語彙ほど図の中心付近に集まるはずなので、図中の片方にしかあらわれない語彙はその誌面中におけるほうが相対的によく使われていることの目安になると思われます。
トピック・モデリング
LDAはトピック・モデリングの手法のひとつで、出現する語彙をもとにして文書をいくつかの潜在的なトピック(話題)に分類することができます。分類先のトピックの数は分析者が任意に決めるものなのですが、ここでは目安とするために、LDAを適用するのに先立って文書のクラスタリングをおこない、デンドログラムを書きました。
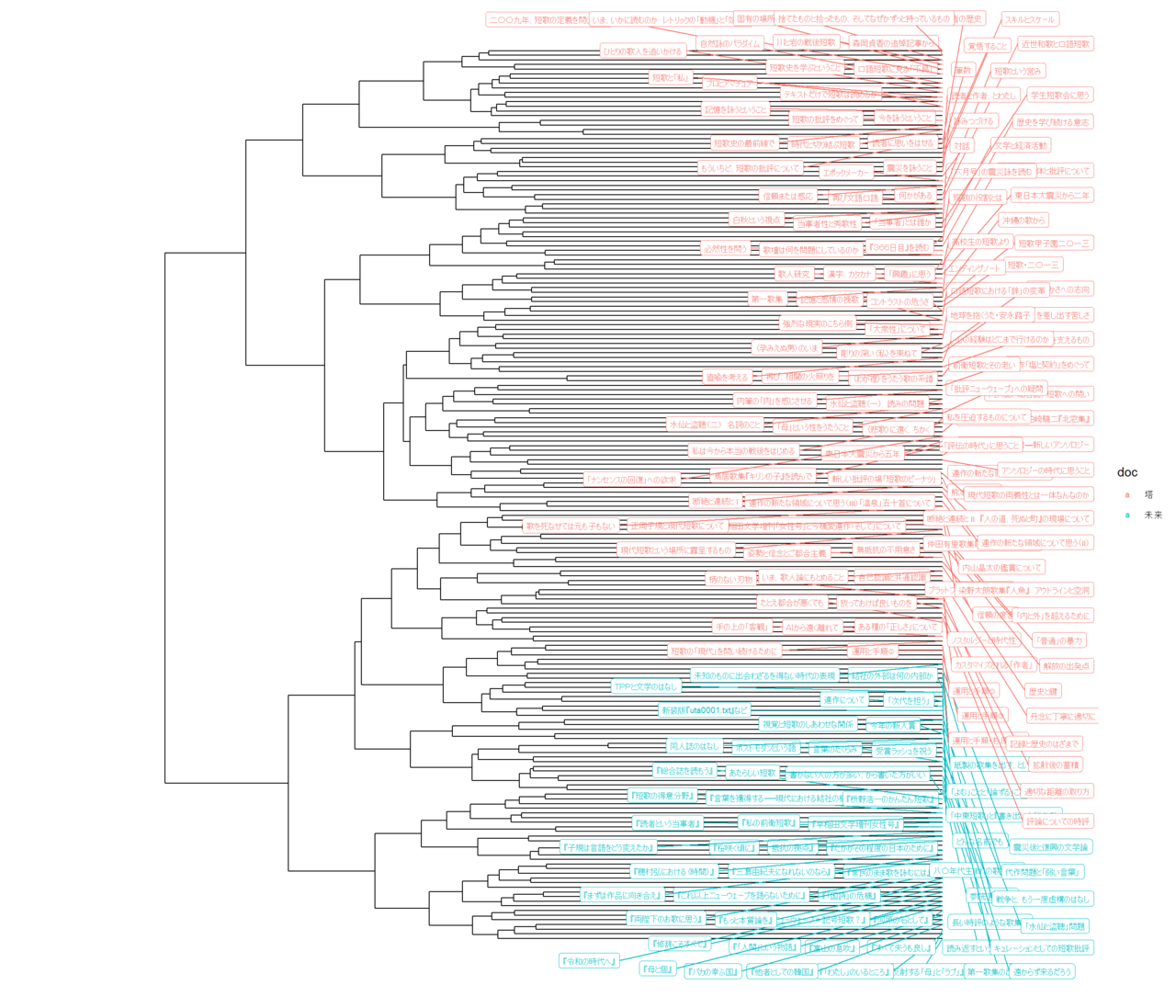
掲載誌によって木構造が比較的はっきりと二分されているのが興味深いです。4~6つくらいのグループに分けるとすっきりする印象なので、LDAはトピック数を6にして適用します。
トピック・モデリングによる分類はただ分類するだけなので、個々のトピックの解釈は分析者がおこなう必要があります。分類先の6つのトピックはこれという解釈が可能なものばかりではありませんでしたが、たとえばリンク先の4番のトピックは短歌における虚構の問題にまつわるトピックのようです(リンク先のページは生成しなおすことがあるかもしれないので番号は対応していないかもしれません、悪しからず)。
単語埋め込み
単語埋め込みは、文書中の語彙の出現のしかたをもとにして、似たような文脈で出現する語ほど近い位置になるように単語間の関係性を高次元の空間に写像する手法です。今回はGloVeという実装を用いて、文書に出現する語彙を50次元の空間に埋め込んでいます。単語埋め込みは文書全体から作成したもの、『塔』掲載分の文書から作成したもの、『未来』掲載分の文書から作成したものの3つを用意し、得られた単語埋め込みをt-SNEという手法でそれぞれ2次元に削減して図示したものが下図です。
全体
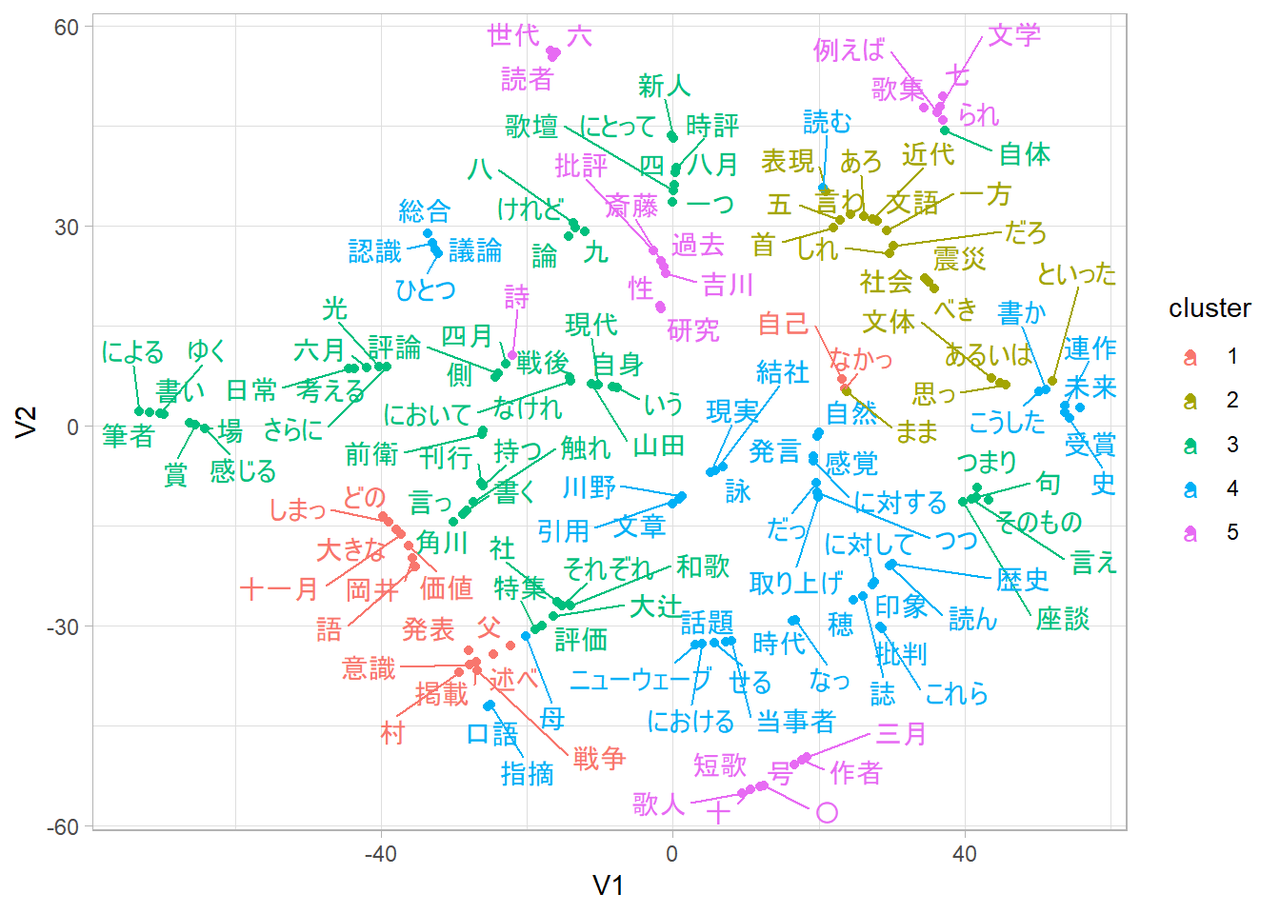
『塔』のみ
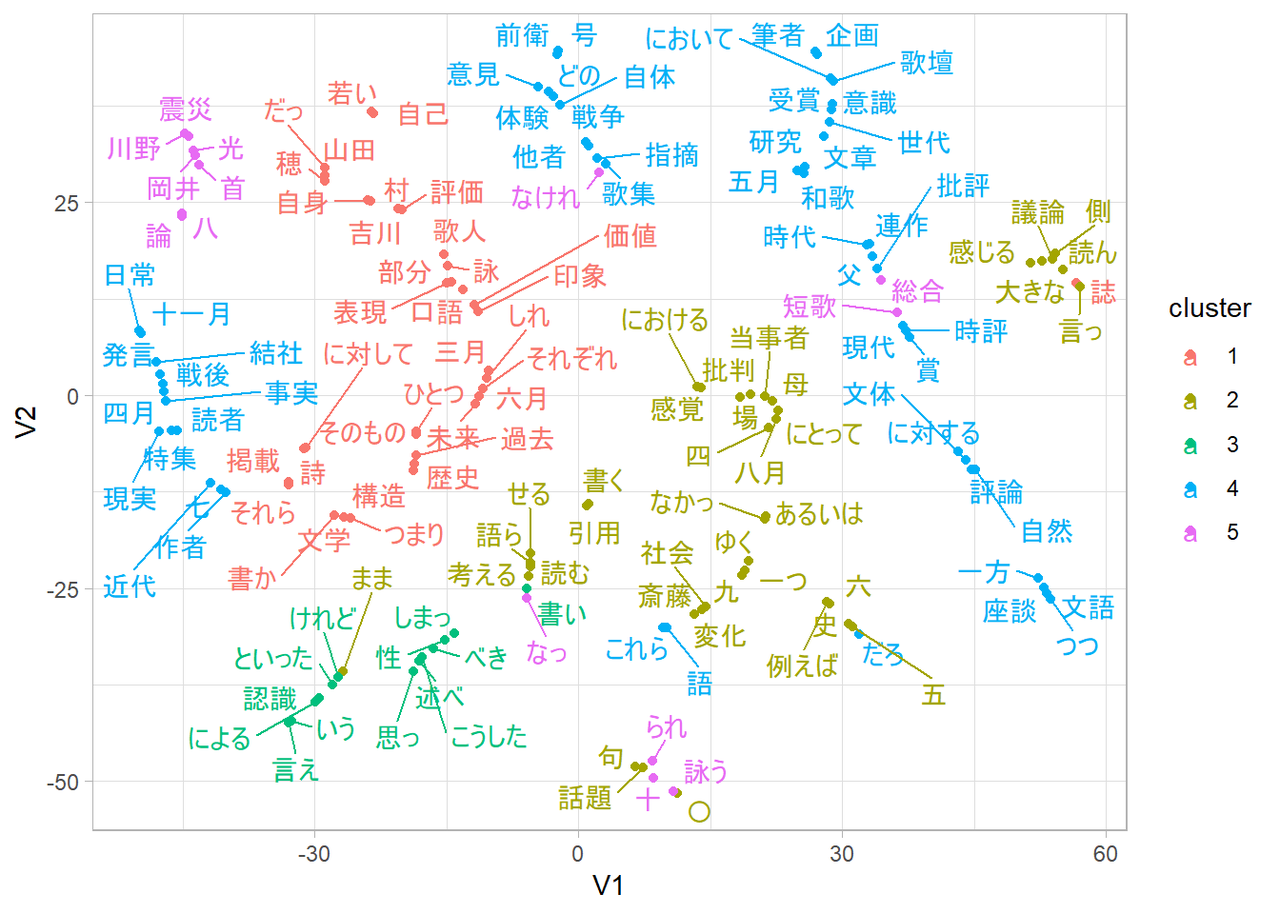
『未来』のみ

図中の語彙は、それぞれの文書のなかでとくに出現数の多い一部のものだけを取り上げています。また、それぞれの図中のなかで近い文脈にあらわれる語彙は近い位置になるようになっていますが、3つの単語埋め込みはそれぞれ基底となるベクトルが異なる空間であるため、軸の意味や語が布置されている位置の意味に対応はありません。
たとえば、このなかの「歌壇」という語に注目してみると、文書全体についての図では中央のやや上に3番の色で図示されていて、「時評」や「にとって」といった語と近い文脈で使われているらしいことがわかります。『塔』のみについての図を見ると、「歌壇」は右上に4番の色で図示されていて、「において」という「にとって」と似たような語彙のほかに、「筆者」「受賞」「意識」といった語彙と近い文脈に出現することがわかります。『未来』のみについての図を見ると、「歌壇」は中央よりやや下のあたりに2番の色で図示されていて、「指摘」「内容」といった語彙ととくに近い文脈に出現するようです。しかし、たとえば「意識」はともかく「筆者」とか「受賞」といった語彙とは少し距離があることがわかります。
これらの図は軸の意味や語が布置されている位置の意味に対応がないため、それぞれの図を見比べるのにはそもそもあまり向いていませんが、近い文脈に置かれている語を概観することで、それぞれのグループにおいてどのような関心から文章が書かれているかを探る手がかりになるかと思います。
まとめ
『未来』と『塔』の二誌のサイトから、ネットに公開済みの時評を収集してテキスト解析をおこないました。分析の対象とした文書は192本で、このくらいの数であれば、十分な時間をかければすべて読み通すことも不可能ではないかもしれません。むしろ個々の時評の述べることについて議論を深めるにはそれぞれの内容を精読すべきでしょうが、大まかにどのような関心から時評が書かれているかを探るうえでは一定の意義のある分析結果が得られたと思います。
二誌に掲載される時評の異なりという観点から見ると、クラスタリングの結果から文書は大まかに二つの枝に二分でき、それぞれがなんとなく二誌の時評の違いに対応していそうなことがわかりました。今回の分析では扱いませんでしたが、ルールベースの決定木などを使用すると、使われている語彙をもとにして比較的よい精度で分類をおこなうことができるかもしれません。
Discussion