文体的特徴にもとづく青空文庫の作品の著者分類
はじめに
この記事では、青空文庫にある作品について、「助詞-記号」「助動詞-記号」「接続詞-記号」のパターンのマイニングをします。その後に、いくつかのパターンの出現比率を特徴量として、芥川龍之介(芥川竜之介)と太宰治の2例について、ロジスティック回帰で著者分類を試します。
データの準備
前処理
ここでは、青空文庫にある以下の10人の作家の文章のうち「新字新仮名」で書かれているもののなかから一部を収集したデータセットを使います。
- 芥川龍之介(芥川竜之介)
- 太宰治
- 泉鏡花
- 菊池寛
- 森鴎外
- 夏目漱石
- 岡本綺堂
- 佐々木味津三
- 島崎藤村
- 海野十三
作品ごとの分量にかなりばらつきがあるので、このなかから文字数が5,000字未満のものを100篇だけランダムに抽出して分析します。
tmp <- tempfile(fileext = ".zip")
download.file("https://github.com/paithiov909/shiryo/raw/main/data/aozora.csv.zip", tmp)
df <- readr::read_csv(tmp, col_types = "cccf") |>
dplyr::mutate(author = as.factor(author)) |>
dplyr::filter(nchar(text) < 5000) |>
dplyr::slice_sample(n = 100L)
作家ごとの大まかな文章量は次のようになっています。作家によって作品数にやや偏りがあります。
df |>
dplyr::mutate(nchar = nchar(text)) |>
dplyr::group_by(author) |>
dplyr::summarise(
nchar_mean = mean(nchar),
nchar_median = median(nchar),
nchar_min = min(nchar),
nchar_max = max(nchar),
n = dplyr::n()
) |>
dplyr::mutate(across(where(is.numeric), trunc))
#> # A tibble: 8 × 6
#> author nchar_mean nchar_median nchar_min nchar_max n
#> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 芥川竜之介 2505 2616 565 4811 18
#> 2 太宰治 1451 972 130 4209 33
#> 3 岡本綺堂 2566 2300 1035 4733 15
#> 4 泉鏡花 3815 3866 2618 4800 6
#> 5 森鴎外 2324 2117 1125 4574 5
#> 6 夏目漱石 2502 2090 1430 4199 15
#> 7 島崎藤村 1119 1119 1047 1192 2
#> 8 海野十三 3105 2795 1363 4724 6
audubon::strj_normalizeで文字列を正規化したうえで、gibasaで分かち書きにします。
df <- df |>
dplyr::mutate(doc_id = title, text = audubon::strj_normalize(text)) |>
dplyr::select(doc_id, text, author) |>
gibasa::tokenize(split = TRUE) |>
gibasa::prettify(col_select = "POS1")
summary(df)
#> doc_id author sentence_id
#> 世界怪談名作集 : 5690 太宰治 :30107 Min. : 1.00
#> 遠野の奇聞 : 3155 芥川竜之介:29082 1st Qu.: 14.00
#> 海のほとり : 3087 岡本綺堂 :27768 Median : 30.00
#> 放し鰻 : 3074 夏目漱石 :24698 Mean : 38.45
#> 海の使者 : 3004 泉鏡花 :15515 3rd Qu.: 55.00
#> のろのろ砲弾の驚異: 2984 海野十三 :11504 Max. :198.00
#> (Other) :126480 (Other) : 8800
#> token_id token POS1
#> Min. : 1.00 Length:147474 Length:147474
#> 1st Qu.: 7.00 Class :character Class :character
#> Median : 14.00 Mode :character Mode :character
#> Mean : 19.85
#> 3rd Qu.: 26.00
#> Max. :193.00
#>
出現頻度の集計
30回以上出現するパターンをグラフにします。「た-。」という文末の表現や「は-、」という主題を表したりする表現が多いようです。
require(ggplot2)
#> 要求されたパッケージ ggplot2 をロード中です
df |>
dplyr::group_by(doc_id) |>
dplyr::mutate(
POS1 = paste(POS1, dplyr::lead(POS1), sep = "-"),
token = paste(token, dplyr::lead(token), sep = "-")
) |>
dplyr::ungroup() |>
dplyr::filter(POS1 %in% c("助詞-記号", "助動詞-記号", "接続詞-記号")) |>
dplyr::count(token) |>
dplyr::filter(n >= 30) |>
ggpubr::ggdotchart(
x = "token", y = "n",
rotate = TRUE, sorting = "descending",
ggtheme = theme_bw()
)

共起ネットワーク
共起関係についてネットワーク図を描いてみます。一部の語は「、」と「。」のどちらとも共起するようです。
df |>
dplyr::group_by(doc_id) |>
dplyr::mutate(
POS1 = paste(POS1, dplyr::lead(POS1), sep = "-"),
from = token, to = dplyr::lead(token)
) |>
dplyr::ungroup() |>
dplyr::filter(POS1 %in% c("助詞-記号", "助動詞-記号", "接続詞-記号")) |>
dplyr::count(from, to) |>
dplyr::filter(n > 5) |>
tidygraph::as_tbl_graph() |>
ggraph::ggraph(layout = "kk") +
ggraph::geom_edge_link(aes(width = n), alpha = .8) +
ggraph::scale_edge_width(range = c(.1, 1)) +
ggraph::geom_node_point() +
ggraph::geom_node_text(aes(label = name), repel = TRUE) +
theme_bw()

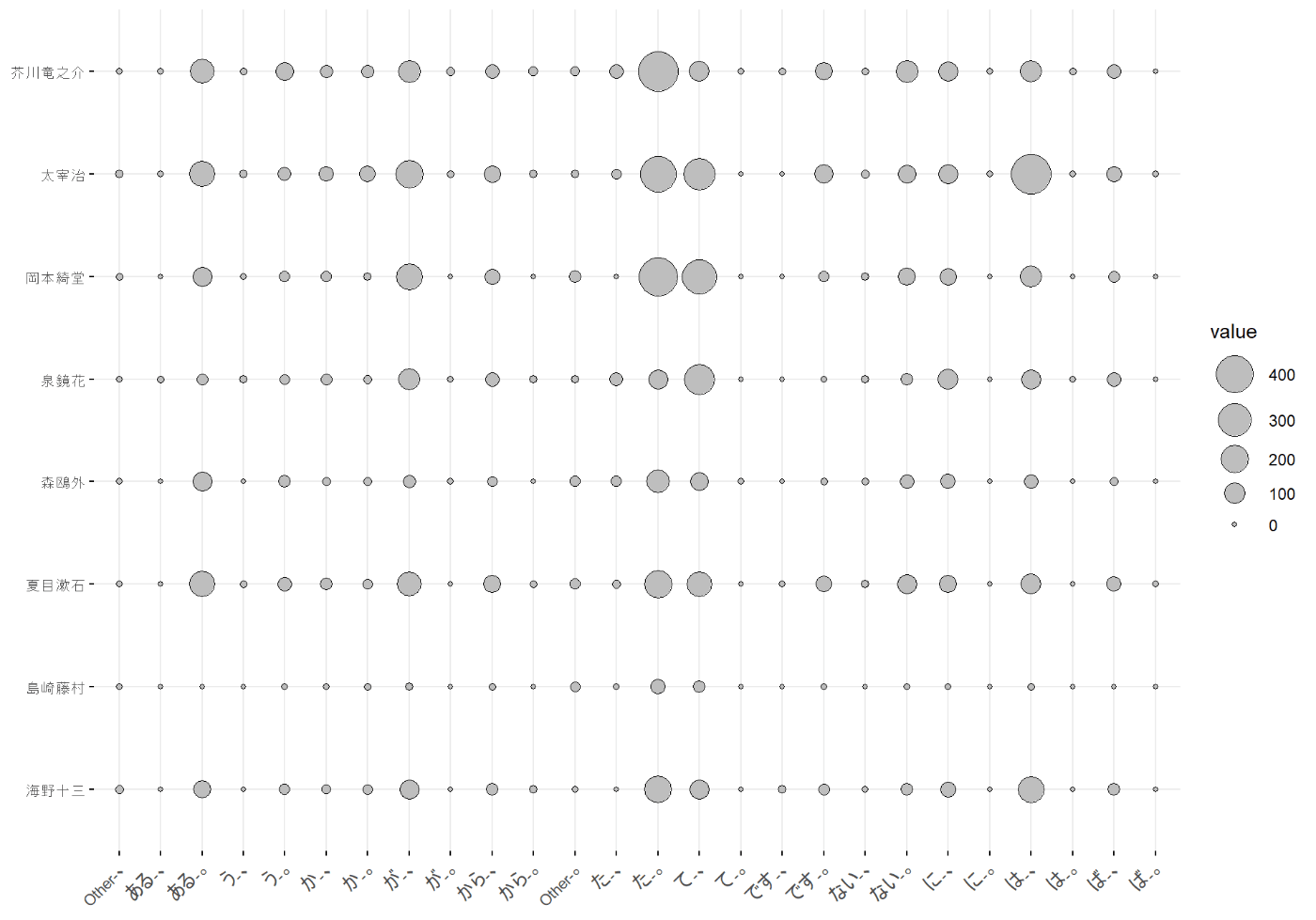
バルーンプロット
作家ごとに頻度を比較できるようにプロットしてみます(もっとも、青空文庫には極端に短い作品がたまにあったりするので、単純な頻度を比較するのはあまり適切でないかもしれません)。
なお、たとえば「神は言っている、ここで死ぬ定めではないと。」のような倒置で文末にくる「と-。」という表現や、「も-。」「で-、」といった表現などはやや特殊なようで、後でバイプロットにしたとき図が偏るため、ここでは集計から省いておきます。
dfm <- df |>
dplyr::group_by(doc_id) |>
dplyr::mutate(
POS1 = paste(POS1, dplyr::lead(POS1), sep = "-"),
from = token, to = dplyr::lead(token)
) |>
dplyr::ungroup() |>
dplyr::filter(
POS1 %in% c("助詞-記号", "助動詞-記号", "接続詞-記号"),
!from %in% c("と", "も", "で"),
to %in% c("、", "。")
) |>
dplyr::count(author, from, to) |>
dplyr::mutate(
author = forcats::fct_drop(author),
from = forcats::fct_lump(from, n = 12, w = n),
term = paste(from, to, sep = "-")
) |>
tidytext::cast_dfm(author, term, n)
dfm |>
quanteda::convert(to = "data.frame") |>
tibble::column_to_rownames("doc_id") |>
ggpubr::ggballoonplot()
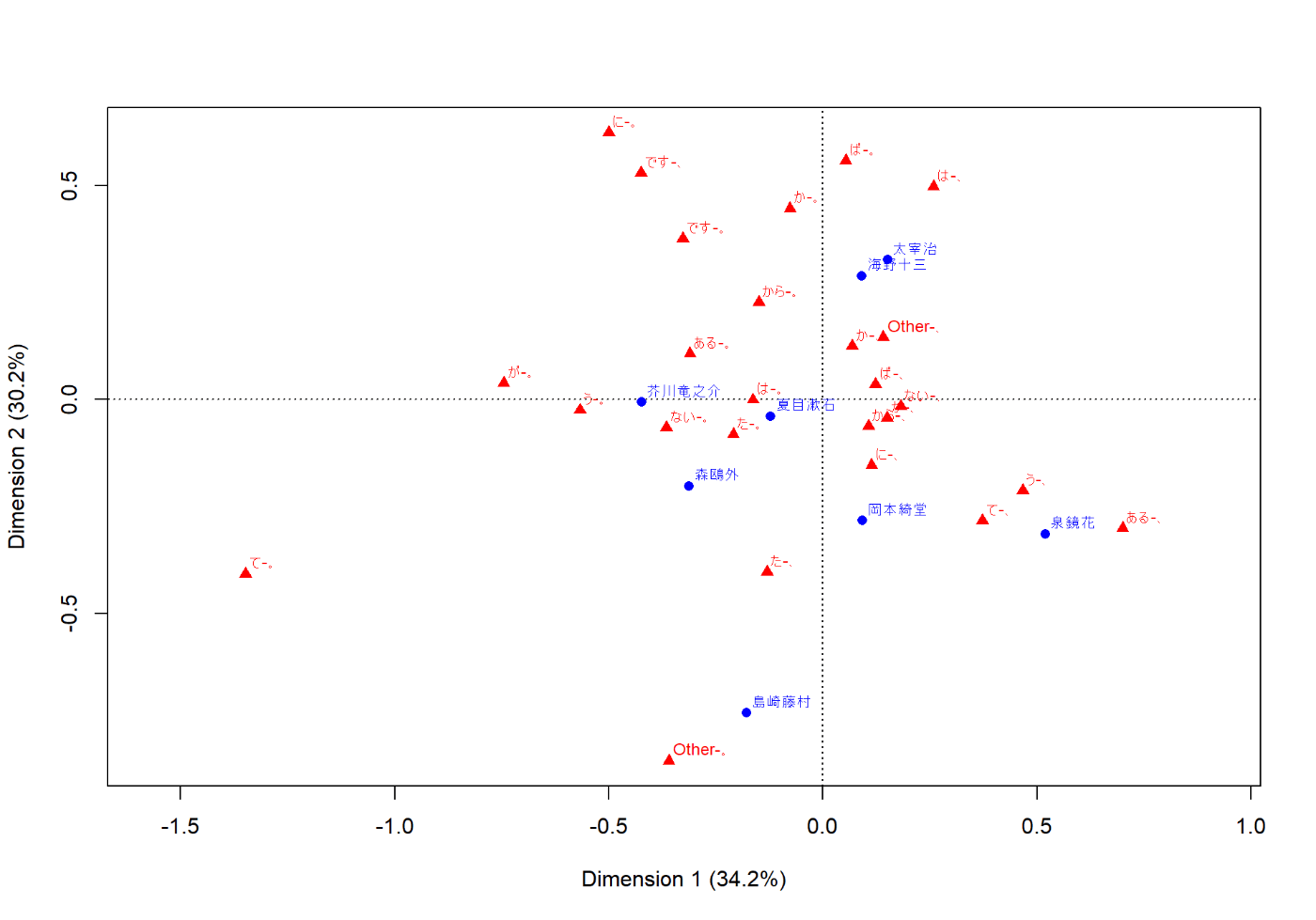
対応分析
対応分析してバイプロットを描いてみます。
mdl <- dfm |>
quanteda.textmodels::textmodel_ca()
require(ca)
#> 要求されたパッケージ ca をロード中です
plot(mdl)
TF-IDF
「と-。」と「も-。」「で-、」のTF-IDFなどを確認します。ここでのTF-IDFなどは、すべてのトークンについてのものではなく、あくまでマイニングしているパターンのなかでの値です。
「と-。」と「も-。」に関しては、そもそもほとんど使われない表現のようです。
df |>
dplyr::group_by(doc_id) |>
dplyr::mutate(
POS1 = paste(POS1, dplyr::lead(POS1), sep = "-"),
from = token, to = dplyr::lead(token)
) |>
dplyr::ungroup() |>
dplyr::filter(POS1 %in% c("助詞-記号", "助動詞-記号", "接続詞-記号")) |>
dplyr::count(author, from, to) |>
dplyr::mutate(term = paste(from, to, sep = "-")) |>
tidytext::bind_tf_idf(term, author, n) |>
dplyr::filter(term == "と-。") |>
dplyr::select(author, term, n, tf, idf, tf_idf)
#> # A tibble: 2 × 6
#> author term n tf idf tf_idf
#> <fct> <chr> <int> <dbl> <dbl> <dbl>
#> 1 芥川竜之介 と-。 1 0.000464 1.39 0.000644
#> 2 太宰治 と-。 2 0.000644 1.39 0.000893
df |>
dplyr::group_by(doc_id) |>
dplyr::mutate(
POS1 = paste(POS1, dplyr::lead(POS1), sep = "-"),
from = token, to = dplyr::lead(token)
) |>
dplyr::ungroup() |>
dplyr::filter(POS1 %in% c("助詞-記号", "助動詞-記号", "接続詞-記号")) |>
dplyr::count(author, from, to) |>
dplyr::mutate(term = paste(from, to, sep = "-")) |>
tidytext::bind_tf_idf(term, author, n) |>
dplyr::filter(term == "も-。") |>
dplyr::select(author, term, n, tf, idf, tf_idf)
#> # A tibble: 1 × 6
#> author term n tf idf tf_idf
#> <fct> <chr> <int> <dbl> <dbl> <dbl>
#> 1 太宰治 も-。 1 0.000322 2.08 0.000669
一方で、「で-、」という表現はどの作家も使ってはいるものの、TFを見るとすこし差があるように見えます。
df |>
dplyr::group_by(doc_id) |>
dplyr::mutate(
POS1 = paste(POS1, dplyr::lead(POS1), sep = "-"),
from = token, to = dplyr::lead(token)
) |>
dplyr::ungroup() |>
dplyr::filter(POS1 %in% c("助詞-記号", "助動詞-記号", "接続詞-記号")) |>
dplyr::count(author, from, to) |>
dplyr::mutate(term = paste(from, to, sep = "-")) |>
tidytext::bind_tf_idf(term, author, n) |>
dplyr::filter(term == "で-、") |>
dplyr::select(author, term, n, tf, idf, tf_idf)
#> # A tibble: 8 × 6
#> author term n tf idf tf_idf
#> <fct> <chr> <int> <dbl> <dbl> <dbl>
#> 1 芥川竜之介 で-、 41 0.0190 0 0
#> 2 太宰治 で-、 124 0.0399 0 0
#> 3 岡本綺堂 で-、 123 0.0597 0 0
#> 4 泉鏡花 で-、 72 0.0522 0 0
#> 5 森鴎外 で-、 16 0.0273 0 0
#> 6 夏目漱石 で-、 84 0.0509 0 0
#> 7 島崎藤村 で-、 4 0.0333 0 0
#> 8 海野十三 で-、 30 0.0273 0 0
ロジスティック回帰
芥川龍之介(芥川竜之介)と太宰治の10,000字未満の作品について、ロジスティック回帰をしてみます。
df <- readr::read_csv(tmp, col_types = "cccf") |>
dplyr::mutate(author = as.factor(author)) |>
dplyr::filter(
nchar(text) < 10000,
author %in% c("太宰治", "芥川竜之介")
) |>
dplyr::mutate(author = forcats::fct_drop(author))
summary(df)
#> doc_id title text author
#> Length:152 Length:152 Length:152 芥川竜之介:69
#> Class :character Class :character Class :character 太宰治 :83
#> Mode :character Mode :character Mode :character
先ほどと同様に形態素解析してから、「助詞-記号」「助動詞-記号」というパターンのみを残した分かち書きにします。
dfm <- df |>
dplyr::mutate(text = audubon::strj_normalize(text)) |>
dplyr::select(doc_id, text, author) |>
gibasa::tokenize(split = TRUE) |>
gibasa::prettify(col_select = "POS1") |>
dplyr::group_by(doc_id) |>
dplyr::mutate(
POS1 = paste(POS1, dplyr::lead(POS1), sep = "-"),
from = token, to = dplyr::lead(token)
) |>
dplyr::ungroup() |>
dplyr::filter(POS1 %in% c("助詞-記号", "助動詞-記号")) |>
dplyr::mutate(term = paste(from, to, sep = "-")) |>
gibasa::pack(term)
分かち書きしたテキストをquantedaのコーパスにしつつ、適当なパターンの特徴量だけ残した文書単語行列にします。
dfm <- dfm |>
dplyr::left_join(dplyr::select(df, doc_id, author), by = "doc_id") |>
quanteda::corpus() |>
quanteda::tokens(what = "fastestword", remove_punct = FALSE) |>
quanteda::tokens_select(c("は-、", "が-、", "に-、", "て-、", "か-、", "で-、", "と-、", "ない-。", "た-。", "だ-。", "が-。")) |>
quanteda::dfm() |>
quanteda::dfm_weight(scheme = "prop")
quanteda.textmodels::textmodel_lrを使って学習します(glmnetのラッパーのようです)。
train <- quanteda::dfm_sample(dfm, size = 40, by = author)
test <- quanteda::dfm_subset(dfm, !quanteda::docid(dfm) %in% quanteda::docid(train))
mdl <- quanteda.textmodels::textmodel_lr(train, quanteda::docvars(train, "author"))
#> Warning: from glmnet C++ code (error code -100); Convergence for 100th lambda
#> value not reached after maxit=10000 iterations; solutions for larger lambdas
#> returned
結果を確認すると、思ったよりそれっぽく予測できているように見えます。実際、「読点の前の文字の相対頻度」などは書き手の同定に使えるっぽいという報告はあるようなので、特徴量として残すパターンをもっと工夫すれば、けっこう精度良く予測できるのかもしれません。
res <-
predict(mdl, test, type = "probability") |>
as.data.frame() |>
dplyr::filter(`太宰治` > .5) |>
row.names()
df |>
dplyr::filter(doc_id %in% quanteda::docid(test)) |>
dplyr::mutate(pred = dplyr::if_else(doc_id %in% res, "太宰治", "芥川竜之介")) |>
dplyr::select(pred, author) |>
table()
#> author
#> pred 芥川竜之介 太宰治
#> 芥川竜之介 22 8
#> 太宰治 7 35
セッション情報
sessioninfo::session_info()
#> ─ Session info ────────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.2.1 (2022-06-23 ucrt)
#> os Windows 10 x64 (build 19043)
#> system x86_64, mingw32
#> ui RStudio
#> language (EN)
#> collate Japanese_Japan.utf8
#> ctype Japanese_Japan.utf8
#> tz Asia/Tokyo
#> date 2022-07-23
#> rstudio 2022.07.0+548 Spotted Wakerobin (desktop)
#> pandoc 2.18 @ C:/Program Files/RStudio/bin/quarto/bin/tools/ (via rmarkdown)
#>
#> ─ Packages ────────────────────────────────────────────────────────────────────
#> ! package * version date (UTC) lib source
#> abind 1.4-5 2016-07-21 [1] CRAN (R 4.2.0)
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.2.0)
#> audubon 0.3.0 2022-07-22 [1] CRAN (R 4.2.1)
#> backports 1.4.1 2021-12-13 [1] CRAN (R 4.2.0)
#> bit 4.0.4 2020-08-04 [1] CRAN (R 4.2.0)
#> bit64 4.0.5 2020-08-30 [1] CRAN (R 4.2.0)
#> broom 1.0.0 2022-07-01 [1] CRAN (R 4.2.0)
#> bslib 0.4.0 2022-07-16 [1] RSPM (R 4.2.0)
#> ca * 0.71.1 2020-01-24 [1] RSPM (R 4.2.0)
#> cachem 1.0.6 2021-08-19 [1] CRAN (R 4.2.0)
#> car 3.1-0 2022-06-15 [1] CRAN (R 4.2.0)
#> carData 3.0-5 2022-01-06 [1] CRAN (R 4.2.0)
#> cleanrmd 0.1.0 2022-06-14 [1] RSPM (R 4.2.0)
#> cli 3.3.0 2022-04-25 [1] CRAN (R 4.2.0)
#> codetools 0.2-18 2020-11-04 [2] CRAN (R 4.2.1)
#> colorspace 2.0-3 2022-02-21 [1] CRAN (R 4.2.0)
#> crayon 1.5.1 2022-03-26 [1] CRAN (R 4.2.0)
#> curl 4.3.2 2021-06-23 [1] CRAN (R 4.2.0)
#> DBI 1.1.3 2022-06-18 [1] CRAN (R 4.2.0)
#> digest 0.6.29 2021-12-01 [1] CRAN (R 4.2.0)
#> dplyr 1.0.9 2022-04-28 [1] CRAN (R 4.2.0)
#> ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.2.0)
#> evaluate 0.15 2022-02-18 [1] CRAN (R 4.2.0)
#> fansi 1.0.3 2022-03-24 [1] CRAN (R 4.2.0)
#> farver 2.1.1 2022-07-06 [1] CRAN (R 4.2.1)
#> fastmap 1.1.0.9000 2022-05-15 [1] https://fastverse.r-universe.dev (R 4.2.0)
#> fastmatch 1.1-3 2021-07-23 [1] CRAN (R 4.2.0)
#> forcats 0.5.1 2021-01-27 [1] CRAN (R 4.2.0)
#> foreach 1.5.2 2022-02-02 [1] CRAN (R 4.2.0)
#> generics 0.1.3 2022-07-05 [1] CRAN (R 4.2.0)
#> ggforce 0.3.3 2021-03-05 [1] CRAN (R 4.2.0)
#> ggplot2 * 3.3.6 2022-05-03 [1] CRAN (R 4.2.0)
#> ggpubr 0.4.0 2020-06-27 [1] CRAN (R 4.2.0)
#> ggraph 2.0.5 2021-02-23 [1] CRAN (R 4.2.0)
#> ggrepel 0.9.1 2021-01-15 [1] CRAN (R 4.2.0)
#> ggsignif 0.6.3 2021-09-09 [1] CRAN (R 4.2.0)
#> gibasa 0.3.0 2022-05-22 [1] Github (paithiov909/gibasa@88b7036)
#> glmnet 4.1-4 2022-04-15 [1] CRAN (R 4.2.0)
#> glue 1.6.2 2022-02-24 [1] CRAN (R 4.2.0)
#> graphlayouts 0.8.0 2022-01-03 [1] CRAN (R 4.2.0)
#> gridExtra 2.3 2017-09-09 [1] CRAN (R 4.2.0)
#> gtable 0.3.0 2019-03-25 [1] CRAN (R 4.2.0)
#> highr 0.9 2021-04-16 [1] CRAN (R 4.2.0)
#> hms 1.1.1 2021-09-26 [1] CRAN (R 4.2.0)
#> htmltools 0.5.3 2022-07-18 [1] CRAN (R 4.2.1)
#> igraph 1.3.4 2022-07-19 [1] RSPM (R 4.2.0)
#> iterators 1.0.14 2022-02-05 [1] CRAN (R 4.2.0)
#> janeaustenr 0.1.5 2017-06-10 [1] CRAN (R 4.2.0)
#> jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.2.0)
#> jsonlite 1.8.0 2022-02-22 [1] CRAN (R 4.2.0)
#> knitr 1.39 2022-04-26 [1] CRAN (R 4.2.0)
#> labeling 0.4.2 2020-10-20 [1] CRAN (R 4.2.0)
#> lattice 0.20-45 2021-09-22 [2] CRAN (R 4.2.1)
#> LiblineaR 2.10-12 2021-03-02 [1] CRAN (R 4.2.0)
#> lifecycle 1.0.1 2021-09-24 [1] CRAN (R 4.2.0)
#> magrittr 2.0.3.9000 2022-05-13 [1] https://fastverse.r-universe.dev (R 4.2.0)
#> MASS 7.3-57 2022-04-22 [2] CRAN (R 4.2.1)
#> Matrix 1.4-1 2022-03-23 [2] CRAN (R 4.2.1)
#> memoise 2.0.1 2021-11-26 [1] CRAN (R 4.2.0)
#> metathis 1.1.1 2021-06-29 [1] CRAN (R 4.2.0)
#> munsell 0.5.0 2018-06-12 [1] CRAN (R 4.2.0)
#> pillar 1.8.0 2022-07-18 [1] CRAN (R 4.2.1)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.2.0)
#> polyclip 1.10-0 2019-03-14 [1] CRAN (R 4.2.0)
#> purrr 0.3.4 2020-04-17 [1] CRAN (R 4.2.0)
#> quanteda 3.2.1 2022-03-01 [1] CRAN (R 4.2.0)
#> quanteda.textmodels 0.9.4 2021-04-06 [1] CRAN (R 4.2.0)
#> R.cache 0.16.0 2022-07-21 [1] CRAN (R 4.2.1)
#> R.methodsS3 1.8.2 2022-06-13 [1] CRAN (R 4.2.0)
#> R.oo 1.25.0 2022-06-12 [1] CRAN (R 4.2.0)
#> R.utils 2.12.0 2022-06-28 [1] CRAN (R 4.2.0)
#> R6 2.5.1 2021-08-19 [1] CRAN (R 4.2.0)
#> Rcpp 1.0.9 2022-07-08 [1] CRAN (R 4.2.1)
#> D RcppParallel 5.1.5 2022-01-05 [1] CRAN (R 4.2.0)
#> readr 2.1.2 2022-01-30 [1] CRAN (R 4.2.0)
#> rlang 1.0.4 2022-07-12 [1] RSPM (R 4.2.0)
#> rmarkdown 2.14 2022-04-25 [1] CRAN (R 4.2.0)
#> RSpectra 0.16-1 2022-04-24 [1] CRAN (R 4.2.0)
#> rstatix 0.7.0 2021-02-13 [1] CRAN (R 4.2.0)
#> rstudioapi 0.13 2020-11-12 [1] CRAN (R 4.2.0)
#> sass 0.4.2 2022-07-16 [1] RSPM (R 4.2.0)
#> scales 1.2.0 2022-04-13 [1] CRAN (R 4.2.0)
#> sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.2.0)
#> shape 1.4.6 2021-05-19 [1] CRAN (R 4.2.0)
#> SnowballC 0.7.0 2020-04-01 [1] CRAN (R 4.2.0)
#> SparseM 1.81 2021-02-18 [1] CRAN (R 4.2.0)
#> stopwords 2.3 2021-10-28 [1] CRAN (R 4.2.0)
#> stringi 1.7.8 2022-07-11 [1] RSPM (R 4.2.0)
#> stringr 1.4.0.9000 2022-05-14 [1] https://fastverse.r-universe.dev (R 4.2.0)
#> styler 1.7.0 2022-03-13 [1] CRAN (R 4.2.0)
#> survival 3.3-1 2022-03-03 [2] CRAN (R 4.2.1)
#> tibble 3.1.8 2022-07-22 [1] CRAN (R 4.2.1)
#> tidygraph 1.2.1 2022-04-05 [1] CRAN (R 4.2.0)
#> tidyr 1.2.0 2022-02-01 [1] CRAN (R 4.2.0)
#> tidyselect 1.1.2 2022-02-21 [1] CRAN (R 4.2.0)
#> tidytext 0.3.3 2022-05-09 [1] CRAN (R 4.2.0)
#> tokenizers 0.2.1 2018-03-29 [1] CRAN (R 4.2.0)
#> tweenr 1.0.2 2021-03-23 [1] CRAN (R 4.2.0)
#> tzdb 0.3.0 2022-03-28 [1] CRAN (R 4.2.0)
#> utf8 1.2.2 2021-07-24 [1] CRAN (R 4.2.0)
#> V8 4.2.0 2022-05-14 [1] CRAN (R 4.2.0)
#> vctrs 0.4.1 2022-04-13 [1] CRAN (R 4.2.0)
#> viridis 0.6.2 2021-10-13 [1] CRAN (R 4.2.0)
#> viridisLite 0.4.0 2021-04-13 [1] CRAN (R 4.2.0)
#> vroom 1.5.7 2021-11-30 [1] CRAN (R 4.2.0)
#> withr 2.5.0 2022-03-03 [1] CRAN (R 4.2.0)
#> xfun 0.31 2022-05-10 [1] CRAN (R 4.2.0)
#> yaml 2.3.5 2022-02-21 [1] CRAN (R 4.2.0)
#>
#> [1] C:/R/win-library/4.2
#> [2] C:/Program Files/R/R-4.2.1/library
#>
#> D ── DLL MD5 mismatch, broken installation.
#>
#> ───────────────────────────────────────────────────────────────────────────────
Discussion