tidymodelsの練習・XGBoostに疎行列を渡して学習する


この記事について
『Rユーザのためのtidymodels[実践]入門』(『tidymodels本』)を参考にしつつ、tidymodelsとtextrecipesを使って著者分類をやります。
モチベーションとしては、XGBoostを使いつつ、訓練データとしてTF-IDFで重み付けされた疎行列を与えるという『tidymodels本』ではやられていないパターンをやってみて、Feature Hashingの場合と比べてみたいと思います。
suppressPackageStartupMessages({
require(tidyverse)
require(tidymodels)
require(textrecipes)
})
tidymodels::tidymodels_prefer()
データセットの準備
ここでは、青空文庫にある以下の10人の作家の文章のうち「新字新仮名」で書かれているもののなかから一部を収集したデータセット(のさらに一部)を使います。
- 芥川龍之介(芥川竜之介)
- 太宰治
- 泉鏡花
- 菊池寛
- 森鴎外
- 夏目漱石
- 岡本綺堂
- 佐々木味津三
- 島崎藤村
- 海野十三
作家や作品によって分量にかなりばらつきがあるので、ここでは20,000字未満の作品についていい感じに抽出して使います。
tmp <- tempfile(fileext = ".zip")
download.file("https://github.com/paithiov909/shiryo/raw/main/data/aozora.csv.zip", tmp)
df <- readr::read_csv(tmp, col_types = "cccf") |>
dplyr::filter(nchar(text) < 20000) |>
dplyr::distinct(title, .keep_all = TRUE) |>
dplyr::mutate(author = forcats::fct_lump(author, n = 4)) |>
dplyr::filter(author != "Other") |>
dplyr::mutate(author = forcats::fct_drop(author))
nrow(df)
#> [1] 325
具体的には、芥川竜之介・太宰治・岡本綺堂・海野十三の4人の325作品です。おおよその分量や内訳は次のようになっています。
df |>
dplyr::mutate(
nchar = nchar(text)
) |>
dplyr::group_by(author) |>
dplyr::summarise(
nchar_mean = mean(nchar),
nchar_median = median(nchar),
nchar_min = min(nchar),
nchar_max = max(nchar),
nchar_total = sum(nchar),
n = dplyr::n()
) |>
dplyr::mutate(across(where(is.numeric), trunc))
#> # A tibble: 4 × 7
#> author nchar_mean nchar_median nchar_min nchar_max nchar_total n
#> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 芥川竜之介 4499 3858 392 14895 346424 77
#> 2 太宰治 5439 3385 95 19928 582029 107
#> 3 岡本綺堂 6853 5877 558 18801 459217 67
#> 4 海野十三 8220 7531 824 19643 608341 74
この325作品は、いずれの作家についても短編の数が多く、たまに長い作品があるという感じのようです。
df |>
dplyr::mutate(nchar = nchar(text)) |>
ggpubr::ggdensity(
"nchar",
y = "density",
color = "author",
palette = viridis::turbo(6)
)

前処理
『tidymodels本』の6章ではtextrecipes::step_tokenizeのcustom_token引数にトークナイザを渡していますが、ここではレシピのこの部分を差し替えたりはしないため、分かち書きの前処理としては共通になります。そこで、テキスト列はtidymodelsの枠組みの外側であらかじめ形態素解析をすませてから、スペース区切りのテキストとしてデータセットのなかに差し戻しておきます。
ここで使っているMeCabの辞書はIPA辞書です。今回のデータセットでは、総トークン数は127万くらいになります。
corp <- df |>
dplyr::mutate(text = audubon::strj_normalize(text)) |>
dplyr::select(title, text, author) |>
gibasa::tokenize(text, title, split = TRUE) |>
gibasa::prettify(col_select = c("POS1", "POS2", "Original"))
nrow(corp)
#> [1] 1273878
辞書にあった語彙で、「助詞」「助動詞」「記号」を除いた結果に、品詞情報をくっつけながら、適当に分かち書きにします。ちなみに、たぶんですが、見た目のかたちが同じでも品詞情報まで見ると異なる語彙というのはわりとよくあるため、品詞情報をくっつけておいたほうが異なり語の数(=特徴量の数)を増やすことができ、最終的な精度がよくなります(たぶん)。
corp <- corp |>
dplyr::mutate(
token = stringr::str_c(Original, POS1, POS2, sep = "/")
) |>
gibasa::mute_tokens(POS1 %in% c("記号", "助詞", "助動詞") |
is.na(Original)) |>
gibasa::pack() |>
dplyr::rename(title = doc_id) |>
dplyr::left_join(
dplyr::select(df, doc_id, title, author),
by = "title"
)
これは、次のようなかたちの分かち書きになっています。
dplyr::pull(corp[1, ], text) |> stringr::str_sub(end = 200L)
#> [1] "私/名詞/代名詞 家/名詞/一般 代々/名詞/副詞可能 お/接頭詞/名詞接続 奥/名詞/一般 坊主/名詞/一般 の/名詞/非自立 父/名詞/一般 母/名詞/一般 はなはだ/副詞/一般 特徴/名詞/一般 ない/形容詞/自立 平凡/名詞/形容動詞語幹 人間/名詞/一般 父/名詞/一般 一中節/名詞/一般 囲碁/名詞/一般 盆栽/名詞/一般 俳句/名詞/一般 道楽/名詞/サ変接続 ある/動詞/自立 いず"
このデータセットを訓練用データとテスト用データに分割しておきます。
corp_split <- initial_split(corp, strata = author)
corp_train <- training(corp_split)
corp_test <- testing(corp_split)
モデリング1(TF-IDFの疎行列の場合)
『tidymodels本』の6章ではわりといきなりFeature Hashingが出てきます。しかし、やはりとりあえずTF-IDFでも学習してみたいですよね。というわけで、まずはtextrecipes::step_tfidfを含むレシピを用意します。
tfidf_rec <-
recipe(author ~ text, data = corp_train) |>
step_tokenize(text, custom_token = \(x) {
strsplit(x, " +")
}) |>
step_tokenfilter(text, min_times = 30, max_tokens = 1e3) |>
step_tfidf(text)
このレシピを使ってワークフローをつくりますが、ポイントとして、このときblueprint=hardhat::default_recipe_blueprint(composition = "dgCMatrix")というおまじないを書きます。
xgb_spec <-
boost_tree(
trees = 1000,
learn_rate = .2,
sample_size = tune(),
loss_reduction = tune(),
tree_depth = tune(),
stop_iter = 5
) |>
set_engine("xgboost") |>
set_mode("classification")
tfidf_wflow <-
workflow() |>
add_recipe(
tfidf_rec,
blueprint = hardhat::default_recipe_blueprint(composition = "dgCMatrix")
) |>
add_model(xgb_spec)
これは、前処理が終わったときのpredictorsの型を指定している記述です。
TF-IDFで重み付けされた文書単語行列は、非常にsparsityが高いオブジェクトですが、前処理が終わったときのpredictorsの型はデフォルトではtibbleなので、ふつうに密なオブジェクトになっています。
実際に確認してみると、値が0のところはちゃんと0.0で埋まっています。
tfidf_rec |>
prep() |>
bake(new_data = NULL) |>
dplyr::select(1:10) |>
dplyr::glimpse()
#> Rows: 242
#> Columns: 10
#> $ author <fct> 岡本綺堂, 岡本綺堂, 岡本綺堂, 岡本…
#> $ `tfidf_text_あいだ/名詞/副詞可能` <dbl> 0.0005113384, 0.0017296145, 0.00549…
#> $ `tfidf_text_あがる/動詞/自立` <dbl> 0.0004354376, 0.0014728782, 0.00000…
#> $ `tfidf_text_あける/動詞/自立` <dbl> 0.0008516207, 0.0000000000, 0.00057…
#> $ `tfidf_text_あげる/動詞/自立` <dbl> 0.0020833483, 0.0009395968, 0.00055…
#> $ `tfidf_text_あげる/動詞/非自立` <dbl> 0.0009433636, 0.0010636501, 0.00000…
#> $ `tfidf_text_あたし/名詞/代名詞` <dbl> 0.0000000000, 0.0008180038, 0.00000…
#> $ `tfidf_text_あたり/名詞/一般` <dbl> 0.0003917866, 0.0017669703, 0.00052…
#> $ `tfidf_text_あと/名詞/一般` <dbl> 0.0019714064, 0.0018523139, 0.00264…
#> $ `tfidf_text_あなた/名詞/代名詞` <dbl> 0.0000000000, 0.0004801046, 0.00171…
一方で、blueprintからcomposition = "dgCMatrix"を指定すると、前処理が終わった時点のpredictorsの型が疎行列(dgCMatrix)になります。疎行列は、glmnetのロジスティク回帰(多項ロジットを含む)とXGBoost、rangerのランダムフォレストなどの一部のモデルでしか扱えませんが、密なオブジェクトを渡す場合に比べて効率よく学習をおこなうことができます。
ワークフローができたので、ハイパーパラメータの探索をします。
set.seed(123)
straps <- bootstraps(corp_train, times = 3, strata = author)
corp_tfidf_grid <-
tune_grid(
tfidf_wflow,
resamples = straps,
grid = grid_latin_hypercube(
sample_prop(),
loss_reduction(),
tree_depth(),
size = 10
),
metrics = metric_set(f_meas),
control = control_grid(save_pred = TRUE)
)
autoplot(corp_tfidf_grid)
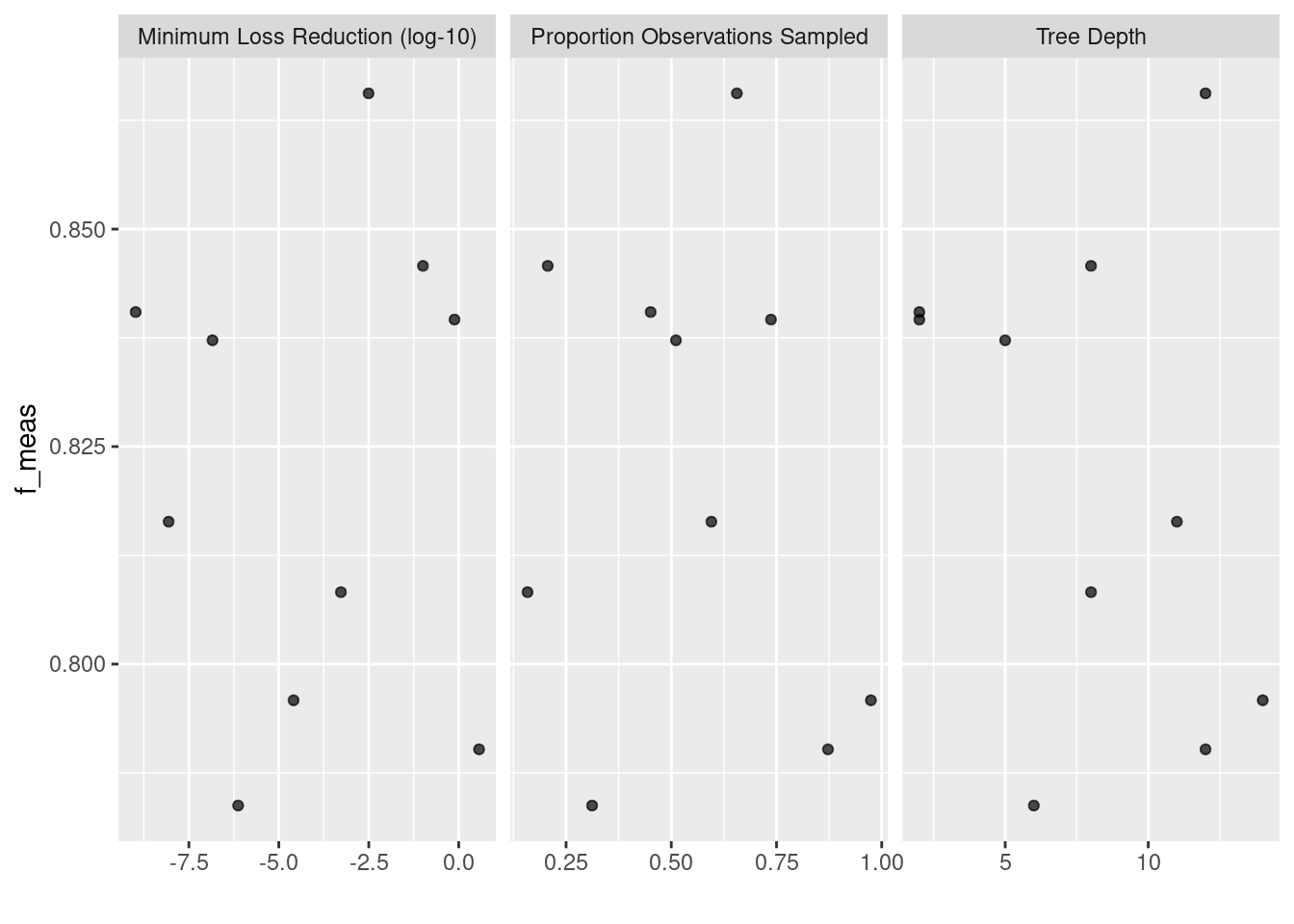
これはこれでよい精度で学習できるようです。
tfidf_wflow_best <-
finalize_workflow(tfidf_wflow, select_best(corp_tfidf_grid))
tfidf_last_fit <-
last_fit(tfidf_wflow_best, corp_split, metrics = metric_set(f_meas))
collect_metrics(tfidf_last_fit)
#> # A tibble: 1 × 4
#> .metric .estimator .estimate .config
#> <chr> <chr> <dbl> <chr>
#> 1 f_meas macro 0.935 Preprocessor1_Model1
モデリング2(Feature Hashing)
『tidymodels本』と同様にFeature Hashingもやってみます。本当はworkflowsetsを使って一気に学習してみたかったのですが、blueprintを指定する方法がよくわからなかったので、先ほどのレシピと差し替えて新しいワークフローをつくります。
hashing_rec <-
recipe(author ~ text, data = corp_train) |>
step_tokenize(text, custom_token = \(x) {
strsplit(x, " +")
}) |>
step_tokenfilter(text, min_times = 30, max_tokens = 1e3) |>
step_texthash(text)
hashing_wflow <-
tfidf_wflow |>
update_recipe(hashing_rec)
先ほどと同様にして学習します。
corp_hashing_grid <-
tune_grid(
hashing_wflow,
resamples = straps,
grid = grid_latin_hypercube(
sample_prop(),
loss_reduction(),
tree_depth(),
size = 10
),
metrics = metric_set(f_meas),
control = control_grid(save_pred = TRUE)
)
autoplot(corp_hashing_grid)
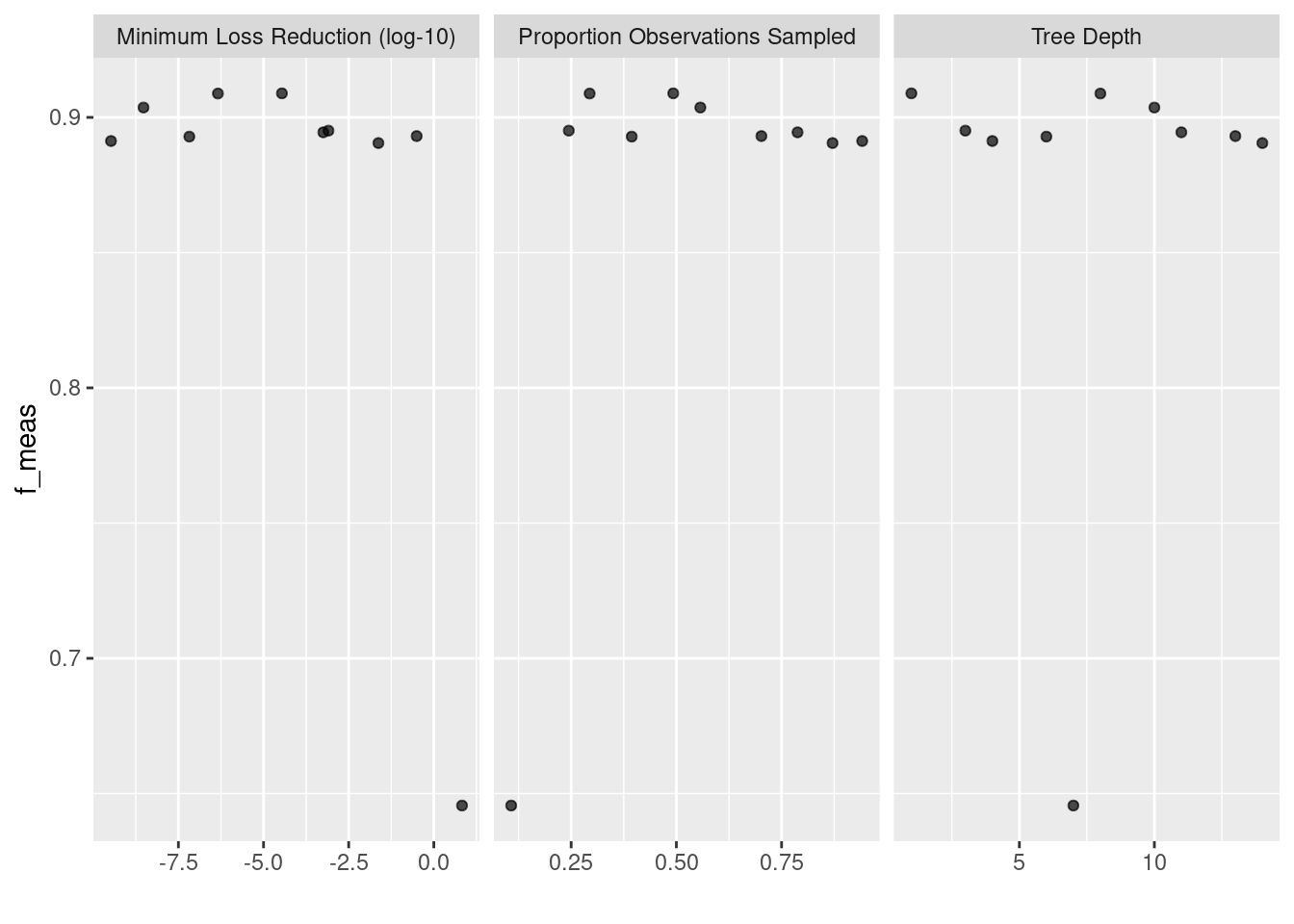
先ほどより良さげなモデルができています。まあ、そもそもテスト用データがそんなにないのでこんなもののような気もしますが。
hashing_wflow_best <-
finalize_workflow(hashing_wflow, select_best(corp_hashing_grid))
hashing_last_fit <-
last_fit(hashing_wflow_best, corp_split, metrics = metric_set(f_meas))
collect_metrics(hashing_last_fit)
#> # A tibble: 1 × 4
#> .metric .estimator .estimate .config
#> <chr> <chr> <dbl> <chr>
#> 1 f_meas macro 0.952 Preprocessor1_Model1
Discussion