RでMeCab(RcppMeCab)を利用して形態素解析する方法
RcppMeCabとは
RcppMeCabは、Junhewk Kim氏が開発している、MeCabとRcppを利用して形態素解析するためのRパッケージです。
RcppMeCabによる形態素解析の例
形態素解析するための関数として、RcppMeCab::posとRcppMeCab::posParallelの2つがあります。両者はまったく同じ機能を提供するものですが、posParallelのほうは形態素解析の処理を内部的にマルチスレッドで回すことができます。posParallelが対応しているOS・プラットフォームならば、基本的にposParallelを使っておくほうが速いです。
渡す引数によって、以下のような出力を得ることができます。
require(RcppMeCab)
sentence <- c("陽が照って鳥が啼き あちこちの楢の林も、けむるとき", "ぎちぎちと鳴る 汚い掌を、おれはこれからもつことになる")
## テキストだけ与える場合、デフォルトの戻り値はnamed list of character vectors.
## リストの各要素は、表層形(surface form)と素性情報の1番目(IPA辞書では「品詞」)を'/'で区切ってつなげた文字列ベクトルになる。
RcppMeCab::pos(sentence)
#> $`1`
#> [1] "陽/名詞" "が/助詞" "照っ/動詞" "て/助詞"
#> [5] "鳥/名詞" "が/助詞" "啼き/動詞" " /記号"
#> [9] "あちこち/名詞" "の/助詞" "楢/名詞" "の/助詞"
#> [13] "林/名詞" "も/助詞" "、/記号" "けむる/動詞"
#> [17] "とき/名詞"
#>
#> $`2`
#> [1] "ぎちぎち/副詞" "と/助詞" "鳴る/動詞" " /記号"
#> [5] "汚い/形容詞" "掌/名詞" "を/助詞" "、/記号"
#> [9] "おれ/名詞" "は/助詞" "これから/副詞" "もつ/動詞"
#> [13] "こと/名詞" "に/助詞" "なる/動詞"
## 'join=FALSE'を指定すると、戻り値はnamed list of named character vectorsになる。
## Neologd辞書などでは収録されている語彙そのものに'/'が含まれていることがあるため、使用ケースによって使い分けるとよい。
RcppMeCab::pos(sentence, join = FALSE)
#> $`1`
#> 名詞 助詞 動詞 助詞 名詞 助詞 動詞
#> "陽" "が" "照っ" "て" "鳥" "が" "啼き"
#> 記号 名詞 助詞 名詞 助詞 名詞 助詞
#> " " "あちこち" "の" "楢" "の" "林" "も"
#> 記号 動詞 名詞
#> "、" "けむる" "とき"
#>
#> $`2`
#> 副詞 助詞 動詞 記号 形容詞 名詞 助詞
#> "ぎちぎち" "と" "鳴る" " " "汚い" "掌" "を"
#> 記号 名詞 助詞 副詞 動詞 名詞 助詞
#> "、" "おれ" "は" "これから" "もつ" "こと" "に"
#> 動詞
#> "なる"
## 'format="data.frame"'にすると、戻り値は以下のようなデータフレームになる。
## pos列・subtype列は素性情報の1~2番目(IPA辞書では「品詞」と「品詞細分類1」)、
## analytic列は素性情報の8番目(IPA辞書の「読み」)だが、
## 未知語で推定されない素性だった場合などには'NA_character_'が含まれることがある。
RcppMeCab::pos(sentence, format = "data.frame") %>%
head(16L)
#> doc_id sentence_id token_id token pos subtype analytic
#> 1 1 1 1 陽 名詞 一般 ヒ
#> 2 1 1 2 が 助詞 格助詞 ガ
#> 3 1 1 3 照っ 動詞 自立 テッ
#> 4 1 1 4 て 助詞 接続助詞 テ
#> 5 1 1 5 鳥 名詞 一般 トリ
#> 6 1 1 6 が 助詞 格助詞 ガ
#> 7 1 1 7 啼き 動詞 自立 ナキ
#> 8 1 1 8 記号 空白
#> 9 1 1 9 あちこち 名詞 代名詞 アチコチ
#> 10 1 1 10 の 助詞 連体化 ノ
#> 11 1 1 11 楢 名詞 一般 ナラ
#> 12 1 1 12 の 助詞 連体化 ノ
#> 13 1 1 13 林 名詞 一般 ハヤシ
#> 14 1 1 14 も 助詞 係助詞 モ
#> 15 1 1 15 、 記号 読点 、
#> 16 1 1 16 けむる 動詞 自立 ケムル
いずれの関数についても、sys_dicとuser_dicという引数から任意の辞書を指定できるほか、開発版(v0.0.1.3 or higher?)ではoptionsから次のようにしてシステム辞書を指定することもできます。
options(mecabSysDic = "/home/rstudio-user/.local/mecab-dic/ipadic-utf8")
RcppMeCabはv0.0.1.2までのCRANリリースがありますが、すでにアクティブに開発されていないため、筆者が個人的にforkしたうえで修正したりしています。
RcppMeCabの使用上の注意点
CRANにある最新リリース(2018-07-04)であるv0.0.1.2の注意点として、64bitのWindows環境ではインストールに失敗します。また、CRANリリースには日本語のIPA辞書などを使用時に未知語があると落ちるバグが残っているため、GitHubにある開発版を利用することをおすすめします。
以下は、いずれも筆者のforkについての情報です。
Changes
-
format="data.frame"時のdoc_id列をfactor型にする(v0.0.1.2では見た目は数字だがcharacter型になっている)など、軽微な挙動の修正・リファクタリング。 -
format="data.frame"時に文区切りしてから形態素解析するように変更。- デフォルトでは、MeCab側ではなく、R側で文区切り(
stringi::stri_split_boundaries(type = "sentence")による)します。 -
options(mecabSplit = FALSE)とすることで、この文区切り処理をスキップできます。
- デフォルトでは、MeCab側ではなく、R側で文区切り(
- OS・プラットフォームを問わず、渡したcharacter vectorを
stringi::stri_enc_toutf8でUTF-8に変換するように。 - Windowsでのソースパッケージからのインストールの改善。
-
format="data.frame"時のC++側の処理の高速化。
Limitations
- OS・プラットフォームを問わず、MeCabの辞書はUTF-8でコンパイルしたものを使用する前提なので、Shift-JISなどの辞書を使用することはできません。
RcppParallelのAPIではなく、Intel Threaded Building Blocks(v.4.3)のAPIを直接触っているため、Windows, OSX, Linux, Solaris(x86 only)以外のプラットフォームではposParallelは動きません。
Performance
あくまで目安ですが、夏目漱石「吾輩は猫である」の全文(2258 elements. メモリ上のサイズで700KB~1.1MB程度?)を同じ環境で解析させると、次のようになります。
require(RMeCab)
require(RcppMeCab)
sentences <- ldccr::NekoText ## paithiov909/ldccr
dplyr::glimpse(sentences)
#> chr [1:2258] "吾輩は猫である" "夏目漱石" "一" " 吾輩は猫である。名前はまだ無い。" ...
vec <- iconv(sentences, from = "UTF-8", to = "CP932")
df <- data.frame(text = vec)
tm <- microbenchmark::microbenchmark(
RMeCabC = lapply(vec, function(elem) {
RMeCabC(elem, mecabrc = "/MeCab/ipadic-shiftjis/mecabrc")
}),
RMeCabDF = RMeCabDF(df, 1, mecabrc = "/MeCab/ipadic-shiftjis/mecabrc"),
pos = pos(sentences),
posParallel = posParallel(sentences),
times = 10L
)
summary(tm)
#> expr min lq mean median uq max neval
#> 1 RMeCabC 7197.2222 7296.917 7369.802 7341.859 7400.890 7680.760 10
#> 2 RMeCabDF 7643.6918 7696.169 7787.620 7728.074 7769.400 8301.763 10
#> 3 pos 1355.6821 1392.607 1442.339 1397.141 1448.497 1693.051 10
#> 4 posParallel 996.5137 1008.699 1028.882 1014.281 1035.060 1144.857 10
ggplot2::autoplot(tm)
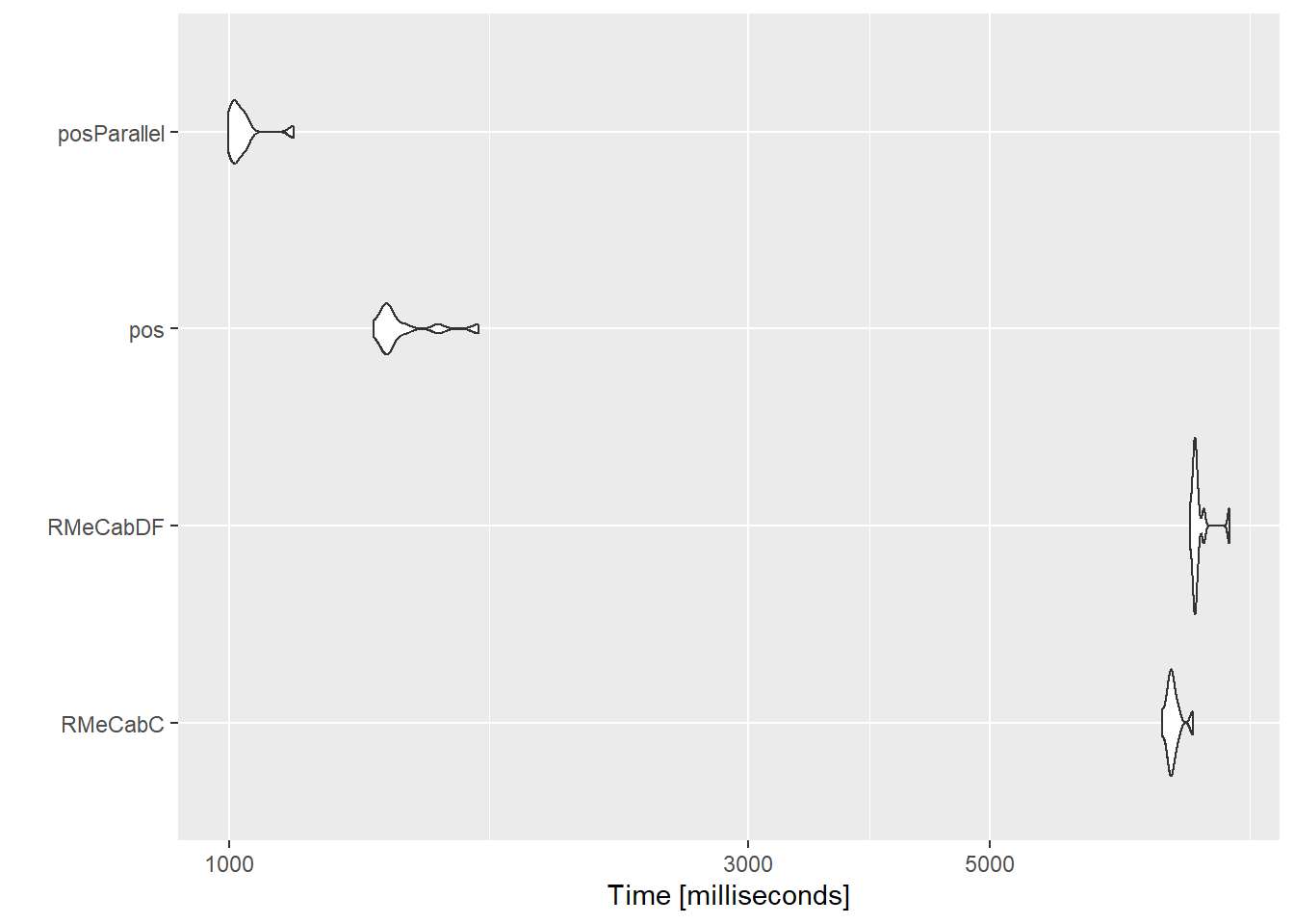
従来のRcppMeCabについてはRMeCabの同等の処理のほうが速いケースがありましたが、MeCabそのものの解析速度には差はないため、RパッケージからMeCabを利用する際にはC/C++部分の書き方によってパフォーマンスに差が出ます。筆者のforkではそのあたりはある程度リファクタリングされているため、単純に文字列ベクトルを形態素解析するかぎりではRcppMeCabのほうが速いです。
RcppMeCabのインストール
筆者がメンテナンスしているforkのRcppMeCabは次のようにしてインストールできます。
Sys.setenv(MECAB_DEFAULT_RC = "/fullpath/to/your/mecabrc") # if necessary
remotes::install_github("paithiov909/rcppmecab-fork")
このforkはgibasaのラッパーに変更したため、パッケージのインストール時にMeCabそのものは必要ありません。一方で、ビルド時にmecabrcへのフルパスを環境変数として指定しているため、インストール後に正常に動作させるためにはmecabrcがあらかじめ配置されている必要があります。MeCabのインストール時にインストール先を変更している場合などは、MECAB_DEFAULT_RC環境変数を指定したうえで、ソースからパッケージをインストールするようにしてください。
Discussion