下書き|MLBotに必要なシステム開発は生成AIにやらせよう
ほっほっほ
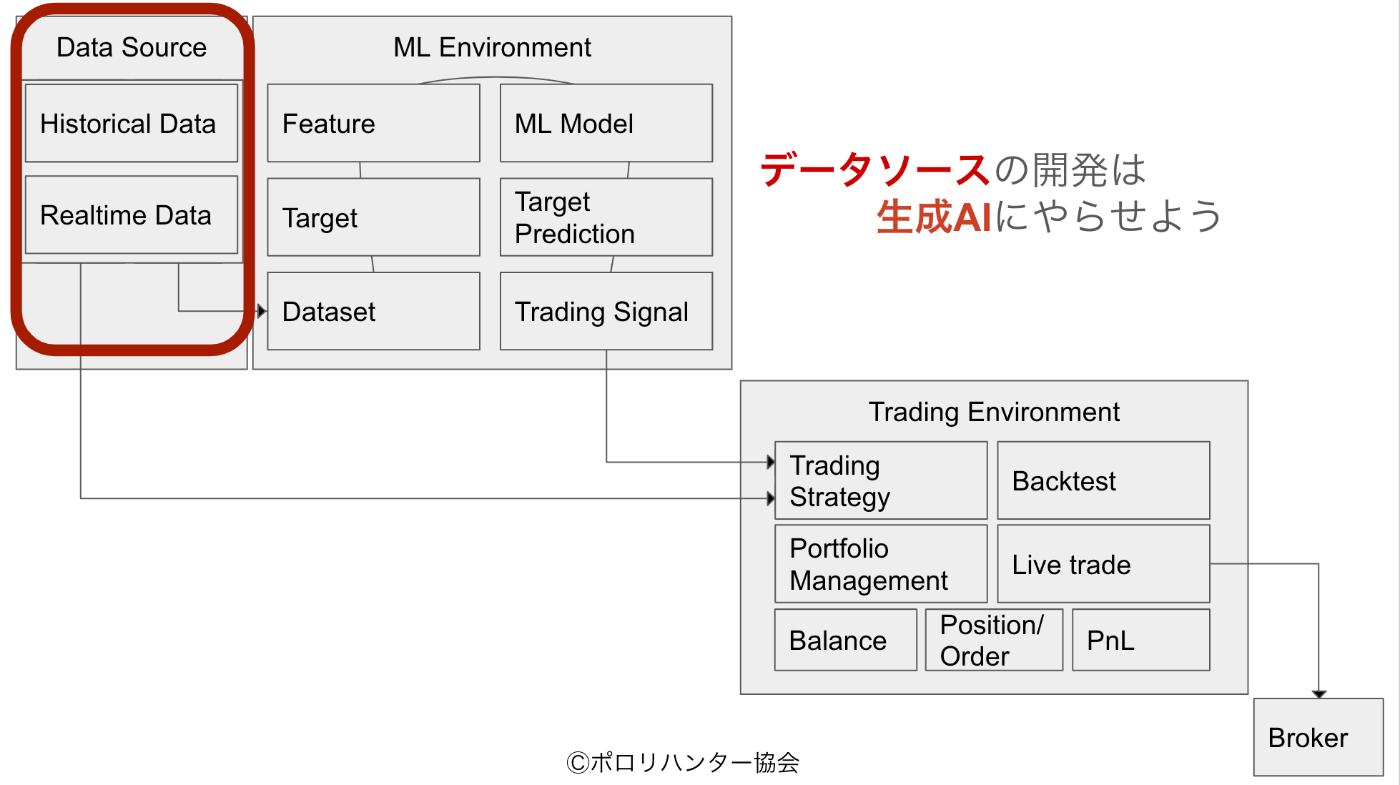
FXトレーディングシステムにおけるデータソースの実装
FXトレーディングシステムを構築する上で、データソースは最も重要な基盤の一つである。本章では、データソースの実装に必要な要素と、その具体的なアプローチについて解説する。
目次
システムの責務
データソース部分の主な責務は大きく3つに分類される。
データの取得と保管
市場データを収集し、適切なフォーマットで保存する。この過程では、データの品質管理も重要な責務となる。異常値の検出や、データの整合性チェックなどが含まれる。
データの提供
システムの他の部分、特にMLEnvironmentに対して、必要なフォーマットでデータを提供する。これには、バッチ処理での提供とリアルタイムストリーミングの両方が含まれる。
エラー検知と回復
接続断が発生した場合の再接続処理や、データ異常の検知、システム全体の状態監視などが含まれる。
データソースの種類と特徴
FXのデータソースは大きく「ヒストリカルデータ」と「リアルタイムデータ」に分類される。
ヒストリカルデータ
ヒストリカルデータには主に3種類ある。
Tickデータ
最も詳細なデータである「Tickデータ」は、個々の取引の情報を含み、最も細かい粒度で市場の動きを捉えることが可能である。高頻度取引や市場微細構造の分析に適しているが、データ量が膨大になるため適切な管理が必要である。
OHLCVデータ
「OHLCVデータ」は、一定期間の始値(Open)、高値(High)、安値(Low)、終値(Close)、取引量(Volume)をまとめたものである。テクニカル分析や一般的なトレード戦略の開発に広く使用されている。Tickデータに比べてデータ量が少なく、扱いやすい特徴がある。
板情報(Order Book)データ
「板情報(Order Book)データ」は、各価格帯における売り注文と買い注文の数量を示すデータである。市場の需給状況を把握するために使用されるが、更新頻度が非常に高く、データ量も多いため適切な管理が求められる。
リアルタイムデータ
リアルタイムデータには主に2種類ある。
ストリーミング価格
「ストリーミング価格」は、最新の価格情報をリアルタイムで取得するものである。一般的にWebSocketを使用して実装され、レイテンシーと接続の安定性が重要な考慮点となる。
リアルタイム板情報
「リアルタイム板情報」は、板情報のリアルタイムな更新を提供するものである。高頻度取引や市場メイク戦略に必要不可欠であるが、更新頻度が非常に高いため、効率的な処理が求められる。
有力なデータソース候補
FXのデータソースとして、以下の選択肢がある。
ブローカー/取引所API
代表的なものとして、OANDAやMetaTrader5のAPIがある。これらは直接取引も可能なため、バックテストと実取引の一貫性を保ちやすい利点がある。また、公式APIであるため信頼性も高い。
データプロバイダー
- Dukascopy: 高品質なヒストリカルデータを無料で提供しているプロバイダーとして知られる。Tickデータレベルの詳細なデータも取得可能である。
- TrueFX: 高品質な無料FXデータを提供しており、特にTickデータの品質が高いことで知られる。
実装上の重要な考慮事項
データソースを実装する際は、以下の点に特に注意を払う必要がある。
レイテンシー管理
データ取得の遅延は、トレーディングシステムのパフォーマンスに直接影響を与える。リアルタイムデータの取得遅延を監視し、必要に応じて最適化を行うことが重要である。
データ品質管理
異常値の検出と除去、プライスチェック、ギャップの検出など、データの品質を維持するための仕組みが必要である。特に、リアルタイムデータでは、即座にこれらのチェックを行う必要がある。
スケーラビリティ
システムの成長に伴い、データ量も増加する。分散処理への対応や負荷分散、効率的なキャッシュ戦略など、スケーラビリティを考慮した設計が重要である。
コスト管理
データの保存にかかるストレージコスト、APIの使用料、ネットワーク帯域の使用料など、運用コストを適切に管理する必要がある。特に、Tickデータを扱う場合はデータ量が膨大になるため、コスト管理は重要な課題となる。
以上のように、FXトレーディングシステムのデータソース実装には多くの考慮点が存在する。これらを適切に設計・実装することで、安定的で信頼性の高いシステムの基盤を構築できる。

抽象化されたデータソースクライアントの実装は、将来のデータプロバイダーの変更に対する柔軟性を高める重要なアプローチである。この設計について詳しく解説する。
データソースクライアントの設計と実装
基本設計の考え方
データソースクライアントは、異なるデータプロバイダーに対する統一的なインターフェースを提供。これにより、システムの他の部分に影響を与えることなく、データプロバイダーを変更できる。
基底クラスの定義
from abc import ABC, abstractmethod
from typing import Callable, Optional
from datetime import datetime
import pandas as pd
class BaseDataSourceClient(ABC):
"""データソースクライアントの基底クラス"""
@abstractmethod
def connect(self):
"""基本的な接続処理"""
pass
@abstractmethod
def ws_connect(self, on_data: Callable, on_error: Callable):
"""WebSocket接続処理"""
pass
@abstractmethod
def get_data(self, start_date: str, end_date: str) -> pd.DataFrame:
"""ヒストリカルデータ取得"""
pass
===
具体的な実装例
class DataSourceClient:
"""データソースクライアントの実装"""
def __init__(self,
provider: str,
symbol: str,
granularity: str):
self.provider = self._get_provider(provider)
self.symbol = symbol
self.granularity = granularity
self.client = None
def _get_provider(self, provider_name: str):
"""プロバイダーの初期化"""
providers = {
'Dukascopy': DukascopyProvider,
'OANDA': OandaProvider,
'MetaTrader5': MT5Provider
}
if provider_name not in providers:
raise ValueError(f"Unsupported provider: {provider_name}")
return providers[provider_name]()
def connect(self):
"""基本接続の確立"""
return self.provider.connect(
symbol=self.symbol,
granularity=self.granularity
)
def ws_connect(self, on_data: Callable, on_error: Callable):
"""WebSocket接続の確立"""
return self.provider.ws_connect(
symbol=self.symbol,
granularity=self.granularity,
on_data=on_data,
on_error=on_error
)
def get_data(self,
start_date: str,
end_date: str) -> pd.DataFrame:
"""ヒストリカルデータの取得"""
return self.provider.get_data(
symbol=self.symbol,
start_date=start_date,
end_date=end_date,
granularity=self.granularity
)
===
プロバイダー固有の実装
class DukascopyProvider(BaseDataSourceClient):
"""Dukascopy固有の実装"""
def connect(self, symbol: str, granularity: str):
# Dukascopy固有の接続処理
pass
def ws_connect(self,
symbol: str,
granularity: str,
on_data: Callable,
on_error: Callable):
# Dukascopy固有のWebSocket接続処理
pass
def get_data(self,
symbol: str,
start_date: str,
end_date: str,
granularity: str) -> pd.DataFrame:
# Dukascopy固有のデータ取得処理
pass
===
利用上の利点
このような設計には、以下のような利点がある:
プロバイダーの交換が容易
# Dukascopyの場合
client = DataSourceClient(provider='Dukascopy', symbol='EURUSD', granularity='1min')
# OANDAに変更する場合
client = DataSourceClient(provider='OANDA', symbol='EURUSD', granularity='1min')
共通のエラーハンドリング
def on_error(error):
if isinstance(error, ConnectionError):
# 再接続処理
pass
elif isinstance(error, DataError):
# データエラー処理
pass
データ形式の標準化
def get_data(self, start_date: str, end_date: str) -> pd.DataFrame:
# プロバイダー固有のデータを標準形式に変換
raw_data = self.provider.get_raw_data(start_date, end_date)
return self._standardize_data(raw_data)
設定の柔軟性
必要に応じて、プロバイダー固有の設定も可能:
class DataSourceClient:
def __init__(self,
provider: str,
symbol: str,
granularity: str,
**provider_settings):
self.provider = self._get_provider(
provider,
**provider_settings
)
# ...
# 使用例
client = DataSourceClient(
provider='Dukascopy',
symbol='EURUSD',
granularity='1min',
api_key='your-api-key',
timeout=30
)
このような薄いクライアントの実装により、システムの保守性が向上し、将来的な変更にも柔軟に対応できるようになる。また、新しいデータプロバイダーを追加する際も、既存のコードに影響を与えることなく拡張が可能である。
出所:https://github.com/ismailfer/dukascopy-api-websocket/blob/main/README.md
DukascopyProviderの実装
概要
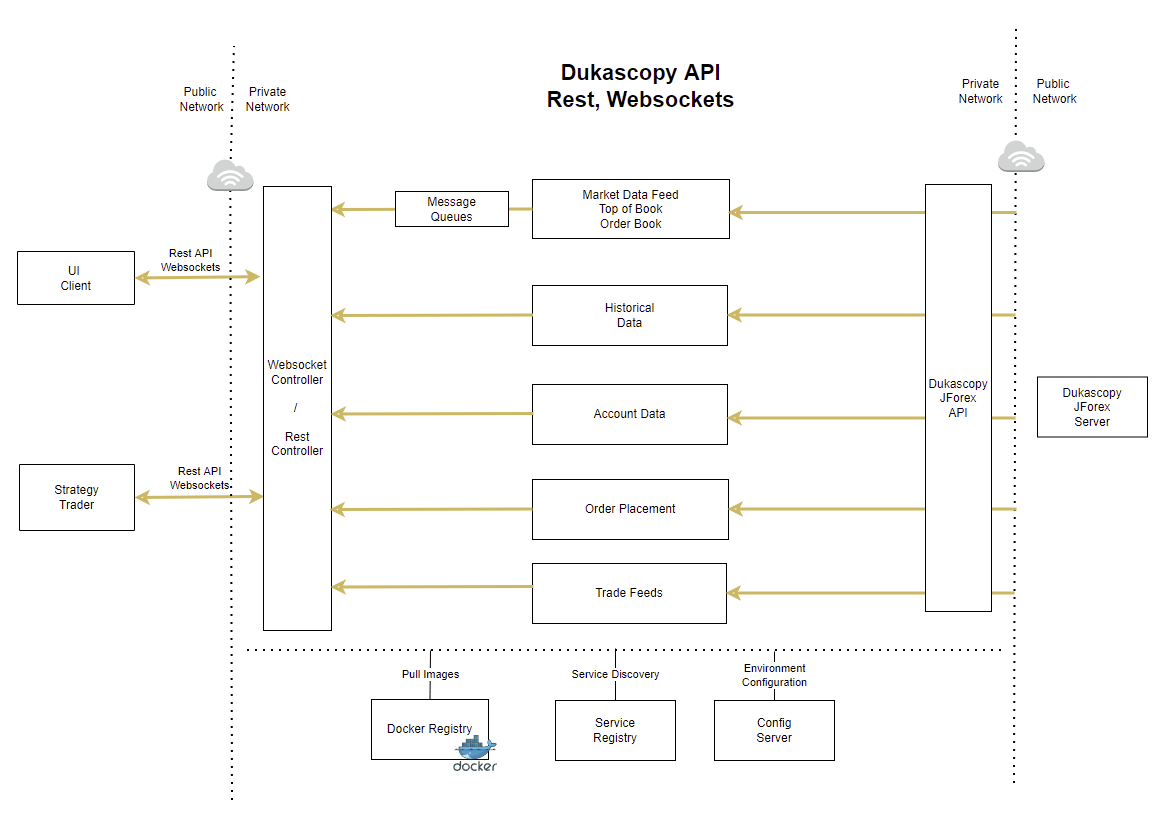
DukascopyのJForex SDKはJavaで実装されており、MLやトレーディングでよく利用されるPythonからの利用には制約がある。しかし、dukascopy-api-websocketプロジェクトを利用することで、REST/WebSocket APIを通じて任意の言語からDukascopyのデータにアクセスすることが可能となる。
dukascopy-api-websocketの特徴
このプロジェクトは以下の機能を提供する:
- REST APIによる簡単なリクエスト/レスポンス通信
- WebSocketによるリアルタイムデータ配信
- JForexプラットフォームとの自動接続管理
- 価格データ、オーダーブックデータ、アカウントデータの取得
- ヒストリカルデータの取得
- 注文の発注機能
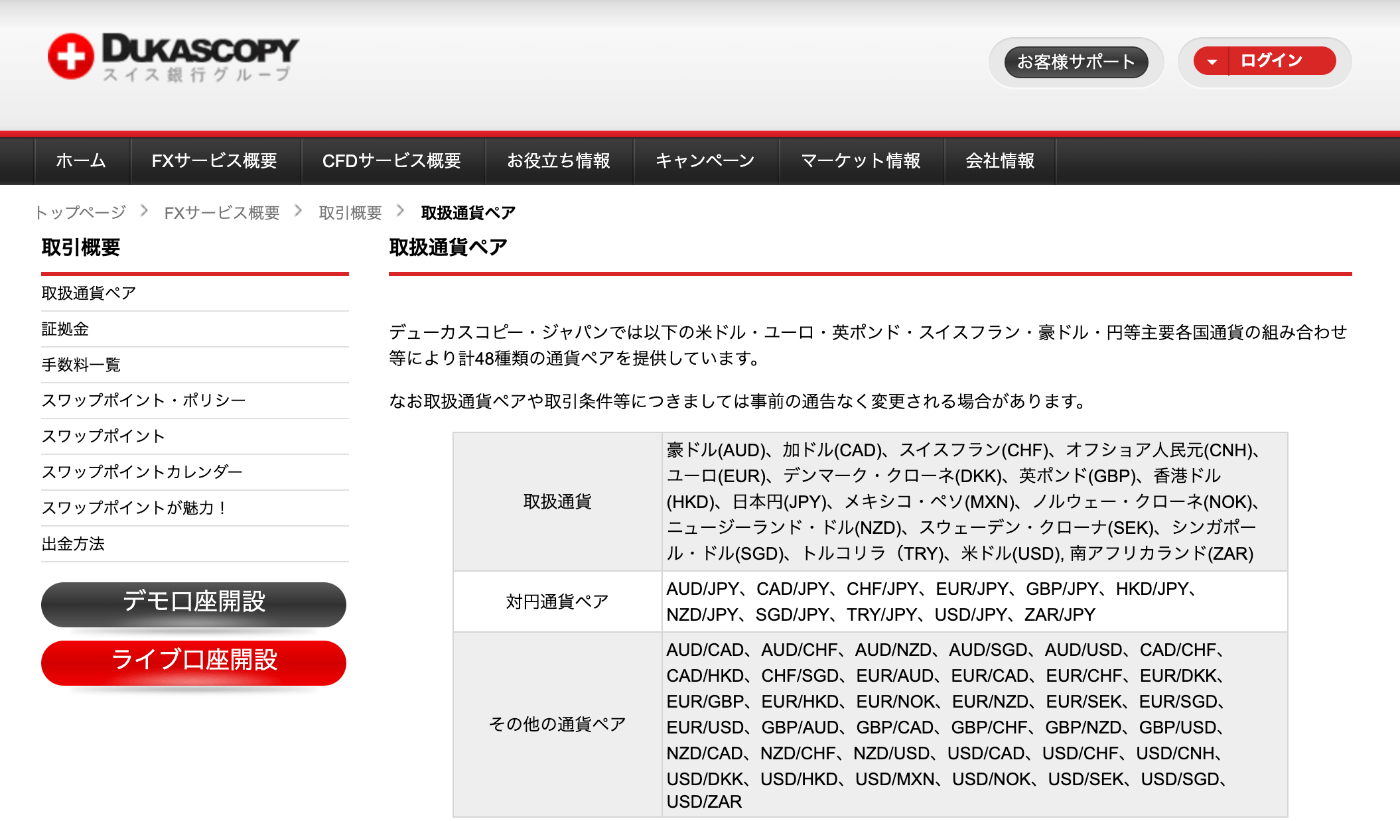
データ取得可能な通貨ペアおよび商品CFD
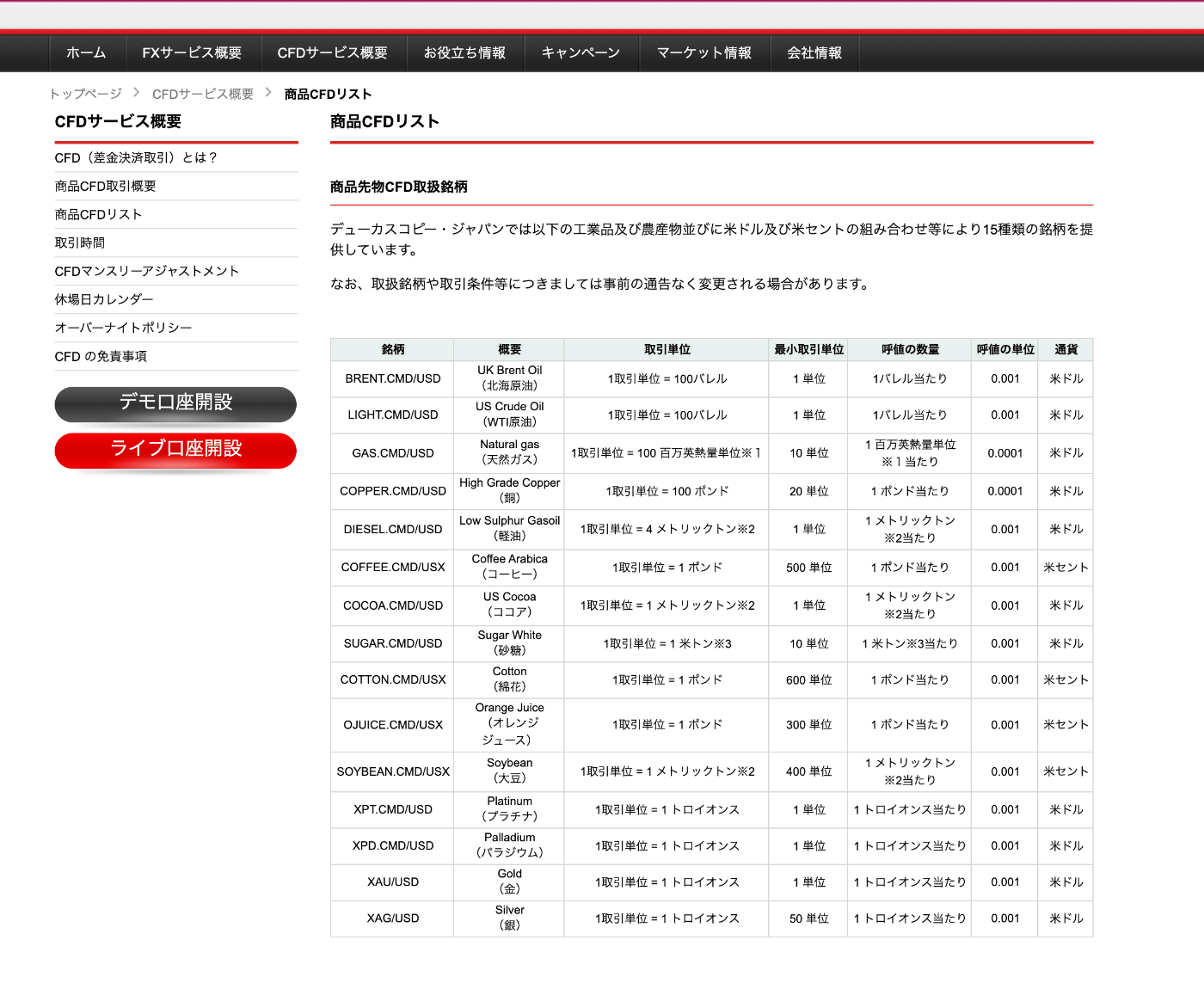
DukascopyProviderの実装方針
このAPIを利用して、以下のようにDukascopyProviderを実装していく:
-
接続管理:
- WebSocket接続の確立と維持
- 接続断の検知と再接続処理
-
データ取得:
- リアルタイムデータの購読
- ヒストリカルデータの取得
- データ形式の標準化
-
エラーハンドリング:
- 接続エラーの処理
- データ異常の検知
実装例
class DukascopyProvider(BaseDataSourceClient):
def __init__(self, host="localhost", rest_port=7080, ws_port=7081):
self.rest_base_url = f"http://{host}:{rest_port}/api/v1"
self.ws_base_url = f"ws://{host}:{ws_port}/ticker"
self.ws = None
self.connected = False
def connect(self):
"""REST APIの接続確認"""
# ヘルスチェックなどの実装
def ws_connect(self, symbol: str, on_data: Callable, on_error: Callable):
"""WebSocket接続の確立"""
url = f"{self.ws_base_url}?topOfBook=true&instIDs={symbol}"
# WebSocket接続の実装
def get_data(self, symbol: str, start_date: str, end_date: str,
granularity: str) -> pd.DataFrame:
"""ヒストリカルデータの取得"""
url = f"{self.rest_base_url}/history"
params = {
"instID": symbol,
"timeFrame": granularity,
"from": start_date,
"to": end_date
}
# REST APIを使用したデータ取得の実装
今後の実装課題
-
データ形式の変換:
- Dukascopy固有のデータ形式を標準形式に変換する処理の実装
- タイムスタンプの統一的な処理
-
エラーハンドリングの強化:
- 各種エラーケースへの対応
- リトライロジックの実装
-
パフォーマンス最適化:
- データバッファリングの実装
- 接続管理の効率化
参考資料
dukascopy-api-websocketをECSに立てて疎通確認完了
from abc import ABC, abstractmethod
from typing import Callable, Optional, Dict, Any
from datetime import datetime
import pandas as pd
from enum import Enum, auto
import requests
import json
import pandas as pd
class DataSourceError(Exception):
"""データソース関連の基本例外クラス"""
pass
class ConnectionError(DataSourceError):
"""接続エラー"""
pass
class DataError(DataSourceError):
"""データ取得エラー"""
pass
class Provider(Enum):
"""サポートされているプロバイダーの列挙型"""
DUKASCOPY = auto()
OANDA = auto()
MT5 = auto()
class BaseDataSourceClient(ABC):
"""データソースクライアントの基底クラス"""
@abstractmethod
def connect(self, symbol: str, granularity: str) -> None:
"""基本的な接続処理"""
pass
@abstractmethod
def ws_connect(self,
symbol: str,
granularity: str,
on_data: Callable[[Dict[str, Any]], None],
on_error: Callable[[Exception], None]) -> None:
"""WebSocket接続処理"""
pass
@abstractmethod
def get_data(self,
symbol: str,
start_date: str,
end_date: str,
granularity: str) -> pd.DataFrame:
"""ヒストリカルデータ取得"""
pass
class DataSourceClient:
"""データソースクライアントのファクトリークラス"""
def __init__(self,
provider: str,
symbol: str,
granularity: str,
**provider_settings):
self.provider = self._get_provider(provider, **provider_settings)
self.symbol = symbol
self.granularity = granularity
def _get_provider(self, provider_name: str, **settings) -> BaseDataSourceClient:
"""プロバイダーの初期化"""
try:
provider = Provider[provider_name.upper()]
except KeyError:
raise ValueError(f"Unsupported provider: {provider_name}")
providers = {
Provider.DUKASCOPY: lambda: DukascopyProvider(**settings),
Provider.OANDA: lambda: OandaProvider(**settings),
Provider.MT5: lambda: MT5Provider(**settings)
}
return providers[provider]()
def connect(self) -> None:
"""基本接続の確立"""
try:
self.provider.connect(
symbol=self.symbol,
granularity=self.granularity
)
except Exception as e:
raise ConnectionError(f"Failed to connect: {str(e)}")
def ws_connect(self,
on_data: Callable[[Dict[str, Any]], None],
on_error: Callable[[Exception], None]) -> None:
"""WebSocket接続の確立"""
try:
self.provider.ws_connect(
symbol=self.symbol,
granularity=self.granularity,
on_data=on_data,
on_error=on_error
)
except Exception as e:
raise ConnectionError(f"Failed to establish WebSocket connection: {str(e)}")
def get_data(self,
start_date: str,
end_date: str) -> pd.DataFrame:
"""ヒストリカルデータの取得"""
try:
return self.provider.get_data(
symbol=self.symbol,
start_date=start_date,
end_date=end_date,
granularity=self.granularity
)
except Exception as e:
raise DataError(f"Failed to fetch data: {str(e)}")
class DukascopyProvider(BaseDataSourceClient):
"""Dukascopy固有の実装"""
def __init__(self,
host: str = "xxxxx",
rest_port: int = 443,
ws_port: int = 445,
**kwargs):
self.rest_base_url = f"https://{host}:{rest_port}/api/v1"
self.ws_base_url = f"wss://{host}:{ws_port}/ticker"
self.ws = None
self.connected = False
self.settings = kwargs
def connect(self):
# Implement the connection logic here
pass
def ws_connect(self):
# Implement the WebSocket connection logic here
pass
def get_data(self, symbol: str, start_date: str, end_date: str, granularity: str) -> pd.DataFrame:
start_date_ms = int(datetime.strptime(start_date, "%Y-%m-%d").timestamp() * 1000)
end_date_ms = int(datetime.strptime(end_date, "%Y-%m-%d").timestamp() * 1000)
url = f"{self.rest_base_url}/history"
params = {
"instID": symbol,
"timeFrame": granularity.upper(),
"from": start_date_ms,
"to": end_date_ms
}
response = requests.get(url, params=params)
data = json.loads(response.text)
return pd.DataFrame(data)
if __name__ == "__main__":
# Dukascopyの場合
client = DataSourceClient(provider='Dukascopy', symbol='USDJPY', granularity='1min')
df = client.get_data(start_date='2024-02-01', end_date='2024-02-04')
print(df.head())
phunt_api % python datasource.py
open high low close volume spread timestamp
0 146.647 146.668 146.602 146.649 141194000.0 0.7 1706713200000
1 146.647 146.647 146.576 146.615 146041000.0 0.6 1706713260000
2 146.615 146.615 146.491 146.504 116137000.0 0.5 1706713320000
3 146.505 146.627 146.494 146.622 118621000.0 0.9 1706713380000
4 146.623 146.751 146.618 146.724 168592000.0 0.8 1706713440000

機械学習における特徴量エンジニアリングの課題と解決策
現状の課題
機械学習プロジェクトにおいて、特徴量の加工ロジックおよび加工済データの管理が分散化しやすく、実験の再現性や知見の共有に支障をきたすケースが多い。特に「同一の特徴量セットに対して異なる目的変数で学習を行う」といったシナリオにおいて、開発効率の低下を招いている。
解決の方向性
これらの課題に対し、Feature Store と呼ばれるインフラストラクチャの導入が有効である。Feature Store は特徴量の一元管理を実現し、以下の利点をもたらす:
- 特徴量のバージョン管理
- 実験の再現性向上
- チーム間でのナレッジ共有の促進
- 計算リソースの効率的活用
代表的なオープンソースソリューションとして、feast が広く採用されている。
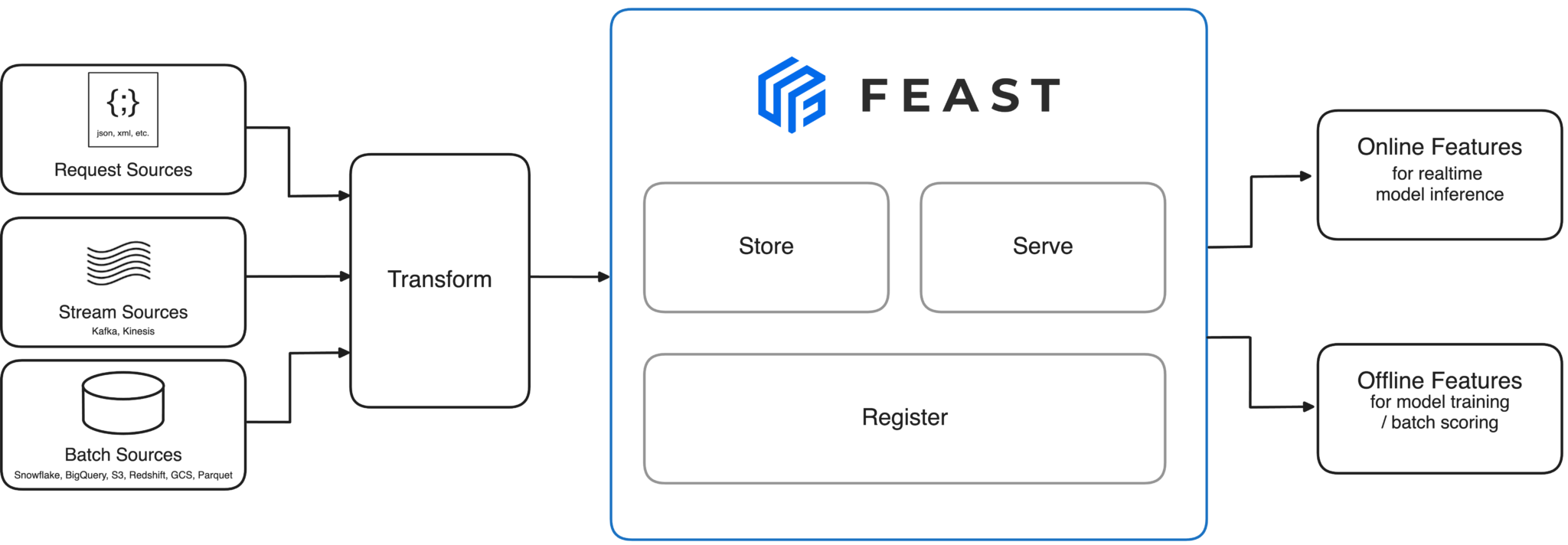
出所:https://feast.dev/
P-Hunter向け実装方針
P-Hunter協会員の利便性を考慮し、feast の機能を抽象化した専用Python パッケージを提供する。
これにより、協会員は低レベルの実装詳細を意識することなく、直感的なインターフェースでデータ加工ロジックの登録・参照が可能となる。なお、feastには現在のところ加工ロジックの登録機能はないようなので別途機能追加する。
パッケージ利用イメージ:
def create_target(api):
# feast に登録済みの offline dataset を取得
df = api.get_dataset('USDJPY_1MIN_2023')
# 10分後リターンを算出
df['USDJPY_next_10min_return'] = df['close'].shift(-10) / df['close'] - 1
return df[['timestamp', 'USDJPY_next_10min_return']]
# 本番データでcodeを実際に実行し、生成したParquetファイルを feast で登録
api.submit_target(name='USDJPY_next_10min_return', code=create_target)
def create_feature(api):
df = api.get_dataset('USDJPY_1MIN_2023')
# 特徴量エンジニアリングロジックの実装
df['feature_1'] = #XXXX
return df[['timestamp', 'feature_1']]
# 本番データでcodeを実際に実行し、生成したParquetファイルを feast で登録
api.submit_feature(name='feature_1', code=create_feature)