Cloudflare で RAG の使いところを体感


はじめに
前に RAG の素振りはしましたが、このスケベ記事を読んだんで、自作ツールに使ってみます。
背景
上場企業の Web サイトの配信場所を調べるツールに Workers と D1 使ってます。
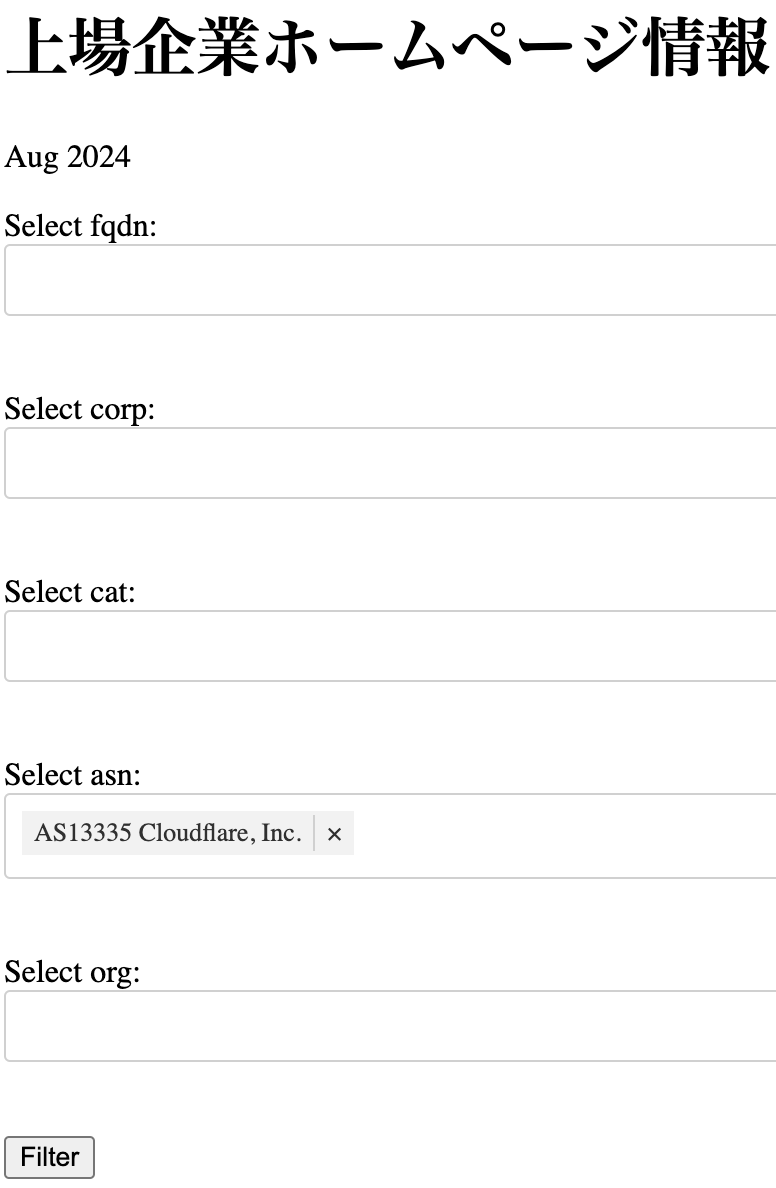
たとえば AS いれると D1 から抜いてきます。

追加でこの辺を知りたいと思ってます。
- 企業の売上高と配信場所の関係
- AS を持たない CMS や WAF 事業者から配信している企業
方針
思いつくのは DB への情報追加やクエリーの追加です。
- 企業の売上情報
- CNAME に事業者名がでてくることが多いので、事業者特有の文字列で検索するクエリー
結果も予想がつきます。超正確に答えてくれるでしょう。
でも、追加情報を調べるのが、面倒。
一方、 DB の情報からテキストを作ってベクトルしておけば、RAG LLM の力でイイ感じの回答をくれるんじゃないか、と期待。でも、正確さはどうなんだろ、と不安。
導入
- DB から会社ごとにカラムを取って、切り貼りでテキスト文にし、TSV に書く(3800社)
👉 {A社} の企業サイト {http://...} は {Cloudfront} に...phrase = f"A Japanse company called \"{corp}\" which is in \"{cat}\" industry uses \"{asn}, {org}\" for their corporate website \"{url}\", and also the domain \"{fqdn}\" is routed to IP address \"{ip}\" and DNS CNAME is {cname}." - TSV を Sqlite3 のデータにする
👉 pandas (python) など - データを SQL にし、wranglar で D1 にテキストを書く
👉man - Worker で D1 からテキストを読み、エンベッディングな AI モデルでベクトルにして、Vectorize DB に書く
👉public beta での制限(随時更新)
以上で準備が終わり、あとはスケベ記事にあるように、
- 質問文がリクエストされる
- Worker で質問文からベクトルを出して、Vectorize DB から近似ベクトル の ID を得る
- ID を D1 に投げ、テキストを得たら、質問文に付帯して テキストジェネレーションな AI モデルに投げて、レスポンスを得る
結果
DB にクエリするときのようなイチゼロの回答がくるわけでなく、また、気まぐれでした。
正確さを増そうと、情報を多めに処理させようとすると Workers などの制限に達したりもありました。
いずれも当然のことかもしれません。
今回は正確さも大事なので、腰を上げて DB とクエリーを追加する作戦をとるべきだとわかりました。
ただ、それはそれとして、期待値の半分は達成してます。
CNAME の一部をトリガーに情報を引けましたし、売上情報も追加してくれました。


DB クエリーだけでは得られない情報をもらえるので、活用できそうです。
たとえば、「医薬業界の企業です。Web サイトにどのプロキシーがおすすめか?」
を聞いたところ、D1 から得たその業界でシェアが多い事業者を”控えめに”勧める文章とともに、DB に存在しない CDN/WAF 観点での理由を複数並べてくれました。
そういうところは、実際のユーザーとしては参考になるでしょう。
補足
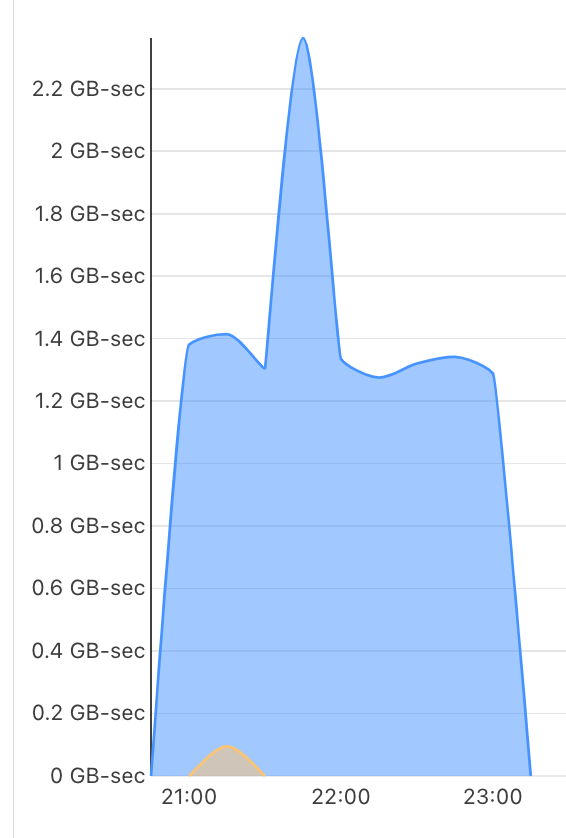
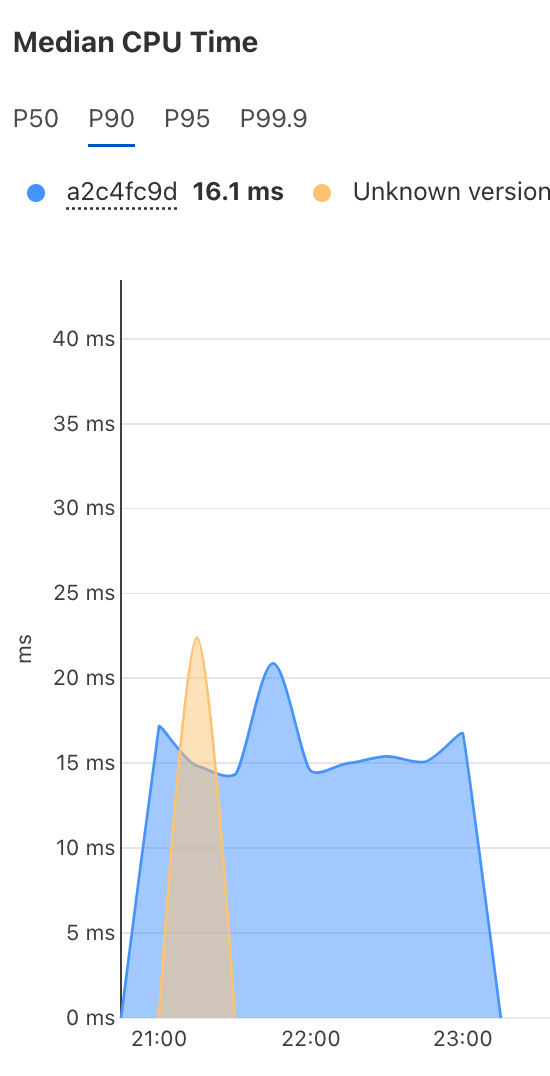
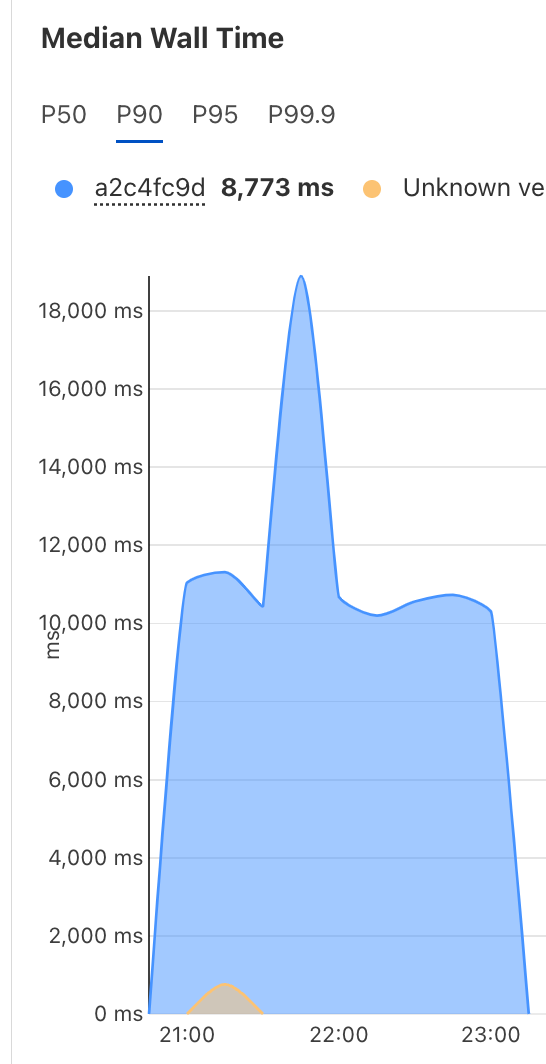
上記 4 (D1 からテキストを読んでエンベッドして Vectorize に書くまで)でのスタッツを参考までに。(public bata だし、状況によって変わると思うので、あくまで現時点での一例で)
Workers Standard。
英語+日本語の文章も入れたので D1 のテーブルには7660行ありました。
一度のリクエストで 5 行処理したので、計 1532 回リクエストされました。
一リクエストで Wall time が 10秒 程度でした。
青をみます。
Discussion