Closed6
dlt(data load tool)のnested dataの雰囲気を掴む
前段
dltではネストされたjsonなどを自動でスキーマを推測して正規化する機能がある
これはAPIなどからデータを取得してDWHにロードする際に便利である
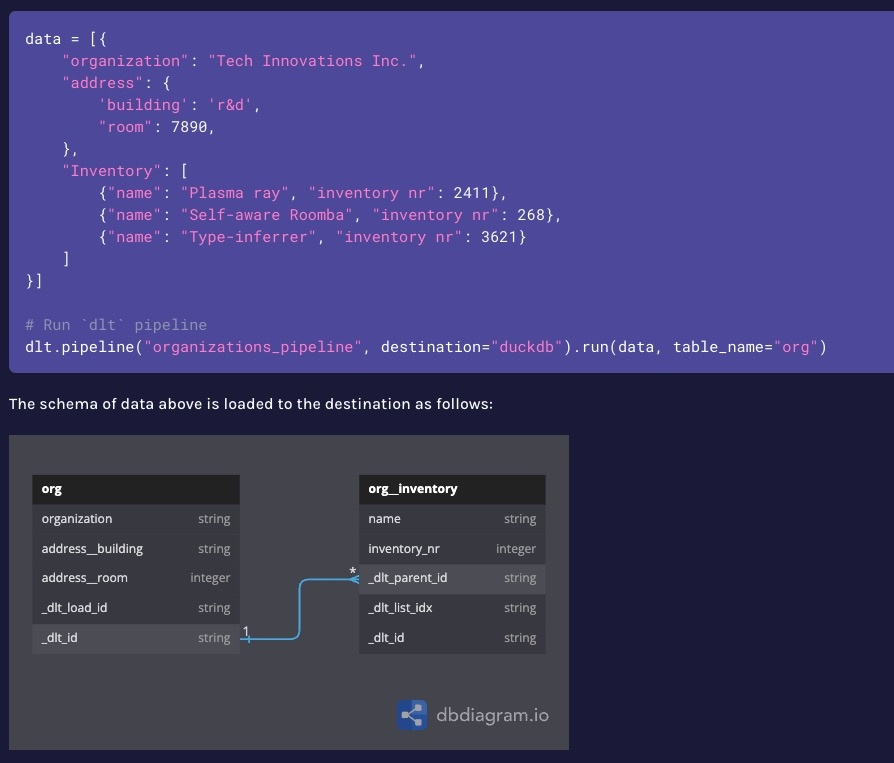
RESAS APIを例にBigQueryに流してみる
RESAS API
内閣府がまとめているオープンデータ APIでもデータを取得することができる
ここでは人口構成のデータを取得してBigQueryにロードしてみる
レスポンス
以下のようなnested json構造
{
"message": null,
"result": {
"boundaryYear": 2020,
"data": [{
"label": "総人口",
"data": [{
"year": 1980,
"value": 12817
}, {
"year": 1985,
"value": 12707
},{
// 略
}]
}, {
"label": "年少人口",
"data": [{
"year": 1980,
"value": 2906,
"rate": 22.67
}, {
"year": 1985,
"value": 2769,
"rate": 21.79
}, {
// 略
}]
}, {
"label": "生産年齢人口",
"data": [{
"year": 1980,
"value": 8360,
"rate": 65.23
}, {
"year": 1985,
"value": 8236,
"rate": 64.81
}, {
// 略
}]
}, {
"label": "老年人口",
"data": [{
"year": 1980,
"value": 1550,
"rate": 12.09
}, {
"year": 1985,
"value": 1702,
"rate": 13.39
}, {
//略
}]
}]
}
}
データ取得とロード
# 概略のみのコード
@dlt.resource()
def get_population_composition_job():
api_client = RESASAPIClient(api_key=API_KEY)
response = api_client.fetch_data()
yield response
def load_population_composition_pipeline():
pipeline = dlt.pipeline(
pipeline_name="population_composition",
destination="bigquery",
dataset_name=dlt.config["destination.bigquery.dataset_name"],
)
load_info = pipeline.run(get_population_composition_job)
if __name__ == "__main__":
get_population_composition_pipeline()
結果
population_composition テーブル (サンプルとして2市町村のみ)

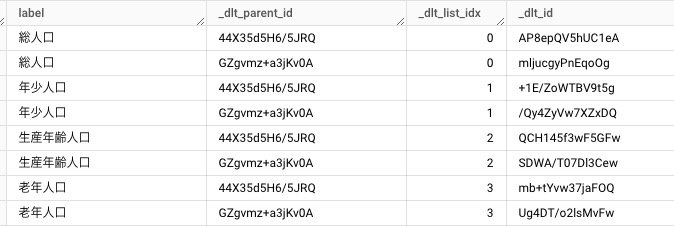
population_composition__dataテーブル
population_composition__data__dataテーブル
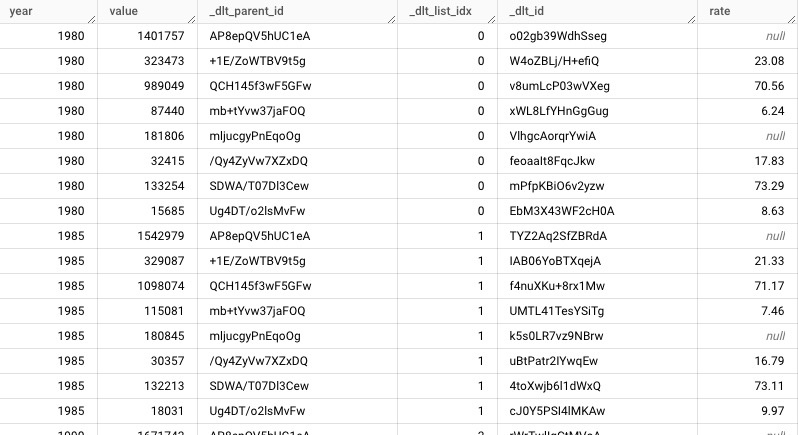
ネストの数だけテーブルが作成されており_dlt_idと_dlt_parent_idをキーにjoinすればフラットな形にも展開できる
まとめ
スキーマ推論がかなり協力なので、レスポンスの形をあまり気にせずにロードできるのは割と強みだと思いました。
もちろんjsonをそのままloadして後でSQLで整理する方法も考えられます。テーブルがたくさんできてしまうのを抑えたい場合はこちらの方がいいでしょう。
dltではjsonのままのロードや正規化の深さをコントロールする場合は自分でスキーマを指定することでできるようです。
スクリプト全文
このスクラップは2024/08/15にクローズされました