dltでウェザーニュースの花粉APIからデータをロードする
dltでウェザーニュースの花粉APIからデータをロードする
概要
私は花粉症です。
それはさておき、花粉の悲惨飛散データは素敵なことにウェザーニューズさんの方でこちらで公開されており、
無料でダウンロードすることができます。
※ 「ウェザーニュースのポールンロボで観測されたデータであることを明示」する必要があるのと、営利・商用や公開目的の場合は連絡が必要とのこと
本記事では、APIからデータを取得しDuckDBにロードするタスクをdltを使って行ってみます。dltはAirbyteやFivetranのようにビルトインのコネクターを持ちますが、REST APIからデータを取得してロードするような場合にも使えるのか?を試します。
環境構築
本記事執筆時点の環境とdltなどの導入
Ubuntu 22.04.4 LTS
Python 3.11.5
rye 0.34.0
uv enabled: true
Pythonの管理にrye+uvを使ってますがなんでも良いです 以降説明上はpip表記です
dlt導入とプロジェクト構成
pip install "dlt[duckdb]" pandas
dlt --version
# dlt 0.4.9
(Optional) dlt init rest_api duckdb でプロジェクトの雛形を作ることができます。その場合不要なコードは削除してください。
以下のように手動で作成しても問題ないです。
project_root
├── .dlt
│ └── config.toml
├── data
│ └── city_code.csv ## 後述
└── pollen_opendata.py # メインスクリプト
dlt initコマンドで生成した場合、.dlt/config.tomlは以下のようになっており、シークレット以外の変数などを格納したり、設定を変更したりできます。
dlthub_telemetry = trueだと匿名情報を送信するとのことなので気になる人はfalseにしましょう。
# put your configuration values here
[runtime]
log_level="WARNING" # the system log level of dlt
# use the dlthub_telemetry setting to enable/disable anonymous usage data reporting, see https://dlthub.com/docs/telemetry
dlthub_telemetry = true
APIからデータ取得部分の実装
エンドポイントのパラメータはcitycode, start, endの3つを指定する必要があります
citycode(市町村コード)はこちらに記載があったので、pd.read_htmlなどでcsvにしてdata/city_code.csvとして置いておきます。
まずは普通にエンドポイントを叩く関数を定義します。
※ 例は全ての市町村を叩いてますが、必要な分だけにしたり、for loopは外に出した方がいいです。
def _load_citycode_data():
"""市区町村コードのマスターデータを読み込む"""
path = Path(__file__).parent / "data" / "city_code.csv"
return pd.read_csv(path, dtype=str)
def get_pollen_opendata(start_date: int, end_date:int) -> Iterator[pd.DataFrame]:
city_code_df = _load_citycode_data()
city_codes = city_code_df["標準地域コード"]
for city_code in city_codes:
try:
response = requests.get(
f"https://wxtech.weathernews.com/opendata/v1/pollen?citycode={city_code}&start={start_date}&end={end_date}"
)
response.raise_for_status()
data = pd.read_csv(io.StringIO(response.text))
yield data
except Exception as e:
print(f"Error: {e}")
print(f"city_code: {city_code} is not available")
continue
※※ この時点で適当な値を入れてみて、挙動を確認したりします。
dltを適用しロードする
(重要) list, json, pd.DataFrame, Iteratorなどを返り値にとる関数を@dlt.resourceデコレータで囲うことでdltのリソース(≒テーブル)として認識されます。
デコレータをつけたあとの関数単体でも今まで通り実行などができる&既存の関数にデコレータをつけるだけなので導入が割とラクだと感じました。
@dlt.resource(primary_key=("citycode", "date"), write_disposition="merge")
def get_pollen_opendata(start_date: int, end_date:int) -> Iterator[pd.DataFrame]:
"""以下同じ"""
ここでは主キーを設定し、増分更新を可能にしています。(同時刻、同都市のデータがダブった場合は新しい方で上書き)
実際にロードを行う記述は以下です。
if __name__ == "__main__":
start_date = (datetime.now() - timedelta(days=3)).strftime("%Y%m%d")
end_date = (datetime.now() - timedelta(days=1)).strftime("%Y%m%d")
# ここで宛先(duckdbのパス、データセット名を指定)
pipeline = dlt.pipeline(
pipeline_name="load_pollen_opendata_pipeline",
destination=dlt.destinations.duckdb("data/pollen_opendata.duckdb"),
dataset_name="pollen_opendata",
# full_refresh=True, # 最初のうちは必要に応じて
)
# パイプライン実行
load_info = pipeline.run(
get_pollen_opendata(start_date=date, end_date=date),
)
# pretty print the information on data that was loaded
print(load_info)
python pollen_opendata.py を実行するとduckdbにロードされます。
(番外編)宛先の変更
データのロード先としてローカルのduckdbを指定してましたが、MotherDuckに変更してみましょう
.dlt/secrets.tomlを作成します。(git管理下には入れないように)
[destination.motherduck.credentials]
database = "pollen_opendata_source"
password = "YOUR_TOKEN"
pipeline内のdestinationの設定を変更します。
if __name__ == "__main__":
start_date = (datetime.now() - timedelta(days=3)).strftime("%Y%m%d")
end_date = (datetime.now() - timedelta(days=1)).strftime("%Y%m%d")
# destinationを変更
pipeline = dlt.pipeline(
pipeline_name="load_pollen_opendata_pipeline",
destination="motherduck",
dataset_name="pollen_opendata",
# full_refresh=True, # sample
)
# パイプライン実行
load_info = pipeline.run(
get_pollen_opendata(start_date=date, end_date=date),
)
# pretty print the information on data that was loaded
print(load_info)
同じように実行することでデータがロードされていることを確認
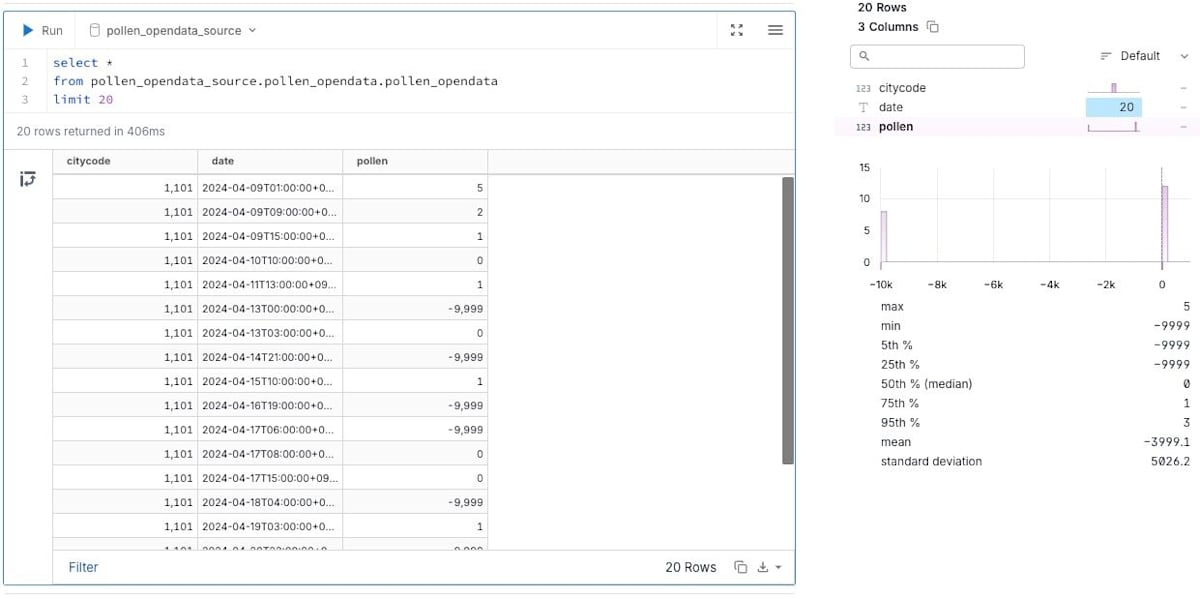
まとめと所感
(まとめ)
- APIからデータを取得し、
@dlt.resourceデコレータをつけてdlt.pipelineで実行してあげるとデータをロードすることができる - 型は推論してくれるので、明示的に書かなくてもよしなにやってくれる(もちろん指定もできる)
(所感)
- 今回、データソースに関しては特にコネクタが無いようなケースを想定してdltを使ってみましたが、既存の関数をそのまま使える点や、ロード先の変更が容易な点が、ミニマムかつ小回りが効きそうで良いなと思いました
- 実はREST APIのデータソースもコネクタ的なものがあるようです(REST API helpers) が、まだ実装途中らしき機能が多かったので今回は普通に実装しました
- REST API helpers
- 割と抽象化されてて、pagenatorにも対応してるとのことなので、今後に期待したい
Discussion