はじめに
おはこんばんちは。
Offers と、Offers MGR を運営している株式会社 overflow のバックエンドエンジニアばばです。
Web サービスを開発している皆様であれば、高度なデータ処理の大変さ・つらさを味わったことはあるかと思います。
たとえば
- グラフ用データを作成するには、API からデータ取得が終わった後に、DWH で集計して、その後バッチ処理かけてごにょごにょ
- 想定してたよりデータ量が多くて、許容時間内に処理が終わらないー
- あの API 、 Rate Limit 厳しいからから並列数制御しないといつまでたっても取得がおわらない・・・
など、悩みはつきません[1]。
上記の悩みが、開発効率性を落とし、技術的負債となってきていることから、Workflow Engine (タスクの実行順序など業務プロセスを自動で管理するソフトウエア) を導入しようという話がチーム内でおこりました。
今回は、Workflow Engine をどのように選定したか、そして、現在導入を進めている Prefect ついてご紹介いたします。
現在のデータ処理基盤のつらみ
弊社のバックエンド技術スタックは Ruby on Rails で統一されており、非同期となる処理も Sidekiq の機能を活用し運用しています。
データの取得・集計などの基盤も、Sidekiq Worker 上でマイクロバッチ処理を実装し、Sidekiq Pro Batches and Callbacks (以下、 Sidekiq Batches) を利用して Workflow を実装しています。
Sidekiq Worker 自体は、API の非同期処理ユースケースからわかるように、分散処理には強く、きめこまやかで柔軟な処理が実装できます。 また、 Rate Limit や DB 負荷の問題に対応する流量制限には、Sidekiq Enterprise の Rate Limiting を活用し制限しています。
Ruby on Rails の資源を利用しつつ、 カジュアルに Workflow を組めるのは大変便利なので重宝していますが、プロダクトに求められる要件の複雑化により、Workflow も複雑化していきました。
その実装を進める上で、様々な痛みが起こるようになりました。痛みの中で一番大きかったものは、 Sidekiq Batches で Workflow を組んだときの可読性の低さでした。
Sideiq Batches での Workflow を組むと可読性が低くなる
Sidekiq Batches は、Batch と呼ばれるグループ化した Worker 群の実行状態を Sidekiq 側で管理し、状態変更(完了、成功、失敗など)で Callbacks を呼び出す仕組みになっています。
この仕組みを利用して、「状態変更の Callbacks 中で次の Batch を作成し、親の Batch の子ジョブとして追加する」ことで依存関係を構築しています。
一方、Workflow は、処理の順番を定義するものであるので、次に何が実行されるかが自明でないと処理を追うことが難しくなります。
GitHub Actions も、Workflow Engine の 1 つであり、YAML で宣言的なわかりやすい構文となっています。
flow1-jobs:
name: flow1
steps:
- run: flow1-task1
- run: flow1-task2
flow2-jobs:
name: flow2
steps:
- run: flow2-task
flow3:
needs: [flow1-jobs, flow2-jobs]
steps:
- run: flow3-task
flow4:
needs: [flow3]
steps:
- run: task4-1
- run: task4-2
ですが、これを Sidekiq Batches で実装すると、Sidekiq Batches の知識がないと到底理解のできないコードになります。
以下に疑似コードを示します。このフローを実装するにも何度か頭が混乱しました。ふぅ。
# Workflow のエントリポイント
def start_workflow(arguments)
overall = Sidekiq::Batch.new
overall.on(:success, 'OverallCallback#finished', arguments)
overall.jobs do
StartWorkflow.perform_async(arguments)
end
end
class StartWorkflow
include Sidekiq::Job
def perform (arguments)
batch.jobs do
step1 = Sidekiq::Batch.new
step1.on(:success, "OverflowCallback#step1_done", arguments)
steps1.jobs do
Flow1Job.perform_async(arguments)
Flow2Job.perform_async(arguments)
end
end
end
end
def OverallCallback
def step1_done(status, options)
overall = Sidekiq::Batch.new(status.parent_bid)
overall.jobs do
batch.jobs do
step2 = Sidekiq::Batch.new
step2.on(:success, "OverflowCallback#step2_done", arguments)
step2.jobs do
Flow3Job.perform_async(arguments)
end
end
end
end
def step2_done(status, options)
overall = Sidekiq::Batch.new(status.parent_bid)
overall.jobs do
batch.jobs do
step3 = Sidekiq::Batch.new
step3.jobs do
Flow4Job.perform_async(arguments)
end
end
end
end
def finished(status, options)
overall = Sidekiq::Batch.new(status.parent_bid)
overall.jobs do
batch.jobs do
step3 = Sidekiq::Batch.new
step3.jobs do
Flow4Job.perform_async(arguments)
end
end
end
end
end
class Flow1Job
include Sidekiq::Job
def perform(arguments)
batch.jobs do
step1 = Sidekiq::Batch.new
step1.on(:success, "Flow1JobCallback#step1_callbacks", arguments)
step1.jobs do
Flow1Task1.perform_async(arguments)
end
end
end
end
class Flow1JobCallback
def step1_callbacks(status, options)
overall = Sidekiq::Batch.new(status.parent_bid)
overall.jobs do
step2 = Sidekiq::Batch.new
step2.jobs do
Flow1Task2.perform_async(arguments)
end
end
end
end
class Flow2Jobs
include Sidekiq::Job
def preform(arguments)
batch.jobs do
step1 = Sidekiq::Batch.new
step1.jos do
Flow2Task.perform_async(arguments)
end
end
end
end
class Flow3Jobs
include Sidekiq::Job
def preform(arguments)
batch.jobs do
step1 = Sidekiq::Batch
step1.on(:sucess, "Flow3JobCallbacks#step1_callbacks", arguments)
step1.jobs do
Flow3Task.perform_async(arguments)
end
end
end
end
class Flow3JobCallback
def step1_callbacks(status, options)
overall = Sidekiq::Batch.new(status.parent_bid)
overall.jobs do
step2 = Sidekiq::Batch.new
step2.jobs do
Flow3Task2.perform_async(options)
end
end
end
end
class Flow4Jobs
include Sidekiq::Job
def preform(arguments)
child = Sidekiq::Batch
child.on(:sucess, "Flow4JobCallbacks#step1_callbacks", arguments)
child.jobs do
Flow4Task1.perform_async(arguments)
end
end
end
class Flow4JobCallback
def step1_callbacks(status, options)
batch = Sidekiq::Batch.new(status.parent_bid)
batch.jobs do
Flow4Task2.perform_async(options)
end
end
end
もっと楽にわかりやすい Workflow を記述したい
このように Sidekiq Batch では、Workflow 自身を実装する必要があり、デバッグにも時間がかかり、少し大きめの機能開発の時間を圧迫しはじめました。
本来であれば、 Workflow の管理は不要で、データ集計ロジックなどプロダクトの価値をあたえるものに時間を注ぐべきです。
そのため、複数の Workflow Engine の導入を検討し、比較することになりました。
Workflow Engine の検討
Workflow Engine には様々なプロダクトがあります。闇雲に試していっても時間がかかるため、選定基準を明確にした上で、候補を絞りこみました。
選定基準
基本的な Workflow Engine の機能要件・性能要件を満たしていることは最低限の条件でした。
- DAG[2] のような、依存関係をもった実行順が管理できること
- スケジュール機能があること
- フロー単位での停止やリトライができること
また、以下のような連携機能を有することも重視しました。
- 自社の技術スタック (特に、 Sidekiq や AWS) と親和性高く連携できるか
- AWS との連携や拡張性が楽で、極力マネージドな構成と Open Source が選べるもの
- Developer EXperience[3] をあげてくれるもの
候補の洗い出し
有限の時間の中から以下をピックアップして検討し、点数をつけて評価しました。
もちろんすべてを実際に使用して評価したのではなく、ドキュメントやブログなどの情報のみにとどめたものがあります。
候補として有力視されたのは以下の 4 つです。
Airflow
Python でフローを記述する
オープンソース
有名なプロダクトで AWS 上にもマネージドサービス (AWS MWAA) として展開されている
エンプラ向け
Digdag
YAML でフローを記述する
オープンソース
Treasure Data 社による。Embulk、Fluentd などとの親和性が高くプラグインによるクラウド対応も充実
小〜中規模向け
Prefect
Python でフローを記述する
オープンソース
後発であり、ML / DataEnginee 向けで、Airflow の不満点を補った作りになっている
小〜中規模向け(エンプラもいける?)
Kestra
YAML でフローを記述する
オープンソース
後発であり、高可用性をもたせた作り
エンプラ向け?
Kuebenetes に特化した Argoflow や、クラウドベンダが提供するサービス(Step Functions)もありますが、今回は除外しました。
他の Workflow Engine に興味のある方へ
Ruby および Ruby on Rails 向けの Workflow Engine
どうしても Ruby じゃなきゃダメなんや、という場合におすすめ。
Kuroko2
Ruby でフローを記述する
オープンソース
Cookpad 社による Workflow & Job Scheduler で Google OAuth に対応している
中規模向け
Rukawa
Ruby でフローを記述する
オープンソース
シンプルだが、スケジューラがなく Cron などのジョブ管理ツールが別途必要
小〜中規模向け
Workflow Engine について知りたい
かなり網羅されています。 GitHub Stars の数も参考になりますよ。
選定
この中で、検証を進め、最終的に Prefect に決定しました。
いずれも素晴らしいプロダクトであり、最低限の要件は満たしていたため最終的には「筆者の好み」になるのかもしれません。
Airflow
- DAG の定義が必要となり直感的ではない(動的な DAG もなかなか大変そう)
- 実行時のパラメータ設定は可能だが面倒
- (MWAA を使った場合) ランニングコストがかかってしまいスモールに開始できない
Digdag
- マネージドがなく、環境構築にコストがかかる
- 実行時にパラメータを渡すことができない (Workflow の修正が必要)
- YAML は便利だが拡張シンタックスがわかりにくい
Kestra
- マネージドがなく、Restack を使ってもコストがかかる
- 拡張機能が Java での実装があり社内技術スタックと相性が悪い
- ECS 連携が公式のプラグインで対応していなかった
Prefect について
Prefect Cloud のメリットを説明します。
Prefect 側も Airflow との対比記事を出しているので、参考までにご覧ください。
Prefect と Prefect Cloud
Prefect は、オープンソース Python ベースの Workflow Engine です。
Prefect Cloud は、オープンソースの Prefect Server の全機能に加え、Push Work Pool や Webhook などの付加価値を加えたものです。
Prefect Cloud の料金
小規模で Prefect Server の全機能を使える無料プランがあり、小さめの規模であれば十分に使えます。
Pro 版は 450 ドル/月、 Enterprice 版もあります。
Prefect のアーキテクチャーについて
Prefect のアーキテクチャは、柔軟性が高く複数のモデルが存在するため最初は混乱してしまいますが、「Flow はどこにあるのか」「どこで、だれが Flow を実行するのか」を意識すれば難しくはありません。
Flow は Python Code
Python のライブラリで、 Python と Prefect SDK がインストールされていれば、原則的にはどの環境でも実行可能です。
これが、ローカルでの開発やテストを記述する上で DX を向上させる理由となっています。
Deployment した場合は、 Flow Code Storage 上にコードを配置する必要があります。
Flow Code Storage は、Docker イメージに含める方法、クラウドプロバイダのストレージサービスを利用する方法のほか、 GitHub などの Git ベースストレージも利用できます。
Deployment は Flow を実行するための情報の定義
Deployment は、 Prefect Cloud (または Prefect Server、以降 Prefect Cloud/Server と記述します) 上に、Flow コードの場所や、Flow の実行環境、実行スケジューリングなどをまとめたものです。
Prefect Cloud/Server は、Deployment をもとに、Flow を実行します。
Deployment には 2 つのモデルが存在し、ユースケースに応じて使い分けます。
Serve モデル
Flow 毎にサービスを起動して、 Prefect Cloud/Server と通信し、Flow を実行するモデルです。
サブプロセス内で実行されるため、設定も少なく直感的でわかりやすいモデルですが、反面、Flow の数だけプロセスが必要でかつ、実行しないときも起動しておく必要があるため、Flow の数がスケールすると非常に高価なものになります。実行環境が、従量課金のサーバレスサービスを使う場合はあまり使われないと思われます。
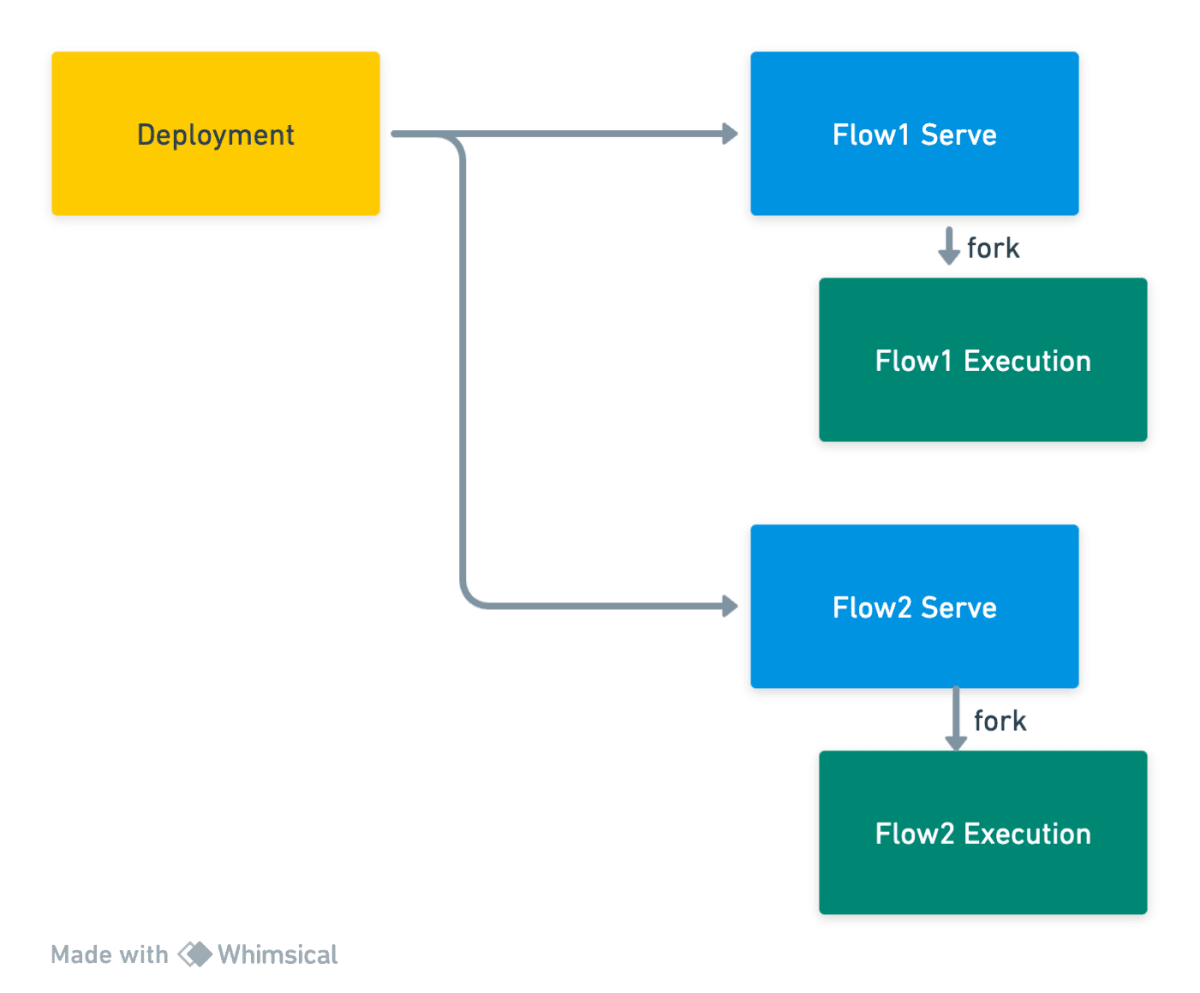
Work Pool モデル
Work Pool と呼ばれる、 Flow を実行するインフラストラクチャの定義を定義します。 Worker は、Flow 実行環境で動作して Prefect Cloud/Server と通信し、Flow を実際に実行します。(Worker 上では実行されず、実行環境を作成して実行を送信するまでを担います)。
Flow 毎 / Deployment 毎に Work Pool を指定できるため、柔軟なプロビジョニングを行うことができます。
また、Prefect Cloud を利用すると Worker なしで直接ジョブを実行できる、 Push Work Pool と Managed Worker Pool [4] が利用できます。
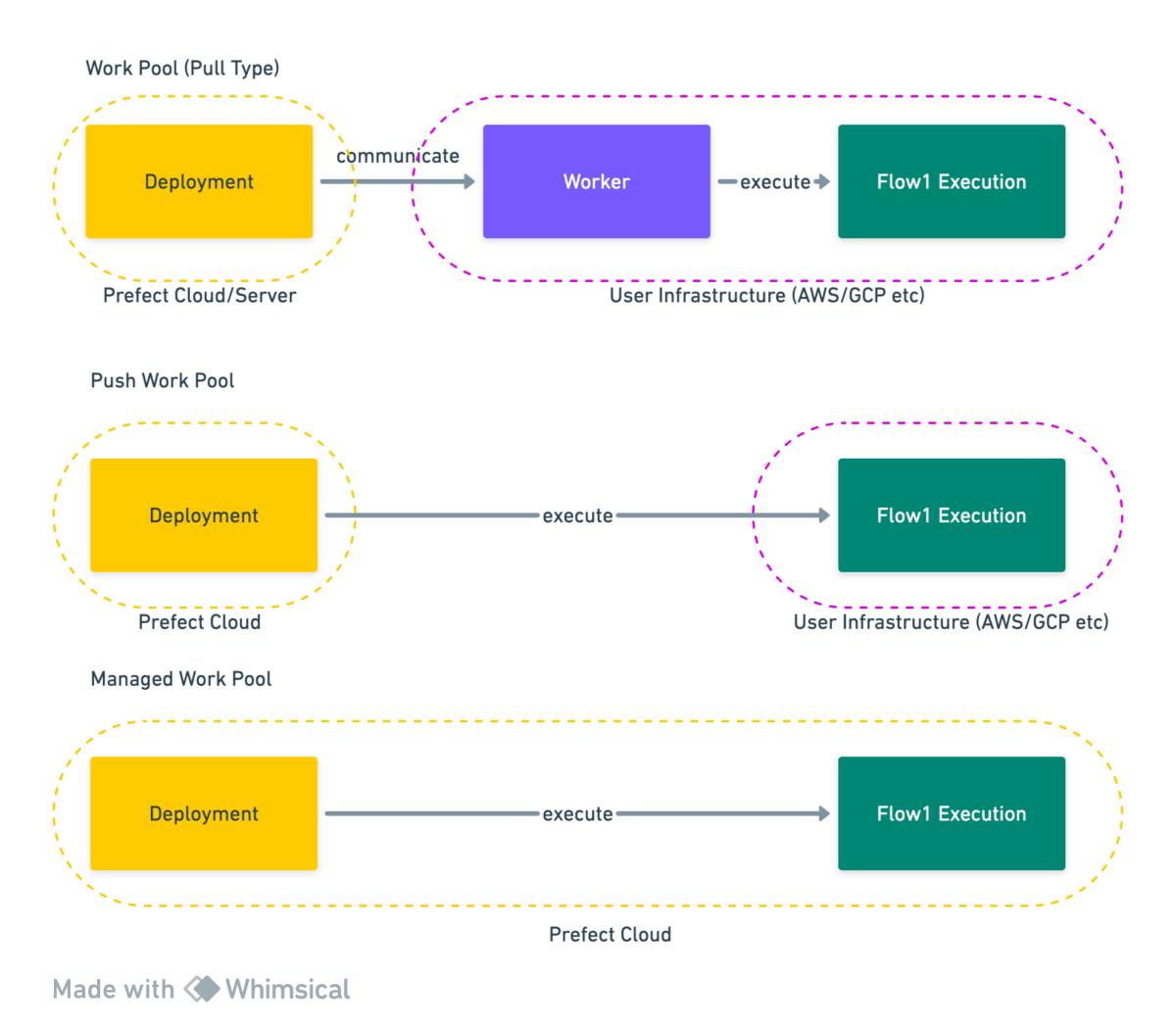
実行環境がクラウドプロバイダのサーバレスサービスを利用しているときは、以下に詳細の説明があります。
基本的には Worker の常駐が必要で、Worker により柔軟な同時実行制限などが可能になります。
Prefect のメリット
Python の環境に閉じている
Python に特化しているため、 エコシステムが利用でき、Python さえ理解していれば学習コストは低くなります。
また、Conda、NumPy、Pandas など、機械学習やデータサイエンスライブラリが豊富にあり、それを活用できるのは大きな強みです。
Python を使っていなくとも、 Ruby などと似た Syntax を持つため、
Web サービス開発のバックエンドエンジニアにはなじみやすい[5]といえるでしょう。
DAG を記述せずにタスクの依存関係を直感的に記述できる
Airflow とは異なり、DAG を意識せずに実装可能な構造となっています。
先ほどの GitHub Actions で記述したフローを Prefect のコードに落としたものです。
from prefect import flow, task
from prefect.task_runners import ConcurrentTaskRunner
@task
def job1_flow():
print('do flow1-task1')
print('do flow1-task2')
return 'return job1'
@task
def job2_flow():
print('do job2-task')
@task
def job3_flow():
print('do job3-task')
@task
def job4_flow():
print('do job4-task1')
print('do job4-task2')
@flow
def overall_flow():
job1_future = job1_flow.submit()
print('job1 submitted')
job2_future = job2_flow.submit()
print('job2 submitted')
result = job1_future.result()
print(f'job1 finished. job1 result={result}')
job2_future.wait()
print(f'job2 finished.')
job3_flow()
job4_flow()
if __name__ == '__main__':
overall_flow()
このスクリプトですが、 pip で prefect をインストールすれば、特に設定せずに実行できます!
python3 -mvenv .venv
source ~/.venv/bin/activate
pip install prefect
python sample.flow
コードの解説
@flow デコレータで囲まれた部分がフローを定義しています。
デフォルトの挙動では、タスクは Python メソッドのように実行できます。
job3_task()
job4_task()
上記は、 job3_task がおわった後に job4_task が実行されます。 Python の挙動と同じですね。
job1_task と job2_task は並列実行させたいので、その場合は submit() を使います。
submit() を呼び出すと、現在のタスクランナーに送信され、非同期で実行されます。
非同期関数は、 wait() で待機します。
result() を使うことで、待機して戻り値を取得できます。
もちろん、次のタスクに値を渡すことができます!
フローとスケジュール(デプロイメント)が分離している
Prefect もスケジュール実行をする場合は、Prefect サーバ上に、登録する必要があります。
これを Prefect では デプロイメント と呼び、フローの実装とは独立しています。
フローとスケジュールなどの定義が分離されていることから、環境毎の実行時間などの変更を柔軟に行えます。
デプロイメントは、 prefect.yaml と呼ばれる設定ファイルに、スケジュールや Work Pool を設定します。
たとえば、先述のフロー定義 を my-test-flow という名前で AM 10:00(JST) に実行する Deployment を作成する設定ファイルは次の通りです。
deployments:
- name: my-test-flow
tags: ["test"]
description: "Test Flowです"
schedule:
cron: 0 10 * * *
timezone: Asia/Tokyo
active: true
flow_name: my-test-flow
entrypoint: flows/sample.py:overall_flow
parameters:
arg: "hello"
work_pool:
name: my-workpool
job_variables: {}
tags は Deployment をラベル付けする際に使い、管理画面や CLI でフィルタをかけるために使います。
schedule で、スケジューリングを指定しています。cron で、crontab 形式のフォーマットをサポートし、 timezone でタイムゾーンを指定します。安心。
active: false とすることで、設定を残したまま無効にできます。
entrypoint は、Deployment が最初に実行する flow で、 相対パス : フロー関数名の形式で指定します。
parameters は、 flow の引数を Key-Value で指定します。
work_pool は、Work Pool の名前やパラメータを指定します。 work_pool は個々の Deployment 毎に設定します。詳細は後述します。
フロー実行のインフラストラクチャが分離している
フローは Prefect Server 上では実行されません[6]。
フローの実行方法の定義は、 Work Pool と呼び、例えば AWS の VPC や ECS Cluster の定義などを行います。
また、インフラストラクチャのプロビジョニングも行うことができ、 ECS Cluster や Task Definition などの作成も不要となります。
(実際の運用ではセキュリティ要件の問題で、別作成になると思いますが PoC や検証時はとても楽です)
実行環境は、AWS ECS / GCP CloudRun / Azure Container Instances / Docker / Kubenetes / Local Subprocess など、そして、 Prefect Managed が利用できます。
原則的には Worker と呼ばれる、スケジュールをポーリングしデプロイメントの実行をスケジュールするサービスの起動しておく必要があります。
ただし、Prefect Cloud では、Worker レスの Push Work Pool オプションがあり、その場合はサーバ側でスケジューリングされた後、実行環境のタスクが実行されます。
管理画面 がモダン
Dashboard では直近の実行結果の統計などが見られ、モダンなデザインとなっています[7]。
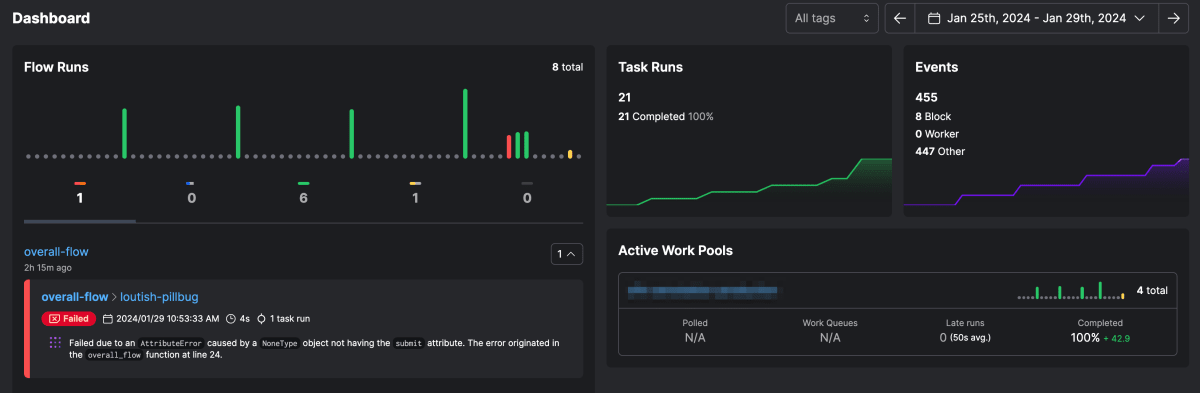
特筆すべきは、エラーとなった flow のログです。
Prefect Cloud では Marvin という AI により、実行ログから重要なエラーメッセージのみを選び表示してくれます。

この図の例は、検証用サーバで Flow を実行したときにエラーが発生したときのものです。弊社では、週末は検証用用のデータベースをシャットダウンしており、実行してしまってエラーがおきたのですが、その際でも最適なエラーログが出力されています。
Prefect と Sidekiq を連携させる
上記の通り Prefect のメリットは大きいのですが、先述の通りバッチジョブは Sidekiq Batches 上で実行されており、Prefect と連携できません。
Sidekiq には API が提供されており、バッチのエンキューはもちろん、Batches の実行ステータスを取得できます。
そこで、 Sidekiq を動作させている Rails プロダクトの内部に Sidekiq Batches をコントロールするため簡単な REST API を追加し、
Prefect 側で Polling することで、連携する方針としました。
以下、実装のサンプルをご紹介します。
Sidekiq REST API の実装
Sidekiq API を用いて、Sidekiq REST API を追加しました。
- Sidekiq Worker クラス名とパラメータを指定してジョブをエンキューする
- Sidekiq Worker は Sidekiq Batches でラップし完了を待つ
- エンキューした Sidekiq Worker のステータスを返却する
ジョブをエンキューする
エンキューの疑似コードです。(エラー処理は割愛してます)
worker_class と worker_params をパラメータとして渡す想定です。
def create
batch = Sidekiq::Batch.new
batch.queue = 'batch_callback_queue'
batch.jobs do
params['worker_class'].constantize.perform_async(params['worker_params'])
end
return json: { bid: batch.bid }
end
返却した batch id を呼び出し元で保管しておきます。
ジョブのステータスを取得する
エンキューした Sidekiq Worker のステータスを待つコードです。
パラメータから bid を渡す想定です。
class SidekiqBatchStatusController < ApplicationController
def get
status = Sidekiq::Batch::Status.new(params[:bid])
return json: { status: status.completed? && status.pending.zero? 'completed' : 'processing' }
end
end
Prefect 側の実装
Prefect 側では共通となるため、 Integrations として実装しました。
プロジェクトの作成
以下のドキュメントに従い、プロジェクトを作成します。
pip install cruft
cruft create https://github.com/PrefectHQ/prefect-collection-template
# 以下を入力する
[1/6] full_name (Arthur Dent):
[2/6] email (arthur.dent@example.com):
[3/6] github_organization (arthur_dent):
[4/6] collection_name (prefect-collection):
[5/6] collection_slug (prefect_collection):
[6/6] collection_short_description (Prefect Collection Template contains all the boilerplate that you need to create a Prefect collection.):
カレントディレクトリ以下に collection_name で入力した名前のディレクトリが作成され、以下にファイル群が作成されます。
MAINTAINERS.md の指示に従い、セットアップを完了してください。
tasks の作成
import httpx
import json
import time
from prefect import task
@task
def run_sidekiq_job(worker_class: str, worker_params: list):
response = httpx.post("https://my-api-url.example.com/api/sidekiq/jobs", json={'worker_class: worker_class, 'worker_params': json.dumps(worker_params)})
return response.raise_for_status().json()
@task
def wait_completed(bid: str):
status = 'processing'
while status != 'complete':
response = httpx.get(f"https://my-api.example.com/api/sidekiq/jobs/status?bid={bid}")
result = response.raise_for_status().json()
status = result['status']
time.sleep(10)
return status
blocks の作成
API のエンドポイントやクレデンシャルを使う場合は Block を用意します。
from prefect.blocks.core import Block
from pydantic import Field
class SidekiqBlock(Block):
"""
Sidekiq API Endpoint Settings
Attributes:
base_uri (str): Base Uri
Example:
Load a stored value:
```python
from prefect_sidekiq import SidekiqBlock
block = SidekiqBlock.load("BLOCK_NAME")
```
"""
_block_type_name = "sidekiq"
# ロゴがあれば置き換えます
_logo_url = "https://images.ctfassets.net/gm98wzqotmnx/08yCE6xpJMX9Kjl5VArDS/c2ede674c20f90b9b6edeab71feffac9/prefect-200x200.png?h=250" # noqa
# ドキュメントのURL
_documentation_url = "https://my-team.github.io/prefect-sidekiq/blocks/#prefect-sidekiq.blocks.SidekiqBlock" # noqa
base_url: str = Field("http://my-api.example.com/api", description="Base Url")
@classmethod
def seed_base_url(cls, name: str, base_url: str):
"""
Seeds the field, value, so the block can be loaded.
"""
block = cls(value=base_url)
block.save(name, overwrite=True)
Flow から呼び出す
作成したインテグレーションは pip でインストールして、python モジュールと同様に利用できます。
以下、インテグレーションを prefect-sidekiq とした場合の例です。
pip install prefect-sidekiq
from prefect import flow
from prefect_sidekiq.tasks import run_sidekiq_job, wait_completed
@flow
def call_flow()
results = run_sidekiq_job(worker_class="MyWorker", worker_argument=[])
wait_completed(bid=results['bid'])
今後実装したい機能
次の機能は、諸事情[8]で実装を見送りましたが、今後必要に応じて実行する予定です。
- Sidekiq Worker の実行を中断する
- Batch Job 完了時のイベント発行
まとめ
今回は、Workflow Engine の基盤として Prefect を採用したときの話と、既存の技術スタックとの連携する方法について説明しました。本番運用は一部分のみでしか開始していないため、これから使っていきながら知見をためていくことになります。
今後、知見がたまれば、より高度な使い方の記事を書こうとおもいます。
少しでも参考になれば幸いです。
参考

Discussion