はじめに
今回、BizOpsの一環として、ourlyのビジネス側の数値をBIツール(QuickSight)で管理するようにしました。
この際に、BIツールを構築する過程で多くの学びがあったので、少しでもこの知見が他の方の役に立ったらなという思いでこの記事を書きました。
本記事では外部のCRMツールからデータを取得しS3に保存、それをデータソースとしてQuickSightに接続するところまでを解説します。
スプレッドシートからBIツールに移行
この記事は下記の画像のように、スプレッドシート上では管理しきれなくなったものをBIツールを用いることでよりグレードアップして管理できる体制を構築した内容となっています。
もしこの記事を読んだ方の中にも現状の管理体制では満足に見切れなくなってきたという方がいましたら、解決手段としてBIツールを視野に入れてみてはいかがでしょうか。

背景として、弊社代表の強烈なスプレッドシート編集術のおかげもあり、弊社もこれまで事業数値をGoogleのスプレッドシート上で管理していました。
しかし事業の拡大とともに管理するデータ量も多くなり、次第に「重すぎて開けない…🥺」「途中で見ていたら固まった…😭」と言った声が上がるようになりました。
ourlyのビジネスの意思決定を正しくするためには、最新の事業数値に常にアクセスできるようにすることが必須! ということでBIツール移行プロジェクトが始まりました。
この時点での要件は下記になります。
- CRMのツールにはHubSpotを使用している
- すでに弊社内でQuickSightを使用している箇所があるため、ourlyとの親和性が高いQuickSightを今回も使用する
- 最新のデータにアクセスできるように構築する
今回の技術選定
今回使用した技術的な要素は下記になります。基本的にはAWSが提供しているサービスと、HubSpot側で用意している非公開アプリ(API)を用いた形となっています。
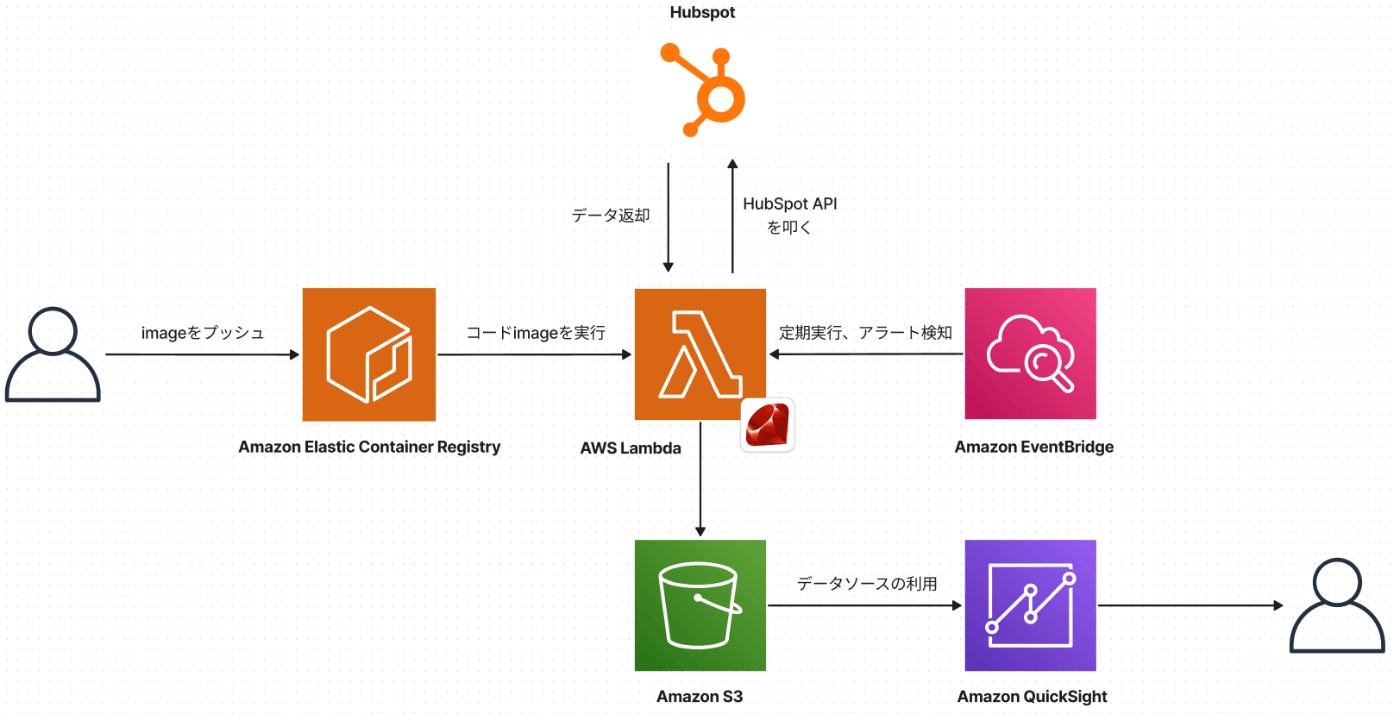
使用したAWSサービスと使用用途としては下記になります。
| AWSサービス | 用途 |
|---|---|
| Amazon QuickSight | BIツール。QuickSight上でデータを結合できカスタマイズ性が高い |
| Amazon S3 | QuickSightでデータソースとして用いるCSVファイルの置き場所 |
| AWS Lambda | ECRに保存されているイメージファイルを元にサーバレスでAPI実行→S3にCSVファイルを保存する |
| Amazon Elastic Container Registry(ECR) | ローカルで作成したコードimageを保存しLambdaに利用 |
| Amazon EventBridge | Lambdaでの実行を定期スケジューリングし監査も行える |
これ以降はLambda, S3, QuickSight(一部ECR)の設定や実装について解説をしていきます。
本記事は定期実行の設定に関する箇所(EventBridge)を説明に含めていません。QuickSightに可視化するためのミニマムの実装は手動でファイルを作成・更新でき、S3に保存されたファイルとQuickSightを繋ぎこむところまでがゴールとなるので、本記事ではそこまでの実装を目指します。
BIツール構築までの道のり
この章からは具体的に、どのような実装内容でQuickSightへ可視化するところまで実現したのかを振り返っていきます。工程ごとに節を分けているので、気になる箇所だけ見ていただいても構いません。
環境構築(Gemをインストール)
HubSpotが公開している非公開アプリ(API)を実行して、データを取得することができます。
今回はRubyを用いて実行するため、 hubspot-api-client というGemを利用しました。
Lambdaの実行環境に上記のGemをインストールし、コードを実行するための環境構築を下記で行いました。この際にGemをインストールするだけではLambda上で実行することができないため、追加でCのライブラリであるgccをインストールしました。
下記は今回の実装で作成したDockerfileです。Lambda実行時にこのDockerfileをもとに環境構築を行うことでHubSpot APIを実行できるようになります。
FROM public.ecr.aws/lambda/ruby:3.2
RUN yum update -y && yum install -y \
gcc \
gcc-c++ \
make \
libcurl4 \
libffi-dev
COPY . ${LAMBDA_TASK_ROOT}/
RUN bundle config set --local path 'vendor/bundle' && bundle install
CMD [ "app.LambdaFunction::Handler.process" ]
最終行の CMD では、Lambda内でイメージを起動する際に関数を実行するようにしています。
HubSpot APIでデータ取得(アクセストークンの設定)
今回はHubSpot APIのうち、CRM APIを利用してデータを取得しました。
APIドキュメントは丁寧に書かれているので、これとchatGPTをうまく使えばデータ取得はできるはずです。
ただ上記のAPIを実行する上で、適切にアクセス権限を付与したアクセストークンを発行する必要があるので、下記ではアクセストークンの発行までの手順をご説明いたします。
※以下の画像は2024/10/01時点のものとなります。閲覧時点でHubSpotのUIに変更が入っている可能性がありますがご了承ください。
まずはHubSpotの設定画面を開きます。

サイドバーから"連携"→"非公開アプリ"を選択。

"非公開アプリを作成"を押し、適切なスコープを設定します。今回はdealに関するデータが読み込めるようなスコープを設定しました。


作成した非公開アプリからアクセストークンを参照してHubSpotのインスタンス生成に使用します。

アクセストークンを取得できたあとは、環境変数やAWS Secrets Mangerを用いて使用するようにしましょう。
S3へ保存(ポリシー設定)
次にAPIで取得したデータをcsvに整形してS3に保存します。
RubyからS3に保存する際の実装方法は、インターネット上に豊富に存在するので調べたら出てくるかと思います。
ですので今回は特に自分が学んだ、S3への保存の際に気をつけるべきポイントを紹介いたします。
それは IAMの設定を活用して、S3のインスタンス作成時によりセキュリティを担保するようにした方がよいという点です。
通常Aws::S3::Clientのインスタンスを生成する際には以下のように、 "access_key_id", "secret_access_key"を使用して生成することができますが、リモートのECRにプッシュするコード内に機密情報は含めたくないですよね。
s3 = Aws::S3::Client.new(
access_key_id: 'your_access_key_id',
secret_access_key: 'your_secret_access_key'
)
そうした時はLambdaの関数に、特定のS3バケットにアクセスできるように適切なIAMを付与してあげましょう。
下記の内容で、LambdaからS3の特定のバケットにアクセスすることを許可するポリシーを作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::bucket-name"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::bucket-name/*" // バケット内に存在する任意のファイルに対しての権限を付与
}
]
}
このポリシーをLambdaの関数に付与しているロールにアタッチしてあげれば、Lambdaの関数実行時に今回使用したいS3に対しての保存処理を"access_key_id", "secret_access_key"無しに実行できるようになります。
s3 = Aws::S3::Client.new
今回ご紹介したIAMポリシーによる設定以外にも、環境変数を使用したりAWS Secrets Managerを使用する方法などがあるので、その時の仕様や環境に合わせて適切に手段を選択しましょう。
QuickSightのデータソースにS3のcsvファイルを設定
さて、ここで主役のBIツールであるQuickSightの登場です。
今回はS3に保存したCSVファイルをデータソースとして参照して、グラフや表に出力できるようにすることを目指します。
先述までにS3に保存したCSVファイルとQuickSightの繋ぎ込みを行いましょう。
では実際の設定作業に入ります。まずQuickSightの画面を開き、「新しいデータセット」を選択します。
この時にデータソースとしてS3を指定します。

データソース名を入力し、マニフェストファイルをアップロードします。マニフェストファイルを用いて、具体的にどのデータファイルを参照するかを指定することができます。
今回は下記のようなマニフェストファイルをJSONファイルで作成しました。
{
"fileLocations": [
{
"URIs": [
"s3://bucket_name/dir/file_name.csv"
]
}
],
"globalUploadSettings": {
"format": "CSV",
"delimiter": ",",
"containsHeader": "true"
}
}
マニフェストファイルが正しく記述されていたら「接続」を押して、データソースを作成します。
以上で、S3に保存されているCSVファイルとQuickSightの接続が完了しました。意外と手軽にできてしまうので、開発者体験が素晴らしいなと率直に思いました。

CUI上から実現できた方が作業の再現性が生まれる
今回はGUI上での設定方法を説明していますが、理想はCUI上から実現できるようにしておくことをオススメします。
なぜか?それはGUI上での操作は漏れが発生しやすい(現に記事内でもスクショで補足している)ためです。複数人での作業をする場合は設定内容が明確なCUI上から実行できるようにしておくことがより大事になります。
今回AWSの検証環境で実装した内容を本番環境に移行する場面がありました。そのような場合に全く同じ作業を一からGUI上で行うことが難しい場合があります。初期実装は試行錯誤する場面もあるため、検証環境と同じ実装が別環境でも実現できたかどうかを保証しづらいです。
ですのでそういう観点でもCUIから実装できるようにしておくと後々大きな旨みになります。(それにCUIからできた方がシンプルにカッコいい)
次回の記事予告
ここまで記事をご覧いただきありがとうございました!
今回はHubSpotで保存されているデータをS3に保存し、それをQuickSightに繋ぎ込むところまでを行いました。
しかしこのままでは、S3に保存されているファイルは手動更新しなければならないため自動で更新できるようにする必要があります。
次回はLambdaとEventBridgeによる定期的なCSVファイルの更新と、QuickSightの同期の自動化作業をメインに解説したいと思います。

Discussion