こんにちは!
ourly というスタートアップで web エンジニアをしている @Hiroです。
弊社が提供しているourlyには、プロフィール機能というものがあります。
この機能の一つで、企業に所属している全社員を一覧で見ることができる画面を提供しています。
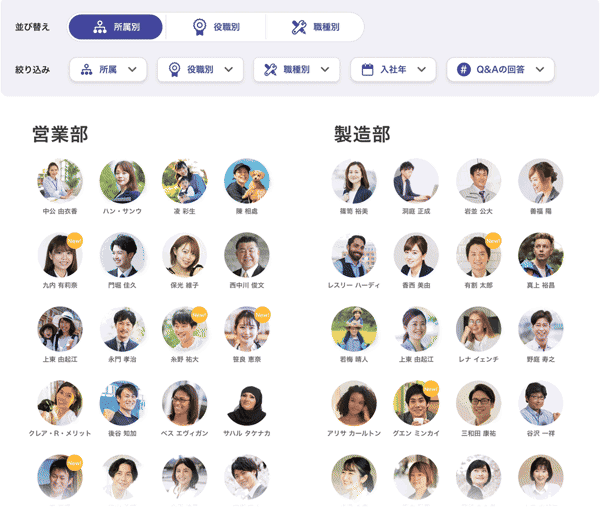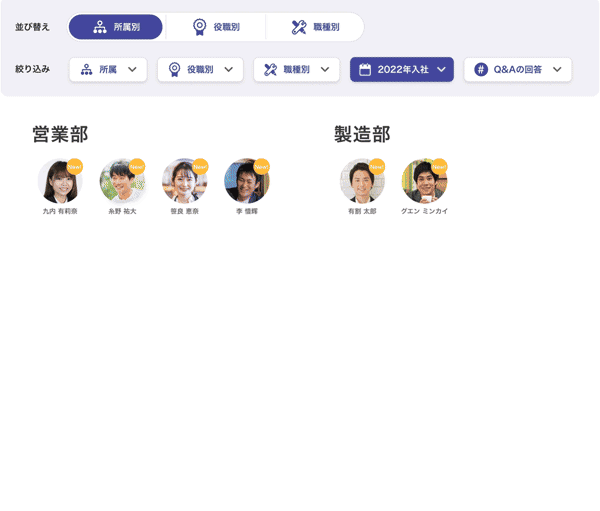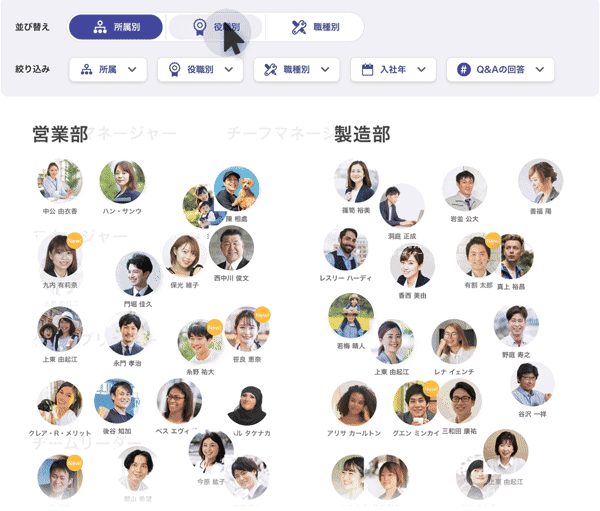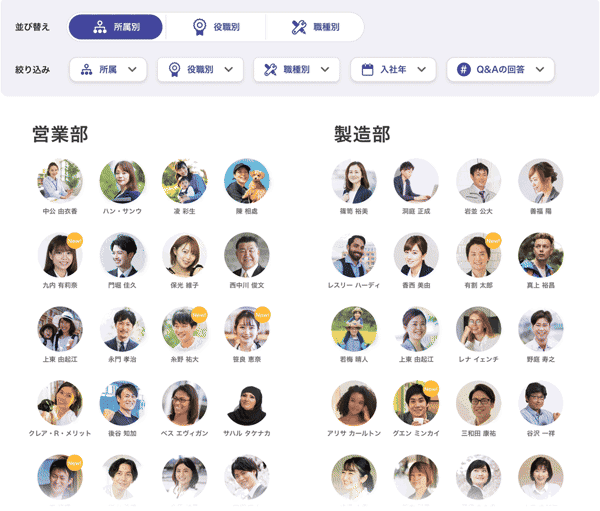
プロフィール一覧画面のイメージ
ある日、この画面に表示されるユーザーの表示順を変更する対応が必要になりました。
元々はユーザーの「作成日時」の昇順で表示していましたが、これを各ユーザーが保持している「役職」や「所属」といった情報を元に表示順を変更するといった内容です。
しかし、この並び替えをORDER BY句を利用してDB側で実施すると、DBにかかる負荷が非常に大きくなり、処理にかかる時間が増加してしまいました。
その結果、画面の表示が遅くなり、ユーザビリティが著しく損なわれるという問題が発生しました。
今回は、この問題をどのように解決したかをご紹介します。
実現したいこと
変更前の表示順
- ユーザーの「作成日時」の昇順で表示

変更後の表示順
- ユーザーが保持している情報を元に、以下のような複数条件で並び替えて表示
- 役職の昇順
- 所属の昇順
- 入社日の昇順
- 作成日の昇順

解決方法
今回の問題ではDBにかかる負荷が大きいことが一番のボトルネックだったので、DBからはデータを取得するだけに留めておき、アプリケーション側で並び替えを実施するといった方法を取りました。
アプリケーション側で並び替えるため、まずユーザーごとにユニークな『並び替え用の値(= 以降"ソートランク"と表現)』を生成します。
この値は、各要素をビットORで「所属|役職|入社日|作成日」のように結合した値で、表示優先度が高い人ほど小さい値となっているため、昇順に並び替えることで期待する順番でユーザーを並び替えることができます。
# ユーザーごとに以下のようなユニークな値(ソートランク)を生成する。
ユーザーA: 1205848751841204253640
ユーザーB: 1224295495914913802256
ユーザーC: 1242742239988623356272
:
# ソートランクを2進数で表現した場合
ユーザーA: 10000010101111010000011010110101111000001100111001001000011001111001000
ユーザーB: 10000100101111010000011010110101111000001100111001001000010100000010000
ユーザーC: 10000110101111010000011010110101111000001100111001001000011000101110000
:
ソートランクの生成方法
ここでは「ユーザーA」を例にして紹介します。

1. 各要素の表示順を整数で表現
まずは各要素の表示順を整数で表現します。
役職や所属はDBに表示順が保持されているため、そのまま利用可能です。入社日や作成日時は整数ではないため、UNIX時間に変換して扱いました。
例:ユーザーA
- 役職: 役員 → 1
- 所属: セールス → 1
- 入社日: 2020/4/1 → 1585666800
- 作成日時: 2024/11/01 10:50:00 → 1730425800
2. 各要素の桁数を揃える
次に各要素を、各要素の最大値を2進数で表現したときの桁数に揃えます。
最終的に各要素をビットORで「所属|役職|入社日|作成日」のように結合するのですが、桁数を最大値に揃えることで、ユーザー間で比較対象となる要素を揃えることができます。
また、桁数を揃える際に下位要素を考慮することで、ビットORで結合したときに要素間の情報が被ってしまうことを防ぎます。
各要素の最大値:
- 役職: 最大値50 → 2進数は6桁(110010)
- 所属: 最大値50 → 2進数は6桁(110010)
- 入社日・作成日時: 最大値2106年のUNIX時間 → 2進数は32桁
- 31桁だとUNIX時間の2038年問題があるため、32桁で表現できる最大値「2106-02-07 15:28:15」を上限としました。
# 各要素を下位要素の合計桁数分、左にシフトする。(.は便宜上付与してます。)
例:ユーザーA
- 役職: 1 << 70 → 1180591620717411303424
- 10000000000000000000000000000000000000000000000000000000000000000000000
- 下位要素の桁数分、左にシフト(70桁 = 所属の桁数(6)+入社日の桁数(32)+作成日時の桁数(32))
- 所属: 1 << 64 → 18446744073709551616
- ......10000000000000000000000000000000000000000000000000000000000000000
- 下位要素の桁数分、左にシフト(64桁 = 入社日の桁数(32)+作成日時の桁数(32))
- 入社日: 1585666800 << 32 → 6810387048352972800
- ........101111010000011010110101111000000000000000000000000000000000000
- 下位要素の桁数分、左にシフト(32桁 = 作成日時の桁数(32))
- 作成日時: 1730425800 << 0 → 1730425800
- ........................................1100111001001000011001111001000
- 下位要素はないので左シフトしなくていい。
3. 各要素を結合
最後に、各要素をビットORで「所属|役職|入社日|作成日」のように結合します。
# 所属|役職|入社日 | 作成日
1180591620717411303424 |
18446744073709551616 |
6810387048352972800 |
1730425800
------------------------
1205848751841204253640
2進数で見ると次の通りになります。
# 所属|役職|入社日 | 作成日
10000000000000000000000000000000000000000000000000000000000000000000000 |
10000000000000000000000000000000000000000000000000000000000000000 |
101111010000011010110101111000000000000000000000000000000000000 |
1100111001001000011001111001000
-------------------------------------------------------------------------
10000010101111010000011010110101111000001100111001001000011001111001000
これにより、表示優先度が高い人ほど小さい値となるソートランクを生成することができます。
実装してみた感想
生成した値を元にアプリケーション側で並び替えることで、DB負荷を抑えながら期待する順番でユーザーを表示できるようになりました。また、生成したソートランクはユーザーの情報が変更されるまでは再利用することが可能なので結果をキャッシュしておくことで再計算のコストも削減できました。
一方で、今回の方法は処理が複雑になるため、コードの可読性が低下するデメリットもありました。そのため、大量のデータを扱う必要がある仕様そのものを見直すことも重要だと感じています。
最後に
今回ご紹介した実装は、大量のデータを並び替える際に役立つソートテクニックです。
DB負荷を抑えつつ、大量のデータを並び替えたいというような課題でお困りの方がいらっしゃいましたら、この記事が少しでも役立てば嬉しいです!

Discussion