DuckDB爆速すぎてGISに使ったりChatGPTと組み合わせてみる

この記事ではDuckDBを使用した地理分析や、Python上でDuckdbのデータを基にLangchainを使ったモデルを利用することで話し言葉でSQLを実行させる例を紹介します。
SQLの価値
2023年も残り数ヶ月ですが、2022年では最も人気あるプログラミング言語のアンケートでSQLはPythonを抑えて3位でありました(参照)。今年はどうなるでしょうか。ただSQLがここに位置するのは必要性が上昇しているからでしょう。同僚もデータサイエンス分野ではPythonかRで良かった(はずな)のに、SQL学びなおすのかと笑いながら話していました。軽く聞いたアンケートでも、多くの人がSQLは「まあできる」「ベーシックはわかるよ」と言います。でもアメリカ人のそれは「SELECT * FROM table WHERE x = 'test'」が分かれば十分だと思っているレベルです。CTEもWindow Functionも、中にはWHERE xyz IN()のINさえ知らないレベルだったりします。データが取得できれば後はPython/R側で分析するからいいではないかというものです。ですが、リード/シニア・データサイエンティスト含め、いろんな技術関わっている人はデータウェアハウス、データレイクの話も含めて、より現実的にSQLの重要度が増していることを感じています。Pythonはデータサインエスの分野では必須ですが、SQLを知っていれば、メモリを結構使うPythonやRでの処理を素早くデータウェアハウス側で済ませることも可能です。
データフレームもテーブルも似たような構造ならデータウェアハウス上で機械学習させてもいいじゃんというのがBigQuery MLですが、Randam ForestやARIMA modelなども単純にそのキーワードをオプション内で指定して、後は標準のSQLでどのデータを使用するか決めるだけです。まあ例え数年のデータであっても半端ないデータ処理をするので予算との相談になりますが、SQLだけで機械学習ができることを示したのは良かったと思います。
Duckdbの台頭
duckdbというAnalysisのためのデータベースをご存知でしょうか。そんなに意識はしてなかったのですが、今年に入ってからGDAL/ogr, GEOS, PostGISの機能が"spatial"というextensionとして紹介され始めてから徐々にみる機会が増えました。
以前H2O.aiが紹介していたpandasやdata.tableなどの比較をしたベンチマークを引き継いで、データの処理速度のベンチマークを紹介しています。見ていただければ分かりますが、バイアスがかかってるのではないかと思うぐらいDuckdbが驚きのスピードを出していると同時に、他のpandasやdask、DataFrames.jlの値は経験上納得もできるわけです。polarsもテストで使ってみましたが、スピードはともかく周りの多くがpandasを使っているとなかなかpolarsにdataframeを切り替えとはいかないですね。そんななかで圧倒的なパフォーマンスを示すduckdb。これはpandasかpolarsといったどっちのデータフレーム使うかという論争ではなく、共存してよりスムーズに使えるようになるのではないかと思い、spatialのextension含めテストしてみました。>
Duckdbの簡単なイントロ
duckdbの良さはSQLiteと同じような感覚でローカルで気軽に使えることです。
$ brew install duckdb
$ duckdb xxx.db;
Macであればこれでduckdbの機能が使えます。でもわざわざファイルを使わなくてもCSVやParquetをそのままデータベース代わりに使うことも可能です。
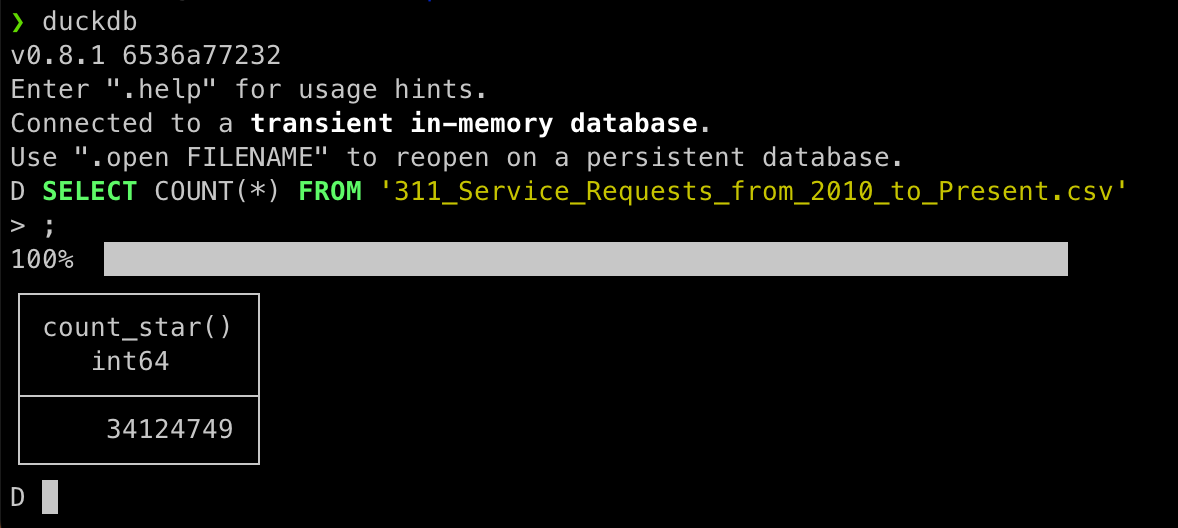
データはイントロやベンチマークなどいろんな所で使われるNYCのオープンソースデータの一つ、311コールです。(余談ですがアメリカでは救急性でない場合は911ではなく311に電話します。911に電話してもそれは救急性ないから311に電話してと言われます。実体験です)このデータ、ダウンロードした時点で19.5> GBあるんです。私はMacbook Air 2022 (8GB RAM)を使っていますがCSVファイルそのものは明確にRAMより大きい。なのに一度テーブルを作ってしまえばその後のスピードは驚異的です。これぐらいの大きさのものをpandasとかで処理するときの待ち時間に不満を持たれていたらぜひduckdbを試してほしいです。
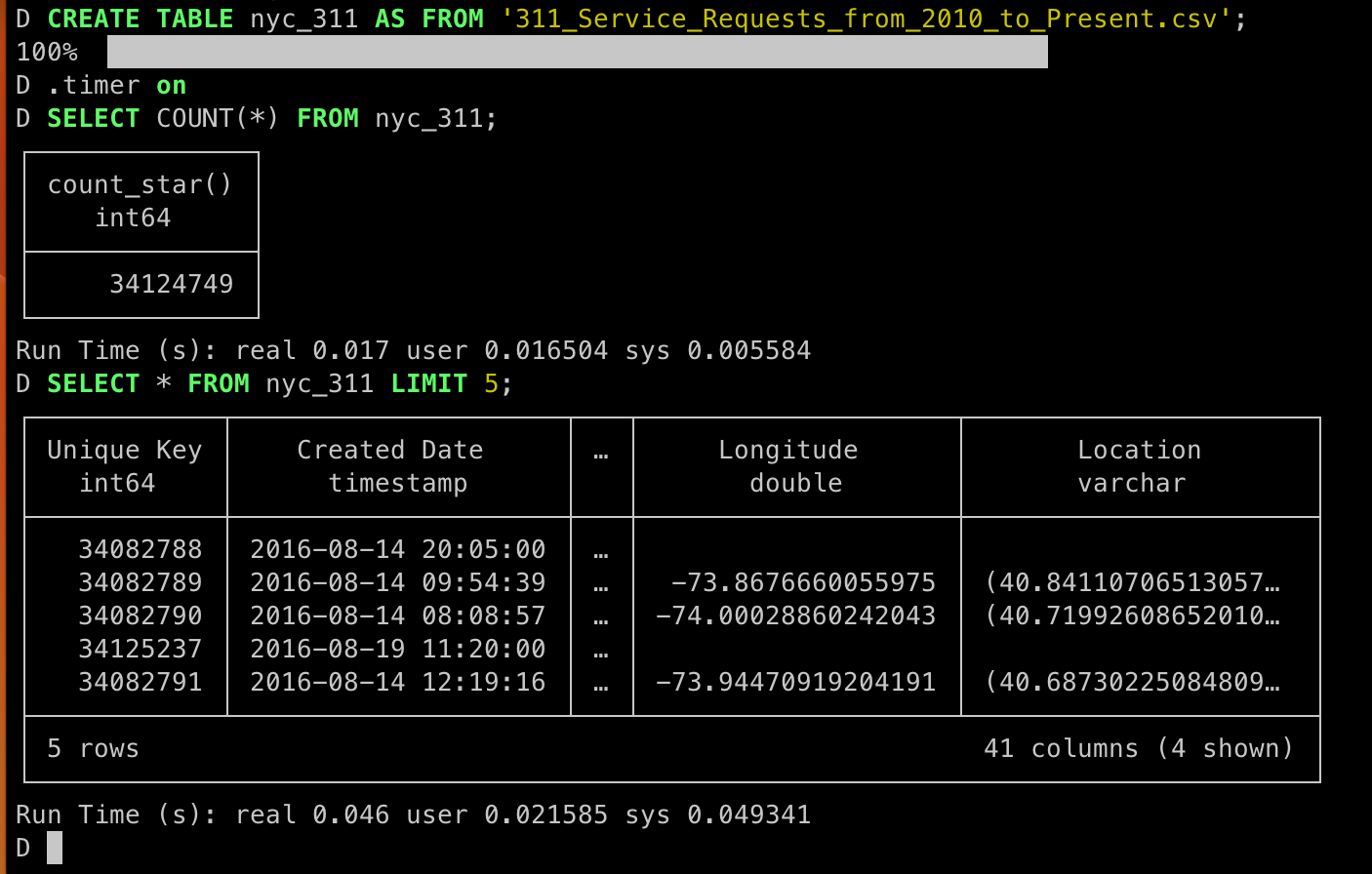
Duckdb for GIS
上の図でもおわかりのように、このデータには緯度・経度が含まれています。Duckdbはextensionという形で機能を追加することができ、2023年の4月にPostGISの一部の機能を使えるようにしたspatialというextensionが公開されています。それを踏まえてMattさんがAnalyze MILLIONS of points in SECONDS (on your computer) with DuckDB for GISというYouTube Videoを出しているのですが、この記事はその話が基になっています。
まずはspatialのextensionをインストールします。
$ duckdb gis.db --unsigned
> SELECT * FROM nyc_311 LIMIT 3;
> INSTALL spatial;
> LOAD spatial;
まずはcsvファイルからnyc_311を作りましたので、緯度・経度からgeometryを追加したnyc_311_geomテーブルを新たに作りました。いわゆる地理情報で、311コールがあったポイントを示します。UberでH3を作成されたIssacさんがduckdb用にh3 extensionを作成されていますが、makeが必要です。詳しくはMark Litwintschikさんの記事を参照してください。>
それからベースとなるNY市の地図データを取ってきます。httpfsというextensionを使うことでDuckdbはネット上からデータを取ってテーブルの如く扱うことができます。
CREATE OR REPLACE TABLE nyc_311 AS
SELECT *
FROM read_csv_auto('311_Service_Requests_from_2010_to_Present.csv');
CREATE OR REPLACE TABLE nyc_311_geom AS
SELECT *,
st_point(Longitude, Latitude) AS geom,
h3_latlng_to_cell(Latitude, Longitude, 10) AS h3
FROM nyc_311;
LOAD httpfs;
CREATE OR REPLACE TABLE nyc_neighborhoods AS
SELECT *,
ST_GeomFromWKB(wkb_geometry) AS geom
FROM
ST_Read("<https://raw.githubusercontent.com/HodgesWardElliott/custom-nyc-neighborhoods/master/custom-pedia-cities-nyc-Mar2018.geojson>");
COPY (
SELECT
neighborhood,
geom
FROM nyc_neighborhoods)
TO 'data/joined.geojson'
WITH (FORMAT GDAL, DRIVER 'GeoJSON');
GISをしていないとこれの意味がわからないとは思いますが、最終的にjoined.geojsonというファイルを作っています。これをVS Codeでみてみると(Geo Data Viewerというextensionを使います)
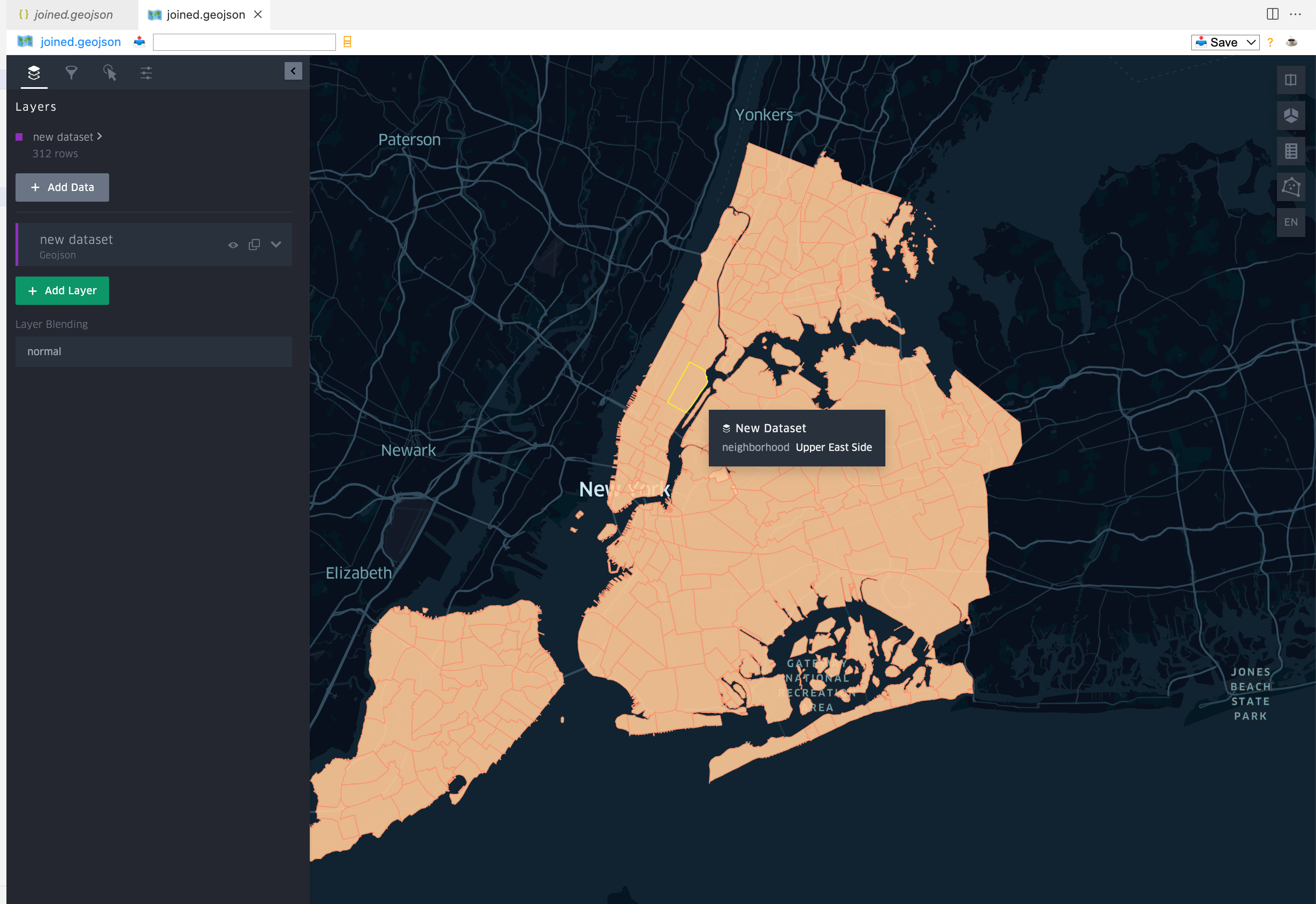
このようなNYのそれぞれのDistrictの範囲を示すようなBoundary Polygonの地図が閲覧できます。GISというのは、これをベースにして、「311コールが多くあった地域を可視化したい、地図で示したい」という話です。動画の例ではそれをヘキサゴンで示してみるというものです。このduckdbのデータにはPythonからアクセスすることができますからシンプルにh3ライブラリを使ってみます。見ていただければ分かりますが、本当にSQLiteを使う感じでDuckdbと繋げてデータを取ってきます。
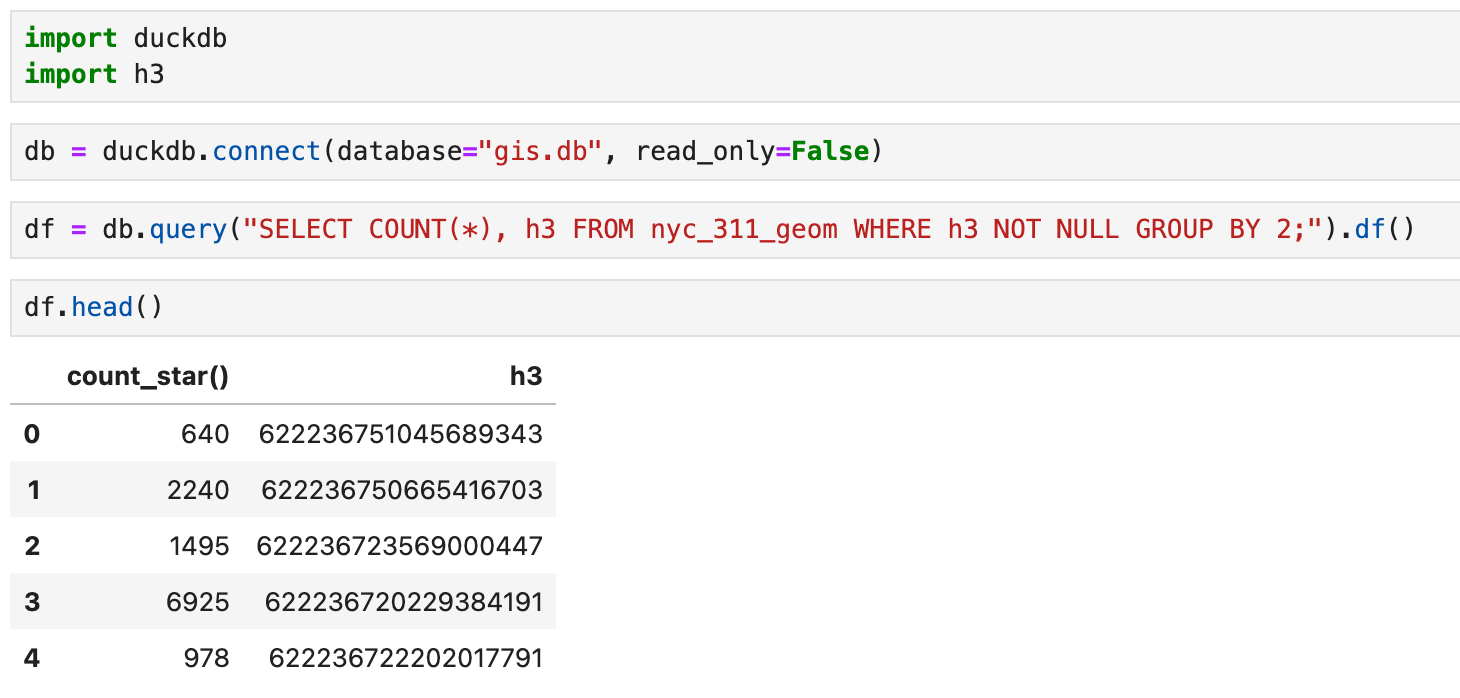
後はここでh3.h3_to_string()を使えば

hexagonベースの地図データを作成することができます。
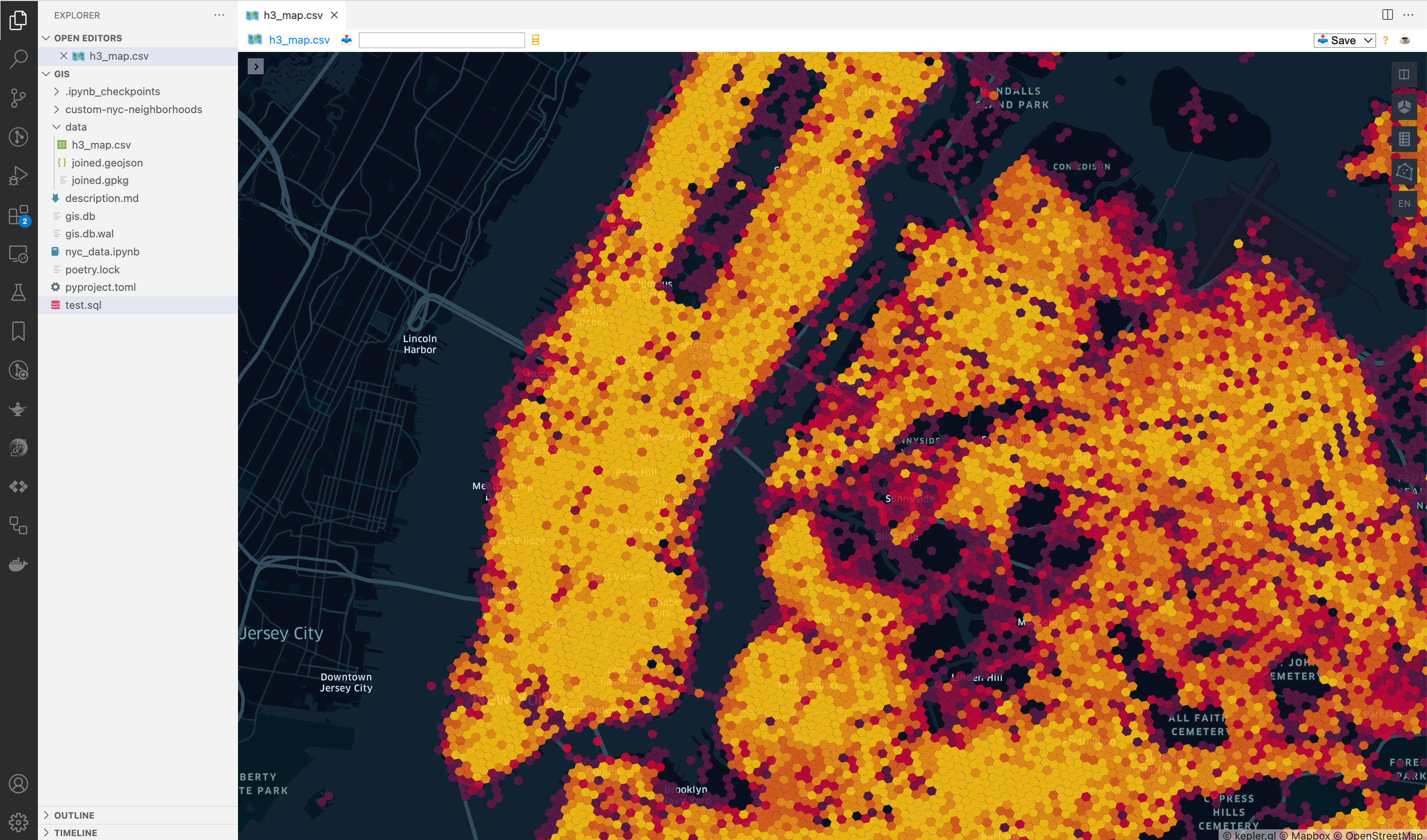
もともとのファイルが19.5 GBあり、gis.dbをつくりそこにCSVファイルからnyc_311, nyc_311_geom, nyc_neighborhoodと大きな3つのテーブルを作ったのでgis.dbは12GBぐらいになりました。それでも元のCSVファイルより小さく済んでるのが驚きですし、それ以上にほとんどの処理が数秒で終えてしまうんです。この速度は紹介した動画のMattさんも言ってますが、英語でいうなら本当にクレイジー。GISデータ、特に大きな地理情報データを扱ってきた人なら分かると思いますが、この速度を感じると今まで使ってきたのは何だったんだと思ってしまいます。Geopandasからどれだけの処理を移行できるか考え始めました。
duckdbはRでも、個人的に使ってるJuliaからでもアクセスできるので、言語にとらわれずデータ処理をすることが可能です。といってもSQLがなかなか好きになれない人もいると思います。そこでChatGPTを使って、今持っているduckdbのデータを基に自動的にSQLを生成してみます。
ChatGPTを使ってDuckDBのデータ処理をする
この話もMattさんが別動画で紹介されていたものですが、とても参考になるものなので紹介します。ここではPythonのlangchainライブラリを使います。
$ pip install langchain
$ pip install openai
# Poetryを使っているなら
$ poetry add langchain
$ poetry add openai
データはNBA Shotsを使います。これは2000年から全てのシュートの情報を網羅しています。これをダウンロードしてduckdb上にテーブルを作成します。

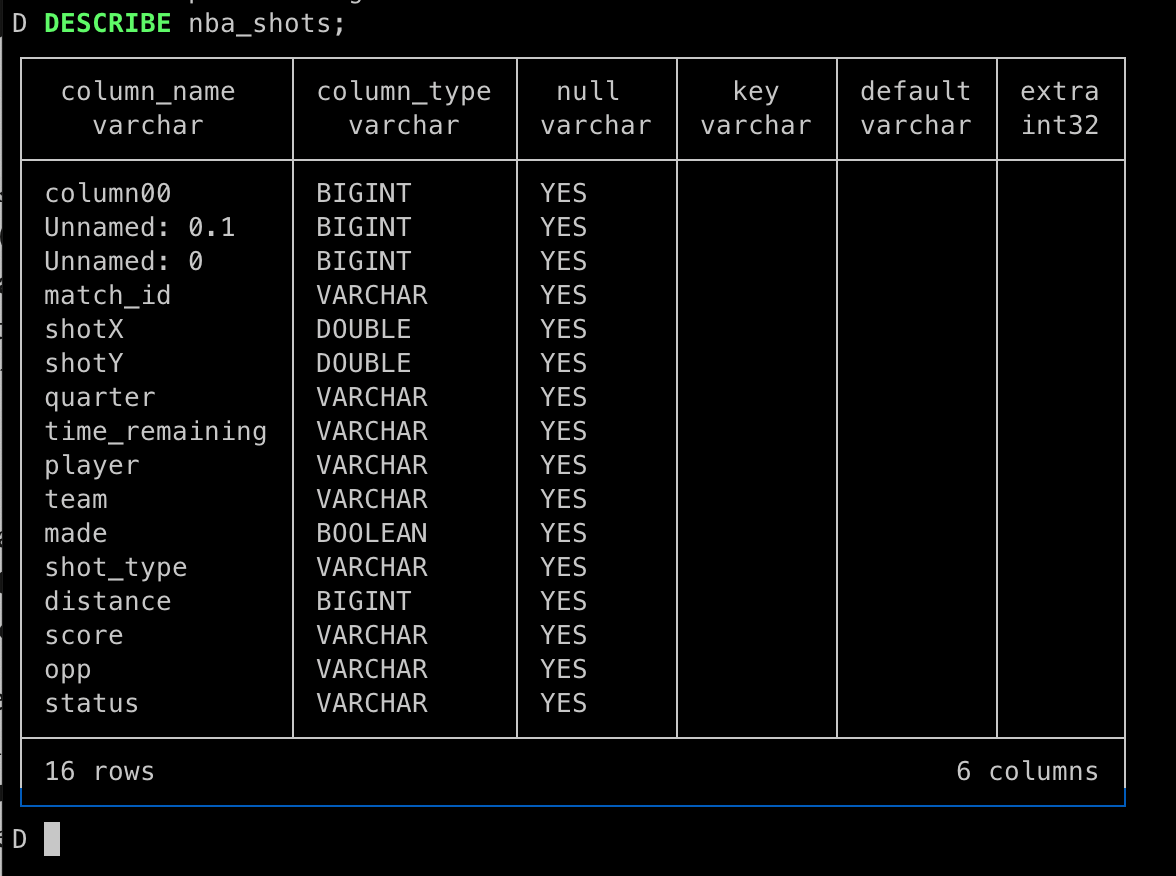
作成したらPython上からアクセスしてみます。先にLangchainライブラリも使用できるようにします

同じ結果がでるのが分かると思います。SQLも使えますし、その結果をDataframeとして表示するのもdf()をつけるだけでできます。
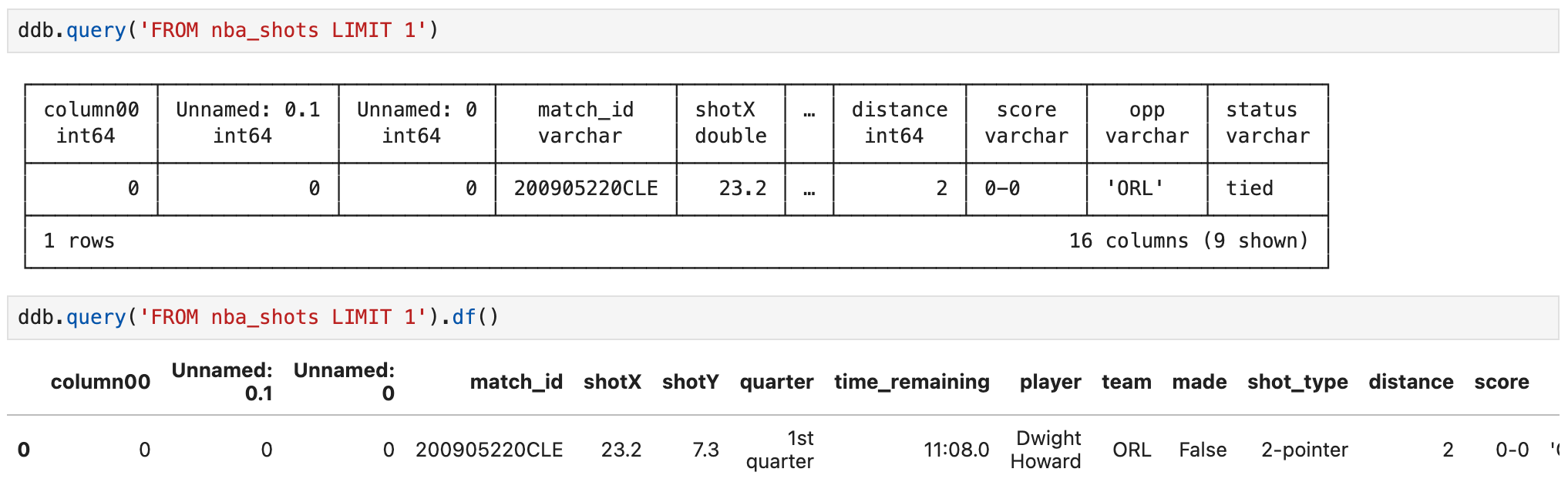
最初の3列は必要ないのでそれを除いたテーブルを作成しました。DuckdbはBigQuery同様にEXCLUDEを使えるのが嬉しいですね。
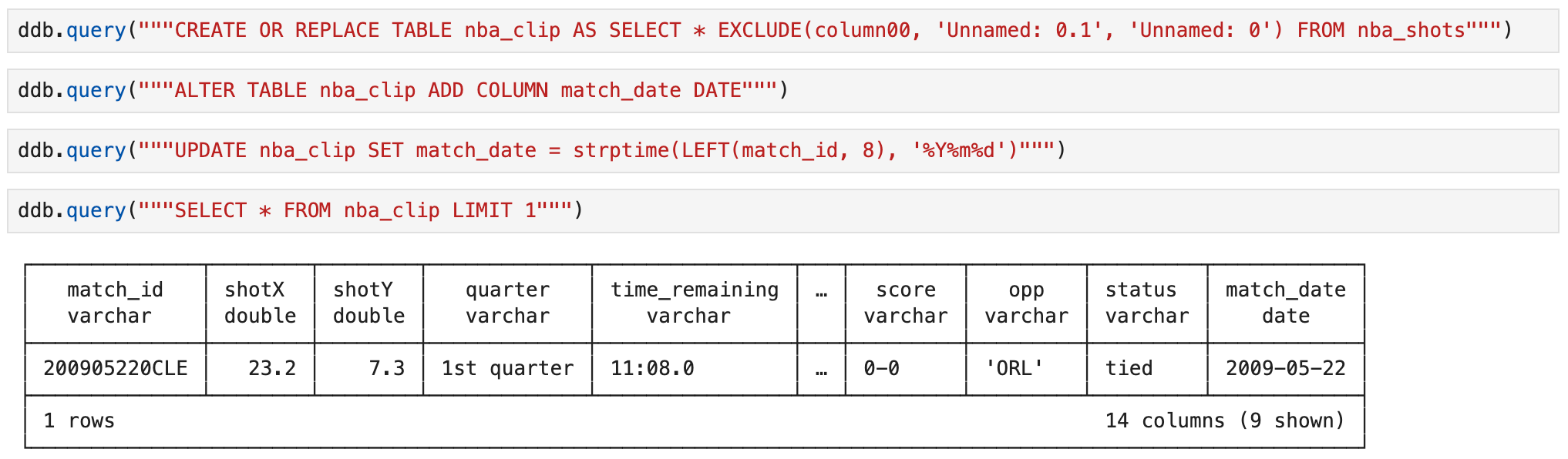
そしてここからはLangchainモデルを使ってSQLを自動生成するためのセットアップです


ChatGPTを使ったAgentができました。まずこのduckdbのテーブルの情報を渡します。ここでテーブルのそれぞれの列が何を意味するのかの情報と、どうして欲しいかを示します。最後に{query}とすることで、SQLを自動で生成してくださいと示しています。

これで環境は整いましたので、質問をしてみます。「2015年に誰が最も3ポイントで得点を獲得したか、最低でも100回以上は試みて」という質問ですね。

実行すると以下のような表示がされ、
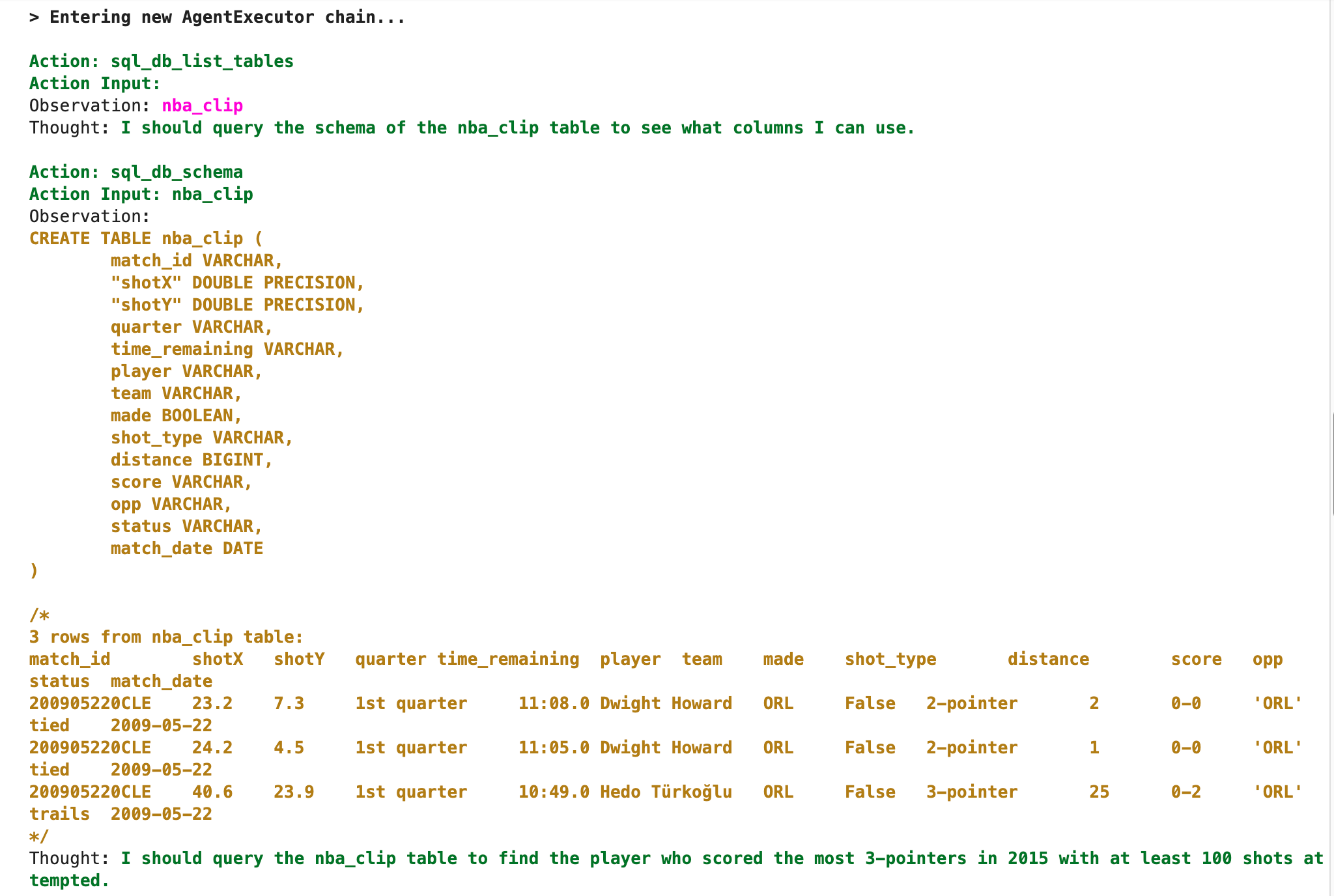
SQL文も表示されるのでどういうSQLを実行して結果をだそうとしたかが分かります。Stephen Curryが最も3ポイントで得点を獲得した選手だと出ました。

正確にはシーズンは2015−2016とまたぐのでポイントは正解ではありませんが、それはTemplate上でより具体的に示す必要があります。その情報がなければ2015年で書いてあれば2015−01−01から2015−12−31までの範囲で調べるのは当たり前です。
ただ今自分が持っているduckdb上のデータから、普通の書き言葉で質問しても、こうやってSQLを書き出し結果を表示するわけです。
これをBigQueryとかでとなると、クエリ使用量とか気にしてしまいますが、一度データをダウンロードして、爆速のDuckdbを利用してしまえば、比較的大きなデータを使うことができます。
DuckdbはWASMでも使えるでしょうから、ブラウザ上で待ち時間少なく、普通に質問したものを「分析」して表示させることもできるでしょう。
Langchainでも活用され、WASMでも使えるだけでなく、地理情報・位置情報も扱えるとなると、Duckdbはこれから更に大きな存在になるのではないでしょうか。楽しみです。
Discussion