pandasで出来る事はどこまでJuliaでできるのか?
Juliaを学ぶにつれて現在Juliaでどこまでできるのだろうと思うことはないでしょうか。Python pandasを仕事でも普段から利用していますが、今のJuliaでは何ができて何ができないのか、Pandasの代わりにどこまでなるのか知りたいと思いました。
「Python 実践データ加工/可視化100本ノック」というPandasを使ってデータ加工、可視化のプロセスに特化して実践的に使える方法を紹介している本があります。とてもいい本だと思うので、pandasの利用する基礎力を身に着けたい方にはおすすめです。ですが、この記事を見ているということはJuliaにも多少の興味をもたれている方だと思いますので、Juliaでできるんだよという事を示していきたいですね。
サンプルデータはGitHubでも公開されていますので、このデータをもとに、Pythonではこのコードを使ってデータ加工やグラフを作成しているけれどもJuliaではこうするというのを一部紹介したのが、今回の記事になります。この記事では本の第1章で紹介されている1-20のプロセスをJuliaで行ってみました。
1-20で紹介されていることをPythonのコード、その後にJuliaのコードの順で紹介しているのでかなりの長さになりますが、説明文は省略してあり、単純にコードの比較とJuliaの結果を表示したものになります。
先に結論だけ言いますと、第1章で紹介されているCSVをデータフレームとしてとりこんでいろいろデータ加工、棒グラフや線グラフで可視化する方法ですが、現在のJulia Dataframeで全て可能です。見ていただければ分かりますが、多くのコードがとても似たようなものであるのがわかると思います。
あえて大きな違いを言えば
tmp = data.loc[tmp['update_fiscal_year'] >= 2016]
このような形でよく使われる.locですが、Juliaでは
tmp = filter(row -> row.update_fiscal_year >= 2016, tmp)
のようにFilter、Subsetなどで選択する形をとっています。
データそのものが小さいので実行速度の比較などはしていませんが、ここではpandasでできることはJuliaでも出来ることが分かりますし、データが大きければ大きいほど最終的な実行速度の差を感じ取っていただけると思います。
まずは実行環境のチェックです。今回はWindowsで試しています。
#julia
versioninfo()
Julia Version 1.8.5
Commit 17cfb8e65e (2023-01-08 06:45 UTC)
Platform Info:
OS: Windows (x86_64-w64-mingw32)
CPU: 8 × Intel(R) Core(TM) i7-7700K CPU @ 4.20GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-13.0.1 (ORCJIT, skylake)
Threads: 1 on 8 virtual cores
Environment:
JULIA_DEPOT_PATH = D:\Julia\.julia
#julia
using BenchmarkTools
using DataFrames
ENV["COLUMNS"]=1000
ENV["LINES"]=50
第1章 「Juliaで」システムデータの加工・可視化を行う
1. Shift-jisでエンコードされた内容のあるCSVファイルをデータフレームに読み込む
#python
import pandas as pd
data = pd.read_csv('data/22_shizuoka_all_20210331.csv', encoding='shift-jis')
#julia いくつかDataFrameにとりこむ方法はあるが、直感的にわかりやすい、私が使ってるのを選んでます
using CSV, StringEncodings
data = CSV.File(open("data/22_shizuoka_all_20210331.csv", enc"shift-jis"), header=false) |> DataFrame;
最初の5行表示
#python
data.head()
#julia
first(data, 5)
データサイズ
#python
len(data)
#julia
# size without header
size(data)
(114613, 30)
#julia
nrow(data)
114613
2. 読み込んだデータの確認
コラム名表示
#python
data.column
#julia
names(data)
30-element Vector{String}:
"Column1"
"Column2"
"Column3"
"Column4"
"Column5"
"Column6"
"Column7"
"Column8"
"Column9"
"Column10"
"Column11"
"Column12"
"Column13"
"Column14"
"Column15"
"Column16"
"Column17"
"Column18"
"Column19"
"Column20"
"Column21"
"Column22"
"Column23"
"Column24"
"Column25"
"Column26"
"Column27"
"Column28"
"Column29"
"Column30"
#julia
length(names(data))
30
データタイプの確認
#python
data.dtypes
#julia
# 全セル表示
eltype.(data)
#julia
# それぞれのコラムごとのデータタイプの場合(Pythonの結果と同様)
eltype.(eachcol(data))
30-element Vector{Type}:
Int64
Int64
Int64
Int64
Dates.Date
Dates.Date
String
Union{Missing, Int64}
Int64
String15
String31
Union{Missing, String}
Union{Missing, Int64}
Int64
Int64
Union{Missing, Int64}
Missing
Missing
Union{Missing, Dates.Date}
Union{Missing, Int64}
Union{Missing, Int64}
Union{Missing, String}
Dates.Date
Int64
Union{Missing, String}
Union{Missing, String15}
Union{Missing, String}
Missing
Union{Missing, String}
Int64
意図しない変換(01が1に変換されている)があるので、データ型(文字列型)を指定して読み直す
#python
data = pd.read_csv('data/22_shizuoka_all_20210331.csv', encoding='shift-jis', header=None, dtype=object)
#julia
data = CSV.File(open("data/22_shizuoka_all_20210331.csv", enc"shift-jis"), header=false, types=String) |>
DataFrame
first(data, 5)
#julia
# もう一度確認
eltype.(eachcol(data))
30-element Vector{Type}:
String
String
String
String
String
String
String
Union{Missing, String}
String
String
String
Union{Missing, String}
Union{Missing, String}
String
String
Union{Missing, String}
Union{Missing, String}
Union{Missing, String}
Union{Missing, String}
Union{Missing, String}
Union{Missing, String}
Union{Missing, String}
String
String
Union{Missing, String}
Union{Missing, String}
Union{Missing, String}
Union{Missing, String}
Union{Missing, String}
String
3. ヘッダ用のテキストファイルを読み込む
#python
mst = pd.read_csv('data/mst_column_name.txt', encoding='shift-jis', sep='\t')
#julia
mst = CSV.File(open("data/mst_column_name.txt", enc"shift-jis")) |> DataFrame
#julia
nrow(mst)
30
#julia
ncol(mst)
3
mstとdataのコラム数が合うか確認
#python
len(mst) == len(data.columns)
#julia
# 1 = row, 2 = column
size(mst,1) == size(data, 2)
true
4. ヘッダ行を追加する
#python
columns = mst.column_name_en.values
#julia
columns = mst.column_name_en
30-element Vector{String31}:
"sequenceNumber"
"corporateNumber"
"process"
"correct"
"updateDate"
"changeDate"
"name"
"nameImageId"
"kind"
"prefectureName"
"cityName"
"streetNumber"
"addressImageId"
"prefectureCode"
"cityCode"
"postCode"
"addressOutside"
"addressOutsideImageId"
"closeDate"
"closeCause"
"successorCorporateNumber"
"changeCause"
"assignmentDate"
"latest"
"enName"
"enPrefectureName"
"enCityName"
"enAddressOutside"
"furigana"
"hihyoji"
コラム名を変更する
#python
data.columns = columns
#julia
data = rename(data, columns)
first(data, 5)
5. 統計量や欠損値を確認する
#python
data.describe()
#julia
describe(data, :all)
欠損値の確認
#python
data.isna()
#julia
ismissing(data)
false
#julia .をつけることで全体としてでなく各セルをチェックする意味をもつ
ismissing.(data)
欠損数の値を項目ごとに集計
#python
data.isna().sum()
#julia
describe(data, :nmissing)
6. 繰り返し処理で新しいデータを追加
データがおいてあるフォルダの状態を確認
Python
import os
os.listdir('data')
#julia
; ls data
22_shizuoka_all_20210331.csv
diff_20210401.csv
diff_20210405.csv
diff_20210406.csv
diff_20210407.csv
diff_20210408.csv
diff_20210409.csv
mst_closeCause.csv
mst_column_name.txt
mst_corp_kind.csv
mst_correct_kbn.csv
mst_hihyoji.csv
mst_latest.csv
mst_process_kbn.csv
output
#julia
# 他の方法
using FileIO
readdir("data")
15-element Vector{String}:
"22_shizuoka_all_20210331.csv"
"diff_20210401.csv"
"diff_20210405.csv"
"diff_20210406.csv"
"diff_20210407.csv"
"diff_20210408.csv"
"diff_20210409.csv"
"mst_closeCause.csv"
"mst_column_name.txt"
"mst_corp_kind.csv"
"mst_correct_kbn.csv"
"mst_hihyoji.csv"
"mst_latest.csv"
"mst_process_kbn.csv"
"output"
diff_ filesのみをリストにする
Python
from glob import glob
diff_files = glob('data/diff*.csv')
diff_files
#julia
# Pythonではglobライブラリがもつglob()関数を使う形なのでfrom~を使いますがJuliaは簡略化
using Glob
diff_files = glob("data/diff*.csv")
6-element Vector{String}:
"data\\diff_20210401.csv"
"data\\diff_20210405.csv"
"data\\diff_20210406.csv"
"data\\diff_20210407.csv"
"data\\diff_20210408.csv"
"data\\diff_20210409.csv"
ファイル名の昇順で並べ替えした上で1つ目のファイルを読み込む
#python
diff_files.sort()
diff = pd.read_csv(diff_files[0], encoding='shift-jis', header=None, dtype=object)
print(len(diff))
diff.head(3)
#julia
sort!(diff_files) # !つけることでinplaceをONにした形になります
diff = CSV.File(open(diff_files[1], enc"shift-jis"), header=false, types=String) |> DataFrame # Juliaは0-baseではなく1-baseです
println(nrow(diff))
first(diff, 3)
2316
静岡県のデータに絞り込みます
#python
diff.columns = columns
diff = diff.loc[diff['prefectureName'] == '静岡県']
print(len(diff))
diff.head(3)
#julia
rename!(diff, columns)
# Julia DataFramesでは空白(Null)の部分を取り除く作業が必要になります
diff = dropmissing(diff, :prefectureName)
diff = diff[diff[!, :prefectureName] .== "静岡県", :]
println(size(diff))
first(diff, 3)
(43, 30)
#julia
# 別の方法 - subset関数を使います。これだと1行ですみます
rename!(diff, columns)
diff = subset(diff, :prefectureName => ByRow(==("静岡県")), skipmissing=true)
println(size(diff))
first(diff, 3)
(43, 30)
差分データリストからの読み込み、絞り込み、データ結合を実装
#python
for f in diff_files:
diff = pd.read_csv(f, encoding='shift-jis', header=None, dtype=object)
diff.columns = columns
diff = diff.loc[diff['prefectureName'] == '静岡県']
data = data.append(diff)
data
#julia
for f in diff_files
diff = CSV.File(open(f, enc"shift-jis"), header=false, types=String) |> DataFrame
rename!(diff, columns)
diff = subset(diff, :prefectureName => ByRow(==("静岡県")), skipmissing=true)
data = vcat(data, diff)
end
first(data, 5)
#julia
describe(data, :all)
重複したデータを確認
#python
data[data["corporateNumber"].duplicated()]
#julia
data[findall(nonunique(data, [:corporateNumber])), :]
重複データを削除
#python
data.drop_duplicates(subset='corporateNumber', keep='last', inplace=True)
#julia
data = unique(data, [:corporateNumber])
#julia
describe(data, :nmissing)
7. マスタ読み込んで項目を横につなげる
#julia
; ls data
22_shizuoka_all_20210331.csv
diff_20210401.csv
diff_20210405.csv
diff_20210406.csv
diff_20210407.csv
diff_20210408.csv
diff_20210409.csv
mst_closeCause.csv
mst_column_name.txt
mst_corp_kind.csv
mst_correct_kbn.csv
mst_hihyoji.csv
mst_latest.csv
mst_process_kbn.csv
output
Python
#python
mst_process_kbn = pd.read_csv('data/mst_process_kbn.csv', dtype=object)
#julia
mst_process_kbn = CSV.File("data/mst_process_kbn.csv", types=String) |> DataFrame
名称を追加
#python
data = data.merge(mst_process_kbn, on='process', how='left')
#julia
# leftjoin()関数を使ってmst_process_kbnをdataにマージしています。
# 共通する項目が「process」なのでそれをキーとして使っています。
data = leftjoin(data, mst_process_kbn, on=:process)
first(data, 5)
#julia
size(data)
(114758, 31)
mst_correct_kbn.csvを同様に処理
#python
mst_correct_kbn = pd.read_csv('data/mst_correct_kbn.csv', encoding='shift-jis', dtype=object)
#julia
mst_correct_kbn = CSV.File(open("data/mst_correct_kbn.csv",enc"shift-jis"), types=String) |> DataFrame
dataにマージします
#python
data = data.merge(mst_correct_kbn, on='correct', how='left')
print(len(data.columns))
data.head(3)
#julia
data = leftjoin(data, mst_correct_kbn, on=:correct)
println(size(names(data)))
first(data, 3)
(32,)
mst_corp_kind.csvを同様に処理します
#python
mst_corp_kind = pd.read_csv('data/mst_corp_kind.csv', dtype=object)
mst_corp_kind
#julia
mst_corp_kind = CSV.File("data/mst_corp_kind.csv", types=String) |> DataFrame
mst_corp_kind

mst_latest.csvを同様に処理します
#python
mst_latest = pd.read_csv('data/mst_latest.csv', dtype=object)
mst_latest
#julia
mst_latest = CSV.File("data/mst_latest.csv", types=String) |> DataFrame
mst_latest

dataにマージします
#python
data = data.merge(mst_latest, on='latest', how='left')
print(len(data.columns))
data.head(3)
#julia
data = leftjoin(data, mst_latest, on=:latest)
println(size(names(data)))
first(data, 3)
(34,)

最後にmst_hihyoji.csvを同様に処理します
#python
mst_hihyoji = pd.read_csv('data/mst_hihyoji.csv', dtype=object)
mst_hihyoji
#julia
mst_hihyoji = DataFrame(CSV.File("data/mst_hihyoji.csv", types=String))
mst_hihyoji

dataにマージします
#python
data = data.merge(mst_hihyoji, on='hihyoji', how='left')
print(len(data.columns))
data.head(3)
#julia
data = leftjoin(data, mst_hihyoji, on=:hihyoji)
println(size(names(data)))
first(data, 3)
(35,)
8. テキストの連結や分割をする
都道府県、市区町村、丁目番地等を1つに連携して住所とする
それぞれの項目に欠損値がないかを確認
#python
data[['prefectureName', 'cityName', 'streetNumber']].isna().sum()
#julia
describe(data[:,[:prefectureName, :cityName, :streetNumber]], :nmissing)

最初に欠損値を考慮しない方法で連結し、結果を確認してみる
#python
data['address'] = data['prefectureName'] + data['cityName'] + data['streetNumber']
print(len(data.columns))
data.head(3)
#julia
# Juliaでは連結は+でなく*を使います。それぞれの列で連結させるので.*と各列でやるよという意味で.(ドット)を追加します
data.address = data.prefectureName .* data.cityName .* data.streetNumber
println(size(names(data)))
first(data, 3)
(36,)
#julia
# 他の方法
using DataFramesMeta
@rtransform data :address = :prefectureName * :cityName * :streetNumber
println(size(names(data)))
first(data, 3)
(36,)
欠損値の項目がどうなったかを確認
#python
data.loc[data['streetNumber'].isna()].head(3)
#julia
first(data[ismissing.(data.streetNumber),:], 3)
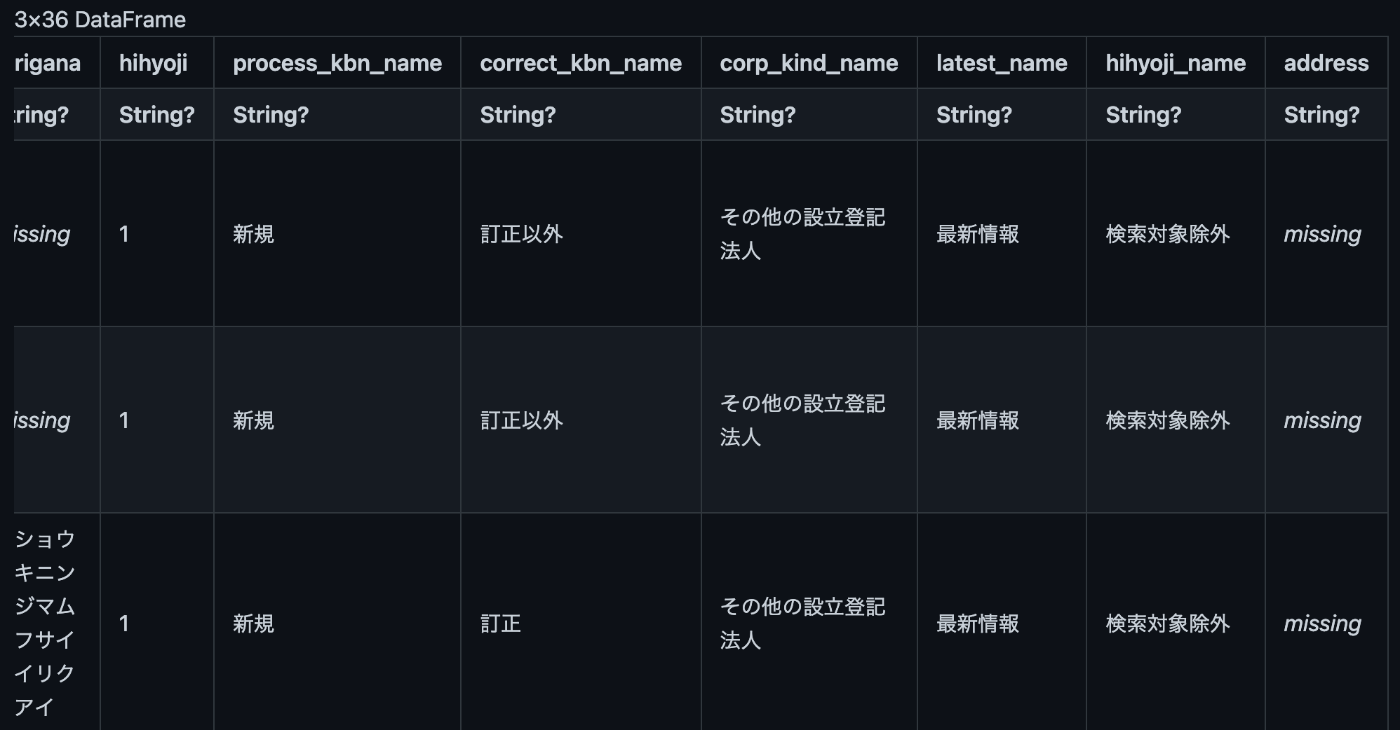
丁目番地等が欠損値のデータを抽出し、都道府県と市区町村だけを連結
#python
data['address'].loc[data['streetNumber'].isna()] = data['prefectureName'] + data['cityName']
#julia
data.address = coalesce.(data.address, data.prefectureName.*data.cityName)
# もしくは列の指定をしてやる必要があります。
# missing_rows = findall(ismissing, data.address)
# data.address[missing_rows] = data.prefectureName[missing_rows] .* data.cityName[missing_rows]
テキストを分割: 郵便番号7桁を前3桁と後4桁に分割する
区切り文字で分割するsplit()がよく使われるが区切り文字がないのでSliceを使う
#python
data['postCode_head'] = data['postCode'].str[:3]
print(len(data.columns))
data.head(3)
#julia
data.postCode_head = map(s -> s[1:3], string.(data.postCode))
# もしくは
# data.postCode_head = [s[1:3] for s in string.(data.postCode)]
println(size(names(data)))
first(data, 3)
(37,)
郵便番号の後半4桁をスライスの一括処理で取得します
#python
data['postCode_tail'] = data['postCode'].str[-4:]
print(len(data.columns))
data.head(3)
#julia
# string. とすることでmissingに関するエラーを無視できます
data.postCode_tail = [s[end-3:end] for s in string.(data.postCode)]
println(size(names(data)))
first(data, 3)
(38,)
9. 日付を加工する
#python
data['closeDate'] - data['assignmentDate']
エラーがでます
# Juliaでも同様にエラーがでます
data.closeDate .- data.assignmentDate
#julia
#ちょっと詳しくみてみます
describe(data, :eltype, :nmissing)

試しに一項目だけ日付型に変換してみます
#python
tmp = pd.to_datetime(data['closeDate'])
tmp.dtypes
#julia
using Dates
tmp = map(s -> (ismissing(s) ? missing : DateTime(s, DateFormat("yyyy-mm-dd"))), data.closeDate)
eltype(tmp)
Union{Missing, DateTime}
繰り返し処理で型変換を行っていきます
dt_columns = ['updateDate', 'changeData', 'closeDate', 'assignmentDate']
for col in dt_columns:
data[col] = pd.to_datetime(data[col])
# Juliaでは'(シングルクォート)は1文字、”(ダブルクオート)は文字列なので”を使います
using Dates
dt_columns = [:updateDate, :changeDate, :closeDate, :assignmentDate]
for col in dt_columns
data[!, col] = map(s -> (ismissing(s) ? missing : DateTime(s, DateFormat("yyyy-mm-dd"))), data[!, col])
end
describe(data, :eltype)
閉鎖日が欠損値でないデータに絞って表示してみる
#python
tmp = data.loc[data['closeDate'].notna()]
print(len(tmp))
tmp.head(3)
#julia
# dropmissing()関数を使うことで欠損値でないデータという条件指定ができます
tmp = dropmissing(data, :closeDate)
println(size(tmp))
first(tmp, 3)
(10077, 39)

閉鎖コードが設定されている行には閉鎖日がもれなく設定されているかチェック
関連性のある項目同士があるべき状態になっているかという観点でのチェックを行います。
#python
len(data.loc[data['closeCause'].notna()]) == len(data.loc[data['closeDate'].notna()])
#julia
size(dropmissing(data, :closeCause)) == size(dropmissing(data, :closeDate))
true
日付項目の値を利用して年月項目を追加
#python
data['update_YM'] = data['updateDate'].dt.to_period('M')
print(len(data.columns))
data.head()
#julia
data.update_YM = Dates.format.(data.updateDate, "yyyy-mm")
println(size(names(data)))
first(data, 5)
(40,)

残りの日付項目も同様に年月項目を作成
#python
dt_prefixes = ['assignment', 'change', 'update', 'close']
for pre in dt_prefixes:
data[f'{pre}_YM'] = data[f'{pre}Date'].dt.to_period('M')
#julia
dt_prefixes = ["assignment", "change", "update", "close"]
for pre in dt_prefixes
data[!, pre*"_YM"] = passmissing(x->Dates.format.(x, DateFormat("yyyy-mm"))).(data[!, pre*"Date"])
end
first(data, 3)

10. 年度を設定する
日本では年度の考え方が必要になる場合があるので、対象を更新日付にしぼり、更新年度を設定してみる
#python
data['update_year'] = pd.DatatimeIndex(data['updateDate']).year # 更新日付から年を取得
data['update_month'] = pd.DatatimeIndex(data['updateDate']).month # 更新日付から月を取得
data['update_fiscal_year'] = pd.DatatimeIndex(data['updateDate']).year # 更新年度に取得した年を設定
data.loc[data['update_month'] < 4, 'update_fiscal_year'] -= 1 # 更新月が3月までは更新年度-1
#julia
data[!, :update_year] = year.(data[!,:updateDate])
data[!, :update_month] = month.(data[!, :updateDate])
data[!, :update_fiscal_year] = year.(data[!, :updateDate])
data.update_fiscal_year .= data.update_fiscal_year .- (data.update_month .< 4) # true 1 false 0
println(size(names(data)))
first(data, 3)
(46,)
年度の計算があっているか確認
更新月が1月から12月のデータを1件ずつ表示させる
#python
for i in range(12):
display(data[['update_YM', 'update_fiscal_year']].loc[data['update_month'] == i + 1][:1])
#julia
for i in 1:12
display(data[data.update_month .== i, [:update_YM, :update_fiscal_year]][1:1, :])
end

11. ファイルに出力する
フォルダの作成
#python
import os
output_dir = 'data/output'
os.makedirs(output_dir, exist_ok=True)
#julia
using FileIO
output_dir = "data/output"
mkpath(output_dir)
"data/output"
csvファイルの出力
#python
output_file = 'processed_shizuoka.csv'
data.to_csv(os.path.join(output_dir, output_file), index=False)
#julia
output_file = "processed_shizuoka.csv"
CSV.write(joinpath(output_dir, output_file), data)
"data/output\\processed_shizuoka.csv"
12. 不要な項目の削除と並べ替え
項目の削除と並べ替え
#python
data = data[['cityName', 'corporateNumber', 'name', 'corp_kind_name', 'process', 'process_kbn_name', 'assignmentDate', 'updateDate', 'update_fiscal_year','update_YM']]
print(len(data.columns))
print(data.columns)
data.head(3)
#julia
data = data[:, [:cityName, :corporateNumber, :name, :corp_kind_name, :process,
:process_kbn_name, :assignmentDate, :updateDate, :update_fiscal_year,
:update_YM]]
println(size(names(data)))
println(names(data))
first(data, 3)
(10,)
["cityName", "corporateNumber", "name", "corp_kind_name", "process", "process_kbn_name", "assignmentDate", "updateDate", "update_fiscal_year", "update_YM"]

1項目だけ削除したいケース
#python
data = data.drop(columns = 'process')
print(data.columns)
data.head(3)
#julia - 考え方としては逆でprocess以外を選択しています
select!(data, Not(:process))
println(names(data))
first(data, 3)
["cityName", "corporateNumber", "name", "corp_kind_name", "process_kbn_name", "assignmentDate", "updateDate", "update_fiscal_year", "update_YM"]
13. まとまった単位で集計
法人種別ごとの件数を確認
#python
tmp = data.groupby('corp_kind_name').size()
#julia
tmp = combine(groupby(data, :corp_kind_name), nrow)

データ量の多い方から順に表示するために並び替え
#python
tmp.sort_values(inplace=True, ascending=False)
#julia
sort!(tmp, :nrow, rev=true)

更新年度ごとの件数
#python
tmp = data.groupby('update_fiscal_year').size()
#julia
tmp = combine(groupby(data, :update_fiscal_year), nrow)

複数の項目でグループ化
#python
tmp = data.groupby(['update_fiscal_year', 'corp_kind_name']).size()
#julia - 分かりやすくするため分けました
gdf = groupby(data, [:update_fiscal_year, :corp_kind_name])
tmp = combine(gdf, nrow)
println(sort!(tmp, :update_fiscal_year))
ピボットテーブルを使った集計
#python
pt_data = pd.pivot_table(data, index='corp_kind_name', columns='update_fiscal_year', aggfunc='size')
pt_data
#julia
pt_data = unstack(tmp, :update_fiscal_year, :nrow)

14. 市区町村別の法人数を可視化
必要なライブラリのインストール
#shell
%%bash
pip install -q japanize-matplotlib
#python
tmp = data.groupby('cityName').size()
tmp.head()
#julia
tmp = combine(groupby(data, :cityName), nrow)
first(tmp, 5)

市区町村別にデータ件数が集計されたものを棒グラフで表示
#python
import matplotlib.pyplot as plt
import japanize_matplotlib
x = tmp.index
y = tmp.values
plt.bar(x,y)
#julia
using Plots
gr()
x = tmp.cityName
y = tmp.nrow
p1 = Plots.bar(x, y, legend=false, fontfamily="Yu Mincho")

#julia 別のライブラリを使う
using Gadfly, Cairo
set_default_plot_size(10inch, 5inch)
g1 = Gadfly.plot(tmp, x=:cityName, y=:nrow, Geom.bar, Guide.xlabel("Number of Rows"), Guide.ylabel("City Name"),
# Scale.y_log10,
Theme(bar_spacing=0.5mm, stroke_color=c->"gray"))

15. グラフの縦横と表示順を変える
値の降順または照準で表示する
#python
tmp.sort_values(inplace=True, ascending=True)
#julia
sort!(tmp, :nrow, rev=true)
#julia - chart
x = sort(tmp.cityName, rev=false)
y = sort(tmp.nrow, rev=false)
p2 = Plots.bar(x, y, legend=false, orientation=:horizontal,
bar_width=0.9, size=(900,800), fontfamily="Yu Mincho")
#julia - Gadflyを利用
set_default_plot_size(10inch, 7inch)
g2 = Gadfly.plot(tmp, y=:cityName, x=:nrow,
Coord.cartesian(yflip=true), Scale.y_discrete,
Geom.bar(position=:dodge, orientation=:horizontal),
Theme(bar_spacing=0.5mm, stroke_color=c->"gray")
)

16. グラフのタイトルとラベルを設定
上位10件に絞り込み、縦の棒グラフにする
#python
tmp.sort_values(inplace=True, ascending=False)
plt.figure(figsize=(20,10))
x = tmp[:10].index
y = tmp[:10].values
plt.bar(x, y)
#julia
sort!(tmp, :nrow, rev=true)
tmp2 = tmp[1:10, :]
p3 = Plots.bar(tmp2.cityName, tmp2.nrow, fontfamily="Yu Mincho", legend=false, bar_width=0.9, size=(900,500))

#julia - Gadfly
g3 = Gadfly.plot(tmp2, x=:cityName, y=:nrow,
Geom.bar(),
Theme(bar_spacing=0.5mm, stroke_color=c->"gray"),
Guide.xticks(orientation=:horizontal),
Guide.yticks(ticks=[0:10_000])
)
タイトルとx軸、y軸のラベルを設定する
#python
plt.figure(figsize=(20,10))
plt.bar(x,y)
plt.title('市区町村別の法人数', fontsize=20)
plt.xlabel('市区町村名', fontsize=15)
plt.ylabel('法人数')
#julia
p4 = Plots.bar(tmp2.cityName, tmp2.nrow, fontfamily="Yu Mincho", legend=false, bar_width=0.9, size=(900,500))
title!(p4, "市区町村別の法人数", fontsize = 20)
xlabel!(p4, "市区町村名", fontsize = 15)
ylabel!(p4, "法人数")

#julia - Gadfly
g4 = Gadfly.plot(tmp2, x=:cityName, y=:nrow,
Geom.bar(),
Theme(bar_spacing=0.5mm, stroke_color=c->"gray"),
Guide.xticks(orientation=:horizontal),
Guide.title("市区町村別の法人数"),
Guide.xlabel("市区町村名"),
Guide.ylabel("法人数")
)
17. グラフの見た目をもっと変えてみる
#python
tmp.sort_values(inplace=True, ascending=False)
tmp = tmp[:10]
x = tmp.index
y = tmp.values
fig, ax = plt.subplots(figsize=(20,10))
bar_list = ax.bar(x, y, color='lightgray')
bar_list[4].set_color('blue')
ax.set_title('自治体別法人数における富士市の位置づけ', fontsize=20);
ax.set_ylabel('法人数', fontsize=15)
ax.text(7.5, 9000, '上位10の自治体を抜粋して表示', fontsize=15)
#julia
x = tmp2.cityName
y = tmp2.nrow
colors = fill("lightgray", length(y)) # set all bars to gray as default
colors[5] = "blue" # change the color of the 5th bar to blue
p5 = Plots.bar(x, y, color=colors, fontfamily="Yu Mincho",
legend=false, bar_width=0.9, size=(900,500))
title!(p5, "自治体別法人数における富士市の位置づけ", fontsize=20)
ylabel!(p5, "法人数")
annotate!(10, 9000, ("上位10の自治体を抜粋して表示", :right, 10))

#julia - Gadfly
using Gadfly, Compose
g5 = Gadfly.layer(
tmp2, x=:cityName, y=:nrow,
Geom.bar(position=:dodge),
Theme(bar_spacing=3mm, default_color="lightgray")
)
tmp3 = tmp2[tmp2.cityName.=="富士市", :]
g6 = Gadfly.layer(
x=tmp3.cityName, y=tmp3.nrow,
Geom.bar(position=:dodge),
Theme(bar_spacing=3mm, default_color="blue"),
order=1)
g7 = Gadfly.plot(g5, g6,
Guide.xticks(orientation=:horizontal),
Guide.title(("自治体別法人数における富士市の位置づけ")),
Guide.ylabel("法人数"),
Guide.xlabel(""),
Guide.annotation(Compose.compose(context(), Compose.text(7.5, 9000, "上位10の自治体を抜粋して表示"), fontsize(10pt))))

18. 90日以内に新規登録された法人数を可視化
現在日時を取得
#python
base_time = pd.Timestamp.now(tz='Asia/Tokyo')
base_time
#julia
using TimeZones
date_time = DateTime("2021-06-09T09:44:57.035", "yyyy-mm-ddTHH:MM:SS.SSS") # 本に記載されていた時刻です
base_time = ZonedDateTime(date_time, tz"Asia/Tokyo")
base_time
2021-06-09T09:44:35+09:00
日付だけ表示されているためassignmentDateをbase_timeと同じ型に変換
#python
data['assignmentDate'] = data['assignmentDate'].dt.tz_localize('Asia/Tokyo')
data.head()
#julia
data.assignmentDate = ZonedDateTime.(data.assignmentDate, tz"Asia/Tokyo");
first(data, 5)
対象データを絞り込む
#python
delta = pd.Timedelta(90, 'days')
tmp = data.loc[(data['process_kbn_name'] == '新規') & (base_time - data['assignmentDate'] <= delta)]
print(len(tmp))
tmp.head()
#julia
using Dates
delta = 90 * Dates.Day(1)
tmp = filter(row -> (row[:process_kbn_name]=="新規") && (base_time-row[:assignmentDate] <= delta), data)
println(nrow(tmp))
first(tmp, 5)
227
抽出した結果をグラフで表示
#python
tmp = tmp.groupby('cityName').size()
tmp.sort_values(inplace=true, ascending=False)
tmp = tmp[:10]
x = tmp.index
y = tmp.values
plt.figure(figsize=(20,10))
plt.bar(x,y)
#julia
tmp = combine(groupby(tmp, :cityName), nrow)
tmp2 = sort(tmp, :nrow, rev=true)
tmp2 = tmp2[1:10, :]
x = tmp2.cityName
y = tmp2.nrow
p6 = Plots.bar(x, y, fontfamily="Yu Mincho", legend=false, bar_width=0.8, size=(800,500))

日付を手入力する方法も試す
#python
base_time = pd.Timestamp('2020-04-16', tz='Asia/Tokyo')
tmp = data.loc[(data['process_kbn_name'] == '新規') & (base_time - data['assignmentDate'] <= delta)]
print(len(tmp))
tmp.head()
#julia
base_time = ZonedDateTime(DateTime("2020-04-16", "yyyy-mm-dd") , tz"Asia/Tokyo")
tmp = filter(row -> (row[:process_kbn_name]=="新規") && (base_time-row[:assignmentDate] <= delta), data)
println(nrow(tmp))
first(tmp, 5)
2766
棒グラフで可視化
#python
tmp = tmp.groupby(by='cityName').size()
tmp.sort_values(inplace=True, ascending=False)
tmp = tmp[:10]
x = tmp.index
y = tmp.values
plt.figure(figsize=(20,10))
plt.bar(x, y)
#julia
tmp = combine(groupby(tmp, :cityName), nrow)
tmp2 = sort(tmp, :nrow, rev=true)
tmp2 = tmp2[1:10, :]
x = tmp2.cityName
y = tmp2.nrow
p7 = Plots.bar(x, y, fontfamily="Yu Mincho", legend=false, bar_width=0.8, size=(800,500))

19. 年度別の推移を可視化する
市区町村が区で終わるデータを抽出
#python
tmp = data.dropna(subset=['cityName'])
tmp = tmp.loc[tmp['cityName'].str.match('^.*区$')]
print(len(tmp))
tmp.head()
#julia
tmp = filter(row -> occursin("区", row[:cityName]), dropmissing(data, :cityName))
println(nrow(tmp))
first(tmp, 5)
50349
対象年月を2016年から2020年に絞り込む
#python
tmp = tmp.loc[(tmp['update_fiscal_year'] >= 2016) & (tmp['update_fiscal_year'] < 2021)]
print(len(tmp))
tmp.head()
#julia
tmp = filter(row -> (row.update_fiscal_year >= 2016) && (row.update_fiscal_year < 2021), tmp)
println(nrow(tmp))
first(tmp, 5)
26405
市区町村名と年度でグループ化
#python
tmp = tmp.groupby(['cityName', 'update_fiscal_year']).size()
tmp.name = 'count'
tmp. tmp.reset_index()
print(len(tmp))
tmp.head(6)
#julia - nrowをcountに名前変更
tmp = combine(groupby(tmp, [:cityName, :update_fiscal_year]), nrow => :count)
sort!(tmp, [:cityName, :update_fiscal_year])
println(nrow(tmp))
first(tmp, 6)
50
年度別推移の折れ線グラフ
import seaborn as sns
from matplotlib.ticker import MaxNLocator
plt.figure(figsize=(20, 10))
plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True))
img = sns.lineplot(x=tmp['update_fiscal_year'], y=tmp['count'], hue=tmp['cityName'])
#julia
x = tmp.update_fiscal_year
y = tmp.count
p7 = Plots.plot(x, y, group=tmp.cityName, fontfamily="Yu Mincho", legend=true, bar_width=0.8, size=(800,500))

#julia - Gadfly
g7 = Gadfly.plot(tmp, x=:update_fiscal_year, y=:count,
Geom.line(),
color=:cityName,
Theme(bar_spacing=0.5mm, stroke_color=c->"gray"),
Guide.xticks(orientation=:horizontal)
)

20. グラフとデータを出力する
CSVファイル出力
#python
data_file = 'knock20_graphdata.csv'
data.to_csv(os.path.join(output_dir, data_file), index=False)
#julia
output_file = "knock20_graphdata.csv"
CSV.write(joinpath(output_dir, output_file), tmp)
"data/output\\knock20_graphdata.csv"
グラフをpng形式の画像ファイルで出力する
#python
graph_file = 'knock20_graph.png"
fig = img.get_figure()
fig.savefig(os.path.join(output_dir, graph_file))
#julia
graph_file = "knock20_graph.png"
# savefig(p7, joinpath(output_dir, graph_file)) # font is missing
draw(PNG(joinpath(output_dir, graph_file), 6inch, 4inch), g7)
Discussion