(E資格)ラビット・チャレンジ 機械学習レポート
参考資料
レポートの参考
- ラビット・チャレンジレポートおまとめ
- sakaeryutaroさんのまとめ(Zenn)
- ラビット・チャレンジを受講した感想・まとめ(みやざダニエルズのIT備忘録)
- StoneRIeverKSさんのまとめ(qiita)
- hirotoさんのまとめ(mathlog)
概要
機械学習モデリングプロセス
- 問題設定
- データ設定
- データの前処理
- 機械学学習、モデルの選定
- モデルの学習
- モデルの評価
データの分割について
ホールドアウト法
データセットを主に二つのサブセット(トレーニングセットとテストセット)に分割し、トレーニングセットを使用してモデルを訓練し、テストセットを使用してモデルの性能を評価する方法。
- 学習用データ:機械学習モデルの学習に利用するデータ
- 検証用データ:学習済みモデルの精度を検証するためのデータ
なぜ分割するか
- モデルの汎化性能(Generalization)を測定するため
- データへの当てはまりの良さではなく、未知のデータに対してどれくらい精度が高いかを測りたい
クロスバリデーション(CV|交差検証)
データセットを複数のサブセット(通常はk個)に分割し、そのうちの1つをテストセットとして、残りをトレーニングセットとして使用する。このプロセスをk回繰り返し、各回でのモデルの性能を評価する。 参考)クロスバリデーションとグリッドサーチ(備忘録)
グリッドサーチ
モデルのハイパーパラメータをチューニングするための手法の一つ。指定されたハイパーパラメータの全ての組み合わせ全てに対してモデルの性能を評価することで、最も良い性能を持つハイパーパラメータの組み合わせを見つけ出す。 参考)クロスバリデーションとグリッドサーチ(備忘録)
線形回帰モデル
- 回帰問題を解くための機械学習モデルの一つ
- 教師あり学習(教師データから学習)に該当する
- 入力とm次元パラメータの線形結合を出力するモデルである
- 慣例として予測値にはハットを付ける(正解データとは異なる)
線形結合とは?
- 入力ベクトルと未知のパラメータの各要素を掛け算し足し合わせたもの
- 入力ベクトルとの線形結合に加え、切片も足し合わせる
- (入力のベクトルが多次元でも)出力は1次元(スカラ)となる
モデルのパラメータについて
- 特徴量が予測値に対してどのように影響を与えるかを決定する重みの集合
- 通常パラメータは未知のため、最小二乗法を用いて推定する
- 説明変数が1次元の場合(m=1)は 単回帰モデル、それ以上の場合は重回帰モデルと呼ばれる
- データには回帰直線(回帰曲面)に誤差が加わり観測されていると仮定し、以下の式で表される
線形単回帰モデル
線形重回帰モデル
パラメータの推定方法
- 最小二乗法により学習データの平均二乗誤差を最小とするパラメータを探索する
- 平均二乗誤差:(実測値と予測モデルも出力値の二乗誤差の和)
最小二乗法によって得られるパラメータの推定値
相関係数について
2つの変数の間にある線形な関係の強弱を測る指標のこと。-1 ~ 1の値を取る。
1に近いと正の相関(片方の変数が大きくなるともう片方も小さくなる)、-1に近いと負の相関。
2組の数値からなるデータ列
参考
実装例
ボストンの住宅データセットを線形回帰モデルで分析する。
部屋数(RM)が4で犯罪率(CRIM)が0.3の物件の値段(PRICE)を求める。
# モジュールとデータのインポート
from sklearn.datasets import load_boston
from pandas import DataFrame
import numpy as np
from sklearn.linear_model import LinearRegression
import warnings
warnings.simplefilter('ignore')
# bostonというインスタンスにインポート
boston = load_boston()
# 説明変数らをDataFrameに変換
df = DataFrame(data=boston.data, columns=boston.feature_names)
# 目的変数をDataFrameに追加
df['PRICE'] = np.array(boston.target)
# 説明変数は2つ
data = df.loc[:, ['CRIM', 'RM']].values
# 目的変数
target = df.loc[:, 'PRICE'].values
# オブジェクト生成
model = LinearRegression()
# fit関数でパラメータ推定
# dataは2変数なので重回帰分析になる
model.fit(data, target)
# 推定
model.predict([[0.3, 4]])
array([4.24007956])
結果はarray([4.24007956])なので、約 $4,240
非線形回帰モデル
データの構造を線形で捉えられる場合は限られており、非線形な構造を捉えられる仕組みが必要である、よく使われるのが基底展開法。 基底展開法では、- 回帰関数として、基底関数(
未知パラメータは線形回帰モデルと同様に最小2乗法や最尤法により推定する。 MSE最小化によって得られる推定量()と予測値()はそれぞれ、
となる。ただし
である。
よく使われる基底関数には、多項式関数、ガウス型基底関数、スプライン関数/ Bスプライン関数などがある。
多項式関数
ガウス型基底関数
参考(基底関数について)
未学習(underfitting)と過学習(overfitting)
- 学習データに対して、十分小さな誤差が得られないモデル->未学習
- 対策: 表現力の高いモデルを利用する
- 小さな誤差は得られたけど、テスト集合との差が大きいモデル->過学習
- 対策1: 学習データを増やす
- 対策2: 不要な基底関数(変数)を削除して表現力を抑止
- 対策3: 正則化法を利用して表現力を抑止
正則化法(罰則化法)
- 「モデルの複雑化にしたがって値が大きくなる正則化項(罰則化項)を課した」関数を最小化
- 形状によって種類がある
- L2ノルム: Ridge推定量
- L1ノルム: Lasso推定量
- 正則化(平滑化)パラメータ(ハイパーパラメータ)
- モデルの曲線のなめらかさを調節する
-
(\boldsymbol{y}-\Phi\boldsymbol{w})^\top(\boldsymbol{y}-\Phi\boldsymbol{w}) -
\gamma R(w) -
\gamma \gamma > 0
参考
実装演習
モジュールインポート〜データ生成
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#seaborn設定
sns.set()
#背景変更
sns.set_style("darkgrid", {'grid.linestyle': '--'})
#大きさ(スケール変更)
sns.set_context("paper")
n=100
# 真の関数
def true_func(x):
z = 1-48*x+218*x**2-315*x**3+145*x**4
return z
def linear_func(x):
z = x
return z
# 真の関数からノイズを伴うデータを生成
# 真の関数からデータ生成
data = np.random.rand(n).astype(np.float32)
data = np.sort(data)
target = true_func(data)
# ノイズを加える
noise = 0.5 * np.random.randn(n)
target = target + noise
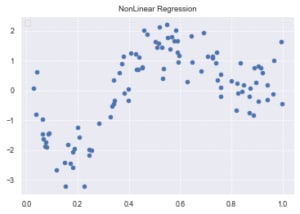
# ノイズ付きデータを描画
plt.scatter(data, target)
plt.title('NonLinear Regression')
plt.legend(loc=2)
線形回帰
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
data = data.reshape(-1,1)
target = target.reshape(-1,1)
clf.fit(data, target)
p_lin = clf.predict(data)
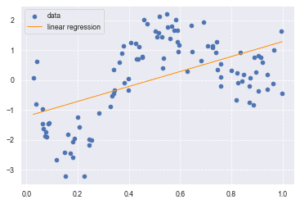
plt.scatter(data, target, label='data')
plt.plot(data, p_lin, color='darkorange', marker='', linestyle='-', linewidth=1, markersize=6, label='linear regression')
plt.legend()
print(clf.score(data, target))
0.28071805923260373
カーネルリッジ回帰
from sklearn.kernel_ridge import KernelRidge
# RBF (Radial Basis Function) カーネルを使用。alpha=0.0002 は正則化の強さを示す
clf = KernelRidge(alpha=0.0002, kernel='rbf')
clf.fit(data, target)
p_kridge = clf.predict(data)
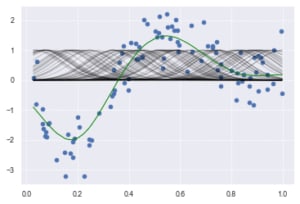
plt.scatter(data, target, color='blue', label='data')
plt.plot(data, p_kridge, color='orange', linestyle='-', linewidth=3, markersize=6, label='kernel ridge')
plt.legend()
#plt.plot(data, p, color='orange', marker='o', linestyle='-', linewidth=1, markersize=6)

Ridge Regression (with RBF kernel trick)
Ridge回帰を使用しているがカーネルトリックを使用して非線形の関係も表現
#Ridge
from sklearn.metrics.pairwise import rbf_kernel
from sklearn.linear_model import Ridge
# rbf_kernelを計算
kx = rbf_kernel(X=data, Y=data, gamma=50)
# alpha=30は正則化の強さを示すパラメータ
clf = Ridge(alpha=30)
clf.fit(kx, target)
p_ridge = clf.predict(kx)
plt.scatter(data, target,label='data')
for i in range(len(kx)):
plt.plot(data, kx[i], color='black', linestyle='-', linewidth=1, markersize=3, label='rbf', alpha=0.2)
plt.plot(data, p_ridge, color='green', linestyle='-', linewidth=1, markersize=3,label='ridge regression')
print(clf.score(kx, target))
0.8159015928124493
Polynomial Regression(多項式回帰)
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
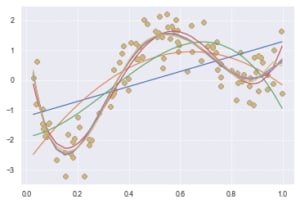
# 1次から10次までの多項式回帰を実施
deg = [i for i in range(1, 10)]
for d in deg:
regr = Pipeline([
# PolynomialFeaturesを用いて与えられたデータを多項式の特徴に変換
('poly', PolynomialFeatures(degree=d)),
('linear', LinearRegression())
])
regr.fit(data, target)
p_poly = regr.predict(data)
plt.scatter(data, target, label='data')
plt.plot(data, p_poly, label='polynomial of degree %d' % (d))
Lasso Regression (with RBF kernel trick)
Lasso回帰を使用するが、Ridge回帰のコードと同様にカーネルトリックを使用して非線形を表現
#Lasso
from sklearn.metrics.pairwise import rbf_kernel
from sklearn.linear_model import Lasso
kx = rbf_kernel(X=data, Y=data, gamma=5)
#lasso_clf = LinearRegression()
# alpha:正則化の強さを示すパラメータ。この値が大きいと多くの係数が0になる
lasso_clf = Lasso(alpha=10000, max_iter=1000)
lasso_clf.fit(kx, target)
p_lasso = lasso_clf.predict(kx)
plt.scatter(data, target)
plt.plot(data, p_lasso, color='green', linestyle='-', linewidth=3, markersize=3)
print(lasso_clf.score(kx, target))
-2.220446049250313e-16
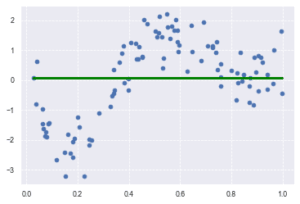
ロジスティック回帰モデル
- 分類問題を解くための教師あり機械学習モデル
- 入力とm次元パラメータの線形結合をシグモイド関数(下式右辺)に入力することで出力は
(0,1) - シグモイド関数の微分については下記のような性質がある。 (シグモイド関数の微分はシグモイド関数で表される)
ロジスティック回帰の式
シグモイド関数とその微分
とした時、
- ロジスティック回帰のパラメータは最尤推定法を用いて推定することが多い。
- 最尤推定とは 尤度関数を最大化するパラメータを推定する手法。 実際には、対数をつけ符号を逆にした対数尤度関数の最小化を行うことが多い。
尤度関数
対数尤度関数
この対数尤度関数のパラメータによる微分が0になる値を、最小二乗法のときのように解析的に求めるのは難しいため、勾配降下法や確率的購買降下法などの最適化アルゴリズムにより求める。
-
勾配降下法:関数の傾きを元に評価関数の最小値を探す手法。利用するデータの量によって3種類に分けられる。
- 最急降下法(バッチ勾配降下法):全データを使用
- 確率的勾配降下法(SGD):ランダムに抽出した1つのデータを使用
- ミニバッチ勾配降下法:データの一部を利用
最適化するパラメータを
最急降下法
確率的勾配降下法(SGD)
また、パラメータ更新のしに、学習速度を早めるために完成功を追加するモメンタムという手法がある。
モメンタムなしのパラメータの更新を
参考)勾配降下法について
分類問題の評価方法
- 混同行列を作成する(分類問題において、予測と実際の分類を行列形式にまとめたもの)
- 各指標を計算する
- 正解率(Accuracy)
- 適合率(Precision)
- 再現率(Recall)
- F値(F-measure)
- AUC(ROC曲線、PR曲線)
- etc...
参考
実装演習
タイタニックの乗客データを利用してロジスティック回帰モデルを作る(2変数から生死を判別する)。
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
%matplotlib inline
# titanic data csvファイルの読み込み
titanic_df = pd.read_csv('./data/titanic_train.csv')
# 前処理
#予測に不要と考えるカラムをドロップ
titanic_df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
#nullを含んでいる行をチェック → Age列が該当
titanic_df.loc[:, titanic_df.isnull().any()].head(10)
# Ageカラムのnullを中央値で補完
titanic_df['AgeFill'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
#再度nullを含んでいる行を表示 (Ageのnullは補完されている)
# titanic_df[titanic_df.isnull().any(1)]
#運賃だけのリストを作成
data1 = titanic_df.loc[:, ["Fare"]].values
#生死フラグのみのリストを作成
label1 = titanic_df.loc[:,["Survived"]].values
# 性別を 0, 1に変換(男性は1、女性は2)
titanic_df['Gender'] = titanic_df['Sex'].map({'female': 0, 'male': 1}).astype(int)
# 乗船クラス(1,2,3|1が最も等級が高い) と性別(0, 1)を足した列を作成。(別々の方が良い気もする)
titanic_df['Pclass_Gender'] = titanic_df['Pclass'] + titanic_df['Gender']
# 不要な列を削除
titanic_df = titanic_df.drop(['Pclass', 'Sex', 'Gender','Age'], axis=1)
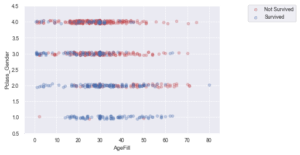
# Pclass_Gender と AgeFillを軸にして、生死との関係性をマッピングしてみる
np.random.seed = 0
xmin, xmax = -5, 85
ymin, ymax = 0.5, 4.5
index_survived = titanic_df[titanic_df["Survived"]==0].index
index_notsurvived = titanic_df[titanic_df["Survived"]==1].index
from matplotlib.colors import ListedColormap
fig, ax = plt.subplots()
cm = plt.cm.RdBu
cm_bright = ListedColormap(['#FF0000', '#0000FF'])
sc = ax.scatter(titanic_df.loc[index_survived, 'AgeFill'],
titanic_df.loc[index_survived, 'Pclass_Gender']+(np.random.rand(len(index_survived))-0.5)*0.1,
color='r', label='Not Survived', alpha=0.3)
sc = ax.scatter(titanic_df.loc[index_notsurvived, 'AgeFill'],
titanic_df.loc[index_notsurvived, 'Pclass_Gender']+(np.random.rand(len(index_notsurvived))-0.5)*0.1,
color='b', label='Survived', alpha=0.3)
ax.set_xlabel('AgeFill')
ax.set_ylabel('Pclass_Gender')
ax.set_xlim(xmin, xmax)
ax.set_ylim(ymin, ymax)
ax.legend(bbox_to_anchor=(1.4, 1.03))
# 説明変数を作成(運賃、乗船クラス+性別)
data2 = titanic_df.loc[:, ["AgeFill", "Pclass_Gender"]].values
# 目的変数(生死フラグ)
label2 = titanic_df.loc[:,["Survived"]].values
# モデルの学習
model2 = LogisticRegression()
model2.fit(data2, label2)
# 運賃10, 乗船クラス+性別が1の乗客の生死フラグと予測確率を表示
print('静止フラグ(予測):', model2.predict([[10,1]]))
print('予測確率:', model2.predict_proba([[10,1]]))
# モデルの回帰係数と切片を表示
print("回帰係数:", model2.coef_)
print("切片", model2.intercept_)
静止フラグ(予測): [1]
予測確率: [[0.03754749 0.96245251]]
回帰係数: [[-0.04622413 -1.51130754]]
切片 [5.2174269]
サポートベクターマシン
- 教師あり学習の一つであり、回帰または分類に適用できる。
- データ
x {\rm sign}(\boldsymbol{\omega}^\top \boldsymbol{x} + b) - 分類境界に最も近い各クラスのデータ(サポートベクトル)までの領域をマージンと呼び、このマージンが最大化するように
\boldsymbol{\omega}^\top b - 分類誤りを許容しない分類(完全分離可能な問題のみ対応)をハードマージンというのに対し、多少の分類誤りを許容して使い勝手を上げた分類をソフトマージンという。
SVMのパラメータ推定問題は以下の最適化問題として定義できる。
ハードマージン
ソフトマージン マージン内に入るデータの誤差を表す変数(スラック変数
一般に過学習を防ぐためには
カーネルを用いた非線形分離への拡張
データの形状によっては、線形分離でデータをうまく分類できない場合がある。このような場合に、元データをより高次元に写像することで分類を可能にする方法がある。下記のような写像を考える。
このとき、元のデータ
であるが、写像によってデータを変形した後の双対問題は、
となる。
上式における内積
参考)
- [機械学習]サポートベクトルマシン(SVM)について、できるだけ分かりやすくまとめていく①~理論と数式編~
- [機械学習]サポートベクトルマシン(SVM)について、できるだけ分かりやすくまとめていく②~ラグランジュの未定乗数法~
- [機械学習]サポートベクトルマシン(SVM)について、できるだけ分かりやすくまとめていく③~カーネル法について~
- [機械学習]サポートベクトルマシン(SVM)について、できるだけ分かりやすくまとめていく④~ソフトマージンとハードマージンの実装~
- [機械学習]サポートベクトルマシン(SVM)について、できるだけ分かりやすくまとめていく⑤~カーネル法を用いた分類の実装~
- カーネルトリック
実装演習
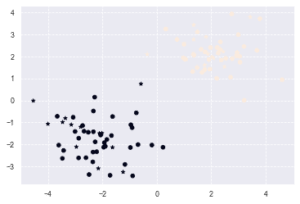
線形分離可能なデータの分類.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# 2値分類したデータを生成する関数
def gen_data():
x0 = np.random.normal(size=100).reshape(-1, 2) - 2.
x1 = np.random.normal(size=100).reshape(-1, 2) + 2.
X = np.concatenate([x0, x1])
y = np.concatenate([np.zeros(50), np.ones(50)]).astype(int)
return X, y
X, y = gen_data()
# 訓練データと検証データに分類
x_train, x_test, y_train, y_test = train_test_split(X, y, random_state=0)
# サポートベクター分類の線形カーネルを使う
svc = SVC(kernel='linear')
# 学習
svc.fit(x_train, y_train)
# 予測
y_pred = svc.predict(x_test)
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train)
plt.scatter(x_test[:, 0], x_test[:, 1], c=y_pred, marker="*")
主成分分析
データを線形変換することで多変量データの変数を情報量の損失を防ぎながら縮約する手法。
- 多次元を低次元にすることで、少数変数を利用した分析や可視化がしやすくなる。
- 各主成分は互いに直行するように選ばれる。 情報量を分散の大きさととらえ、線形変換後の変数の分散が最大となる射影軸を探す。
平均化したベクトルを
目的関数は
制約条件(
制約つき最適化問題はラグランジュ関数を最大にする係数ベクトルを探索することで求められる。 これは、ラグランジュ関数が微分して0になる点なので、元のデータの分散共分散行列の固有値と固有ベクトルが解となる。
参考)ラグランジュの未定乗数法について
ラグランジュ関数
寄与率
第
k番目の固有値に対応する固有ベクトルを第k主成分と呼ぶ。
累積寄与率
第1から
実装演習
# モジュールインポート〜前処理
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegressionCV
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
cancer_df = pd.read_csv('data/cancer.csv')
cancer_df.drop('Unnamed: 32', axis=1, inplace=True)
y = cancer_df.diagnosis.apply(lambda a: 1 if a == 'M' else 0)
X = cancer_df.loc[:, 'radius_mean':]
# 学習用とテスト用のデータ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# データの特徴量のスケールがバラバラなので標準化する
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# PCAを実施。まずは寄与率をみてみる。
pca = PCA(n_components=30)
pca.fit(X_train_scaled)
plt.bar([n for n in range(1, len(pca.explained_variance_ratio_)+1)], pca.explained_variance_ratio_)
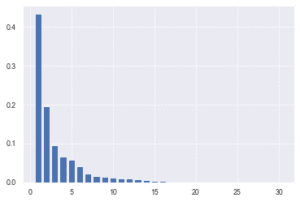
第二主成分まででも類式寄与率は60%を超えるので、データの6割以上を説明できているといえる。
# 次元数2まで圧縮
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train_scaled)
# 散布図にプロット
temp = pd.DataFrame(X_train_pca)
temp['Outcome'] = y_train.values
b = temp[temp['Outcome'] == 0]
m = temp[temp['Outcome'] == 1]
plt.scatter(x=b[0], y=b[1], marker='o') # 良性は○でマーク
plt.scatter(x=m[0], y=m[1], marker='^') # 悪性は△でマーク
plt.xlabel('PC 1') # 第1主成分をx軸
plt.ylabel('PC 2') # 第2主成分をy軸
Text(0, 0.5, 'PC 2')
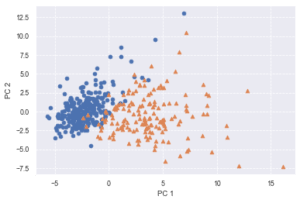
散布図を見るに PCA後の第1,第2主成分だけでもある程度の精度で線形分類できそうだと考えられる。
k近傍法
k近傍法は教師あり学習のひとつで、分類問題を解くための手法
- 新しいデータ
x x k x -
k -
k - 数式をモデルを使わない、ノンパラメトリックな手法
- 最近傍法はk近傍法でk=1の場合と同義
参考
k-means(k-平均法)
- 教師なし学習の一つでクラスタリング手法。
- 与えられたデータを
k -
k
アルゴリズムの概要
- 各クラスタ中心の初期値を設定する。
- 各データ点に対して、各クラスタ中心との距離を計算し、最も距離が近いクラスタを割り当てる。
- 各クラスタの平均ベクトル(中心)を計算する。
- 収束するまで2, 3の処理を繰り返す。
より良好な会を得るためには、最初に割り当てるクラスターや各種条件(設定するクラスタ)などを変えたりすることが有効
参考
以上
Discussion