Go
memo
- Go はunicodeとutf8を利用しているため、絵文字なども使える。
- Goは静的型付けされた言語。
-
var 変数名 = 値を変数名 := 値と書くことができる。(省略) -
a, b, c := 1, "2", 3のように連続して変数を宣言、代入することができる。 - 未使用変数があるとエラーになる。
- 基本的にショートハンドで変数宣言を行うが、初期値が欲しい場合にvarを使って宣言を行う。
- 初期値とは、宣言した変数の型に応じて割り当てられる決まった値。例えば、
intであれば0、stringであれば空文字、boolであればfalse - 関数スコープの外では変数宣言のショートハンド
:=は使用できない。 - 関数の二つ以上の引数の型が同じ場合、省略できる。
func add (x, y int) int {}※xもyもint型 - 関数は複数の戻り値を返すことが出来る。
func swap (x, y string) (string, string) { return y ,x }
- 以下をnaked returnという。この場合、x,yが戻り値となる。ただ、可読性が悪くなるためあまり使わないかも。
func split(sum int) (x, y int) {
x = sum * 4 / 9
y = sum - x
return
}
- 定数はconstを使って宣言出来る。が、constの宣言にショートハンドは使えない。
-
go buildコマンドで実行可能なファイルを作成する。 - goの環境変数
GOOSGOARCHに値を入れ替えることでどの環境に対してファイルを作成するかを変更できる。デフォルトでは自分の環境になっている。ちなみにgo環境変数をグローバルにセットする場合は、export 環境変数名=値で設定できる。 - go 環境変数の確認は
go envでできる - ファイル内で宣言した関数名、変数名の最初の文字が大文字の場合、外にエクスポートしていることになる。小文字の場合、外部からその関数、変数を使用することはできない。
- パッケージごとにinit関数を定義することができる。init関数はパッケージに定義されているmain関数よりも先に実行される。(initという名前からもわかるように初期化などに使われる。)
- なお、init関数より先にパッケージにimportされているパッケージの方が先に実行される。
- init関数は何個でも書くことができる。一応内部的に別物として分けられているらしい。
- main.goファイルの
package mainfunc mainがモジュールのエントリポイントとなるため、必須。なお、func mainは引数を取らず、何もreturnしてはいけない。
goの型
- bool
true false - string
文字列。string →[]byte(byte配列)に変換することができる。逆も然り。 - numeric types
数値型。以下の型がある。- int int8 int16 int32(rune) int64
符号ありの整数型。int8は-128から127まで、int64はint64は-9223372036854775808から9223372036854775807格納できる。 - uint uint8(byte) uint16 uint32 uint64
符号なしの整数型(-にならない整数型)。uint8(byte)は0から255まで、uint64は0から18446744073709551615まで格納できる。 - uintptr
? - float32 float64
浮動小数点数。基本64推奨。 - complex64 complex128
?
- int int8 int16 int32(rune) int64
- array
配列。長さが変えられない。基本的には開発の際は使わないらしい。
// 3つの数字データの配列
var a := [3]int{ 1, 2, 3 }
// データの数がわからない場合は、...を鉤括弧に書けば自動的に計算してくれる。
var b:= [...]int{1, 2, 3, ....
- slice
配列。こちらを基本使用する。長さが変えられる(apendしたりできる)
// 鉤括弧の中には何も書かない。それがslice型を意味することになる。
var a := []int{ 1, 2, 3 }
- map
連想配列。jsのオブジェクト的な型。配列と違って順不同。キーと値は全て同じ型でなくてはならない。
参照型。 - struct
構造体。Classの代わりみたいな感じ。作りはオブジェクト的な感じ。キーと値の型はバラバラでも良いのがmapのが違い。よく使いそう。
Go runtime system
コンパイラ
go言語を機械言語に変換する。
メモリ
これらのメモリ領域の使用判断はGoによって行われる。
- stack
メモリ領域。実行中の処理の変数や関数などを保持するための領域。LIFO(last in first out)※新しく追加されたデータから先に取り除く。heapより高速なため基本的にはこちらが使用される。 - heap
メモリ領域。stackより長期で保持するデータや大量のデータなどを保持するための領域。遅い。不要になったデータはガベージコレクターによってdeallocateされる。
並行処理(concurrency)と並列処理(parallelism)
- 並行処理
一つのCPUにおいて、特定の時間範囲の中で、複数の処理を実行できる構成のこと。並行処理とはプログラ ミングのパターンである。例えば、オーケストラの指揮者をイメージするとわかりやすい。指揮者は色々な演奏者がどこで演奏すべきかをコントロールする。並行処理とは、その特定の時間範囲の中で、どの処理がいつ実行されるべきかのコントロールをすること。 - 並列処理
同時に複数の処理を実行すること。マルチCPUのPCであれば「並行」処理が書かれたコードを「並列」処理することができる。
- race conditin
並行処理を実行する際、共有している変数への更新処理などが前後することで、意図した結果にならない場合がある。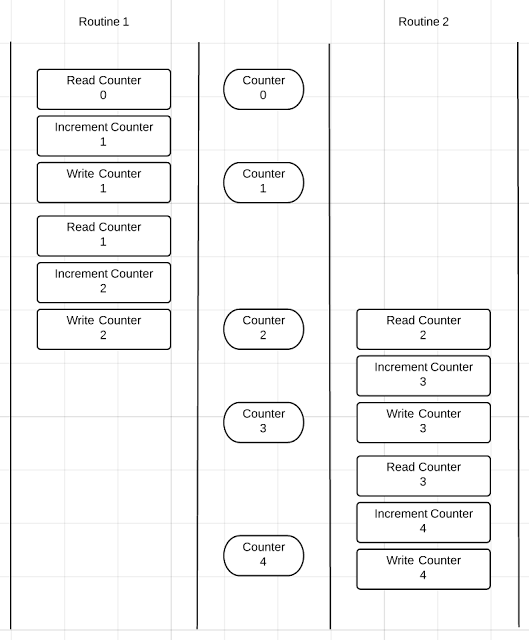
文法
比較演算子
==, !=, <=, <, >, >=
論理演算子
&&, ||, !
if文内での変数宣言
if文の条件式に変数宣言ができる。
package main
import "fmt"
func calculateValue() int {
return 15
}
// ここでvalue変数を定義してそれを条件式に使用している。
func main() {
if value := calculateValue(); value > 10 {
fmt.Println("The value is greater than 10")
}
}
comma ok (カンマOK慣用句)
以下の2パターンを判定するために使われるらしい。
- map(オブジェクト的なもの)の中にあたいが存在しているかどうか判定する時
// mapの作成
f := map[string]int {
"Apple": 1,
"Banana": 2,
}
if s, ok := f["Apple"]; ok {
// do something
}
- 型があっているかどうかを判定する時
var test interface {}
test = 123
if t, ok := test.(int); ok {
// do something
}
switch文
jsと大体同じ。違いとしては、
-
switch 対象 {}の対象の部分に何も書かずにcaseに条件文を書ける。switch { ... case x > 10: ...} - breakを書かなくて良い(デフォでbreakと同じ挙動)
- case に複数の値を設定できる。
case 1 ,2, 3 -
fallthroughを使うと次のcase内の処理を強制的に実行する。fallthroughを書いたのに、次のケースがなければエラーとなる。
switch x {
case 1 :
xxx(yyy)
// そのまますぐ次の case 2: に行く。
fallthrough
case 2: ....
}
select文
書き方はswitch文と同じ感じ。チャンネルという概念の理解が必要。
switch文と違い、上のcaseから順に実行されるのではなく、チャンネルへの送受信が実行可能かを判断して実行されるらしい。複数のチャネルが実行可能と判断された場合はその中からどれか一つがランダムに実行される。また、すべてのケースに当てはまらない場合、defaultに飛ぶが、defaultがないとselect文がブロックされる。
// 二つのチャンネルをランダムな時間経過後に作成する処理
d1 := time.Duration(rand.Int63n(250))
d2 := time.Duration(rand.Int63n(250))
go func (){
time.sleep(d1 * time.Millisecond)
ch <- 41
}
go func (){
time.sleep(d2 * time.Millisecond)
ch <- 42
}
// 先に作成されたチャネルに応じて処理を行うselect文
select {
case <-ch1:
// ch1から受信したときに実行される処理
case v := <-c2:
// ch2から受信したときに実行される処理
// 変数に値を入れることもできる
default:
// どのcaseも準備できていないときに実行される処理(省略可能)
}
for文
基本JSなどと同じ。書き方応じてwhile文のように使える。
// 通常のfor文
for i := 0; i < 5; i++ {
// 処理
}
// while文
var x int = 0
for x < 20 {
x++
}
// 条件を内部に持つfor文
y := 10
for {
if(y > 20){
break
}
y++
}
for ... range文
foreachと同じ。
// 配列のループ。i は回数、vは値。
for i, v := range []string{"foo", "bar", "baz"} {
fmt.Println(i, v)
// 0 foo
// 1 bar
// 2 baz
}
// 連想配列のループ。kはキー、vは値。
for k, v := range map[string]int{"key-1": 100, "key-2": 200, "key-3": 300} {
fmt.Println(k, v)
// key-2 200
// key-3 300
// key-1 100
}
配列(slice)の操作
sliceは内部的にはarrayである。sliceはただarrayをPointerで指しているだけ。そのため、jsなどと同様、別物として作成しないと、同じメモリ番地を参照してしまうため注意。
- 値の追加(append)
xi := []int{0,1,2,3,4}
xi = append(xi, 20,21,22)
fmt.Println(xi) // [0, 1, 2, 3, 4, 20, 21, 22]
- 切り取り(slice)
xi := []int{0, 1, 2, 3, 4, 5, 6}
// 配列のインデックス0番目以上〜4番目未満を取得
fmt.Println(xi[0:4]) // [0, 1, 2, 3]
// 配列のインデックス1番目以上を取得
fmt.Println(xi[1:]) // [1, 2, 3, 4, 5, 6]
// 配列のインデックス6番目未満を取得
fmt.Println(xi[:6]) // [0, 1, 2, 3, 4]
// 全取得
fmt.Println(xi[:]) // [0, 1, 2, 3, 4, 5, 6]
- 削除(delete)
xi := []int{0, 1, 2, 3, 4, 5, 6}
// sliceとappendを使ってインデックス3番目の値(2)を取り除く。
xi = append(xi[:3], xi[4:]...) // sliceの後に``「...」をつけることで配列を展開できる。
fmt.Println(xi) // [0, 1, 3, 4, 5, 6]
- sliceの作成(make)
// 中身が空のint配列を作成し、配列の長さをarray型のように限定することができる。
xi := make([]int, 0,3) // 長さが3の配列
// ただし、長さを超えてappendされた場合は、自動的に長さが伸びる。(makeで指定した最大値分)
xi = append(xi,0, 1, 2, 3, 4, 5, 6, 7)
fmt.Println(len(xi)) // 8
fmt.Println(cap(xi)) // キャパシティを返す関数で9となる。 (最大値3の倍数)
- 複製(copy)
a := []int{1,2,3,4,5} // 中身のあるsliceを作成
b := make([]int, len(a)) // 中身のない、長さがa配列と同じ配列を作成。
copy(b, a) // bにaの中身をコピーする
なお、コピー先とコピー元のsliceは同じ型である必要がある。
- 展開
配列の展開にはjsのようにドット三つをつける。
func main() {
xi := []int{1, 2, 3, 4, 5, 6}
x := sum(xi...)
}
- 注意
配列やスライスから参照でスライスを作成する際、以下のようにスライス(or配列)の開始位置の方向から排除した値は戻ってこない。
// 配列
arr := [4]string{a, b, c, d}
// スライス1
slice1 := arr[1:3] // b,c
slice2 := slice1[0:2] // b,c
上記例では、slice1とslice2は同じarrを参照しているため、slice2は一見、a, b, cとなりそうに見えるが、slice1作成時点で開始一方向から切り取る位置を1と指定したため、それより前の位置にあったaはすでになくなっている。
ただし、逆に終了位置の指定だと、
// 配列
arr := [4]string{a, b, c, d}
// スライス1
slice1 := arr[1:3] // b,c
slice2 := slice1[0:4] // b,c,d
slice1作成時点でdはカットしたはずだが、slice2で復帰している。
連想配列(map)の操作
- mapの作成
a := map[string]int{
"A": 1,
"B":2
}
// makeを使った方法
b := make(map[string]int)
b["c"] = 100
fmt.Println(len(b)) // 1
- mapのrange over
a := map[string]int{
"A": 1,
"B": 1
}
// 第一引数にkey、第二引数にvalueをとる。
for k, v:= range a {
fmt.Println(k,v)
}
- 削除(delete)
sliceと違ってビルトインのdelete関数が存在する。
a := map[string]int{
"A": 1,
"B": 1
}
// 第一引数にmap、第二引数にキー
delete(a, "A")
- comma ok
mapは存在しないキーにアクセスしてもデフォルト値を返却するため、実際に存在するキーなのか、存在しないけどデフォルト値が返却されたのかが判別できない。そこで、comma ok を使用することで存在の確認を行うことができる。
a := map[string]int{
"A": 1,
"B": 1
}
// キー「C」はmap「a」に存在しないので、okがfalseとなる。
if v ,ok := a["C"]; ok{
fmt.Println("key exists")
} else{
fmt.Println("not ok")
}
- makeを使って作れる
配列と同様にmapもmakeで作成することができる。ただし、長さのみ指定可能。
//
sample := make(map[string]string,3)
構造体(struct)
type person struct {
first string
last string
age int
}
type chef struct {
person
first string
cookingLicens bool
}
func main () {
chef1 := chef {
person: person {
first: "AAA"
last: "BBB"
age: 45
},
first : "CCC"
cookingLicense: true,
}
// chef1.person.firstとしなくてもchef1.firstでアクセスできる。
// ただし、chef1.firstにすでに何か定義されていた場合はそちらが優先される。
fmt.Println(chef1.first, chef1.person.first, chef1.age) // CCC AAA 45
}
- 無名の構造体
p1 := struct {
first string
last string
age int
} {
first: "AAA"
last: "BBB"
age: 45
}
関数(func)
- 可変超引数
個数を限定しない引数を入れたい場合は以下のように定義する。
func sum (nums ...int) int {
n := 0
for _, v := range nums {
n += v
}
}
// 他の引数を指定する場合は、最後に指定する必要がある。
func sum (i int, s string, nums ...int) int {
n := 0
for _, v := range nums {
n += v
}
}
- defer
囲っている関数自体が終了するか(ここではmain)、リターンするか、gorutineがパニックになるまでその処理の実行を遅らせることができる。
例えば、必ずリリースする必要のあるリソースなどに対してdeferを使う。
~
{
f, err := os.Open(filename)
if err != nil {
return "", err
}
defer f.close() // このブロックの全ての処理が終了した際に実行される。
~
}
- メソッドのアタッチ
type Person struct {
first string
}
// 関数名の前に()書いてその中にアタッチするstructを書く。
func (p Person) speak() {
fmt.Println("I am", p.first)
}
func main() {
p1 := Person{
first: "James",
}
p1.speak()
}
- interface
特定のメソッドを持つ型を一括りにして扱える仕組み。
例えば、Aというメソッドを持つ型が複数ある時、以下のようにinterface b を定義した場合メソッドAを持つ型は全てinterface Bでもある、ということになる。
type a1 struct {
name string
}
type a2 struct {
name string
}
// 上記二種のstructにAメソッドをアサインする
func(a a1)A(){ ... }
func(a a2)A(){ ... }
// struct a1とa2は同時にinterface b でもある。
type b interface {
A()
}
また、interface型以外であれば、プリミティブな型にもinterfaceを定義することができる。
type A int
func (a A) String() string {
....
}
また、goのビルトインパッケージの中にはパッケージ内にinterfaceが定義されているものがある。
- Stringer
Stingerはfmtパッケージに含まれているinterfaceでprintで文字列出力する際に、カスタマイズした形で出力することができる。
type book struct {
title string
}
func(b book)String() string {
return fmt.Sprint(b.titile," is a book")
}
func main () {
b := book{ title: "AAAA"}
// 本来structをprintした場合、{ title: "AAAA" }と出るが、
// Stringerをつかって出力内容をカスタムしたため、「AAAA is a book」と出る。
fmt.Println(b)
}
ユニットテスト
go言語のテストはビルトインのtestingパッケージを使用して行う。
- package名_test.goでファイルを作成。(例:main_test.go)
- ファイル内ではtestingパッケージをインポート
- package名はテストしたいpackageと同じ
- テスト用関数の関数名は必ず、TestXxxと命名(Xxxの部分はテストしたい関数名の先頭文字を大文字にしたもの)
- 引数には(t *testing.T)を入れる。
package main
import "fmt"
func sum(a int, b int) int {
return a + b
}
func main() {
a := sum(1, 2)
fmt.Println(a)
}
package main
import "testing"
func TestSum(t *testing.T) {
total := sum(1, 2)
if total != 3 {
t.Errorf("Sum was incorrect, got %d, want %d", total, 3)
}
}
ポインタ
例えば、1+1のような計算をする場合、「1」、「+」、「1」という値を保持する必要がある。人間が計算する時と同じ。脳にそれら値を記憶する必要がある。PCの場合その記憶する場所がメモリである。メモリにはそれぞれ場所がわかるようにアドレスが存在し、ポインタはメモリのアドレスのことである。
例えば、以下のように変数を定義した場合、値1は特定の場所に保持される。その値の保持されているアドレスを知りたい場合「&」オペレータを使うことでアドレスがわかる。
x := 1
fmt.Println(&x)
また、ポインタの型は「*」を使って表現できる。
x :=1
fmt.Printf("%T", &x) // *int
s :="AAAAA"
fmt.Printf("%T", &s) // *string
- ポインタの示すアドレスにある値を参照したい場合
「*」をポインタの前にかく
s :="AAAAA"
x := &s // ”AAAAA”が保持されているメモリのアドレスをxに代入している。
// sに保持されている値を参照できる
fmt.Println(*x) // AAAAA
// これでも同じ結果
fmt.Println(*&s) // AAAAA
// こんなこともできる
// s変数の値を参照して代入
*x = "BBBBB"
fmt.Println(s) // BBBBB
- goの参照型
以下は変数に値を格納した時、値を参照するためのアドレスが代わりに使用される- ポインタ
- スライス(配列)
- マップ(連想配列)
- Channel(マルチスレッド間で使用)
- 関数
- Interface
- セマンティクス
値セマンティクスと参照セマンティクスがある。- 値セマンティクス... コピーされた値
- 参照セマンティクス...参照されたメモリ
例えば、以下の例でaddOneの引数は値セマンティクスでadOnePの引数は参照セマンティクスである。
// 引数はコピーされて別の値vに+1される
addOne(v int) int {
return v + 1
}
// 引数はポインタのため、ポインタが指す値に対して+1される
addOneP(v *int) {
*v+=1
}
a := 1
// addOneの戻り値は2だが、変数aは不変。
addOne(a)
fmt.Println(a) // 1
// addOnePの引数で指定されたポインタが示す変数に対して+1される
addOneP(&a)
fmt.Println(a) // 2
なお、基本的には値セマンティクスを使用する。参照セマンティクスはバグの特定が難しくなるため。
参照セマンティクスを使用するケースとしては、
- データ量が大きい場合など。引数に入れて関数内でコピーされた値を使用する場合、コピーにかかる時間やコピー先のメモリなどを節約するため。64バイト以上で検討した方が良いらしい。
- メソッドのレシーバや引数を変更できるようにしたい場合
- 特定の型が持つメソッドの引数がポインタの場合(メソッドの引数を統一して混乱を避ける)
- goの標準ライブラリの関数が要求する場合
ジェネリクス
- 型の制約
type myNumbers interface {
int | float64
}
func add [T myNumbers](a, b, T) T {
return a + b
}
- タイプエイリアス
type myTypeAlias int
var n myTypeAlias = 42
以下の場合、基本的にはadd関数の引数の型intとmyTypeAlias型が違うためエラーになる。
func add(a, b int) int {
return a + b
}
add(n,2) // エラー
ただし、引数の型を以下のように定義した場合は通る(型の前に「~」をつける)
「~」をつけることで、型エイリアスの元となった型を見てくれるようになる。
func add(a, b ~int ) int {
return a + b
}
add(n,2) // OK
-
package constraints
型の制約において頻繁に使われる組み合わせをまとめたもの。
例えば、float32とfloat64の組み合わせの型制約を作成する場合、自前で作らずとも「float」というpakcage constarintsをインポートして使えば良い。
現在goで定義されているpackage constraintsは以下。
https://pkg.go.dev/golang.org/x/exp/constraints -
concrete type と interface type
- concrete type
intやbool、sliceやmapなど定義した後にインスタンス化が可能な型 - interface type
それ自体ではインスタンス化ができない。interface typeに含まれるメソッドを持つ構造体の型(concrete type)をインスタンス化して初めて型として機能する。
- concrete type
jsonデータの扱い
- marshal
いわゆるインメモリ表現(配列、構造体といったデータ構造)のデータをバイト列表現(ただのバイト列、json)にエンコードすること。
b, err := json.Marshal(aaaa)
なお、構造体やmapなどでキ名がキャピタルでないとmarshalで認識されない
type person struct {
First string
Last string
}
// 小文字で認識させたい場合はタグをつける。
type person struct {
First string `json:"first"`
Last string `json:"last"`
}
- unmarshal
marshalの逆。引数にjsonのデータとそれを変換した後に格納するための変数へのポインタをとる。
var aaa []SomeType
err := json.Unmarshal(jsonBlob, &aaa)
REST APIを作る
- 標準のhttpパッケージを使えば、httpステータスコードを以下のようにわかりやすく表現できる。
import "net/http"
http.StatusOK // 200
http.StatusBadRequest // 400
- REST API作成にはginという軽量フレームワークを使うと良さそう。
- 例えば、直接使わないけど、そのパッケージに間接的に必要なパッケージがあり、ファイル保存時にimport文からそのパッケージが消えて欲しくない場合以下のように書けば、残すことができる。
import (
_ "github.com/mattn/go-sqlite3"
)