✨
Internship Memo 01




インターンシップで学んだことについてまとめます.
-
データサイエンスプロジェクトむっずかしい
- 成功を妨げる要員 - 高品質なデータが不可欠 - データインフラが不可欠
要するに,データが未整備
- 成功を妨げる要員 - 高品質なデータが不可欠 - データインフラが不可欠
-
データサイエンティストの仕事の8割が「データの準備や前処理」
-
データエンジニアこれから伸びる(確信)
- データサイエンティストは逆に減少傾向
-
データエンジニア(リング)
- データを収集,保存,分析するためのシステムを設計・構築・運用するエンジニア
- データエンジニアリングライフサイクル
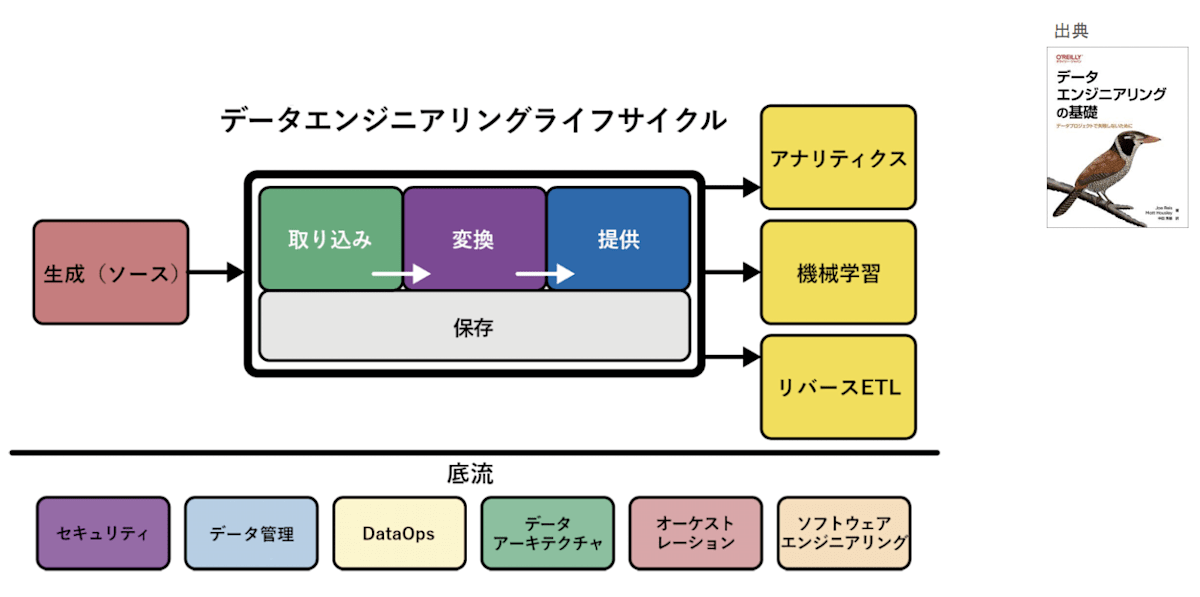
-
DataWarehouse : データを集めて、一箇所に集約、分析しやすく
- データインジェスト:DataWarehouse へのデータ投入
使用したテックスタック
-
クラウドプラットフォーム:AWS
- Amazon のクラウドサービス
-
データウェアハウス:Snowflake
- データ分析に強い DB
-
Infrastructure as Code(IaC):Terraform
- AWS や Snowflake のインフラをコードで管理
-
データモデリング:dbt
- データパイプラインを開発する SQL 実行ツール
- データパイプライン:複数のデータソースからデータを収集、処理、分析し、活用可能な形で提供するための一連のプロセスとツールのこと
- パイプラインの種類
- ETL(Extract, Transform, Load):データを抽出し、データを変換し、データウェアハウスにロードする(従来からある)
- ELT(Extract, Load, Transform):データを抽出し、データをロードし、データを変換する
- パイプラインの種類
-
データ可視化:Snowsight
- データ変換の結果をグラフなどを使って可視化
構築したアーキテクチャ図
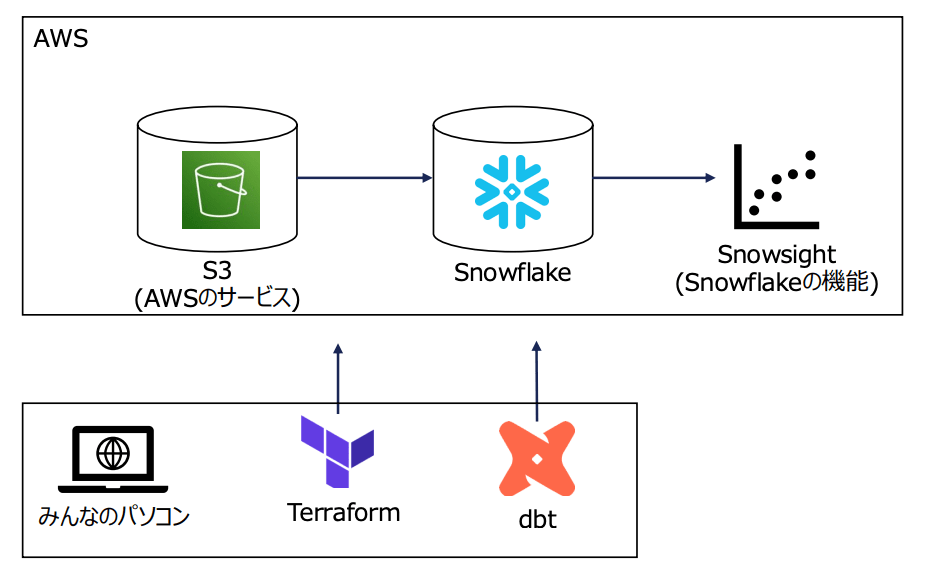
- Snowflake
- クラウドネイティブ:完全にクラウド上で動作するため、ハードウェアの管理や複雑なセットアップが不要
- データの保存と処理の分離
- データの保存(ストレージ)と処理(コンピューティング)を分離している
- 必要に応じて柔軟にリソースを調整可能
- 「スキーマオンリード」という考え方に基づく
- 例えば,Amazon S3(ストレージ)と Amazon EC2(コンピューティング)を組み合わせて使用する場合、データの保存と処理が分離されている
- データの保存(ストレージ)と処理(コンピューティング)を分離している
- Terraform
- インフラストラクチャをコードとして定義可能
- 宣言型のアプローチ
- 宣言型の構成ファイルを使用して、インフラの望ましい最終状態を記述
- ユーザーは具体的な手順を記述する必要がなく、Terraform が必要な操作を自動で判断して実行する
- dbt
- データ変換の役割
- ELT プロセスの T(Transform)を担当
- データウェアハウスにロードされたデータを SQL を用いて変換し、分析に適した形に整える
- 宣言的な SQL モデル
- ユーザーは SQL でデータモデルを定義し、dbt がそれを実行してテーブルやビューを生成
- データ変換のプロセスをコードで管理可能
- https://zenn.dev/dbt_tokyo/books/537de43829f3a0
- データ変換の役割
なぜこの技術を使用したのか?
- Terraform
- インフラストラクチャをコードとして管理することで、インフラの変更履歴を管理しやすくなる
- AWS,Snowflake などのプラットフォームの構築が可能だから
- Snowflake
- Snowsight を使用することで、データの可視化が容易になる
- dbt
- SQL と比較すると,デメリットがないから

- SQL と比較すると,デメリットがないから
Discussion