code2vec ~ プログラミングコードをベクトル化する手法 ~


自身の研究でプログラミングコードをベクトル化する際の技術について調べていたら,code2vec に出会ったので,今回はその手法の流れを自分の備忘録として残しておきます。
TL;DR
- コードスニペット(プログラミングコード)を抽象構文木(AST)に変換して,その構造をベクトル化
- ベクトル化したものを Attention Mechanism というものを使って,コードスニペット全体を表す単一のコードベクトルに変換
- 変換されたコードベクトルは,メソッド名などのコード特性を予測するために使用される
理論の部分
理論の部分に関してはこちらの記事に詳しく書かれています!
「イメージだけ掴みたいよ〜」という方は次の章に進んでください 🚀
手法の流れ ~ イメージ ~
今回は下記の関数名 f のコードスニペットを例にして,code2vec がどのようにしてメソッド名を予測しているのかを見ていきましょう!❤️🔥
boolean f(Object target) {
for (Object elem: this.elements) {
if (elem.equals(target)) {
return true;
}
}
return false;
}
1. 抽象構文木(AST)の生成
code2vec は,コードスニペットから 抽象構文木(AST)を作るためにParserを使用します.
IT 辞書によると,Parser(パーサ)とは以下のように定義されています.
パーサ(parser)とは、コンピュータプログラムのソースコードや XML 文書など、何らかの言語で記述された構造的な文字データを解析し、プログラムで扱えるようなデータ構造の集合体に変換するプログラムのこと。そのような処理のことを「構文解析」「パース」(parse)という。
今回の場合の Parser は,
Java のコードスニペットを解析して,抽象構文木(AST)というデータ構造に変換している
ということですね!
変換されてできた抽象構文木(AST)は下記のようになります 👇
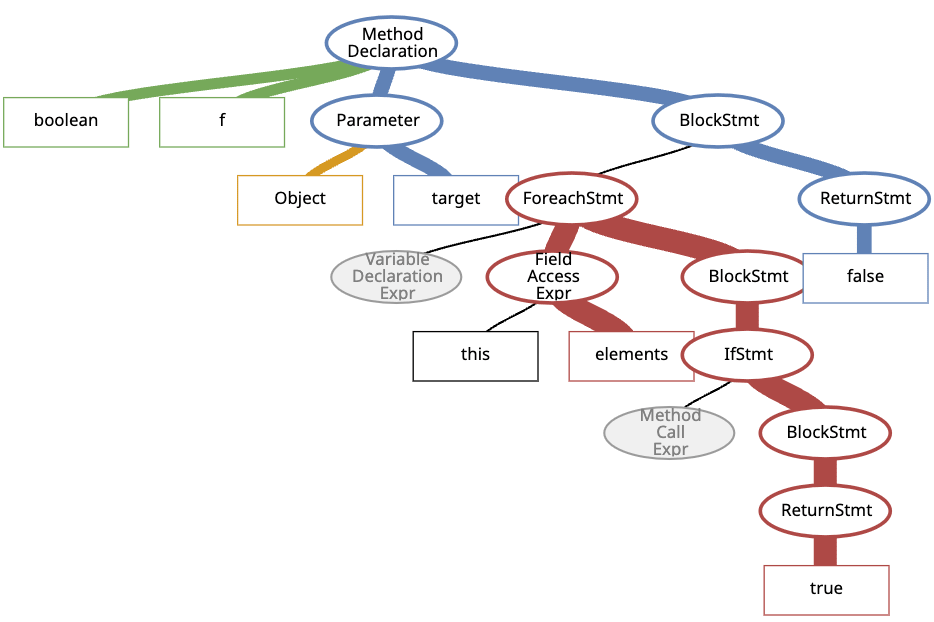
図1:抽象構文木(AST)
2. パスコンテキストの抽出
次に先ほど生成した抽象構文木(AST)からパスコンテキストを抽出します.
下記が論文に記載されているパスコンテキストの定義です.なんのこっちゃ分かりませんね... 😅
Definition (Path-context)
Given an AST Path, its path-context is a triplet < , , > where and are the values associated with the start and end terminals of .
この定義で言いたいこととしては,AST ノード間のパスを取り出して,それぞれを 「始点 - 経路(始点と終点の間の部分) - 終点」 として表現しているということです.
なんのこっちゃ分からないので,具体例で考えていきましょう!
詳しく見ていきましょう 👀
-
開始ノード(x):
- AST における始点
-
経路(p):
- AST における始点と終点の間の部分
-
NameExprからAssignExprへの経路 -
AssignExprからIntegerLiteralExprへの経路
-
- 矢印は AST 内での移動方向を示す
- ↑: 親ノードへ
- ↓: 子ノードへ
- AST における始点と終点の間の部分
-
終点(y):
- AST における終点
経路(p)の AST 構造
AssignExpr
/ \
NameExpr IntegerLiteralExpr
-
AssignExpr: 代入式全体を表す -
NameExpr: 左辺の変数xを表す -
IntegerLiteralExpr: 右辺のリテラル値7を表す
では,今回の例である関数名 f のコードスニペットに対してパスコンテキストはどのようになるか見ていきましょう! 🔎
図1の赤いパスに注目すると,パスコンテキストは下記のようになります 👇
3. 埋め込み(Embedding)の計算
次に,各パスコンテキストを固定長のベクトルに変換していきます.
固定長のベクトルとは?
Gemini に聞いてみました!
固定長のベクトルとは、要素数が事前に決まっていて、変更できないベクトルのことです。例えば、3 次元空間の座標を表すベクトル (x, y, z) は、常に 3 つの要素を持ちます。これが固定長のベクトルです。一方、要素数が可変であるベクトルは可変長ベクトルと呼ばれます。例えば、文章を単語に分割したものをベクトルで表す場合、文章の長さによってベクトルの要素数(単語数)が変わります。
固定長ベクトルにする理由は、主に以下の点が挙げられます。
- 計算効率の向上: 固定長のベクトルは、メモリ上に連続して格納されることが多いため、アクセスや計算が効率的に行えます。可変長ベクトルでは、要素数が変わるたびにメモリの再割り当てなどが発生し、オーバーヘッドが生じる可能性があります。
- モデルの簡素化: 機械学習などでは、入力データの形式を固定することで、モデルの構造を簡素化し、学習を安定させられます。例えば、画像認識では、画像を固定サイズのベクトルに変換してから入力することが一般的です。
- 互換性の確保: データ交換やシステム連携を行う際、ベクトルの形式を固定することで、互換性を確保しやすくなります。
具体的な例として、以下のようなケースで固定長ベクトルが用いられます。
- 画像処理: 画像を固定サイズにリサイズし、各ピクセルの色情報を要素とするベクトルで表現する。
- 自然言語処理: 文章を単語に分割し、各単語に対応するベクトルを固定長に揃える(例えば、最大単語数 100 語までとし、足りない場合はパディングで埋める)。
- 音声認識: 音声データを固定長のフレームに分割し、各フレームの特徴量を要素とするベクトルで表現する。
固定長ベクトルは、データの表現方法を統一し、処理を効率化するために重要な役割を果たしているんですね!
埋め込み(Embedding)とはまずなんなのか... 🤔
AWS のドキュメントがわかりやすそうだったので,記載しておきます.
埋め込みとは、機械学習 (ML) や人工知能 (AI) システムが人間のように複雑な知識領域を理解するために使用する、
です。一例として、計算アルゴリズムは、2 と 3 の差は 1 であることを理解しています。これは、2 と 100 と比較して、2 と 3 の間に密接な関係があることを示しています。ただし、現実世界のデータにはより複雑な関係が含まれています。たとえば、鳥の巣とライオンの巣は似たような組み合わせですが、昼夜は逆の用語です。埋め込みは、現実世界のオブジェクトを、実世界のデータ間の固有のプロパティと関係をキャプチャする複雑な数学的表現に変換します。プロセス全体が自動化され、AI システムはトレーニング中に埋め込みを自己作成し、必要に応じてそれを使用して新しいタスクを完了します。
埋め込みを使うことによって,AI が世の中のことをもっと賢く理解することができるようになるんですね!🧠
コンテキストベクトルの生成
各要素(始点,経路,終点)に対応する埋め込みベクトルを計算して,それらを結合してコンテキストベクトルを生成します.
下記が論文に記載されているコンテキストベクトルの定義です.
各要素(始点,経路,終点)に対応する埋め込みベクトルを計算して,それらを
value_vocab と path_vocab についてさらに詳しく 🇬🇧
- value_vocab: This matrix stores embeddings for each unique terminal value (tokens) observed during training, such as variable names, literals, and keywords.
- path_vocab: This matrix stores embeddings for each unique AST path observed during training.
では,先ほど求めた下記のパスコンテキストのコンテキストベクトルを計算してみましょう! 🔎
これらを結合し,1 つのコンテキストベクトルを生成します.
4. Attention Mechanism によるパスの重み付け
コードスニペットには複数のパスコンテキストがあるので,Attention Mechanism を使って,これらを単一のコードベクトルに変換します.
Attention Mechanism は,各パスコンテキストにその重要性を反映する重みを割り当てることができます.重みが大きいほど,そのパスコンテキストが重要であるということですね!
下記が論文に記載されている Attention Mechanism の定義です.なんか難しそう... 😅
Given the combined context vectors:
, the attention weight of each is computed as the normalized inner product between the combined context vector and the global attention vector .
ソフトマックス関数とは?
こちらの記事がわかりやすかったです ❤️
超簡単に言うと,多値分類をしたいときに使われる関数です!
では,今回の例の場合,Attention Mechanism によって各パスコンテキストの重みはどのようになるのかをみていきましょう! 🔎
論文によると,パスの幅がとスコアは比例するとのことなので,今回の例だと
The widths of the paths are proportional to the attention score that each of these path-contexts was given.
その他のパスには,
コードベクトルの生成
ここまできたら,コードベクトルを生成する準備が整いました 🤩

下記が論文に記載されているコードベクトルの定義です.
The aggregated code vector
, which represents the whole code snippet, is a linear combination of the combined context vectors factored by their attention weights.
コンテキストベクトル
5. メソッド名の予測
最後に,生成されたコードベクトル
スコアの計算
下記が論文に記載されているスコアの計算方法です.
The predicted distribution of the model
is computed as the (softmax-normalized) dot product between the code vector and each of the tag embeddings:
that is, the probability that a specific tag
should be assigned to the given code snippet is the normalized dot product between the vector of and the code vector .
コードベクトル
今回の例題の場合,メソッド名の予測スコアは下記のようになります.

上記の結果からも分かるように,今回の例題のコードスニペットには,contains というメソッド名が適しているということがわかりますね!🎉
以上が code2vec の手法によるメソッド名の予測の流れです!
そもそもなぜ,こちらの手法が有用なのか?
- AST パスや Attention Mechanism などを用いることによって,プログラミングコードに今まで以上に意味を持たせることが可能になった
👉 コンピュータ 🤖 がプログラミングコードを理解しやすくなった 🌟
最後に
code2vec の手法の流れについて,イメージが深まったでしょうか?🤔
少しでも理解の手助けになれば幸いです 🌟
間違いなどありましたら,お気軽にコメントいただけると嬉しいです 🙇♂️
最後まで読んでいただき,ありがとうございました!🙏
参考文献
Discussion