【LangChain】のRAGの類似度計算の詳細を確認したら色々変だった
はじめに
LangChain で RAG を実装する時、以下のように (FAISS, Chroma などの) 何らかの VectorStore の as_retriever() メソッドで retriever を生成し、invoke() を実行して類似度検索をすると思います。
vectorstore = SomeVectorStore(embeddings)
retriever = vectorstore.as_retriever(search_type="similarity")
result = retriever.invoke("some text")
retriever に指定できる search_type は
- similarity(類似度検索)
- similarity_score_threshold(閾値以下切り捨て類似度検索)
- mmr(極端に似たものを避けて類似度検索)
の 3 つあります。
この中で、similarity_score_threshold の類似度の計算は特殊で、類似度を変換して
この記事ではそれについて説明しますが、変なところが 2 段階になっているのでちょっと読みづらいかもしれません。ご了承ください。
結論をいうと、基本的にそれほど実害はなさそうですが、similarity_score_threshold の動きは結構怪しく、特に FAISS を使う場合は similarity_score_threshold を使わないほうがいいです。FAISS は similarity でも閾値指定できるので、そちらを使ったほうがいいです。
ライブラリのバージョン
動作確認した各ライブラリのバージョンは以下のとおりです。
langchain==0.3.25 langchain_core==0.3.63 langchain_community==0.3.24
langchain-chroma==0.2.4 chromadb==1.0.12 faiss-cpu==1.11.0
ベクトルの類似度計算について
langchain の実装の説明の前に、まず以下の 3 つのベクトルの類似度計算について簡単にまとめます。
-
L^2 - コサイン類似度
- 最大内積
この節では一般の
ノルム、内積の定義
を
を
と表すこととします。
を
や、3 つの
が成り立ちます。
L^2

となります。また余弦定理から、
が成り立ちます。よって
と計算することができます。特に
となり、
cos 類似度
cos 類似度は、ベクトルの近さを 2 つのベクトルのなす角のみで測る方法で、その角度が小さいほど似ていると判断します。
ベクトル
よって
最大内積
最大内積は内積が大きいほど近いと考えます。余弦定理から
なので、
LangChain の類似度計算
まず簡単に LangChain の類似度計算の処理流れについて説明し、その後 Chroma と FAISS の動作確認をします。
処理の流れ
冒頭で述べたように、埋め込みベクトルによる類似度計算を行う時は
vectorstore = SomeVectorStore(embeddings)
retriever = vectorstore.as_retriever(search_type="similarity")
result = retriever.invoke("some text")
のように書きます。invoke() の中身では _get_relevant_documents() というメソッドを実行しており、その中で search_type によって vectorstore の類似度検索方法を変えています。
_get_relevant_documents の中身
| search_type | 呼ばれるメソッド | 説明 |
|---|---|---|
| similarity | self.vectorstore.similarity_search() | スコアを元に検索する |
| similarity_score_threshold | self.vectorstore.similarity_search_with_relevance_scores() | 関連度を元に検索する |
| mmr | self.vectorstore.max_marginal_relevance_search() | 省略 |
mmr はこの記事では考えないこととします。
ここでスコアとは、
真ん中の similarity_search_with_relevance_scores() に必要な、関連度の計算についてもう少し深掘りしましょう。
関連度の計算について
関連度への変換については VectorStore というベースクラスに、スコアの算出方法毎に関数が用意されています。用意されているものの、(長さを 1 に正規化しているかどうかなど) 個々の事情で計算方法が異なるため、オーバーライドする想定のようですが、FAISS と Chroma ではそのまま使われています。
L2距離の関連度計算の関数
cos類似度の関連度計算の関数
最大内積の関連度計算の関数
実はこれらの関数のすべて、処理がおかしいです。一つひとつ確認していきましょう。
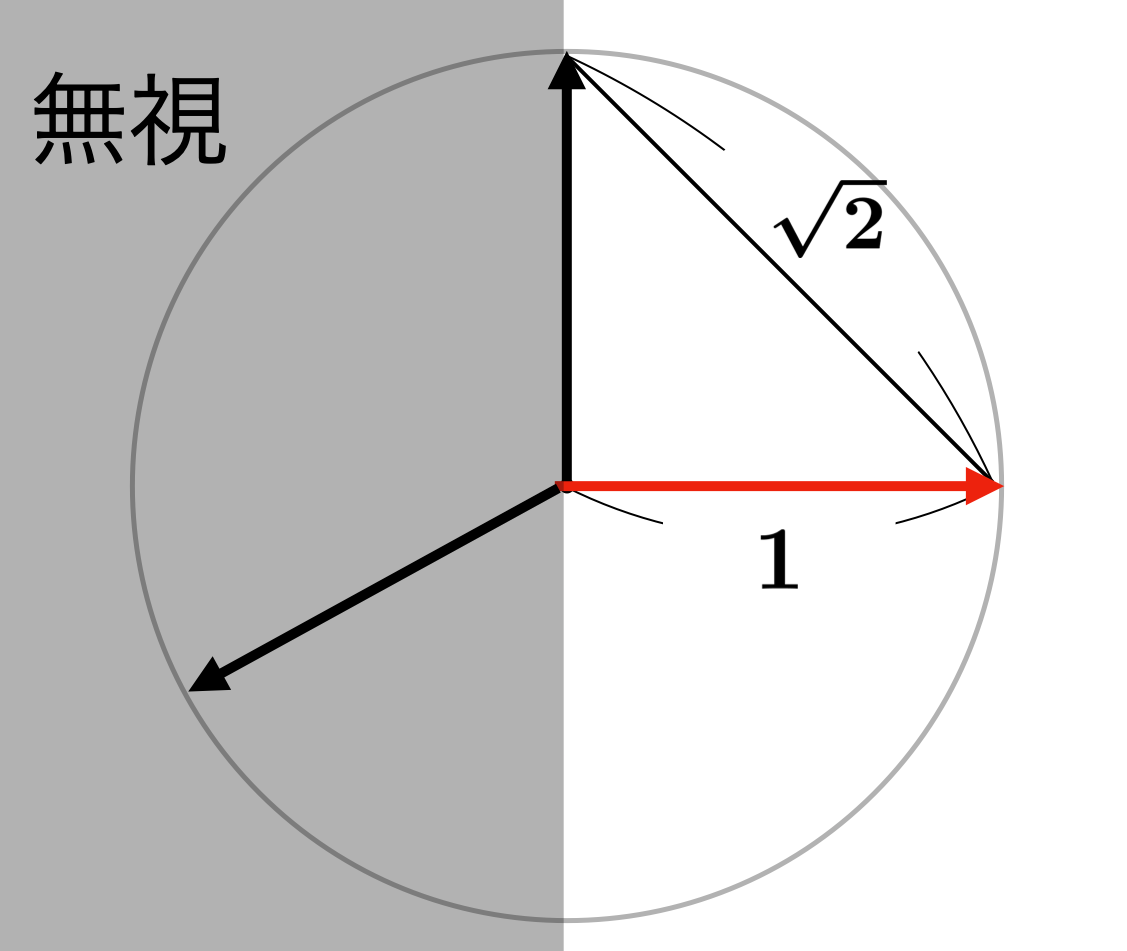
L^2
まずは
L2距離の関連度計算の関数
そして関数のコメントに
# This function converts the Euclidean norm of normalized embeddings
# (0 is most similar, sqrt(2) most dissimilar)
# to a similarity function (0 to 1)
と、"ベクトルの長さが
一応以下のように、角度が
cos 類似度の関連度計算
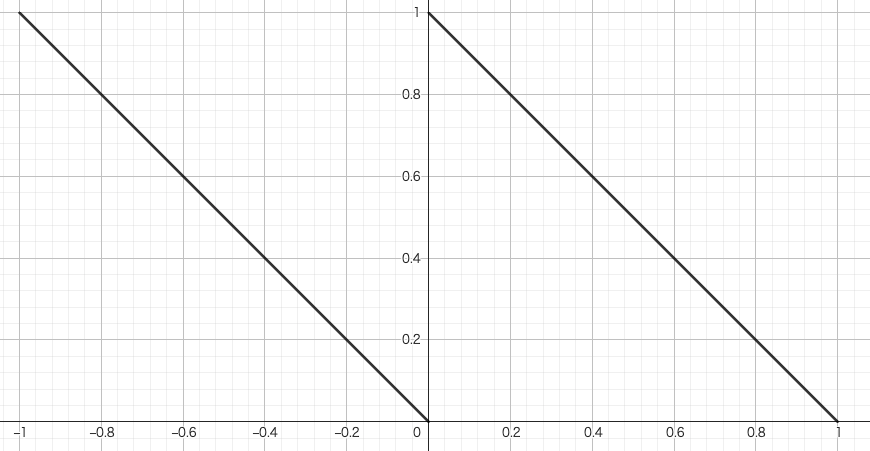
次は cos 類似度の関連度計算について見ていきましょう。
cos類似度の関連度計算の関数
式で表すと
となっています。引数の名前が distance なので、
となります。しかし
最大内積の関連度
最後に最大内積の関連度計算について見ていきましょう。
最大内積の関連度計算の関数
式で表すと
となります。ベクトルの長さが
動作確認
ここからは実際に動かして、類似度計算がどのように行われているか確認します。詳細は以下の Colaboratory に残しています。
準備
OpenAI 等のちゃんとした Embedding を使うと動作確認がしづらいので、以下のようなダミーの埋め込みを定義します。
from langchain_core.embeddings import Embeddings
class DummyEmbeddings(Embeddings):
def embed_documents(self, texts: list[str]) -> list[list[float]]:
return [self.embed_query(text) for text in texts]
def embed_query(self, text: str) -> list[float]:
if text == "こんにちは":
return [1, 0]
elif text == "おはよう":
return [-1, 0]
else:
return [0, 1]

Chroma の動作
Chroma の cos 類似度と
cos 類似度の動作確認
db = Chroma.from_texts(
["こんにちは", "おはよう", "こんばんは"],
embedding=DummyEmbeddings(),
persist_directory="cos",
collection_metadata={"hnsw:space": "cosine"}
)
search_type="similarity" の場合、
db.similarity_search_with_score("こんにちは")
# 結果
# こんにちは 0.0
# こんばんは 1.0
# おはよう 2.0
search_type="similarity_score_threshold" の場合、
db.similarity_search_with_relevance_scores("こんにちは")
# 結果
# こんにちは 1.0
# こんばんは 0.0
# おはよう -1.0
閾値を指定すると以下のようになります。
# 閾値 0
db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.0, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# こんばんは
# 閾値 0.2
db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.2, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
よって
L^2
db_l2 = Chroma.from_texts(
["こんにちは", "おはよう", "こんばんは"],
embedding=DummyEmbeddings(),
persist_directory="l2",
collection_metadata={"hnsw:space": "l2"}
)
search_type="similarity" の場合、
db_l2.similarity_search_with_score("こんにちは")
# 結果
# こんにちは 0.0
# こんばんは 2.0
# おはよう 4.0
search_type="similarity_score_threshold" の場合、
db_l2.similarity_search_with_relevance_scores("こんにちは")
# 結果
# こんにちは 1.0
# こんばんは -0.4142135623730949
# おはよう -1.8284271247461898
閾値を指定すると以下のようになります。
# 閾値指定 -0.3
db_l2.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": -0.3, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# 閾値指定 -0.5
db_l2.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": -0.5, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# こんばんは
閾値は
FAISS の動作
FAISS の cos 類似度と
cos 類似度の動作確認
faiss = FAISS.from_texts(
["こんにちは", "おはよう", "こんばんは"],
embedding=DummyEmbeddings(),
normalize_L2=True,
distance_strategy=DistanceStrategy.MAX_INNER_PRODUCT
)
search_type="similarity" の場合、スコアは
faiss.similarity_search_with_score("こんにちは")
# 結果
# こんにちは 1.0
# こんばんは 0.0
# おはよう -1.0
search_type="similarity_score_threshold" の場合、関連度は以下のようになります (めちゃくちゃです)。
faiss.similarity_search_with_relevance_scores("こんにちは")
# 結果
# こんにちは 0.0
# こんばんは -0.0
# おはよう 1.0
# 1 - cosθ if cosθ > 0 else -cosθ (謎実装)
閾値を指定すると以下のようになります。関連度の計算が変であることに加えて、切り捨てるべき方向が逆なので、なぜか一番遠いはずの "おはよう" だけが残ります。
faiss.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.1, "k": 6}
).invoke("こんにちは")
# 結果
# おはよう
FAISS は実は、search_type="similarity" でも閾値指定でき、そっちを使ったほうが良いです。
faiss.as_retriever(
search_type="similarity",
search_kwargs={"score_threshold": 0.1, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
faiss.as_retriever(
search_type="similarity",
search_kwargs={"score_threshold": -0.1, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# こんばんは
L^2
faiss_l2 = FAISS.from_texts(
["こんにちは", "おはよう", "こんばんは"],
embedding=DummyEmbeddings(),
normalize_L2=True,
distance_strategy=DistanceStrategy.EUCLIDEAN_DISTANCE
)
search_type="similarity" の場合は、
faiss_l2.similarity_search_with_score("こんにちは")
# 結果
# こんにちは 0.0
# こんばんは 2.0
# おはよう 4.0
search_type="similarity_score_threshold" の場合、
faiss_l2.similarity_search_with_relevance_scores("こんにちは")
# 結果
# こんにちは 1.0
# こんばんは -0.41421354
# おはよう -1.8284271
閾値を指定すると以下のようになります。指定した閾値より関連度が小さいものが切り捨てられます。
# 閾値 -0.1
faiss_l2.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": -0.1, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# 閾値 -0.5
faiss_l2.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": -0.5, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# こんばんは
ここまでは Chroma の
最後に一応、search_type="similarity" の場合の閾値指定について確認します。
# 閾値 0.1
faiss_l2.as_retriever(
search_type="similarity",
search_kwargs={"score_threshold": 0.1, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# 閾値 1.1
faiss_l2.as_retriever(
search_type="similarity",
search_kwargs={"score_threshold": 1.1, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# 閾値 2.1
faiss_l2.as_retriever(
search_type="similarity",
search_kwargs={"score_threshold": 2.1, "k": 6}
).invoke("こんにちは")
# 結果
# こんにちは
# こんばんは
結論
- FAISS で閾値を指定したい場合、search_type="similarity_score_threshold" ではなく search_type="similarity" を使ったほうが良い。
- スコア、関連度の算出がベクターストアによって異なる可能性があるので確認したほうが良い。
- Retriever がスコアを返してくれないせいで問題が見つかりにくい。
Discussion