マルチモーダルLLMのllavaを使った簡単アプリ作成
はじめに
どこもかしこも生成 AI、どこもかしこもマルチモーダルな感じなので、OSS で使える llava を使ってローカルで動く WEB アプリ的なものを作ってみることにしました。
WEB ブラウザから、アップロードボタンを押して画像をアップロードしたらどんなものが写っているか答えてくれるもの。
手っ取り早く Ollama っていろんなところで llama 派生モデルを動かせるアプリを使います。ローカルで API サーバーとして動きます。
Ollama についてはここでも書いてるので、ぜひみてみてください。
参考
マルチモーダルな API たち。
作ったもの
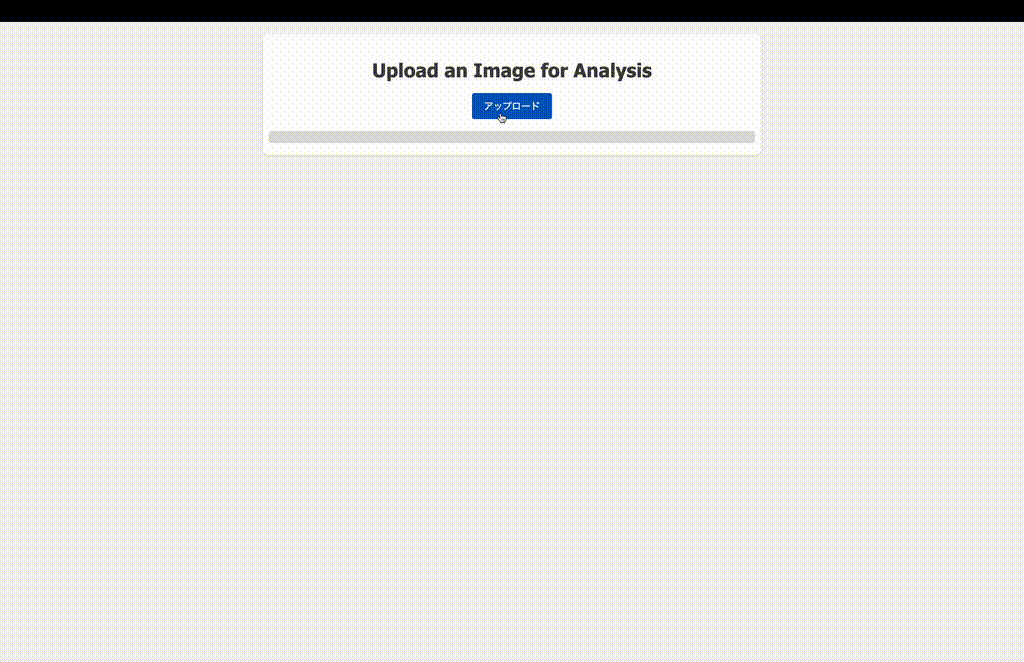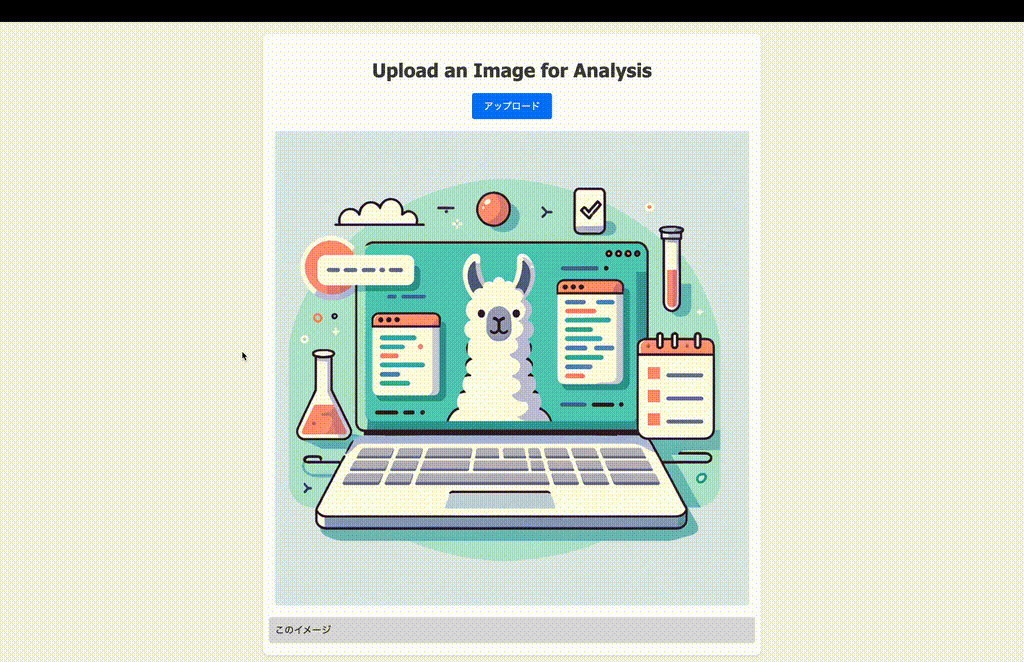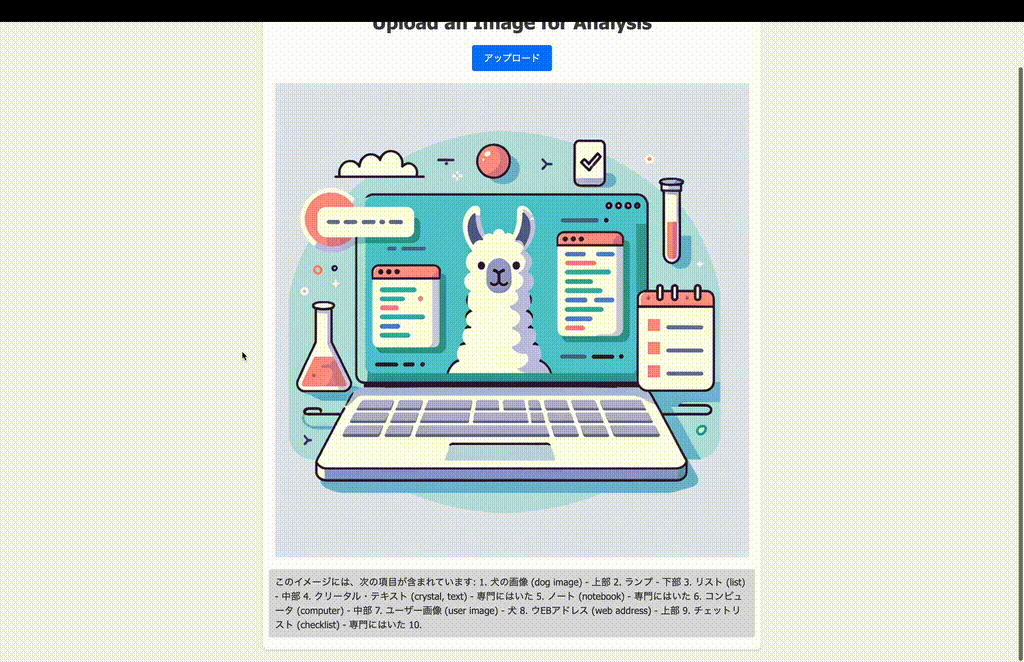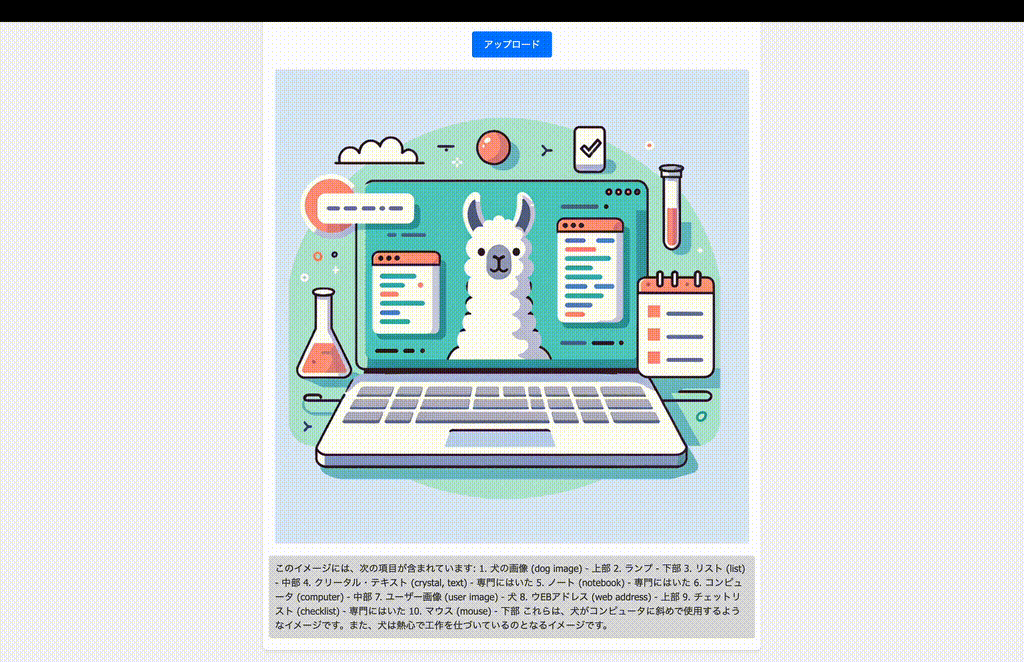
こんな感じ。
正直、そんなに賢くはないけども。
日本語が得意な OSS のマルチモーダル LLM がそのうち出てきてくれるといいなぁ。
環境
M1 Mac でやってます。
Ollama は以下からインストールします。入れたら勝手に動くと思います。
シンプルに試したいので、HTML とちょっとした css と JavaScript で動かします。ほとんど ChatGPT に作ってもらいました。
ローカルにおいて、HTML にアクセスするだけだと、Ollama の API にアクセスできなかったので、vscode で、Live Server ってのを使って動かしました。
詳細
HTML
まず、HTML はこんな感じ。インプットのボタンとイメージがあるくらい。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Image Analysis Service</title>
<link rel="stylesheet" href="style.css" />
</head>
<body>
<div class="container">
<h1>Upload an Image for Analysis</h1>
<label for="imageInput" class="custom-file-upload"> アップロード </label>
<input
type="file"
id="imageInput"
accept="image/*"
style="display: none"
/>
<img
id="uploadedImage"
src="#"
alt="Uploaded Image"
class="uploaded-image"
style="display: none"
/>
<div id="result"></div>
</div>
<script src="script.js"></script>
</body>
</html>
CSS
CSS はこんな感じ。ChatGPT がデフォルトでこのフォントを出してくるのはなんでなんやろう。よくあるフォントなんやろか。
body {
font-family: "Segoe UI", Tahoma, Geneva, Verdana, sans-serif;
background-color: #f4f4f4;
color: #333;
margin: 0;
padding: 20px;
}
.container {
max-width: 800px;
margin: auto;
background: #fff;
padding: 20px;
border-radius: 8px;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
display: flex;
flex-direction: column;
align-items: center;
}
h1 {
color: #444;
margin-bottom: 20px;
}
.custom-file-upload {
display: inline-block;
padding: 10px 20px;
cursor: pointer;
background-color: #007bff; /* ブルー */
color: white;
border: none;
border-radius: 4px;
transition: background-color 0.3s;
}
.custom-file-upload:hover {
background-color: #0056b3; /* 濃いブルー */
}
.uploaded-image {
max-width: 100%;
height: auto;
margin-top: 20px;
border-radius: 4px;
}
#result {
margin-top: 20px;
padding: 10px;
background-color: #ddd;
border-radius: 4px;
width: 100%;
}
JavaScript
メインの JavaScript はこんな感じです。ファイルがアップロードされたら、ごにょごにょしはじめます。
API に渡す json はすごくシンプル。
レスポンスのハンドリングがそこそこ複雑。done が帰ってくるまで、再帰的?に処理する。
また、一つの JSON オブジェクトが複数のチャンクに分割されて送信されるか、または複数の JSON オブジェクトが一つのチャンクに含まれる可能性があることも考えて処理しています。ちゃんと動いていればですが。。。テストできると良いんだけども。。。
どうも、ReadableStream ってのを使って、ストリームを受けてるみたいです。
下記サイトに、モダンそうな書き方もあるので、もっとスマートに書けるのかもです。
API の仕様は以下参照です。
document
.getElementById("imageInput")
.addEventListener("change", function (event) {
if (this.files && this.files[0]) {
// console.log(this.files[0]);
const reader = new FileReader();
reader.onload = function (e) {
// 画像を表示
const uploadedImageElement = document.getElementById("uploadedImage");
uploadedImageElement.src = e.target.result;
uploadedImageElement.style.display = "block";
// Base64エンコードされたデータを取得(API用)
const base64Image = e.target.result.split(",")[1];
// APIを呼び出す
callApi(base64Image);
};
reader.onload = function (e) {
const base64Image = e.target.result.split(",")[1];
// console.log(base64Image);
callApi(base64Image);
// 画像を表示する処理を追加
const uploadedImageElement = document.getElementById("uploadedImage");
uploadedImageElement.src = e.target.result; // 完全なBase64データをsrcにセット
uploadedImageElement.style.display = "block"; // 画像を表示する
};
reader.readAsDataURL(this.files[0]);
}
});
function callApi(imageData) {
const data = {
model: "llava",
prompt: "このイメージに何があるか日本語で答えて?",
images: [imageData],
};
const resultDiv = document.getElementById("result");
// const loadingDiv = document.getElementById("loading");
resultDiv.style.display = "block";
resultDiv.textContent = "Loading...";
fetch("http://localhost:11434/api/generate", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
})
.then((response) => {
const reader = response.body.getReader();
let accumulatedText = ""; // 読み取ったテキストを蓄積する変数
let accumulatedResponse = ""; // response値を蓄積する変数
function processText({ done, value }) {
if (done) {
console.log("Stream complete");
console.log(accumulatedText); // 最後に蓄積されたテキストをログに出力
return;
}
// チャンクをデコードして蓄積
accumulatedText += new TextDecoder("utf-8").decode(value);
// 蓄積されたテキストから完全なJSONオブジェクトを抽出し処理
try {
let startPos = 0;
let endPos = 0;
// 複数のJSONオブジェクトを処理するためのループ
while (
(startPos = accumulatedText.indexOf("{", endPos)) !== -1 &&
(endPos = accumulatedText.indexOf("}", startPos)) !== -1
) {
const jsonString = accumulatedText.substring(startPos, endPos + 1);
try {
const jsonObj = JSON.parse(jsonString);
if (jsonObj.response) {
// JSONオブジェクトのresponseプロパティを処理
console.log(jsonObj.response);
accumulatedResponse += jsonObj.response; // divに内容を追加
resultDiv.textContent = accumulatedResponse;
}
} catch (e) {
console.error("Error parsing JSON chunk", e);
}
// 処理済みの部分を蓄積テキストから削除
accumulatedText = accumulatedText.substring(endPos + 1);
endPos = 0; // インデックスをリセット
}
} catch (error) {
console.error("Error processing accumulated text", error);
}
// 次のチャンクを読み取り
return reader.read().then(processText);
}
reader.read().then(processText);
})
.catch((error) => {
console.error(error);
resultDiv.style.display = "none"; // エラーが発生した場合に表示を非表示にする
});
}
動かし方
vscode で、Command + Shift + Pして、Live Server: Open with Live Serverしました。

おわりに
ストリームっぽく文字を出力していたり、思ったよりも凝ったものになりました。
でも、それなりにシンプルでいい感じです。プロンプトを工夫したらあんなことやこんなこともできそう。ワクワク。。。
Ollama はコンテナでも動くらしいので、クラウド上でも動くかもです。コンテナ上で GPU を使うサービスがあるかとかいまいちよく分かってませんが。
ChatGPT に言われるがまま理解できていない部分もあるかもなので、変なところとかあればご指摘お願いします。
Discussion