この記事は、株式会社オプティマンドアドベントカレンダー2024 1日目の記事です。
blockchain概要
分散型システムの観点
そもそも今回の記事に執筆する経緯として、分散型システムの本を読んでいる中で、gossip protocolというものを知り、それでBitcoinにも使われているよ、との情報が得られて興味を持ち始めました。ブロックチェーンは元々根幹的分散型システムなので、この節では従来のWEB2で議論しているものとの違いをみながら、ブロックチェーンの特徴や考え方をまとめたいと思います。
CAP定理とPACELセオレム
分散型システムの設計において、CAP定理(Consistency, Availability, Partition Tolerance)は重要な指針となりますが、ブロックチェーンの場合、特に「Partition Tolerance(ネットワーク分断に対する耐性)」が前提条件とされます。そのため、Consistency(整合性)とAvailability(可用性)のトレードオフが課題となります。
PACELセオレムは、Performance(性能)、Availability(可用性)、Consistency(整合性)、Ease of use(使いやすさ)、Latency(遅延)の観点から分散システムを捉え直すフレームワークです。ブロックチェーン技術においては、特に性能(Performance)と遅延(Latency)の最適化が課題です。また、ネットワークパーティションの有無に関わらず、ブロックチェーンの場合は常に整合性と遅延のトレードオフが存在します。
分散型 vs 脱中央集権型
脱中心化という言葉はよく聞きますが、厳密に従来の分散型システムとは多少イメージが違います。

「分散型(Distributed)」と「脱中心型(Decentralized)」には少し違いがあります。従来の分散型システム(例:分散データベース、マイクロサービス、CDNなど)では、ノードが協調して中央集約的な制御を実現します。例えば、分散データベースの場合、データは各ノードに分散されていますが、外部から見れば1つのDBサービスとなっています。また、通常分散されているノードの間に、マスターまたは制御パネル的な存在があります。ここで意思決定や権限の中央集権が発生します。さらに、マイクロサービスを考えると、各ノードに別々のサービスを提供し、役割が違うことも一般的です。
一方、ブロックチェーンでは、従来の分散型システムのような意思決定の集中はありませんし、役割も全て平等になります。全てのノードが独立で行動することができるし、ネットワークに参加することができます。その代わりに、システム全体のステートの整合性を保つためには、合意形成アルゴリズムをベースに最終的にネットワーク上のノードに同じステートに達することができます。
このように権限と役割の面で違いますが、ブロックチェーンのネットワークもカテゴリーで言えば分散型システムなので、この記事では無理やり「脱中央集権」の布教をするつもりがありません。以降は「分散型」をメインに使います。
分散型システムのコンセンサスアルゴリズム
分散型システム内の複数のノードが整合性の取れた状態を維持するために、一つのルール(アルゴリズム)を決める必要があります。従来の分散型システムとブロックチェーンでは求められる要件や適用方法に違いがあり、それに応じて採用されるアルゴリズムも異なります。
従来の分散型システムでは、Paxos(multi-paxosなど派生も含め)、Raft、BFT(Byzantine Fault Tolerance)などのアルゴリズムが挙げられます。Kubernetesのバックエンドetcd、ではRaft, Cockroach DB, Google Spanner、CassandraなどではPaxosを採用しています。これらのアルゴリズムは総じて、CFT(crash fault Tolerance)アルゴリズムとして考えられます。
一方で、ブロックチェーンの分散型システムでは、各ノードにおいて信頼関係はないし、設計上スループットも結構ネックになるので、考慮する要素が違います。ブロックチェーンの方ではPBFT(Practical Byzantine Fault Tolerance)、PoW(Proof of Work), PoS(Proof of Stake)などのアルゴリズムが挙げられます。これらは何方かと言えば、C(rash)に関心があるというより、B(yzantine)に関心が強いため、データの整合性やデータ改竄などに非常に強いことから、BFT(Byzantine Fault Tolerance)アルゴリズムとされています。
ブロックチェーンのアーキテクチャのところで、どのように整合性を保つか、データ改竄に強いかを見ていきたいと思います。
特徴
- P2P(ピアツーピア)
中央サーバーを持たず、ノード同士が直接通信することでシステムを維持。BitTorrentやNapsterと似た仕組み。 - 分散型台帳/帳簿(Distributed Ledger) 各ノードが台帳を共有し、取引履歴を同期。データの改ざんが極めて難しくなる。
- 暗号学的セキュリティ(Cryptographically Secure) トランザクションの検証やデータ保護に暗号技術(例:ハッシュ関数や公開鍵暗号)が使われ、データの完全性が保証される。
- 追加のみ可能(Append-Only) 過去のデータを改変することはできず、新たなデータのみ追加可能。これが信頼性の基盤。
- コンセンサスによる更新(Updatable via Consensus) PoW(Proof of Work)やPoS(Proof of Stake)などのアルゴリズムにより、ネットワーク全体の合意を取って更新。
解決している問題とは
ブロックチェーンの技術でどのような問題を解決しようとするかというと、やはりその特徴からざっくり言えばこれらが挙げられるかと
- 信頼性の確保、または第三者を介さずに信頼を構築。この場合は金融取引の中間業者(銀行とか)が不要になります。
- データ改ざん防止、過去の取引を変更するにはネットワーク全体(全てのノード)を攻撃する必要があり、ほぼ不可能になります。
- 透明性の向上、誰でも公開帳簿を確認可能になります。よくあるドネーションの資金流れが不明とか、政府の資金流れが不透明などの問題が解消できるかと(まあ別問題でこれは進められない可能性がありますが)。
問題点
一方で、ブロックチェーンにはそれなりに課題を抱えています。
- スケーラビリティ(Scalability)ビットコインは1秒間に約7トランザクションのみ。従来のDBのように大量データ処理がかなり厳しい。
- 規制の不確実性(Regulation) 各国の態度も違うし、色々と政策面で規制が難しい(元々それと対抗するような一面もあるかもですが)
- プライバシー(Privacy) トランザクションが公開されるため、匿名性が不完全(結局身分証明提出しないと使えないとか仮想通貨取引所の規制がほとんどだし、今後も国際的に規制が増える予想がつくので、完全な匿名性は求められないかなと)。
- 技術の未成熟(Immature Technology)まだまだ若い技術なので言葉通りかなと。
- 相互運用性(Interoperability) これは2つの意味があって、一つは従来のweb2のネットワークとの連携、もう一つは異なるブロックチェーン間の連携が難しいことです。
- エネルギー消費 これは主に、仮想通貨を新しいブロックのマイニング報酬として位置づけられ、結局大きな電力をマイニングに使われてしまう問題です。Bitcoinのマイニングに使われる年間電力は国の年間発電量レベルになるらしいです。ただこれらの電力消費に対して十分な社会的な価値を貢献しているかは、よく疑問視されています(もちろん、ブロックチェーン=仮想通貨ではない)。
技術者の観点からでは、スケーラビリティ、相互運用性周りはやはり気にしますね。これらの課題を解決するためにはすでに色々と試行錯誤が始まっています。
blockchainシステムの仕組み
アーキテクチャ
アーキテクチャを考える時に主に分散型システムのノード間の通信(いわばネットワーク)視点と、一つ一つのノードの構成(ブロックチェインそのもののデータ構造)視点があります。
レイヤー
ブロックチェーンのネットワークはいくつかレイヤーに分けられます。
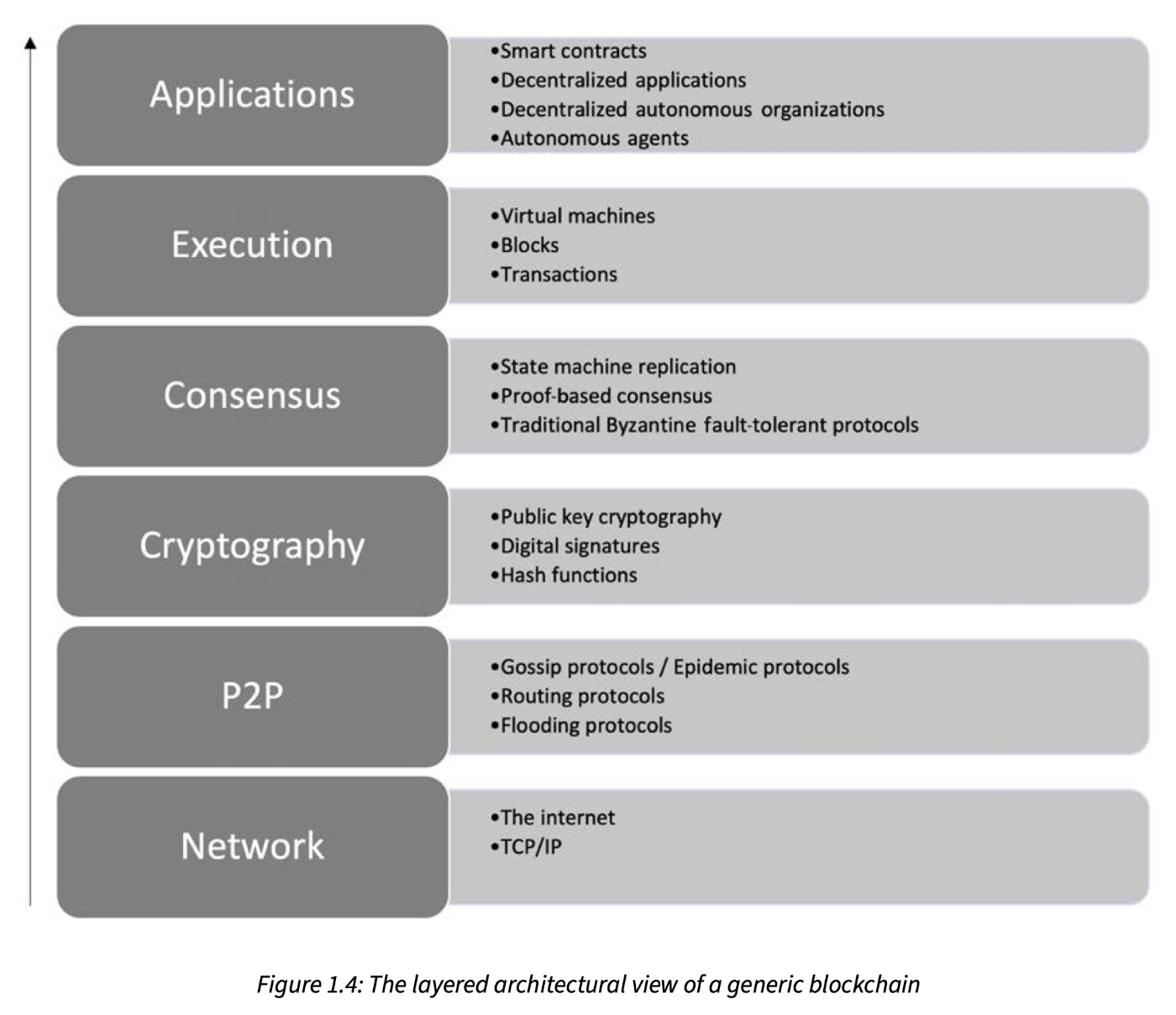
- ネットワークレイヤー ここはノードの間の通信レやーとなります。TCP/IPをベースにして通信することがよくみられます。P2Pのプロトコル
- P2Pレイヤー このレイヤーでP2P通信のプロトコルが定義されています。ネットワークレイヤーと合併してネットワークレイヤーとして考えることもできます。
- 暗号化レイヤー ブロックチェーンの中核を成すセキュリティ機能を提供し、ネットワーク全体の信頼性とトランザクションデータの暗号化、データの改ざん防止を実現する役割を果たしています。
- コンセンサスレイヤー PoWやPoSなどのアルゴリズムによる合意形成。ネットワークに分散されているノードが最終的に同じステートに到達します。
- 実行レイヤー トランザクションの実行、またはスマートコントラクトのロジックを実行する部分や、トランザクションとブロックの追加を担当するレイヤーです。EVM(Ethereum Virtual Machine), ewasm(Ethereum WebAssembly)。
- アプリケーションレイヤー ユーザーが直接触れるレイヤーで、Web3アプリ開発と言われると基本このレイヤーの話になります。DApps(分散型アプリケーション)、DEX(取引所)、Web3ウォレット。ここの動作は実行レイヤーと緊密に関連するため、二つのレイヤーを合併して考えることもできます。また、UIの開発も含まれるので、既存のWeb2の技術スタックも運用されるレイヤーとなります。
ブロック
この節からの内容について、こちらのサイトを参考にして書いていきますが、イメージがつきにくい場合はそちらのサイトの動画を一度みた方がおすすめです。

これはブロックチェーンの最小単位となりますが、データを保持する1つのピースとして考えられます。従来のDBSの観点で言えばブロック・ノードとされることがわかりやすいかもしれませんが、一つ大きな違いとして、ブロックのデータは一度書き込むと変えることが基本できません。DBのデータを更新するためには、都度の新しい「トランザクション」を初め、そのトランザクションのデータがまとまった形で新しいブロックに納まることになります。つまり、ブロックのボディ領域には、「ブロックチェーン全体のステートの変更履歴」を保持している、と考えられます。
ブロックのヘッダーにはいくつかプロパティを保持しています。
- 前のブロックのハッシュ値
- Nonceとは、ハッシュ関数の実行回数・計算量=カウンターとしてみられます(詳細はマイニングのところに参考)
- ブロック生成されたタイムスタンプ
- Merkle RootというのはMerkle treeというデータ構造のルートノードの値を持っています。この値は、データに保存されている全てのドランザクションの再帰の形で計算された値(例えば、HRoot = H(H(T1) + H(T2)))というイメージ)。つまり、今のブロック内のデータの整合性はここで確保されています。
なお、上記の図には書いていなかったが、上記の全てのデータ(つまり、前のブロックのハッシュ値も含めた状態で)をベースに、「現在のブロックのステートに対応するハッシュ値」が計算できます。この値は、次のブロックの、「前のブロックのハッシュ値」として記録されます。
チェイン
ブロックチェインには複数の以上のブロックが繋ぐことで構成されています。その肝となるのは、「Block Nのステートに対応するハッシュ値」と「Block N+1のヘッダーに記録されたBlock Nのステートに対応するハッシュ値」、という仕組みです。ハッシュ関数の実行結果は、そのインプットデータが少しでも変わると全く別物になるため、このように決めておくと、Block Nのデータを勝手に変えることができなくなります。仮にBlock Nのデータを変えると、Block N+1で記録されているBlock Nのハッシュ値が合わなくなるため、データの整合性がなくなります。さらにBlock N+1を変えれば良い、と思うと、今度はBlock N+2の整合性が失われます。このように、Block Nのデータを変えようとするときは、Nから最後のブロックを全て再計算する必要があります。
分散型
チェインのところでわかったように、一つのブロックのデータを変えるために、そのブロック以降のブロックも全て変えなければならない、という難関があります。これはどれほど難しいことなのかは、次のマイニングの節で多少わかると思いますが、一定のルールに満たすハッシュ値を計算できるまでハッシュ関数を実行しまくることが必要なので、それを多数のブロックで全部やるには膨大な時間が必要です。
これ自体はすでにかなり難しいですが、分散されているシステムではそのブロックが変更されたステートを拡散していくにはさらに不可能に近いです。同じブロックチェインは、違うノードに分散されているため、データ改竄したチェインを全てのノードに拡散していくにはもはや理論上の可能性しかなく、現実には不可能なことです。このような仕組みがあるため、ブロックチェーンのデータを不正に改ざんすることがほぼないとされています。
「ほぼ」というのは、一定の条件を満たせば、51%攻撃を行うことができます。この攻撃は、ネットワーク全体の51%以上の計算リソースを掌握する状態で、秘密に作ったデータ改ざんされたチェインをネットワーク全体に承認してもらうことができます。ネットワークの規模が小さい、もしくは計算リソースが集中すぎると起こりやすいと言われています。ただ、ここの51%というのは、分散されているノードの総数の半数以上という意味ではなく、あくまでも「計算リソース」の半数以上をさしています。この意味はマイニングとフォークのところでまた補足します。
動き方
ブロックチェーンのアーキテクチャは多少理解できたかと思いますが、ここでは静的構造ではなく動的な部分を説明します。つまり、各ノードに存在するブロックチェインにデータ更新がされるまでの流れとなります。
トランザクション
トランザクションは言葉、ブロックチェーンを従来のDBSとして見る場合、データ変更の最小単位(ブロックチェーンのステート変更の最小単位)として考えられます。もっとシンプルに例をあげると、アドレスAからアドレスBへ1通貨を送金した、その送金の記録が1つのトランザクションデータとして考えられます。
データ更新する際に、ノードの間にその更新を伝播させるためにgossip protocolを利用しています。gossipは言葉通り、「噂話」のように、各ノードが自身が知る情報を隣接するノードに伝えて、そのノードたちがさらに他のノードに広めるイメージです。これは一見グラフ探索に見えますが、BFSとはだいぶ性質が違い、基本「ノードAからノードBという明確な目的」を持たないのです。つまり、隣の誰かに伝えばよく、それが最終的にどこまで伝えていくかは気にしません。それによって、同じトランザクションの情報が複数回違うルートで同じノードに届くこと(冗長性)があります。もちろん、これで永遠に終われない問題があるので、通常TTLが来ると、伝播が止まります。
トランザクションのデータは書くノードに伝播されたら、すぐにブロックチェーンに反映するわけではなく、一旦各ノードのメモリプールで格納されます。次のマイニングプロセスが終わるまでブロックチェーンには記録されません。
マイニング
ここでまずBitCoinで提案されたPoWを例にしてマイニングとは何なのかを説明します。Proof of Workは言葉通り、仕事をした証明になりますが、その仕事というのはハッシュ関数の繰り返し実行を通してルールにクリアする値を見つけ出す、いわば「宝探し」のプロセスです。そのルールは色々とありますが、例えば「初めからは4桁が1000より小さい数字」、「最初の5桁が全部0」とか、一定の難易度があれば見つけるまで時間がかかります。
なお、構造のところでみたと思いますが、Nonceの部分は基本カウンター的な位置付けとなっており、この値が変わるたびにハッシュ値も変わるため、計算量も積み重ねていきます。計算するときはメモリプールに格納されているトランザクションデータを含めて計算し、宝探しが成功する場合、トランザクションデータを含めてブロックとしてチェインに追加されます。 仮にメモリプールでトランザクションデータがない場合どうなるだろうか。この場合は空のブロックが追加されます。新しいブロックが追加されたら、マイナーへ報酬が支払いされます。
PoW以外にも、PoS(Proof of Stake)がよく聞きます。PoWと多少違う仕組みになっており、Ethereum2.0, EOS, Pol, Tezosなどのネットワークに採用されています。各アドレスには、仮想通貨を保持すること(stake)が要求されます。その保持する量が大きければ、バリデーター(PoWのマイナーに相当)に選ばれる確率が上がります。すると、バリデーターが次のブロックを生成する権利を持ちます。ブロックが追加されると報酬がもらえます。この方法は物理的にGPUなどを使って大量なハッシュ計算をするPoWと比べてだいぶエコなので、Virtual miningとも呼ばれます。
フォーク
新しいブロックが発見されたらネットワークの他のノードに拡散されていきます。ここで、マイニングは分散されている各ノードで行われるため、一定の確率で、2つまたは以上のノードが同時に新しいブロックを発見した、とのことが発生します。このケースはいわばフォーク(一時的な分岐)と呼ばれ、1つのブロックチェーンが2つのバージョンができている状況です。通常longest chain rule、つまりチェインのブロック数が長い方が採用されます。ただ現在ではmost work chain=作業量が多い方が正しいとされていて必ずしも一番長いわけではありませんが、仮に同じ長さであった場合、計算作業量の合計が多い方が勝ちます。
そのため、データ改ざんについて分散型の節で51%攻撃について紹介しましたが、フォークとフォーク解決の仕組みによって、合計の計算作業量が勝つため、半数以上の計算リソースを掌握すると、フォーク解決の時に勝つことが可能です。
アドレス残高
最後に触れておきたいのは、自分が勉強する中で出た疑問の一つです。「アドレスAの通貨残高を知るためには、全てのブロックをチェックして、トランザクションデータを集計する必要があるのではないか?」とのことです。
この問題について、ブロック構造のところで、Merkle Treeを触れたと思いますが、アカウントや残高の情報は、各ノードでチェインとは別に保存されているらしい。Ethereumの場合は、MPT(Merkle Patricia Tree)の中には、アカウントアドレスと残高などが含まれています(参考記事 )。このデータ構造でやることをシンプルに言えば、アカウントのステートとアドレスの間にマッピングを作ることです。Ethereumのようなアカウントモデルの場合は、アカウント情報をチェインと別に保存し、ブロックチェーンではトランザクション情報だけ保持するようにしています(アーキテクチャ参考)。
Bitcoinは別のUTXO(Unspent Transaction Output)モデルが採用されています。このモデルではEthereumのような「アカウント」の概念も持たず、全てのアドレスに紐づく未使用の通貨のトランザクション情報が保持されます。そのため、仮にアドレスAの残高を知りたいときは、アドレスAに紐づくトランザクションを取り出し、その合計値が残高になります。例えば、アドレスAには現在1btcを持っているとして、その中の0.2をアドレスBに送金したとします。この場合、UTXOでは、アドレスAに紐付くトランザクションとして、0.8btcが記録されます。つまりお釣りの情報が残されるのです。逆に、アドレスBから0.1を受け取ると、アドレスAにとって0.8+0.1で合計値が計算できるようになります。
この2つのモデル比較についてこちら で詳しく説明されています。いずれにしても、ブロックチェーンというのは、言葉通りのブロックチェインのみ存在するわけではなく、さまざまなステートを別のデータ構造で保存していることです。
終わりに
この記事を作成する際に、mastering blockchain を主に参考していました。また、イメージをつけるためには、こちらの デモサイト と、JSでブロックチェーンを実装するチュートリアルが非常に助かりました。
それほど新しい技術ではないのですが、ブロックチェーンの設計を学ぶ中で、かなり巧妙で面白く思っていました。今回の記事ではその仕組みを大雑把にまとめてみました。次に機会があればEthereumやスマートコントラクトについて書こうと思います。

世界のラストワンマイルを最適化する、OPTIMINDのテックブログです。「どの車両が、どの訪問先を、どの順に、どういうルートで回ると最適か」というラストワンマイルの配車最適化サービス、Loogiaを展開しています。recruit.optimind.tech/
Discussion