この記事はOptimind Advent Calendar 2023の2日目の記事となります。
はじめに
皆さんDataform使っていますか?
一年前にもDataformの記事[1]を書きましたが、その時と比べて2023.1130現在ではDataformにも様々なアップデートがあり、日々より便利になっています。(WorkflowやReleaseのConfigとか増えていてとても良い感じ)
本記事では、そんなDataformを使用してデータをクレンジングする方法について簡単に記述しようかと思います。尚、ご留意いただきたい点として、本記事はGCP版のDataformを前提とした表現を多分に含みます。
データのレイヤー化による責務分解
近年ではデータウェアハウスの性能の向上もありELTツールがより一般的に用いられるようになってきているかと思います。この時、データを最終的に利用する形まで持っていくまでの変換過程に対し、データのオブザーバビリティ向上や認知負荷を下げることなどを目的に、レイヤー分割による構造化が行われます。このレイヤー化のアプローチは様々な手法[2][3][4][5]が提案されていますが、本記事ではこちらのブログの手法を踏襲しStaging Layerを実装します。
Staging Layerとは
Rawデータのテーブル群はBronze Layerなどと表現されますが、この時点ではデータの仕様は保証されていない状態です。具体的には、データソースが必ず自チームで管理されているのであればある程度はコントローラブルで良いのですが、往々にしてデータモデルを作成する際に使用するテーブルはチーム外の管理下にある場合が多く、スキーマのドリフトや仕様の誤認などが普通に起きえます。なので、Rawテーブルを前提とした変換を無邪気に行うと後続の処理が壊れやすくなり、壊れた際にデータの値起因なのかスキーマ起因なのか、それとも後続の変換処理(※)自体が悪いのかなど原因の切り分けが難しくなります。このような問題に対処するために、Staging Layerというものを設け簡単な名前変更やスキーマチェック、重複削除などのデータクレンジングに関する責務をこのレイヤーに集中させることで、データパイプラインに問題が起きた時のトレーサビリティを向上させることができます。
(※)この部分はDataformであればユニットテストで抑えるという方法もありますが
Dataformによる実装
Dataformではテーブルに対してassertion[6]を設定することができます。
例えば以下のような形で特定のテーブルの各カラムに対して各種制約のチェックを入れ込むことができます。
config {
type: "table",
assertions: {
uniqueKey: ["id"],
nonNull: ["name"]
}
}
SELECT id,name FROM table
このチェックに違反したデータが読み込まれると、変換がこのテーブル更新の段階で失敗します。どのようなデータで失敗したかは、デフォルトではdataform_assertionsというデータセットに違反した制約ごとのテーブルが生成されているので、その中の要素を確認することでチェック可能です。
よって、このテーブルが正常に更新されれば以後このテーブルを前提にして変換処理を組めば良いという、Staging Layerとしての責務を果たすことができます。非常に簡単です。
バリエーション
簡単には前述したように適宜assertionを組んでいけば良いわけですが、この時 Rawテーブルの状況によってあれやこれやする必要が出てくるので、以降はそのバリエーションを示したいと思います。
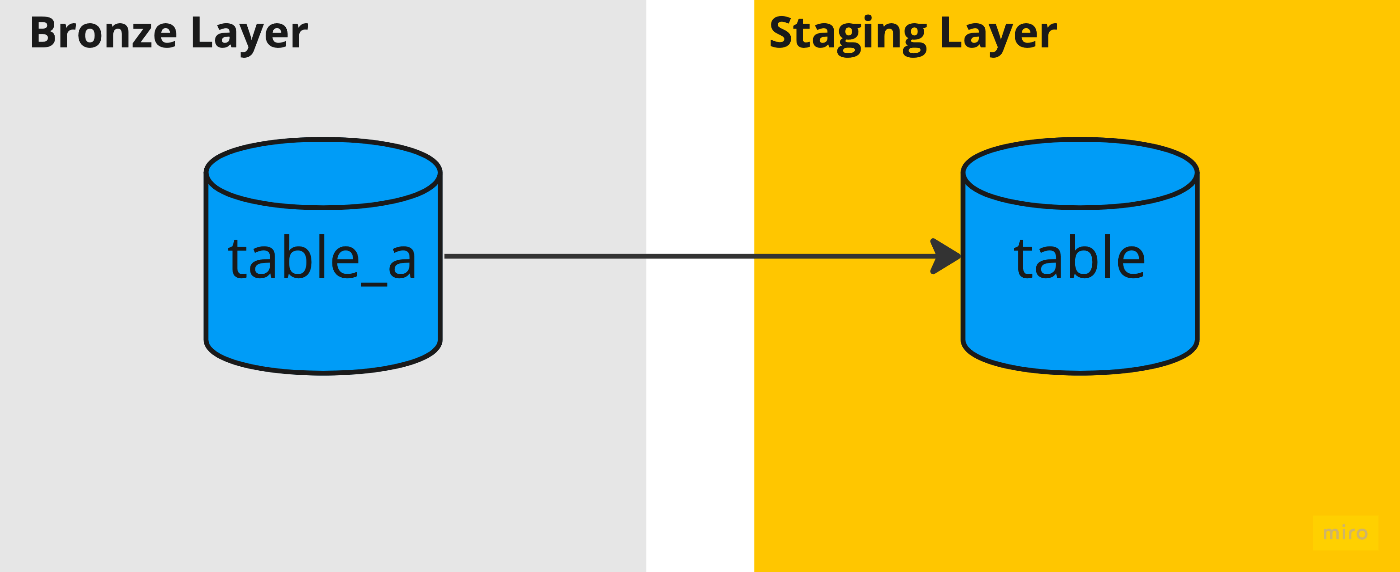
データソースが1テーブルの場合
読み込むソースデータとなるテーブルが一つである場合です。
これは一番シンプルなケースで前述したクエリと同じような書き方で済みます。
データソースが複数テーブルの場合①
ソースデータのテーブルが複数あり、それらを集約して一つのテーブルに変換する場合です。
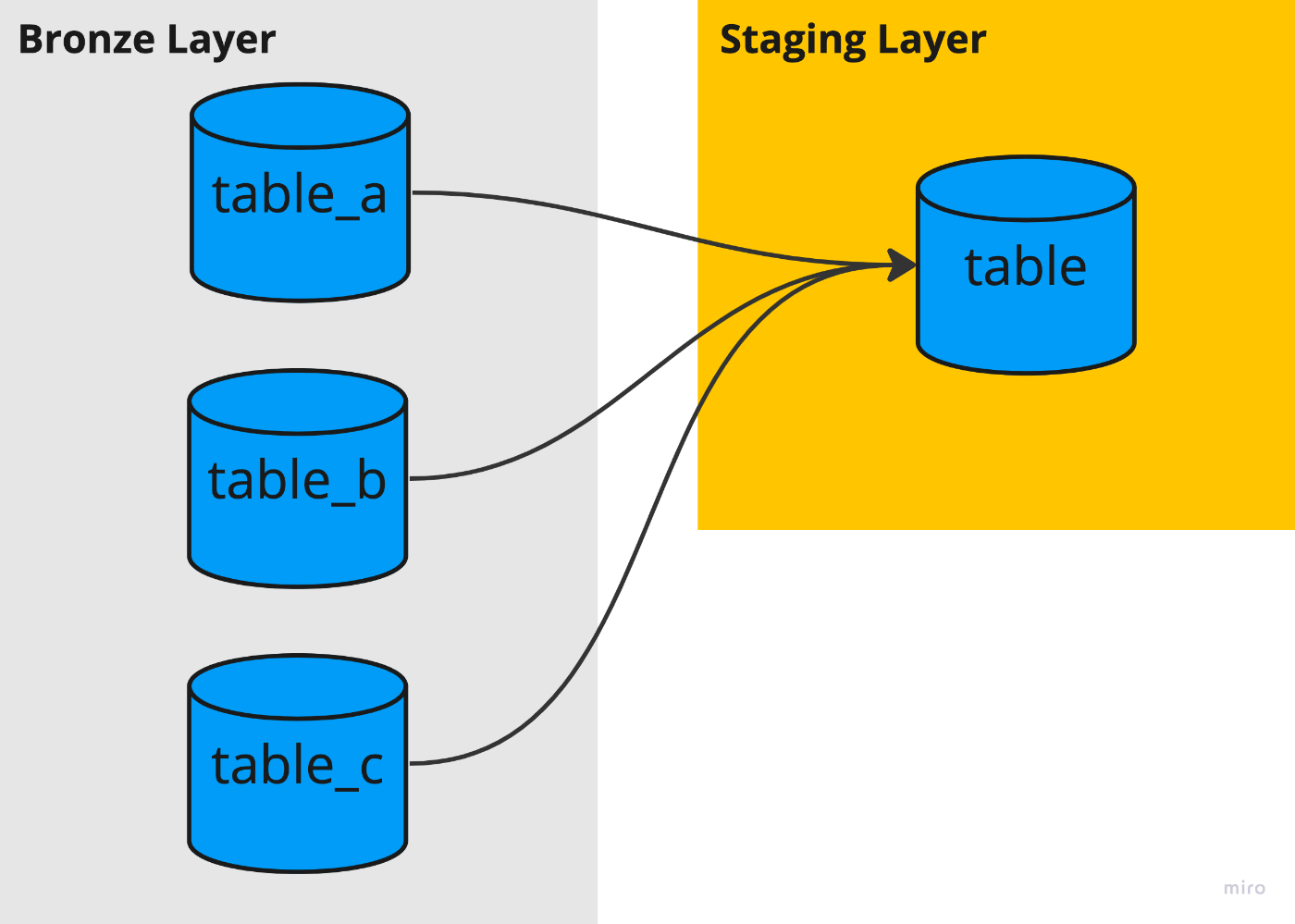
これは、対象となるソーステーブルがprefixは同じでsuffixのみ違うようなケース、例えばtable_a,table_b,table_cなどならば以下のような記述で実装可能です。
config {
type: "table",
assertions: {
uniqueKey: ["id"],
nonNull: ["name"]
}
}
SELECT id,name FROM table_*
このようにワイルドカードクエリで集約する記述方法はとてもシンプルで良いですが、いくつか対応が難しいケースが存在し、それは例えば以下のようなケースがありそうです。
- カラム名の変更など、スキーマドリフトが生じた場合
-
table_subset_aのような種別がそもそも異なる、紛らわしい名前のテーブルが同一データセット内に存在した場合(稀によくある)
データソースが複数テーブルの場合②
①で対応できないケースに対応するためには、例えばUNIONで愚直に書いていく方法が考えられます。table_bでname列がnamaeにリネームされ、table_cでname列がfirst_name列とlast_name列に分割されたと仮定して、それに対応するクエリを書くと以下のようになります。
config {
type: "table",
assertions: {
uniqueKey: ["id"],
nonNull: ["name"]
}
}
SELECT id, name FROM table_a
UNION
SELECT id, namae AS name FROM table_b
UNION
SELECT id, CONCAT(first_name, ' ', last_name) AS name FROM table_c
ただし、この方法にも課題があり、例えば期間毎に新しくソーステーブルが生成され更にそれぞれのソーステーブル間のスキーマに後方互換性が保証されないようなケースを考えると、それに対応しようとする場合、新たなテーブルが生成されたタイミングでUNION句を増やして再度デプロイすることが必要になり保守運用コストが上がります。ただ、このケースのようにスキーマがドリフトした場合などは、変化後のスキーマの各カラムに対する意味的な理解をそもそも人間がする必要があるため、自動で対応することはあまり現実的ではないように思えます。そのため、そもそもそのようなケースが起きないような運用方針を他チームと調整することが重要そうです。
感想
データパイプラインは容易に壊れます。壊れますが、どこが要因かを判別しやすくし、改修までのリードタイムを短くすることも様々なアプローチで可能であり、今後もいろいろな手法を活用してより頑健なパイプラインを作っていければと思っています。
余談ですが、最近業務で急遽解析タスクが発生し久しぶりにDataformを触りましたがサクッとデータモデリングができて非常に快適でした。BigQuery周りの機能もますます充実してきて(Notebook機能最高ですね)、非常に良いユーザ体験だなと思いました。
最後に
本記事を読んでオプティマインドの組織について興味を持っていただけた方は、弊社採用資料により詳しい内容が書かれていますのでぜひご覧ください。また、もっと詳しく知りたいと思っていただけた方はカジュアル面談も大歓迎ですので、気軽にお声がけください。
-
https://piethein.medium.com/medallion-architecture-best-practices-for-managing-bronze-silver-and-gold-486de7c90055 ↩︎
-
https://docs.aws.amazon.com/whitepapers/latest/modern-data-architecture-rationales-on-aws/modern-data-architecture-layers-deep-dive.html ↩︎
-
https://medium.com/@dipan.saha/exploring-snowflakes-data-layers-landing-bronze-staging-silver-and-gold-3c3f157a88cf ↩︎

世界のラストワンマイルを最適化する、OPTIMINDのテックブログです。「どの車両が、どの訪問先を、どの順に、どういうルートで回ると最適か」というラストワンマイルの配車最適化サービス、Loogiaを展開しています。recruit.optimind.tech/
Discussion