本記事は OpenSearch Project Blog "Explore OpenSearch 3.3" の翻訳版です。
OpenSearch 3.3をご紹介
OpenSearch 3.3がダウンロード可能になりました。検索、オブザーバビリティ、AI活用アプリケーションをサポートする多数の新機能を搭載しています。本リリースでは、オブザーバビリティツールキットの大幅な拡張や、エージェント型AIの統合をよりシンプルかつ強力にする新機能など、様々なユースケースにわたるアップグレードを提供します。
オブザーバビリティ
本リリースにより、OpenSearchは最も高機能で包括的、かつユーザーフレンドリーなオブザーバビリティソリューションを提供します。クエリ機能と可視化ツールの劇的な強化により、より堅牢で効率的なオブザーバビリティパイプラインを構築し、ログ、メトリクス、トレースデータからより多くの洞察を発見できます。
新しいDiscoverオブザーバビリティエクスペリエンスを体験
本リリースでは、完全に再設計されたOpenSearch Dashboardsインターフェースのプレビュー版を提供します。3.4のリリースでデフォルトビューになる予定の新インターフェースは、ログ分析、分散トレーシング、インテリジェントな可視化を単一のユーザーエクスペリエンスに統合します。ユーザーは、自動可視化、コンテキスト認識型のログ・トレース分析、AI駆動のクエリ構築を特徴とするアプリケーションで、オブザーバビリティデータを分析・相関付けできます。本リリースではまた、利用可能なチャートタイプも拡張され、データのより多くの可視化オプションを提供します。新しいDashboardsエクスペリエンスを有効にするには、こちらの手順を参照してください。
OpenSearch Dashboardsでのチャート選択を自動化
新しいDiscoverエクスペリエンスは、列形式のクエリ結果を提供し、最も適切な可視化を推奨してくれます。例えば、日付列を持つ1つのメトリクスは時系列分析用の折れ線グラフにデフォルト設定され、高いカーディナリティを持つ2つのカテゴリ列は自動的にヒートマップをトリガーします。各ルールは優先順位でランク付けされた代替チャートタイプを提供し、可視化の切り替えに柔軟性を持たせています。
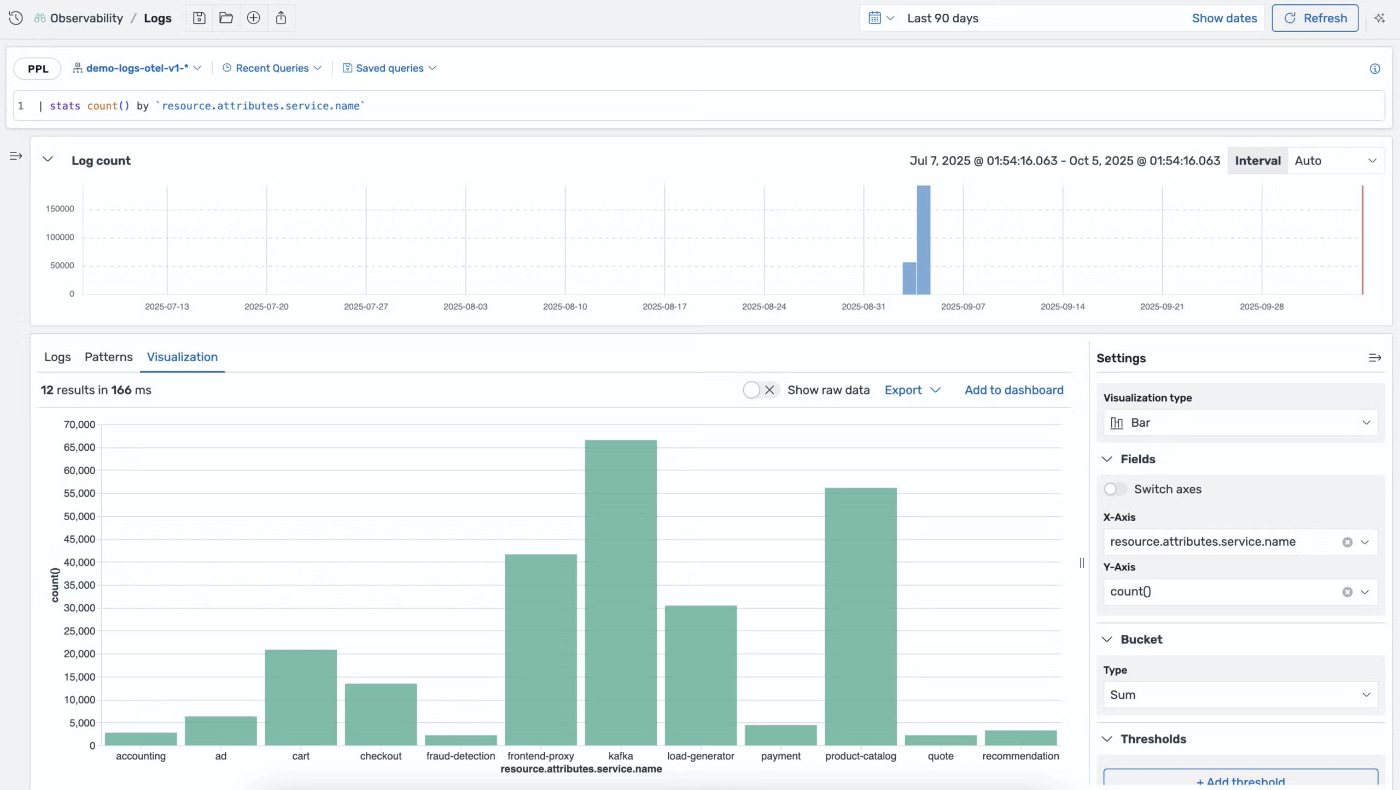
追加のカスタマイズオプションには、軸ラベルと範囲、データアラートのしきい値、タイトルとツールチップの設定、色スキームの調整、視覚スタイルの変更などが含まれます。12のプリセットルールが、シンプルなメトリクス表示から複雑な多次元散布図まで、一般的なデータパターンをカバーします。アーキテクチャでは、わずか数行のコードでカスタムルールとチャートタイプを使用できます。以下の画像は、ユーザーが定義した期間にわたって、スタック内の各サービスのログデータ量を示すオブザーバビリティの可視化の例です。
Discover Tracesでトレースデータをクエリ
Discoverインターフェース上に構築され、3.3で新登場したDiscover Tracesは、大規模分散システム全体でトレースをクエリおよび探索するための中央インターフェースを提供します。Tracesにはクリックしてフィルタリングすることができるインターフェースが含まれており、直接ユーザーが記述する必要なく複雑なPiped Processing Language(PPL)クエリを構築できます。トレースのより深い調査が必要な場合、新しいトレース詳細ページが個々のトレースジャーニーを明らかにし、その特定の操作の完全なメタデータ、属性、実行コンテキストを表示します。この機能を有効にするには、こちらのステップバイステップガイドを参照してください。
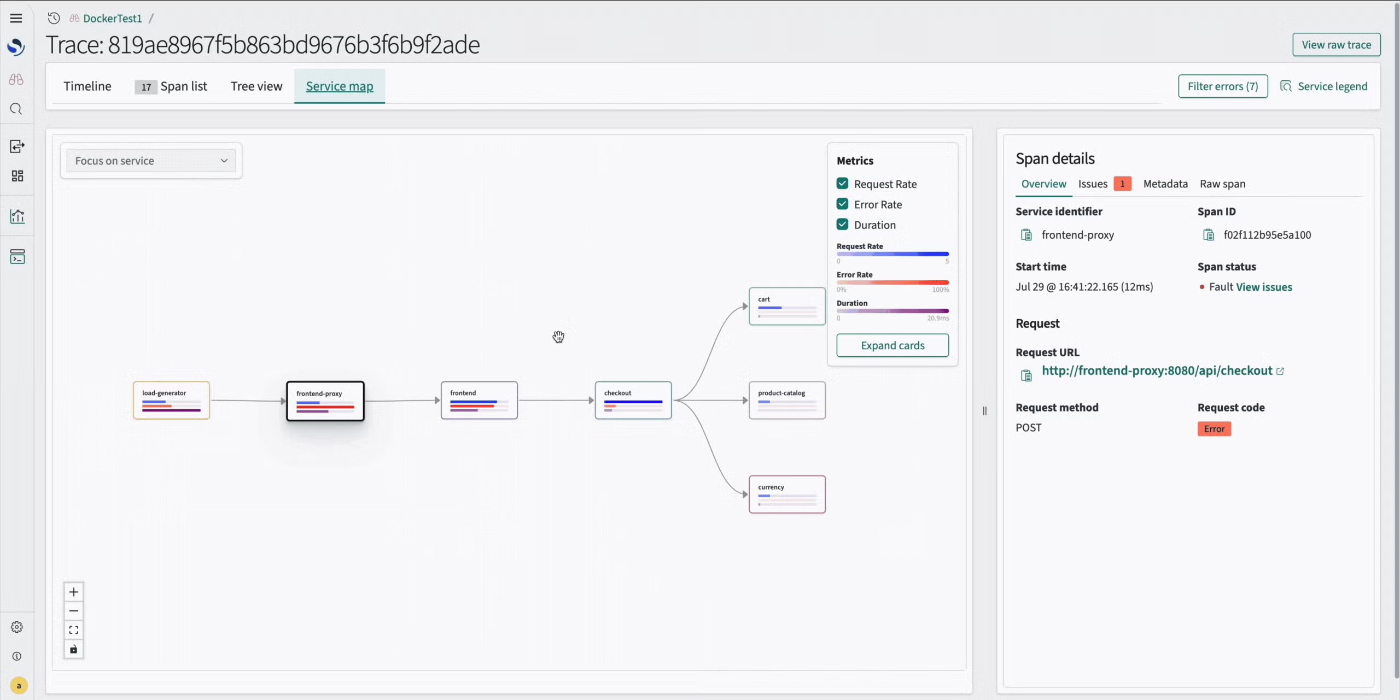
React Flowでインタラクティブなノードベース可視化を探索
本リリースでは、実験的機能としてReact FlowライブラリをOpenSearch Dashboardsコアに追加し、インタラクティブなノードベース可視化のための標準化されたフレームワークを提供します。この統合により、個々のプラグインがライブラリのコピーをバンドルした際に発生していたバージョン競合が解消され、一貫したユーザーエクスペリエンスを提供します。このライブラリは現在、Discover Traces機能と共に使用され、トレーススパンとサービス依存関係を可視化するサービスマップをレンダリングします。従来のチャートライブラリとは異なり、React Flowはワークフローとネットワークダイアグラムに特化し、ドラッグアンドドロップのインタラクション、カスタムノードコンポーネント、アクセシビリティへの準拠を維持しながら数千のノードを効率的にレンダリングします。この機能を有効にするには、こちらのステップバイステップガイドを参照してください。以下は、インタラクティブなノードベースの可視化の例です。
Apache Calcite互換性による強力な新PPL関数を使用
Apache CalciteがOpenSearch 3.3でPPLのデフォルトクエリエンジンとなり、幅広いデータ管理システムへの移植性が向上しました。Calciteの成熟したフレームワークは、新しい最適化機能、クエリ処理効率の向上、新しいPPLコマンドの広範なライブラリを提供します。
PPLクエリパフォーマンスを評価およびベンチマーク
OpenSearch 3.3では、PPLのパフォーマンス能力を検証するための包括的なベンチマークインフラストラクチャを導入しています。ClickBenchおよびBig5データセットで、さまざまな分析シナリオにわたる標準化されたパフォーマンステストをサポートします。自動化された夜間のベンチマーク実行により継続的なパフォーマンス監視が提供され、公開ダッシュボードによりPPLクエリパフォーマンスの透明性が提供されます。詳細については、ベンチマークページをご覧ください。
クエリ時に非構造化ログデータを処理
本リリースでは、データの前処理を必要とせずに非構造化テキストを直接フィルタリング、抽出、解析するための新しい複数のコマンドを備えた、PPLへのテキスト処理機能を追加しています。regexコマンドはパターンベースのフィルタリングを提供して関連するログエントリを分離し、rexは正規表現を使用して生テキストから構造化フィールドを抽出します。spathコマンドはJSONデータからフィールドを抽出し、ネストされたオブジェクトと配列へのアクセスを可能にします。これらのコマンドを組み合わせることで、非構造化データを即座に分析できます。さらに、fields、table、renameコマンドでのワイルドカードサポートにより、類似した名前のフィールドに対する一括操作が可能になります。
シンプルなコマンドで時系列データと分布を分析
OpenSearch 3.3では、新しいtimechartおよびbinコマンドを導入しています。timechartコマンドは柔軟なスパン制御で時間間隔ごとにデータを集約し、binコマンドは数値データを範囲またはバケットに自動的にグループ化します。時系列パターン分析とデータ分布モデリングがPPLクエリ内でよりアクセスしやすくなり、ユーザーはクエリ操作を通じて直接トレンドと外れ値を特定できます。
新しい関数で高度な統計分析を実行
OpenSearch 3.3は、より深いデータ分析のための新しい統計関数でPPLの分析能力を拡張します:
-
earliestおよびlatest関数は、タイムスタンプベースの値を取得し、データセット内の値の最も早い、または最も遅い出現を見つけます。 - 新しい複数値統計関数である
listおよびvaluesは、集約操作中に複数の値を構造化配列に収集します。listは重複を保持し、valuesは一意の値を返します。これらの関数は、グループ化されたデータポイント間の関係を保持し、関連する値のコレクションを維持する必要がある高度な分析ワークフローを可能にします。 -
maxおよびmin集約関数は、より広範な比較操作のために非数値データタイプをサポートするようになりました。
複雑なデータ変換のための新しい評価関数をデプロイ
OpenSearch 3.3では、データ変換目的のための新しい評価関数を導入しています:
- 拡張された
coalesce関数は、混合データタイプ全体のnull値を処理し、データクリーニング操作のための柔軟なフォールバックロジックを提供します。 -
mvjoin関数は、指定された区切り文字を使用して複数値フィールドを単一の文字列に結合し、クエリ内での配列操作を可能にします。 -
sum、avg、max、minの数学関数は、複数の値またはフィールドにわたる行レベルの計算と比較を可能にします。 -
regex_matchはパターンマッチング操作に使用され、strftimeはタイムスタンプのフォーマットに使用されます。これらの関数により、外部処理ステップを必要とせずに、PPL式内で直接複雑なデータ変換が可能になります。
単一クエリ内でデータセットを結合および再構成
本リリースでは、柔軟なデータ結合とフィールド操作のための新しいコマンドにより、PPLのデータ操作機能を強化しています。appendコマンドは複数のクエリからの結果を統一されたデータセットに結合し、単一の操作内で異なるソースや時間範囲からのデータをマージできます。一方、joinコマンドでは、認証ログとアプリケーションログを結合してセキュリティインシデントを調査するなどのアクションを実行できます。これらの機能により、単一のPPLクエリ内で包括的なデータ分析ワークフローが可能になります。
実験的なAI駆動Discoverツールで洞察を発見
本リリースでは、インテリジェントなコンテキストの認識、会話型インターフェース、エージェント統合を通じて、ユーザーがデータとやり取りする方法を変革できる実験的なAI機能をOpenSearch Dashboardsに導入しています。3つの新しいAI機能を探索できます:自動コンテキストキャプチャのためのContext Providerプラグイン、リファレンスAIエージェントを備えたOSD-Agentsパッケージ、およびDiscoverページでインテリジェントアシスタント体験を作成する拡張Chat UIです。チャットインターフェースとやり取りすると、現在のページコンテキスト(選択されたトレース、フィルタリングされたログ、時間範囲)を自動的に理解し、会話型リクエストに基づいてクエリの更新や可視化の作成などのアクションを実行できます。このシステムは、ReactベースのLangGraphエージェントを参照実装として提供し、高度な根本原因分析のためのHolmesGPTなどの専門エージェントとの統合をサポートします。HolmesGPT用にこれらのツールを有効にする方法については、このセットアップガイドを参照してください。
ベクトル検索と生成AI
OpenSearch 3.3は、より高度でパフォーマンスの高い生成AIアプリケーションをサポートするための一連のベクトル検索の機能強化を本番環境に提供します。
エージェント型検索で最適化された検索結果を取得
OpenSearch 3.3は、エージェント型検索の一般提供を開始し、自然言語入力を通じてデータとやり取りできるようにします。エージェント型検索は、インテリジェントエージェントを活用して、ユーザーの意図に基づいて適切なツールを自動的に選択し、最適化されたクエリを生成します。このエージェント型検索機能は、複数ターンの会話をサポートするためにクエリ間でコンテキストを維持し、ユーザーにカスタム検索テンプレートを使用するオプションを提供します。エージェントは、クエリコンテキストに基づいて最も適切なテンプレートをインテリジェントに選択および入力します。また、外部Model Context Protocol(MCP)サーバーへのシームレスな接続により、OpenSearchクラスター以外にも検索を拡張できます。エージェント型検索により、ユーザーは複雑なクエリドメイン固有言語(DSL)クエリを構築することなく、正確な検索結果を得ることができます。
永続的なエージェント型メモリでコンテキスト認識型インタラクションを構築
OpenSearch 3.2で実験的機能として導入され、本リリースでは本番対応のエージェント型メモリを含んでいます。これは、AIエージェントが会話やインタラクションを通じて学習、記憶、推論できるようにする永続的なメモリシステムです。この機能は、セマンティック事実抽出、ユーザー設定学習、会話要約など、複数の戦略を通じて包括的なメモリ管理を提供し、エージェントが時間をかけてコンテキストを維持し、知識を構築できるようにします。また、統合、検索、履歴追跡などの高度なメモリ操作を可能にします。エージェントに永続的で検索可能なメモリを提供することで、この機能は静的なAIインタラクションを動的でコンテキスト認識型の体験に変換し、時間とともに改善され、メモリの編成と保持ポリシーの制御を維持しながら、よりパーソナライズされたインテリジェントな応答を可能にします。
ニューラルスパース検索を最大100倍高速化
OpenSearch 3.3は、Seismicを組み込んでいます。これは、ニューラルスパース検索のパフォーマンスを革新することを約束する画期的なスパース検索アルゴリズムです。Seismicは、従来の方法より最大100倍速い優れた検索レイテンシの改善を提供しながら、90%以上のrecallを維持します。スケールとともに劇的に遅くなる可能性のあるアプローチとは異なり、Seismicは、コレクションが数百万から数十億のドキュメントに成長するにつれてスケーラビリティを向上させ、大規模デプロイメントでは従来のBM25クエリを上回ることができます。このアルゴリズムは、多段階のプルーニング技術を通じて精度と速度をインテリジェントにバランスし、5000万ドキュメントコレクションで15ミリ秒未満の検索レイテンシを提供し、より少ないリソースでより高いクエリスループットを可能にし、より大きなスパースベクトルコーパスをサポートし、スパース埋め込みでは以前は達成不可能だったリアルタイムアプリケーションを可能にします。
プロセッサーチェーンで柔軟なデータ変換パイプラインを構築
OpenSearch 3.3では、プロセッサーチェーンを導入しています。これは、人工知能と機械学習(AI/ML)ワークフロー内で柔軟なデータ変換パイプラインを可能にする強力な新機能です。プロセッサーチェーンを使用すると、複数のプロセッサーを連鎖させることでデータを順次変換でき、各プロセッサーの出力が次のプロセッサーの入力になります。この機能は、モデル応答のクリーニング、大規模言語モデル(LLM)出力からの構造化データの抽出、モデル推論のための入力の準備に特に価値があります。JSONPathフィルタリング、正規表現操作、条件ロジック、配列反復を含む10種類のプロセッサータイプのサポートにより、外部ツールなしでデータ形式の変換、特定情報の抽出、出力の標準化が可能です。プロセッサーチェーンは、予測呼び出し中のモデル入力と出力、およびエージェントツール出力に設定でき、AI/MLパイプラインへのシームレスな統合と、検索およびMLアプリケーションからのよりクリーンで実用的な結果を実現します。
Streamable HTTPトランスポートでMCPサーバーアクセスを効率化
OpenSearch 3.3は、ML Commons MCPサーバーをServer-Sent Events(SSE)からStreamable HTTPトランスポートプロトコルにアップグレードします。MCPサーバーは、エージェントの検出と呼び出しのためのOpenSearchツールを公開し、OpenSearchのロールベースアクセス制御(RBAC)を通じてユーザー権限に基づいて応答が変化することを保証する組み込みの承認処理を備えています。本リリースでは、Streamable HTTPクライアント用のMCPコネクタサポートも導入し、ML Commonsエージェントが外部MCPサーバーに接続し、簡素化された接続管理と自動承認処理でそれらのツールを利用できるようにします。
バッチ推論サポートでセマンティックハイライトのパフォーマンスを向上
OpenSearch 3.3では、リモートセマンティックハイライトモデル用のバッチ処理を導入し、ML推論呼び出しを削減することでパフォーマンスを向上させます。以前は、セマンティックハイライトは検索結果ごとに1回の推論呼び出しを行っていました。バッチ処理により、すべての結果が単一のバッチ呼び出しで送信され、オーバーヘッドが削減され、GPU利用率が向上します。ベンチマークでは、ワークロードの特性に応じて2倍から14倍のパフォーマンス向上が示されており、多くの短いドキュメントを返すクエリで最良の結果が得られます。検索クエリにbatch_inference: trueを追加することで、バッチ処理を有効にします。この機能は下位互換性があり、Amazon SageMakerまたは外部エンドポイントにデプロイされたリモートモデルをサポートします。
Late interactionスコアでベクトル検索の精度を向上
OpenSearch 3.3では、lateInteractionScore関数を導入しています。これは、単一ベクトル検索を複数ベクトルの精度で強化する再スコアリング機能です。この関数はColBERTのlate interactionメカニズムを実装し、従来の単一ベクトルで初期検索を実行し、クエリとドキュメントの埋め込み表現との間のトークンレベルマッチングを使用して結果を再スコアリングできるようにします。この関数はマルチモーダルアプリケーションを強化し、テキストクエリが画像パッチまたは視覚的特徴に対して再スコアリングできるようにしながら、セマンティックの粒度を保持します。各クエリトークンはドキュメントベクトル間で最適なマッチを見つけ、解釈可能なクロスモーダル検索とモダリティ間の細かい配置を提供します。この2段階アプローチは、単一ベクトル検索の効率と複数ベクトル再スコアリングの精度を組み合わせます。
リモートモデル推論ストリーミングでリアルタイムデータ処理を実現
OpenSearch 3.3では、モデル予測とエージェント実行の両方に対する実験的なストリーミングサポートを導入し、ユーザーがAIモデルやエージェントとやり取りする方法において大きな進歩をもたらします。このストリーミング機能は、Server-Sent Events(SSE)を通じてリアルタイムデータストリーミング機能を導入し、データが利用可能になると塊で配信します。このストリーミングアプローチは、長い応答を伴うLLMインタラクションに特に有益で、ユーザーは完全な応答を待つのではなく、すぐに部分的な結果を確認できます。
検索
本リリースでは、検索結果を改善し、パフォーマンスとスケーラビリティを向上させる多数の新機能も提供します。
Maximal Marginal Relevanceで検索結果を強化
OpenSearch 3.3では、ネイティブMaximal Marginal Relevance(MMR)サポートを導入し、関連性と多様性をブレンドした検索結果を提供します。MMRは、最も関連性の高い情報を取得することと冗長性を減らすことの間でインテリジェントにバランスをとり、品質に影響を与えることなくユーザーがより幅広い回答を確認できるようにします。これは、セマンティック検索、推奨システム、ナレッジベースに特に価値があります。繰り返しまたは過度に類似した結果が発見を制限する可能性があるためです。ネイティブ統合により、MMRはOpenSearchクエリとパイプライン内で動作し、外部ツールや設定を必要としません。関連性を維持しながら検索結果の多様性を自動的に促進することで、この機能はより豊かで意味のある検索結果と改善されたユーザーエクスペリエンスの提供を支援します。
star-treeサポートでmulti-termsの集計を高速化
OpenSearch 3.3では、star-treeを介してmulti-termsの集計を解決できるようになりました。multi-terms集計(multi-terms aggregations)は、特に大規模なデータセットに適用される場合、最も実行速度が遅い集約の1つです。現在、star-treeは大規模データセットのmulti-terms集計の高速化を支援でき、さらに新しく導入された失敗統計(failur statistics)がインデックス/ノード/シャードレベルの統計の一部として含まれるようになり、ユーザーはクエリの失敗を確認できるようになりました。
新しいツールでハイブリッドクエリのパフォーマンスを向上
OpenSearch 3.3は、QueryCollectorContextSpecの実装により、ハイブリッド検索クエリを実行する際のパフォーマンス最適化を提供します。この関数は、検索プロセスにQueryCollectorContextを直接注入し、より効率的な検索実行のためにいくつかの定型コードを削除します。ベンチマークでは、語彙検索のサブクエリを使用したハイブリッド検索で最大20%のパフォーマンス向上が示され、語彙検索とセマンティックサブクエリを使用した検索では最大5%の向上が示されています。
Apache Arrow Flightで高性能データストリーミングを探索
本リリースには、クラスター内で高性能データストリーミングの新しい道を開く、新しい実験的なストリーミング対応トランスポート層が含まれています。Apache Arrow Flight RPCプロトコル上に構築されたこのオプトイン機能は、ノード間通信のサーバー側ストリーミングを可能にし、トランスポートアクションが単一の接続で複数の応答をストリーミングできるようにします。これは、大規模な結果セット、リアルタイムデータフィード、プログレッシブクエリ結果に最適です。実装には、直感的なsendResponseBatch()およびcompleteStream()メソッドを備えた新しいStreamTransportService APIが含まれており、stream-transport-exampleプラグインで示されているように、プラグインがカスタムストリーミングトランスポートアクションを追加できるようにします。TLS暗号化との完全なセキュリティ統合も含まれています。現在、内部クラスター通信のみで利用可能です(RESTクライアントサポートはまだありません)。開発者は、arrow-flight-rpcプラグインをインストールし、opensearch.experimental.feature.transport.stream.enabledフラグを有効にすることで試すことができます。アーキテクチャ、セキュリティ設定、メトリクス監視をカバーするドキュメントをご覧ください。
新しいストリーミング機能で高カーディナリティの集計クエリの効率を向上
新しい実験的なストリーミング集約は、シャードごとに完全な状態を構築するのではなく、Luceneセグメントごとに部分的な結果をストリーミングすることで、高カーディナリティの集計の処理モデルを変更します。これにより、ワークロードがデータノードからコーディネーターに移動し、データノードのリソースが制約されている高カーディナリティシナリオでコーディネーターがスケーラブルなポイントになります。メトリクスサブ集約(max、min、doc_count、cardinality)を使用したterms集約(キーワードおよび数値フィールド)をサポートし、実装では、高コストなグローバル順序の代わりに事前計算されたセグメントレベルの順序を使用し、高コストなTopN優先キュー操作を排除し、データノードでのメモリとCPUの大幅な削減を実現します。arrow-flight-rpcプラグインをインストールし、opensearch.experimental.feature.transport.stream.enabled=trueおよびクラスター設定stream.search.enabled=trueを設定することで、この機能を有効にできます。この機能は最近、OpenSearchCon North Americaでのプレゼンテーションでも紹介されました。
コスト、パフォーマンス、スケーラビリティ
本リリースには、OpenSearchクラスターのコスト、パフォーマンス、スケーラビリティの向上に役立つ更新が含まれています。
拡張されたgRPCサポートで高性能データトランスポートを探索
OpenSearch 3.3は、OpenSearchで最も人気のあるクエリタイプ全体でgRPCトランスポートのSearch APIサポートを拡張します。タームレベルクエリには、Range、Terms set、Exists、IDs、およびWildcardとRegexp操作にアクセスできるようになりました。全文検索では、Match PhraseおよびMulti-Matchクエリタイプを利用でき、地理的検索はGeoBoundingBoxおよびGeoDistanceサポートの恩恵を受けます。Boolean、script、nestedクエリが、本リリースの拡張Search APIサポートを完成させ、gRPCトランスポート検索機能をREST APIに一歩近づけます。OpenSearch protobufs PythonライブラリはPyPIに公開されており、PythonアプリケーションのgRPCへの便利なオンボーディングを可能にし、本リリースではOpenSearch Benchmarkサポートも含まれています。
FieldDataCacheの削除フローを最適化
OpenSearch 3.3では、フィールドデータキャッシュのクリアは非同期でより効率的になりました。このアップデートによりこの操作は、キー数とフィールド数の積に比例する時間ではなく、キー数に比例する時間しか消費しなくなりました。これにより、推奨よりも多くのフィールドを使用するドメインでの遅いキャッシュクリーンアップによって引き起こされるノードのドロップ問題が防止されます。同様の変更により、特にディスクキャッシュが使用される場合、リクエストキャッシュのクリアの効率も向上します。関連して、本リリースでは、フィールドデータキャッシュサイズのデフォルト設定を変更し、キャッシュが満杯になったときに、後続のリクエストでの望ましくない混乱を招くサーキットブレーキング動作ではなく、通常のキャッシュ削除が発生するようにしています。
安定性、可用性、回復性
OpenSearch 3.3は、OpenSearchデプロイメントの安定性、可用性、回復性の維持に役立つ機能も提供します。
ワークロードグループ別にクエリを監視および分析
OpenSearch 3.3は、統合されたWorkload Management(WLM)機能によりQuery Insights Dashboardを強化し、クラスター管理者がワークロードグループ別にライブクエリを監視および分析できるようにします。この統合により、ライブクエリテーブルに新しいWLM Groupカラムが導入され、Query InsightsとWLMダッシュボード間の双方向ナビゲーションが提供されます。ユーザーは、ワークロードグループでアクティブなクエリをフィルタリングし、CPU使用率、メモリ消費、経過時間を含むワークロード固有のメトリクスを表示できるようになりました。WLMが有効になっている場合、管理者は、クエリの詳細からワークロードグループの構成への移動、およびその逆をシームレスに行うことができ、ワークロード固有のクエリ分析を合理化します。これにより、管理者はパフォーマンスの問題を迅速に特定し、リソース割り当てを最適化し、複数のインターフェース間を切り替えることなく、特定のワークロードコンテキスト内でクエリのトラブルシューティングを行うことができます。この機能は、WLMがインストールされていない環境での下位互換性を維持します。
ルールベースの自動タグ付けでワークロード管理を簡素化
ルールベースの自動タグ付けは、定義されたルールに基づいて受信リクエストに自動的にラベルを付け、管理者がワークロードを管理し、クラスターアクティビティを監視するのに役立ちます。以前は、ルールはインデックスパターンを使用してのみ適用でき、類似したインデックスを共有するが異なるユーザーまたはロールから発信されるリクエストを区別するシステムの能力が制限されていました。新しいプリンシパル属性機能は、インデックスパターンに加えて、ユーザー名やロールなどの属性を活用してルールを許可することにより、このギャップに対処します。これにより、より正確でコンテキスト認識型のタグ付けが可能になり、クラスターが重要なワークロードに優先順位を付け、ポリシーを適用し、リソースの競合を減らすことができます。ルールは、優先順位ベースのメカニズムを使用して評価され、最も具体的な一致が適用されることを保証します。この機能強化により、ワークロードのバランス、可視性、制御が改善され、OpenSearchでの将来の多次元タグ付け機能の基盤が築かれます。
はじめに
最新バージョンのOpenSearchは、ダウンロードページでご覧いただけます。また、OpenSearch Playgroundで可視化ツールを確認することもできます。詳細については、リリースノート、ドキュメントリリースノート、および更新されたドキュメントをご覧ください。別のソフトウェアプロバイダーからOpenSearchへの移行を検討している場合は、プロセスをガイドするために設計されたツールとドキュメントを提供しています。こちらからご利用いただけます。
お気軽にコミュニティフォーラムにアクセスして、このリリースに関する貴重なフィードバックを共有し、Slackインスタンスで他のOpenSearchユーザーと繋がってください。
(日本のコミュニテイもありますので、興味がある方はぜひご参加ください! )

OpenSearch Project(OSS) の Publicationです。 OpenSearch Tokyo User Group : meetup.com/opensearch-project-tokyo/
Discussion