【やってみた】PyTorchでMNIST(精度評価編)
前回投稿からすっかり日が空いてしまいました・・・
できれば毎週投稿したいのですが、遊びの誘惑とはすごいもの
気づいたらコントローラーを握ってる日々です
気を取り直して、モデルの精度評価を行っていきましょう!
前回の振り返り
前回はMNISTからデータを読み出して、とりあえずモデルを構築しました。
ただval_lossが最小の際に重みを保存しておらず、過学習気味になったモデルをそのまま評価してました
今回は
-
val_lossが最小になった場合に、モデルを保存する - 学習の経過をグラフで描画する
- 混合行列を出す
- 間違えた画像をピックアップして可視化
の4つに取り組んでみます!
val_lossが最小になった場合に、モデルを保存する
前回なんで実装してなかったんでしょう、びっくりですね・・・
基本的にはval_lossが最低になった部分が精度が高いとされているので、そこでモデルが保存されるようにコードを修正します。
best_loss = None
for e in range(EPOCH):
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
if (best_loss is None) or (best_loss > val_total_loss):
best_loss = val_total_loss
model_path = 'model.pth'
torch.save(model.state_dict(), model_path)
print()
これでモデルが保存されるようになりました、ほっとしますね・・・
では前回正しくできなかった精度評価をしてみましょう!
モデルを評価する
とりあえず保存したモデルから評価を行ってみます
test_total_acc = 0
model.eval()
model_path = 'model.pth'
model.load_state_dict(torch.load(model_path))
with torch.no_grad():
for n,(data,label) in enumerate(test_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
test_total_acc += cal_acc(label,output)
print(f"test acc:{test_total_acc/len(test_data)*100}")
結果
test acc:98.65999603271484
おおー、割といい線行ってますね。逆に何を間違えたんでしょうか?
まずは学習のグラフを確認してみましょう
グラフ描画
学習の経過を出すには以下のコードを実行します
こちらのサイトを参考に
fig, ax = plt.subplots()
t = np.linspace(1,10,10)
ax.set_xlabel('Epoch')
ax.set_ylabel('loss')
ax.grid()
ax.plot(t,train_loss,color = 'red',label='train')
ax.plot(t,val_loss,color = 'green',label='val')
ax.legend(loc = 0)
fig.tight_layout()
plt.show()
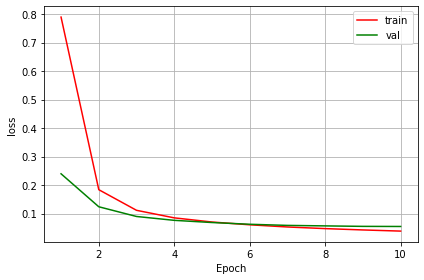
5~6 Epoch付近から過学習気味になってますね。続いて正解率も見てみましょう。
import numpy as np
fig, ax = plt.subplots()
t = np.linspace(1,10,10)
ax.set_xlabel('Epoch')
ax.set_ylabel('Acc')
ax.grid()
ax.plot(t,train_acc,color = 'red',label='train')
ax.plot(t,val_acc,color = 'green',label='val')
ax.legend(loc = 0)
fig.tight_layout()
plt.show()

大きな乖離はありませんね。MNISTはやっぱり簡単だからかなぁ・・・
次は混合行列を出して確認してみましょう!
混合行列を出す
混合行列を出すにはsklearnのモジュールを利用します。
実装は
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_pred))
こんな感じでするのですが、現状はoutputを保存してないので、listで保存できるようにコードを変更します
test_total_acc = 0
model.eval()
model_path = 'model.pth'
model.load_state_dict(torch.load(model_path))
pred_list = []
true_list = []
with torch.no_grad():
for n,(data,label) in enumerate(test_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
test_total_acc += cal_acc(label,output)
pred = torch.argmax(output , dim =1)
pred_list += pred.detach().cpu().numpy().tolist()
true_list += label.detach().cpu().numpy().tolist()
print(f"test acc:{test_total_acc/len(test_data)*100}")
いざ!尋常に勝負!
[[ 976 0 1 0 0 0 1 0 1 1]
[ 0 1126 2 0 1 0 1 1 4 0]
[ 1 2 1006 11 1 1 0 4 6 0]
[ 0 0 0 1004 0 2 0 1 2 1]
[ 0 0 0 0 975 0 0 0 0 7]
[ 2 0 0 12 1 873 1 0 2 1]
[ 4 1 0 1 5 4 940 0 3 0]
[ 0 2 2 5 0 0 0 1011 1 7]
[ 2 0 2 6 2 1 0 2 956 3]
[ 2 2 0 3 1 1 0 1 0 999]]
・・・・、どれがどの数字なんだ!!!
ちょっとわかりにくいので、ラベルを付けられるようにしましょう
こちらのサイトを参考にラベルを付けてみました
import pandas as pd
def add_label(matrix,columns):
columns_num = len(columns)
act = ['正解データ'] * columns_num
pred = ['予測データ'] * columns_num
cm = pd.DataFrame(matrix,columns = [pred,columns],index = [act,columns])
return cm
cm = add_label(confusion_matrix(true_list, pred_list),[x for x in range(10)])
display(cm)
結果はこちら

さっきのデータより見やすくなりましたね!
結果を見ているとちらほらと誤認識が・・・
どうやら0は穴があるタイプの数字と誤認識してますね(2は癖があるタイプだったんでしょうか?)
1は2、8とよく間違えてますね。7ならわかるんですがなぜ2と8・・・
間違えた数字を可視化してみる
評価コードにちょっと手を加えます
test_total_acc = 0
model.eval()
model_path = 'model.pth'
model.load_state_dict(torch.load(model_path))
pred_list = []
true_list = []
data_list = []
with torch.no_grad():
for n,(data,label) in enumerate(test_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
test_total_acc += cal_acc(label,output)
pred = torch.argmax(output , dim =1)
pred_list += pred.detach().cpu().numpy().tolist()
true_list += label.detach().cpu().numpy().tolist()
data_list.append(data.cpu())
print(f"test acc:{test_total_acc/len(test_data)*100}")
そのあとに以下を実行
fig = plt.figure(figsize = (20,5))
data_block = torch.cat(data_list,dim = 0)
idx_list = [n for n,(x,y) in enumerate(zip(true_list,pred_list)) if x!=y ]
len(idx_list)
for i,idx in enumerate(idx_list[:20]):
ax = fig.add_subplot(2,10,1+i)
ax.axis("off")
ax.set_title(f'true:{true_list[idx]} pred:{pred_list[idx]}')
ax.imshow(data_block[idx,0])

・・・、左下なんて人間でもわかりませんね。全体的に間違えている数字画像は人間でもよくわからないものが多いので仕方がない気もします。
窓口業務でしたら、もう一度書いてもらうレベルですね
可視化をしたところで今回は終わりたいと思います。
初手精度98%ですが、果たしてここからどれだけ上げることができるでしょうか・・・?
Discussion