【やってみた】PyTorchでYOLOv3をゼロから作る!
はじめに
お久しぶりです。前回はlabelmeとYOLOXで物体検出してましたね。
今回も引き続き物体検出です。前回の終わりでCenterNetの実装記事書きたいなーっと言っていたのですが、先にYOLOv3の実装をしたので記事にしました!
なぜ今さら・・・?と思っている方も多いと思います。実際YOLOv5やらYOLOXにYOLOR、さらにはYOLOv7なんてのもありますよね。
YOLOを使うだけならいいんですが、その中身を理解しているか? と聞かれると、うーん・・・。となるのが現状です。
そこで、今回はYOLOv3を実装しながら、中身がどうやって構成されているかを学んでいきたいと思います!(論文とweb記事の内容、画像をもとに作っているため、若干違うかもしれませんが、そこはご愛敬ということで・・・)
環境
今回はGoogle Colaboratory上に実装していきました。前回記事でも書いたかもしれませんが、最近PROにしてP100が割り当てられるようになり、とっても快適です。
1000円課金するだけで使えるなんて、なんて便利なんでしょう・・・。
まずはアーキテクチャから
論文は から読めますね。アーキテクチャまったくわからん・・・。
の記事中にわかりやすい図がありました。
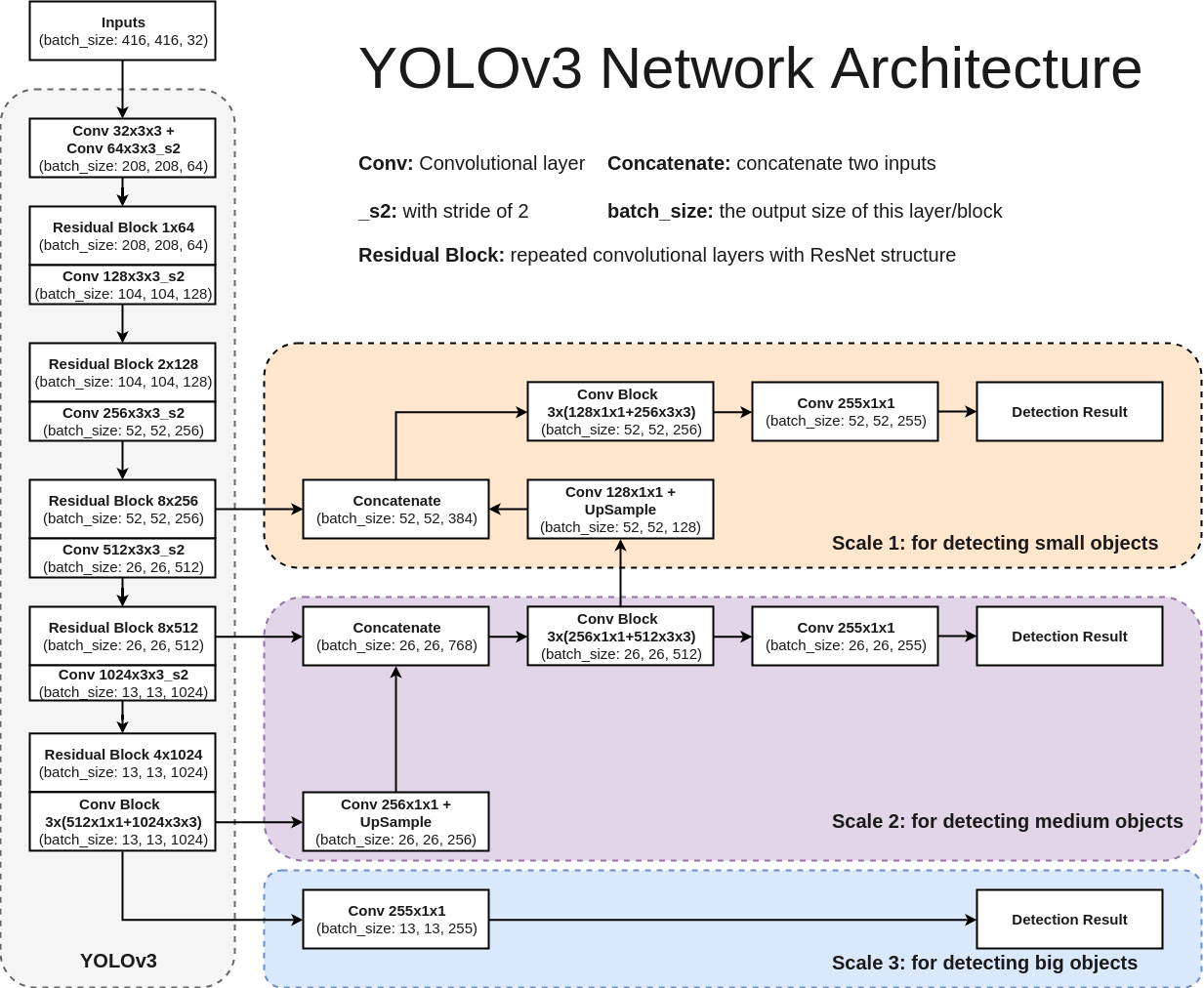
なるほど、こんな感じになってるんですね。YOLOv3が人気だったころ、利用方法とアルゴリズムは理解していたのですが、中身がこんな感じになっていることまでは完全に理解してませんでしたので、いい勉強になります。
出力部分は次の図のようになってます。
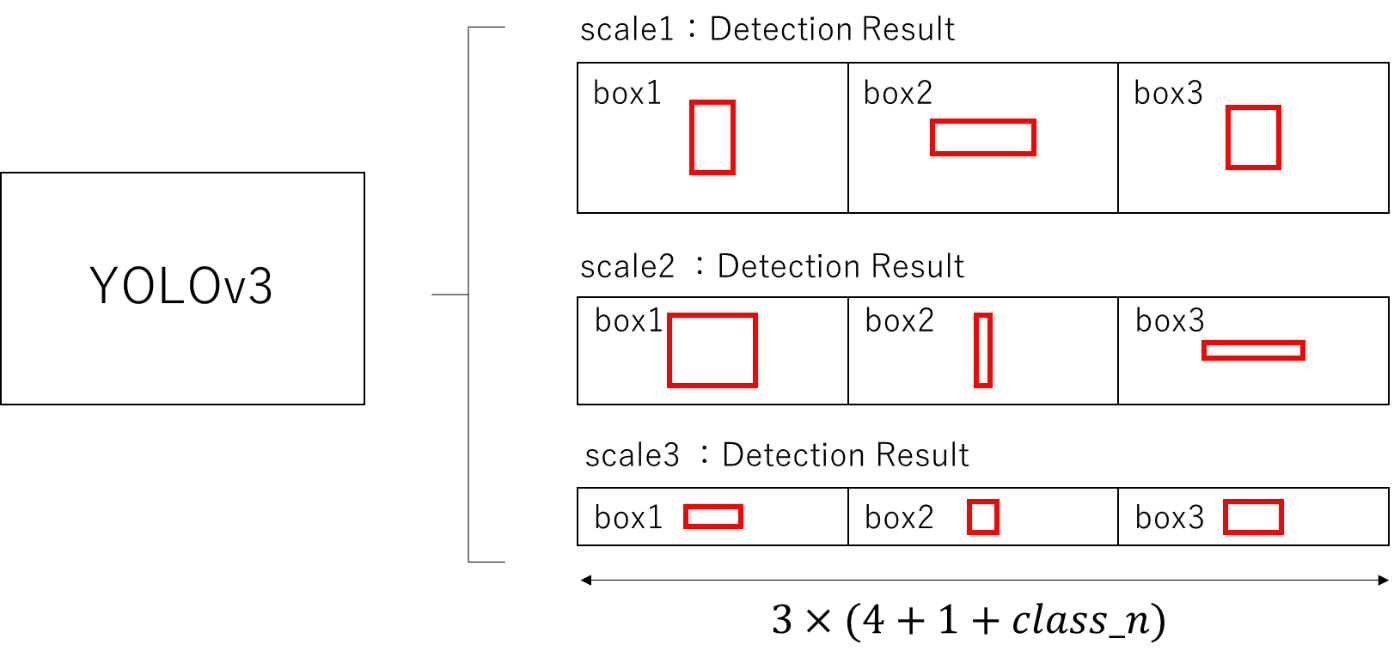
YOLOv3の出力はサイズが違うものが3種類あります。
特徴マップのサイズが大きいものは小さなオブジェクトを検出する際に、特徴マップが小さなものは大きなオブジェクトを検出する際に利用します。
この理由は次の図の通りです。

例として画面いっぱいにリンゴが映ったものを利用します。このリンゴは大きな物体と考えることができますね。
この画像に対して畳み込み演算を繰り返し、各出力まで特徴抽出を行ったと仮定します。
特徴マップが大きい場合、畳み込みのフィルタに対してリンゴが大き過ぎるため、リンゴの全体像を把握できず、物体をうまく検出することができません。
一方特徴マップが小さい場合は、畳み込みのフィルタに対してリンゴが比較的小さくなっているため、リンゴの全体像を把握することができ、リンゴを検出することができます。
逆に小さなオブジェクトの場合は畳み込みを複数回行うことで消えてしまう可能性があるので、大きな特徴マップで検出することが求められます。
また、YOLOv3は形の違うAnchorBoxを9つ持っています。物体検出の際は、その物体と最も近いサイズのAnchorBoxを微調整することで出力されます。
最後に、各boxの大きさは
である必要があります。最初の4は物体の位置とサイズの予測(中心のx座標、中心のy座標、幅、高さ)、次の1はそこに物体があるかの信頼度、最後
これらを踏まえてモデルを作っていきます!
とりあえず作ってみる
何はともあれ、まずはひな形まで作っていきます。
from torch.nn.modules.batchnorm import BatchNorm2d
import torch
import torch.nn as nn
import torch.nn.functional as F
class YOLOv3(nn.Module):
def __init__(self,class_n = 80):
super(YOLOv3 , self).__init__()
def forward(self,x):
モデルの引数にclass数を利用しています。クラス数が変化するとモデルの出力が変化するので、スムーズに変更しやすいように追加しています。
続いて利用するResidualBlock構築用関数を作っておきます。
from torch.nn.modules.batchnorm import BatchNorm2d
import torch
import torch.nn as nn
import torch.nn.functional as F
class YOLOv3(nn.Module):
def __init__(self,class_n = 80):
super(YOLOv3 , self).__init__()
def MakeResidualBlock(self,fn):
block = nn.Sequential(nn.Conv2d(fn , int(fn/2) , 1 , 1),
nn.BatchNorm2d(int(fn/2)),
nn.LeakyReLU(),
nn.Conv2d(int(fn/2) , fn , 3 , 1 , 1),
nn.BatchNorm2d(fn),
nn.LeakyReLU(),
)
return block
def forward(self,x):
YOLOv3で利用されているResidualBlockはボトルネックを利用しています。
最後に利用するモジュールを図を見ながら書き込んでいきます!
from torch.nn.modules.batchnorm import BatchNorm2d
import torch
import torch.nn as nn
import torch.nn.functional as F
class YOLOv3(nn.Module):
def __init__(self,class_n = 80):
super(YOLOv3 , self).__init__()
self.class_n = class_n
self.first_block = nn.Sequential(
nn.Conv2d(3 , 32 , 3 , 1 , 1),
nn.BatchNorm2d(32),
nn.LeakyReLU(),
nn.Conv2d(32 , 64 , 3 , 2 , 1),
nn.BatchNorm2d(64),
nn.LeakyReLU(),
)
self.residual_block_1 = self.MakeResidualBlock(64)
self.conv_1 = nn.Conv2d(64 , 128 , 3 , 2 , 1)
self.residual_block_2 = nn.Sequential(self.MakeResidualBlock(128),self.MakeResidualBlock(128))
self.conv_2 = nn.Conv2d(128 , 256 , 3 , 2 , 1)
self.residual_block_3 = nn.Sequential(self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256))
self.conv_3 = nn.Conv2d(256 , 512 , 3 , 2 , 1)
self.residual_block_4 = nn.Sequential(self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512))
self.conv_4 = nn.Conv2d(512 , 1024 , 3 , 2 , 1)
self.residual_block_5 = nn.Sequential(self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),)
self.conv_block = nn.Sequential(self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),)
self.scale3_output = nn.Conv2d(1024 , (3 * (4 + 1 +self.class_n)) , 1 , 1 )
self.scale2_upsample = nn.Conv2d(1024 , 256 , 1 , 1 )
self.scale2_convblock = nn.Sequential(nn.Sequential(nn.Conv2d(768 , 256 , 1 , 1),
nn.BatchNorm2d(256),
nn.LeakyReLU(),
nn.Conv2d(256 , 512 , 3 , 1 , 1),
nn.BatchNorm2d(512),
nn.LeakyReLU(),
),self.MakeResidualBlock(512),self.MakeResidualBlock(512),)
self.scale2_output = nn.Conv2d(512 , (3 * (4 + 1 +self.class_n)) , 1 , 1 )
self.scale1_upsample = nn.Conv2d(512 , 128 , 1 , 1 )
self.scale1_convblock = nn.Sequential(nn.Sequential(nn.Conv2d(384 , 128 , 1 , 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(),
nn.Conv2d(128 , 256 , 3 , 1 , 1),
nn.BatchNorm2d(256),
nn.LeakyReLU(),
),self.MakeResidualBlock(256),self.MakeResidualBlock(256),)
self.scale1_output = nn.Conv2d(256 , (3 * (4 + 1 +self.class_n)) , 1 , 1 )
self.upsample = nn.Upsample(scale_factor = 2)
def MakeResidualBlock(self,fn):
block = nn.Sequential(nn.Conv2d(fn , int(fn/2) , 1 , 1),
nn.BatchNorm2d(int(fn/2)),
nn.LeakyReLU(),
nn.Conv2d(int(fn/2) , fn , 3 , 1 , 1),
nn.BatchNorm2d(fn),
nn.LeakyReLU(),
)
return block
def forward(self,x):
ゴリゴリ作ってしまいました。
なんかもっとおしゃれな方法がある気がするなぁ・・・。
とりあえず最後まで作っちゃいましょう。
続いてはデータの流れを定義する部分を構築します。
from torch.nn.modules.batchnorm import BatchNorm2d
import torch
import torch.nn as nn
import torch.nn.functional as F
class YOLOv3(nn.Module):
def __init__(self,class_n = 80):
super(YOLOv3 , self).__init__()
self.class_n = class_n
self.first_block = nn.Sequential(
nn.Conv2d(3 , 32 , 3 , 1 , 1),
nn.BatchNorm2d(32),
nn.LeakyReLU(),
nn.Conv2d(32 , 64 , 3 , 2 , 1),
nn.BatchNorm2d(64),
nn.LeakyReLU(),
)
self.residual_block_1 = self.MakeResidualBlock(64)
self.conv_1 = nn.Conv2d(64 , 128 , 3 , 2 , 1)
self.residual_block_2 = nn.Sequential(self.MakeResidualBlock(128),self.MakeResidualBlock(128))
self.conv_2 = nn.Conv2d(128 , 256 , 3 , 2 , 1)
self.residual_block_3 = nn.Sequential(self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256),self.MakeResidualBlock(256))
self.conv_3 = nn.Conv2d(256 , 512 , 3 , 2 , 1)
self.residual_block_4 = nn.Sequential(self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512),self.MakeResidualBlock(512))
self.conv_4 = nn.Conv2d(512 , 1024 , 3 , 2 , 1)
self.residual_block_5 = nn.Sequential(self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),)
self.conv_block = nn.Sequential(self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),self.MakeResidualBlock(1024),)
self.scale3_output = nn.Conv2d(1024 , (3 * (4 + 1 +self.class_n)) , 1 , 1 )
self.scale2_upsample = nn.Conv2d(1024 , 256 , 1 , 1 )
self.scale2_convblock = nn.Sequential(nn.Sequential(nn.Conv2d(768 , 256 , 1 , 1),
nn.BatchNorm2d(256),
nn.LeakyReLU(),
nn.Conv2d(256 , 512 , 3 , 1 , 1),
nn.BatchNorm2d(512),
nn.LeakyReLU(),
),self.MakeResidualBlock(512),self.MakeResidualBlock(512),)
self.scale2_output = nn.Conv2d(512 , (3 * (4 + 1 +self.class_n)) , 1 , 1 )
self.scale1_upsample = nn.Conv2d(512 , 128 , 1 , 1 )
self.scale1_convblock = nn.Sequential(nn.Sequential(nn.Conv2d(384 , 128 , 1 , 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(),
nn.Conv2d(128 , 256 , 3 , 1 , 1),
nn.BatchNorm2d(256),
nn.LeakyReLU(),
),self.MakeResidualBlock(256),self.MakeResidualBlock(256),)
self.scale1_output = nn.Conv2d(256 , (3 * (4 + 1 +self.class_n)) , 1 , 1 )
self.upsample = nn.Upsample(scale_factor = 2)
def MakeResidualBlock(self,fn):
block = nn.Sequential(nn.Conv2d(fn , int(fn/2) , 1 , 1),
nn.BatchNorm2d(int(fn/2)),
nn.LeakyReLU(),
nn.Conv2d(int(fn/2) , fn , 3 , 1 , 1),
nn.BatchNorm2d(fn),
nn.LeakyReLU(),
)
return block
def forward(self,x):
x = self.first_block(x)
x_res = self.residual_block_1(x)
x = x + x_res
x = self.conv_1(x)
for layer in self.residual_block_2:
x_res = layer(x)
x = x + x_res
x = self.conv_2(x)
for layer in self.residual_block_3:
x_res = layer(x)
x = x + x_res
x1 = x
x = self.conv_3(x)
for layer in self.residual_block_4:
x_res = layer(x)
x = x + x_res
x2 = x
x = self.conv_4(x)
for layer in self.residual_block_5:
x_res = layer(x)
x = x + x_res
for layer in self.conv_block:
x = layer(x)
scale3_result = self.scale3_output(x)
scale2_up = self.upsample(self.scale2_upsample(x))
x = torch.cat([x2 , scale2_up],dim = 1)
for layer in self.scale2_convblock :
x = layer(x)
x2 = x
scale2_result = self.scale2_output(x)
scale1_up = self.upsample(self.scale1_upsample(x2))
x = torch.cat([x1 , scale1_up],dim = 1)
for layer in self.scale1_convblock :
x = layer(x)
scale1_result = self.scale1_output(x)
return scale3_result , scale2_result , scale1_result
おお・・・、完成した・・・!
モデルの出力を確認する
とりあえず組めたので、モデルがどういう出力を返すのか確認しましょう。(ミスしているとこの段階でエラーが出ます)
model = YOLOv3()
with torch.no_grad():
output = model(torch.zeros((1,3,416,416)))
for i in range(3):
print(output[i].shape)
#torch.Size([1, 255, 13, 13])
#torch.Size([1, 255, 26, 26])
#torch.Size([1, 255, 52, 52])
とりあえず動いているみたいですね。モデルの構築は以上です!やったー-!
データの準備
実験するにはデータが必要です。今回はYOLOv5で準備されているCOCO128を利用します!
AnchorBoxを定義する
YOLOでは一般的にAnchorBoxを利用します。アンカーボックスはアノテーションされたデータセットを基準に決定します。
今回はk-Meansを利用してデータセットのアノテーションをクラスタリングし、その結果をAnchorBoxにしました。
まずはデータからクラスタリングを行い、各データがどのクラスに属するか決定します。
最初に示した図から、YOLOv3はAnchorBoxを9つ持っているので、9つのクラスタリングを行います。
import os
import glob
import pandas as pd
from sklearn.cluster import KMeans
label_path = "/content/coco128/coco128/labels/train2017"
label_list = glob.glob(os.path.join(label_path , '*'))
img_size = 416
bbox_dict = {'width':[] , 'height':[]}
bbox_list = []
for path in label_list:
with open(path , 'r',newline='\n') as f:
for s_line in f:
bbox = [float(x) for x in s_line.rstrip('\n').split(' ')]
bbox_dict['width'].append(bbox[3])
bbox_dict['height'].append(bbox[4])
bbox_list.append(bbox[3:5])
df = pd.DataFrame(bbox_dict)
print(df.head())
km = KMeans(n_clusters=9,
init='random',
n_init=10,
max_iter=300,
tol=1e-04,
random_state=0)
y_km = km.fit_predict(bbox_list)
df['cluster'] = y_km
print(df.head())
最後にAnchorを決めます。
anchor_dict = {"width":[],"height":[],"area":[]}
for i in range(9):
anchor_dict["width"].append(df[df["cluster"] == i].mean()["width"])
anchor_dict["height"].append(df[df["cluster"] == i].mean()["height"])
anchor_dict["area"].append(df[df["cluster"] == i].mean()["width"]*df[df["cluster"] == i].mean()["height"])
anchor = pd.DataFrame(anchor_dict).sort_values('area', ascending=False)
anchor["type"] = [int(img_size/32) ,int(img_size/32) ,int(img_size/32) , int(img_size/16) ,int(img_size/16) ,int(img_size/16) , int(img_size/8), int(img_size/8), int(img_size/8)]
print(anchor)
#width height area type
#7 0.953643 0.856002 0.816320 13
#2 0.591571 0.828589 0.490169 13
#5 0.777525 0.379511 0.295079 13
#6 0.414800 0.443691 0.184043 26
#3 0.245450 0.694372 0.170434 26
#8 0.152484 0.359089 0.054755 26
#0 0.245576 0.165619 0.040672 52
#4 0.087694 0.152691 0.013390 52
#1 0.040143 0.047590 0.001910 52
Anchorを作成できましたね!
AnchorBoxが大きいものは大きな物体なので、これらは大きな物体を検出する出力に割り当てます。
同様に、AnchorBoxが小さいものは小さな物体なので、小さな物体を検出する出力に割り当てます。
データセットを準備する
続いてYOLOv3が学習できるようにデータセットを準備しましょう。
データセットを準備する前に、YOLOv3の予測方法についてちょっと説明します。
YOLOv3は、論文から
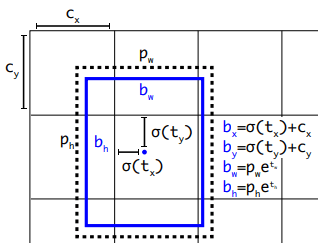
のように予測します。
ここで、
まずは幅と高さの推定方法について説明します。
幅と高さの推定方法
YOLOv3では次の式で幅と高さを推定します。
YOLOv3の出力は
直接物体の幅・高さを予測するのではなく、AnchorBoxの微調整を学習することで学習コストを大幅に削減することが期待できます。
中心位置の推定方法
YOLOv3では次の式で中心位置を推定します。
なぜへんてこな式で予測しているのでしょうか?
例えばサイズが416x416の画像に物体が写っており、その物体の中心が(200 , 250)だとします。
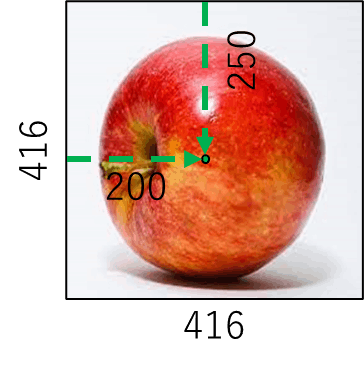
中心が存在するピクセルは 200px,250pxですね。
この物体は大きいので、特徴マップが小さなもので予測をします。特徴マップが13 x 13 pxだと中心はどこになるでしょうか?
画像サイズに対する中心の位置は
なので、13 x 13 pxでは(6.253 , 7.800)となります。
小数点以下はピクセルで表せないので、ピクセルレベルだと(7 , 6)(オレンジの点)までしか中央を表せません。
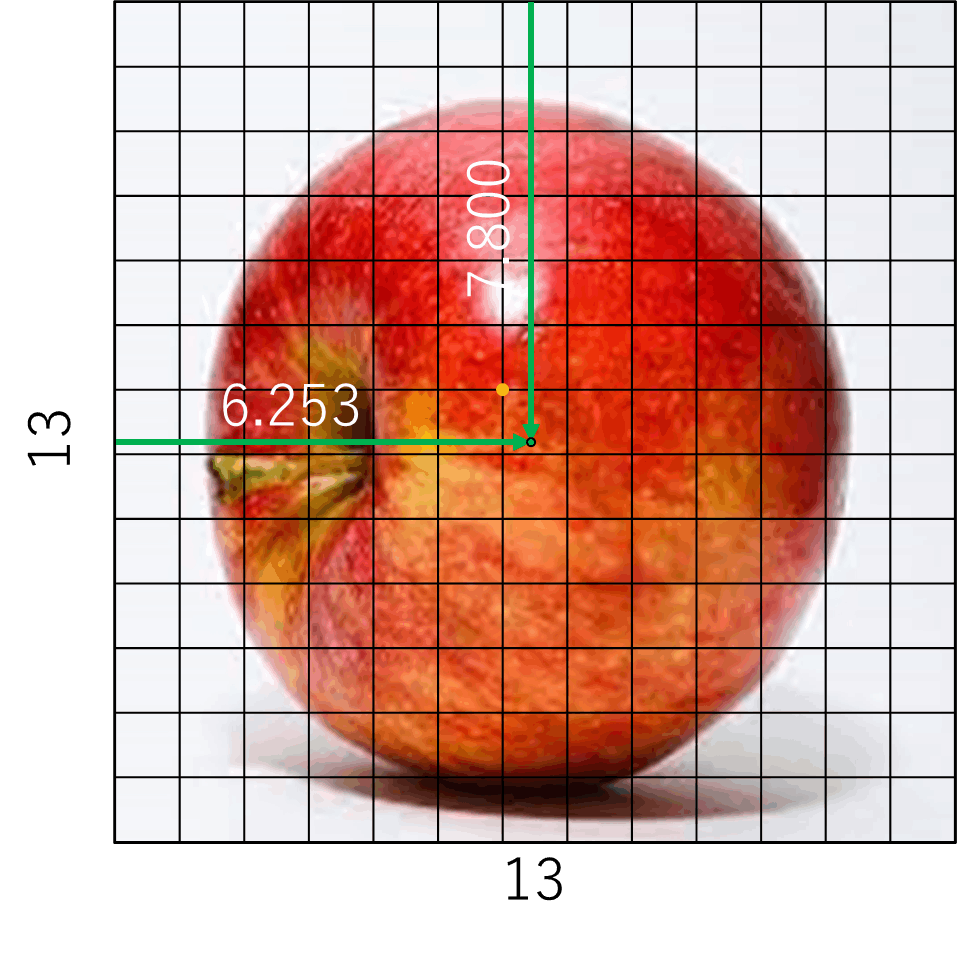
これでは特徴マップが小さくなるにつれて大きな誤差を含むことになります。
そこでYOLOv3ではピクセル内のどこに中心があるかを予測するようにしています。
YOLOv3の出力
今回の場合だと、ピクセル(7 , 6)から(0.253 , 0.800)のところにあるという風に考えることができます。
YOLOv3は
ここまでを振り返ると・・・
ここまでを振り返ると、YOLOv3の予測はAnchorBoxを微調整したり、ピクセル間の誤差補正を予測したりしている、微調整検出マンだということがわかります。
しかし、アノテーションデータは真の中心位置と幅・高さのみとなります。
そのためデータセットをYOLOv3の微調整用に変換する必要があります。
まずは幅と高さから考えましょう。
だったので、
と変換できます。同様に中心位置も変換してみましょう!
なので、
となります。ここでシグモイド関数の逆関数はロジット関数なので、
とすることで導くことが可能です。これを用いて実際にデータセットを記述していきましょう!
データセットを実際に構築していく
まずは必要な部分から構築していきます。
データセットの引数には、画像パスとラベルパスのリスト、クラス数、画像サイズとAnchorBoxの辞書、前処理のtransformを指定しています。
from six import b
from torch.utils.data import Dataset,DataLoader
import cv2
from PIL import Image
import math
import numpy as np
from torchvision.ops.boxes import box_iou
class YOLOv3_Dataset(Dataset):
def __init__(self,img_list , label_list,class_n,img_size,anchor_dict,transform):
super().__init__()
self.img_list = img_list
self.label_list = label_list
self.anchor_dict = anchor_dict
self.class_n = class_n
self.img_size = img_size
self.transform = transform
self.anchor_iou = torch.cat([torch.zeros(9,2) , torch.tensor(self.anchor_dict[["width","height"]].values)] ,dim = 1)
関数内にあるself.anchor_iouは、AnchorBoxを二次元のテンソルに落とし込んだものです。
では順番に作っていきましょう!
ラベルを読み出す関数
ラベルを読み出す関数は次のように構築しました。
def get_label(self , path):
bbox_list = []
with open(path , 'r',newline='\n') as f:
for s_line in f:
bbox = [float(x) for x in s_line.rstrip('\n').split(' ')]
bbox_list.append(bbox)
return bbox_list
うーん、もうちょっといい方法あるのかな?
幅・高さをt_w,t_h
def wh2twth(self, wh):
twth = []
for i in range(9):
anchor = self.anchor_dict.iloc[i]
aw = anchor["width"]
ah = anchor["height"]
twth.append([math.log(wh[0]/aw) , math.log(wh[1]/ah)])
return twth
一つの幅高さを、すべてのanchorに対して計算しています。多分これは対象のanchorだけに変更することができると思います。とりあえずこのまま・・・。
中心座標をC_x,C_y,t_x,t_y
def cxcy2txty(self,cxcy):
map_size = [int(self.img_size/32) , int(self.img_size/16) , int(self.img_size/8)]
txty = []
for size in map_size:
grid_x = int(cxcy[0]*size)
grid_y = int(cxcy[1]*size)
tx = math.log((cxcy[0]*size - grid_x + 1e-10) / (1 - cxcy[0]*size +grid_x+ 1e-10))
ty = math.log((cxcy[1]*size - grid_y+ 1e-10) / (1 - cxcy[1]*size + grid_y+ 1e-10))
txty.append([grid_x , tx , grid_y ,ty])
return txty
すべての出力サイズに対して計算をしています。これも特定のサイズのみで十分なのですが、とりあえずこのまま・・・。
ラベルをテンソルに変換する関数
def label2tensor(self , bbox_list):
map_size = [int(self.img_size/32) , int(self.img_size/16) , int(self.img_size/8)]
tensor_list = []
for size in map_size:
for x in range(3):
tensor_list.append(torch.zeros((4 + 1 + self.class_n,size,size)))
for bbox in bbox_list:
cls_n = int(bbox[0])
txty_list = self.cxcy2txty(bbox[1:3])
twth_list = self.wh2twth(bbox[3:])
label_iou = torch.cat([torch.zeros((1,2)) , torch.tensor(bbox[3:]).unsqueeze(0)],dim=1)
iou = box_iou(label_iou, self.anchor_iou)[0]
obj_idx = torch.argmax(iou).item()
for i , twth in enumerate(twth_list):
tensor = tensor_list[i]
txty = txty_list[int(i/3)]
if i == obj_idx:
tensor[0,txty[2],txty[0]] = txty[1]
tensor[1,txty[2],txty[0]] = txty[3]
tensor[2,txty[2],txty[0]] = twth[0]
tensor[3,txty[2],txty[0]] = twth[1]
tensor[4,txty[2],txty[0]] = 1
tensor[5 + cls_n,txty[2],txty[0]] = 1
scale3_label = torch.cat(tensor_list[0:3] , dim = 0)
scale2_label = torch.cat(tensor_list[3:6] , dim = 0)
scale1_label = torch.cat(tensor_list[6:] , dim = 0)
return scale3_label , scale2_label , scale1_label
やっていることは今までの変換内容をテンソルに入れ込んでいるだけです。
ここで注意点が。YOLOv3はラベルのバウンディングボックスサイズと最も形状が近いAnchorBoxを持つもののみが学習をします。
なので、同一物体に対して学習できるのは1つとなります。
バウンディングボックスと最も形状が近いAnchorBoxはIoUを用いて計算します。
上のコードの
label_iou = torch.cat([torch.zeros((1,2)) , torch.tensor(bbox[3:]).unsqueeze(0)],dim=1)
iou = box_iou(label_iou, self.anchor_iou)[0]
obj_idx = torch.argmax(iou).item()
の部分ですね。まったく似てないAnchorで学習をしてもうまく予測できなくなるので注意が必要です!
これらをひとまとめにするとこのようになりました!
from six import b
from torch.utils.data import Dataset,DataLoader
import cv2
from PIL import Image
import math
import numpy as np
from torchvision.ops.boxes import box_iou
class YOLOv3_Dataset(Dataset):
def __init__(self,img_list , label_list,class_n,img_size,anchor_dict,transform):
super().__init__()
self.img_list = img_list
self.label_list = label_list
self.anchor_dict = anchor_dict
self.class_n = class_n
self.img_size = img_size
self.transform = transform
self.anchor_iou = torch.cat([torch.zeros(9,2) , torch.tensor(self.anchor_dict[["width","height"]].values)] ,dim = 1)
def get_label(self , path):
bbox_list = []
with open(path , 'r',newline='\n') as f:
for s_line in f:
bbox = [float(x) for x in s_line.rstrip('\n').split(' ')]
bbox_list.append(bbox)
return bbox_list
def wh2twth(self, wh):
twth = []
for i in range(9):
anchor = self.anchor_dict.iloc[i]
aw = anchor["width"]
ah = anchor["height"]
twth.append([math.log(wh[0]/aw) , math.log(wh[1]/ah)])
return twth
def cxcy2txty(self,cxcy):
map_size = [int(self.img_size/32) , int(self.img_size/16) , int(self.img_size/8)]
txty = []
for size in map_size:
grid_x = int(cxcy[0]*size)
grid_y = int(cxcy[1]*size)
tx = math.log((cxcy[0]*size - grid_x + 1e-10) / (1 - cxcy[0]*size +grid_x+ 1e-10))
ty = math.log((cxcy[1]*size - grid_y+ 1e-10) / (1 - cxcy[1]*size + grid_y+ 1e-10))
txty.append([grid_x , tx , grid_y ,ty])
return txty
def label2tensor(self , bbox_list):
map_size = [int(self.img_size/32) , int(self.img_size/16) , int(self.img_size/8)]
tensor_list = []
for size in map_size:
for x in range(3):
tensor_list.append(torch.zeros((4 + 1 + self.class_n,size,size)))
for bbox in bbox_list:
cls_n = int(bbox[0])
txty_list = self.cxcy2txty(bbox[1:3])
twth_list = self.wh2twth(bbox[3:])
label_iou = torch.cat([torch.zeros((1,2)) , torch.tensor(bbox[3:]).unsqueeze(0)],dim=1)
iou = box_iou(label_iou, self.anchor_iou)[0]
obj_idx = torch.argmax(iou).item()
for i , twth in enumerate(twth_list):
tensor = tensor_list[i]
txty = txty_list[int(i/3)]
if i == obj_idx:
tensor[0,txty[2],txty[0]] = txty[1]
tensor[1,txty[2],txty[0]] = txty[3]
tensor[2,txty[2],txty[0]] = twth[0]
tensor[3,txty[2],txty[0]] = twth[1]
tensor[4,txty[2],txty[0]] = 1
tensor[5 + cls_n,txty[2],txty[0]] = 1
scale3_label = torch.cat(tensor_list[0:3] , dim = 0)
scale2_label = torch.cat(tensor_list[3:6] , dim = 0)
scale1_label = torch.cat(tensor_list[6:] , dim = 0)
return scale3_label , scale2_label , scale1_label
def __getitem__(self , idx):
img_path = self.img_list[idx]
label_path = self.label_list[idx]
bbox_list = self.get_label(label_path)
img = cv2.imread(img_path)
img = cv2.resize(img , (self.img_size , self.img_size))
img = Image.fromarray(img)
img = self.transform(img)
scale3_label , scale2_label , scale1_label = self.label2tensor(bbox_list)
return img , scale3_label , scale2_label , scale1_label
def __len__(self):
return len(self.img_list)
データセットの確認
では、構築したデータセットが正しく動いているか確認しておきましょう!
import numpy as np
def visualization(y_pred,anchor,img_size,conf = 0.5,is_label = False):
size = y_pred.shape[2]
anchor_size = anchor[anchor["type"] == size]
bbox_list = []
for i in range(3):
a = anchor_size.iloc[i]
grid = img_size/size
y_pred_cut = y_pred[0,i*(4 + 1 + class_n) :(i+1)*(4 + 1 + class_n) ].cpu()
if is_label:
y_pred_conf = y_pred_cut[4,:,:].cpu().numpy()
else:
y_pred_conf = torch.sigmoid(y_pred_cut[4,:,:]).cpu().numpy()
index = np.where(y_pred_conf > conf)
for y,x in zip(index[0],index[1]):
cx = x*grid + torch.sigmoid(y_pred_cut[0,y,x]).numpy()*grid
cy = y*grid + torch.sigmoid(y_pred_cut[1,y,x]).numpy()*grid
width = a["width"]*torch.exp(y_pred_cut[2,y,x]).numpy()*img_size
height = a["height"]*torch.exp(y_pred_cut[3,y,x]).numpy()*img_size
xmin,ymin,xmax,ymax = cx - width/2 , cy - height/2 ,cx + width/2 , cy + height/2
bbox_list.append([xmin,ymin,xmax,ymax])
return bbox_list
import torchvision.transforms.functional as FF
def show(imgs):
if not isinstance(imgs, list):
imgs = [imgs]
fix, axs = plt.subplots(ncols=len(imgs), squeeze=False)
for i, img in enumerate(imgs):
img = img.detach()
img = FF.to_pil_image(img)
axs[0, i].imshow(np.asarray(img))
axs[0, i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
from torchvision.io import read_image
from torchvision.utils import draw_bounding_boxes
import matplotlib.pyplot as plt
img_list = glob.glob(os.path.join("/content/coco128/coco128/images/train2017","*"))
img_size = 416
print(anchor)
import torchvision.transforms as T
class_n = 80
img_list = sorted(glob.glob(os.path.join("/content/coco128/coco128/images/train2017","*")))
label_list = sorted(glob.glob(os.path.join("/content/coco128/coco128/labels/train2017","*")))
transform = T.Compose([T.ToTensor()])
train_data = YOLOv3_Dataset(img_list,label_list,80,img_size , anchor,transform)
train_loader = DataLoader(train_data , batch_size = 1)
for n , (img , scale3_label , scale2_label ,scale1_label) in enumerate(train_loader):
path = img_list[n]
img = cv2.imread(path)[:,:,::-1]
img = cv2.resize(img , (img_size , img_size))
img = torch.tensor(img.transpose(2,0,1))
preds = [scale3_label , scale2_label , scale1_label]
for color,pred in zip(["red","green","blue"],preds):
bbox_list = visualization(pred,anchor,img_size,conf = 0.9,is_label = True)
img = draw_bounding_boxes(img, torch.tensor(bbox_list), colors=color, width=1)
show(img)
こんな感じで出力されていれば成功です!

バウンディングボックスのが違うのは、どのサイズの出力層が学習するかを表しています。
- 赤:大きなサイズを予測する層(構成図のScale3)
- 緑:中くらいのサイズを予測する層(構成図のScale2)
- 青:小さなサイズを予測する層(構成図のScale1)
以上でデータセットの準備は完了です!おつかれさまでしたー!
損失関数を実装
最後に損失関数を実装しましょう。損失関数は

となっています。愚直に実装しましょう!
criterion_bce = torch.nn.BCEWithLogitsLoss()
def bbox_metric(y_pred , y_true,class_n = 80):
for i in range(3):
y_pred_cut = y_pred[:,i*(4 + 1 + class_n) :(i+1)*(4 + 1 + class_n) ]
y_true_cut = y_true[:,i*(4 + 1 + class_n) :(i+1)*(4 + 1 + class_n) ]
loss_coord = torch.sum(torch.square(y_pred_cut[:,0:4] - y_true_cut[:,0:4])*y_true_cut[:,4])
loss_obj = torch.sum((-1 * torch.log(torch.sigmoid(y_pred_cut[:,4] )+ 1e-10) + criterion_bce(y_pred_cut[:,5:],y_true_cut[:,5:]))*y_true_cut[:,4])
loss_noobj = torch.sum((-1 * torch.log(1 - torch.sigmoid(y_pred_cut[:,4])+ 1e-10))*(1 - y_true_cut[:,4]))
return loss_coord , loss_obj , loss_noobj
上の関数では、入力を各スケールごとにしています。
各スケールではboxが3つあるので、
for i in range(3):
y_pred_cut = y_pred[:,i*(4 + 1 + class_n) :(i+1)*(4 + 1 + class_n) ]
y_true_cut = y_true[:,i*(4 + 1 + class_n) :(i+1)*(4 + 1 + class_n) ]
で分割して、以降の計算を行っています!
学習しよう
ここまで来たら、あとは学習するのみです!
以下に学習コードを記載します!
from tqdm import tqdm
class_n = 80
model = YOLOv3().to('cuda')
optimizer = torch.optim.Adam(model.parameters())
lambda_coord = 1
lambda_obj = 10
lambda_noobj = 1
conf = 0.5
best_loss = 99999
for epoch in range(300):
total_train_loss = 0
total_train_loss_coord = 0
total_train_loss_obj = 0
total_train_loss_noobj = 0
with tqdm(train_loader) as pbar:
pbar.set_description("[train] Epoch %d" % epoch)
for n , (img , scale3_label , scale2_label ,scale1_label) in enumerate(pbar):
optimizer.zero_grad()
img = img.cuda()
scale1_label = scale1_label.cuda()
scale2_label = scale2_label.cuda()
scale3_label = scale3_label.cuda()
labels = [scale3_label , scale2_label ,scale1_label]
preds = list(model(img))
loss_coord = 0
loss_obj = 0
loss_noobj = 0
for label , pred in zip(labels , preds):
_loss_coord , _loss_obj , _loss_noobj = bbox_metric(pred , label)
loss_coord += _loss_coord
loss_obj += _loss_obj
loss_noobj += _loss_noobj
loss = lambda_coord*loss_coord + lambda_obj*loss_obj + lambda_noobj*loss_noobj
total_train_loss += loss.item()
total_train_loss_coord += loss_coord.item()
total_train_loss_obj += loss_obj.item()
total_train_loss_noobj += loss_noobj.item()
loss.backward()
optimizer.step()
pbar.set_description("[train] Epoch %d loss %f loss_coord %f loss_obj %f loss_noobj %f" % (epoch ,total_train_loss/(n+1),total_train_loss_coord/(n+1) , total_train_loss_obj/(n+1),total_train_loss_noobj/(n+1)))
if best_loss > total_train_loss/(n+1):
model_path = 'model.pth'
torch.save(model.state_dict(), model_path)
best_loss = total_train_loss/(n+1)
loss_coord,loss_obj,loss_noobjの重みは、
lambda_coord = 1
lambda_obj = 10
lambda_noobj = 1
で決定しています。
[train] Epoch 0 loss 286.405978 loss_coord 8.636225 loss_obj 5.200393 loss_noobj 225.765828: 100%|██████████| 128/128 [00:17<00:00, 7.53it/s]
[train] Epoch 1 loss 102.405287 loss_coord 10.209075 loss_obj 6.452265 loss_noobj 27.673560: 100%|██████████| 128/128 [00:17<00:00, 7.44it/s]
[train] Epoch 2 loss 102.833235 loss_coord 13.040047 loss_obj 6.941306 loss_noobj 20.380132: 100%|██████████| 128/128 [00:16<00:00, 7.54it/s]
[train] Epoch 3 loss 104.517658 loss_coord 15.754182 loss_obj 7.285496 loss_noobj 15.908514: 100%|██████████| 128/128 [00:16<00:00, 7.55it/s]
[train] Epoch 4 loss 97.555768 loss_coord 9.416801 loss_obj 7.300497 loss_noobj 15.134000: 100%|██████████| 128/128 [00:16<00:00, 7.58it/s]
[train] Epoch 5 loss 94.218886 loss_coord 8.056409 loss_obj 7.216737 loss_noobj 13.995110: 100%|██████████| 128/128 [00:16<00:00, 7.54it/s]
[train] Epoch 6 loss 93.856368 loss_coord 8.066146 loss_obj 7.152021 loss_noobj 14.270010: 100%|██████████| 128/128 [00:16<00:00, 7.53it/s]
のように出力されれば学習は進んでいます。
今回はYOLOv3がどのように動いているかを確認するためにモデルを組んでいるので、検証用データなどは準備しませんでした。(本当は準備する必要があります・・・)
とりあえず動作が確認できればOK!
出力を確認する
それでは最後に出力を確認してみましょう!
from torchvision.io import read_image
from torchvision.utils import draw_bounding_boxes
import matplotlib.pyplot as plt
img_list = sorted(glob.glob(os.path.join("/content/coco128/coco128/images/train2017","*")))
img_size = 416
model_path = 'model.pth'
model.load_state_dict(torch.load(model_path))
model = model.cuda()
for path in img_list:
img = cv2.imread(path)
img = cv2.resize(img , (img_size , img_size))
img = Image.fromarray(img)
img = transform(img).unsqueeze(0).cuda()
with torch.no_grad():
preds = list(model(img))
img = cv2.imread(path)[:,:,::-1]
img = cv2.resize(img , (img_size , img_size))
img = torch.tensor(img.transpose(2,0,1))
for color,pred in zip(["red","green","blue"],preds):
bbox_list = visualization(pred,anchor,img_size,conf = 0.9)
img = draw_bounding_boxes(img, torch.tensor(bbox_list), colors=color, width=1)
show(img)

・・・。できているものもあればできていないものもありますね。
素組でそのほかのチューニングを全くしておらず、データも少ないとこのような感じなんでしょうか?(モデルの構造自体が若干違う可能性が高い気もします)
とりあえず、動作のすべてを構築できたので、今回は良しとします!
まとめ
今回はYOLOv3をゼロから構築してみました!思ったより大変ですね・・・。
次こそは、CenterNetを構築したい・・・!(と言いつつ別のことをしている未来が見える)
ではまた~。
Discussion