SchemaSpyでPostgreSQLのenum、geometry(PostGIS)を詳しく出力する
この記事は PostgreSQL - Qiita Advent Calendar 2024 - Qiita の3日目の記事になります。
SchemaSpy とは
SchemaSpyは、データベースの情報を元に、ER図やテーブル、カラム一覧などの情報をHTML形式のドキュメントとして出力するツールです。
アプリケーションの改修に応じて、データベースのマイグレーションをコード or SQLで書いていくようなことが多いと思います。
そうなってくると、ER図を別途管理するのは二重管理になりがちなので、マイグレーション後の状態からSchemaSpyでER図を作成するといった方法はとても便利です。
SchemaSpyは自分にとって欠かせないツールの一つなっています。
SchemaSpy における PostgreSQL の enum、geometry(PostGIS) の情報
SchemaSpyでPostgreSQLのenumとgeometry(PostGIS)ですが、カラムのTypeとして出力されるのは下記のようになります。
- enum は enum の名前が出力
- geomerty は一律
geomertyとして出力
例えば下記のようなテーブルを作成した場合
CREATE TYPE place_type AS ENUM ('city', 'park', 'lake', 'mountain');
CREATE TABLE locations (
location_id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
type place_type NOT NULL,
coordinates GEOMETRY(Point, 4326) NOT NULL,
region_id INTEGER REFERENCES regions(region_id) ON DELETE CASCADE,
created_at TIMESTAMPTZ DEFAULT statement_timestamp()
);
COMMENT ON TABLE locations IS '場所情報';
COMMENT ON COLUMN locations.location_id IS '場所ID';
COMMENT ON COLUMN locations.name IS '場所名';
COMMENT ON COLUMN locations.type IS '場所の種類';
COMMENT ON COLUMN locations.coordinates IS '座標情報(ポイント)';
COMMENT ON COLUMN locations.region_id IS '地域ID';
COMMENT ON COLUMN locations.created_at IS '作成日時';
SchemaSpyで出力される内容は下記の通りです。
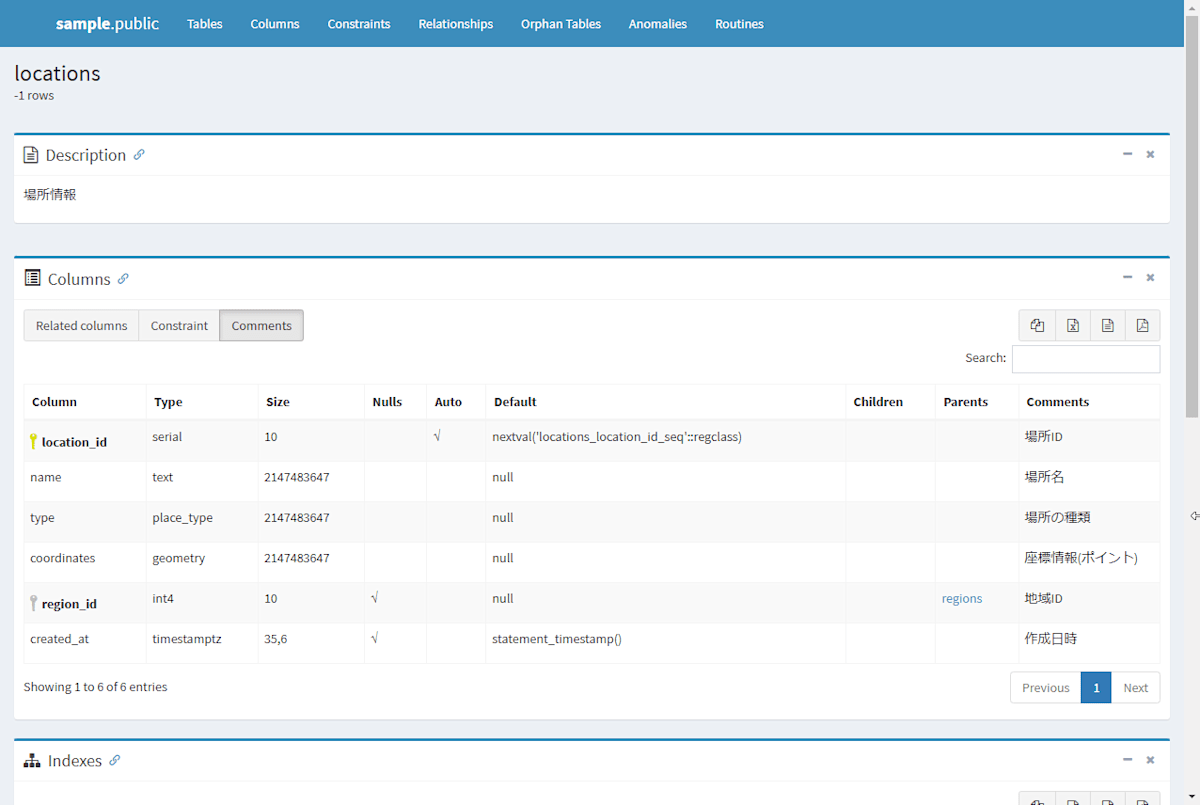
enum と geometry となるカラムは下記のようになりました。

デフォルトだとこのような内容ですが、さらに下記の情報がわかるとより良くなりそうです。
- enum は値の選択肢も
- geomerty はサブタイプ(
PointやLineStringなど)やSRIDの情報も
SchemaSpyでTypeとして表示する内容をカスタマイズする方法
ということで、SchemaSpyをカスタマイズすることで、先ほど挙げた情報を出力できるようにします。
DatabaseType とは
SchemaSpyでは、DatabaseTypeというものがあり、実行時にこれを指定して、各データベースに応じた処理が行われるようになっています。
設定ファイルだとschemaspy.t、コマンドライン引数の場合は-tで指定するものがDatabaseTypeです。
PostgreSQLだとpgsql11を指定することになります。(11からはこれ)
どんなDatabaseTypeがあるかは、ドキュメントでは見つけられなかったのですが、下記フォルダを見るとわかります。
DatabaseTypeにselectColumnTypesSqlという設定があり、SQLでカラムのTypeの内容を変えられるようになっています。
selectColumnTypesSql=
Fetch column type for all columns, expected columns: table_name, column_name, column_type, short_column_type
column_typeとshort_column_typeといった二種類がありますが、short_column_typeはリレーションをダイアグラムで表示する際(表示領域が狭い)ところで利用されるものになります。
DatabaseType の追加方法
selectColumnTypesSqlを設定する=新規のDatabaseTypeとして設定する必要があります。設定はファイルとして書き、ファイル名がDatabaseTypeの名前となります。
といっても全ての定義を書く必要は無く、ベースとなる設定を元にして、上書きしたいものを指定するような形となっています。
今回はPostgreSQLを対象にするので、extends=pgsql11としたうえで、selectColumnTypesSql=でSQLを書く形になります。
extends=pgsql11
selectColumnTypesSql=<SQLを書く>
DatabaseTypeのファイル検索パスは下記に記載の通りです。
この後に実際に試す際には、実行時のカレントフォルダに配置することで対応します。
enum で値の選択肢を出すように設定する
まずはenumで値の選択肢を出すようにしてみます。
SQLは下記のようになりました。
WITH
enum_values AS (
SELECT
pg_namespace.nspname AS table_schema,
pg_type.typname AS enum_name,
string_agg(
pg_enum.enumlabel,
', '
ORDER BY
pg_enum.enumsortorder
) AS enum_labels
FROM
pg_type
INNER JOIN pg_enum ON (pg_type.oid = pg_enum.enumtypid)
INNER JOIN pg_namespace ON (pg_type.typnamespace = pg_namespace.oid)
WHERE
pg_type.typtype = 'e'
GROUP BY
pg_namespace.nspname,
pg_type.typname
)
SELECT
c.table_name,
c.column_name,
CASE
WHEN c.data_type = 'USER-DEFINED'
AND ev.enum_name IS NOT NULL THEN ev.enum_name || '(' || ev.enum_labels || ')'
ELSE c.udt_name
END AS column_type,
c.udt_name AS short_column_type
FROM
information_schema.columns c
LEFT JOIN enum_values ev ON c.table_schema = ev.table_schema
AND c.udt_name = ev.enum_name
WHERE
c.table_schema = 'public';
enumの選択肢はpg_enumから取得可能なので、pg_enumの内容を, で結合した形にしました。
short_column_typeでは選択肢は入れないようにすることで、リレーションをダイアグラムで表示する箇所では、余計な領域を取ることが無いようにしています。
これをDatabaseTypeとして設定します。名前はpgsql-enumとしました。
extends=pgsql11
selectColumnTypesSql=WITH enum_values AS (SELECT pg_namespace.nspname AS table_schema, pg_type.typname AS enum_name, string_agg(pg_enum.enumlabel, ', ' ORDER BY pg_enum.enumsortorder) AS enum_labels FROM pg_type INNER JOIN pg_enum ON (pg_type.oid = pg_enum.enumtypid) INNER JOIN pg_namespace ON (pg_type.typnamespace = pg_namespace.oid) WHERE pg_type.typtype = 'e' GROUP BY pg_namespace.nspname, pg_type.typname) SELECT c.table_name, c.column_name, CASE WHEN c.data_type = 'USER-DEFINED' AND ev.enum_name IS NOT NULL THEN ev.enum_name || '(' || ev.enum_labels || ')' ELSE c.udt_name END AS column_type, c.udt_name AS short_column_type FROM information_schema.columns c LEFT JOIN enum_values ev ON c.table_schema = ev.table_schema AND c.udt_name = ev.enum_name WHERE c.table_schema = :schema
スキーマ名はSchemaSpy側から指定されるので:schemaとして指定(WHERE c.table_schema = :schema)しておくことになります。
今回は、実行するにあたり、SchemaSpyの接続情報などもpropertiesファイルとして定義しておきます。ポイントは、schemaspy.tとして今回追加したDatabaseTypeを指定するところだけです。
schemaspy.t=pgsql-enum
schemaspy.dp=drivers
schemaspy.host=db
schemaspy.port=5432
schemaspy.db=sample
schemaspy.u=db_user
schemaspy.p=db_password
schemaspy.o=output-enum
schemaspy.s=public
これらファイルを同じフォルダに配置し、
.
├── drivers
│ └── postgresql-42.7.4.jar
├── pgsql-enum.properties
├── schemaspy-6.2.4.jar
└── schemaspy-enum.properties
実行します。
java -jar schemaspy-6.2.4.jar -configFile schemaspy-enum.properties
下記のようにenumの値が表示されるようになりました。わかりやすくなりましたね!


ダイアグラムとして表示される箇所はshort_column_typeでの値となるので、今まで通り値無しです。

さらに geomerty でサブタイプとSRIDの情報も出すように設定する
追加で geomerty のサブタイプ(PointやLineStringなど)とSRIDも出すようにします。
(PostGISで追加される情報を利用しているので、geometryを出す必要が無い場合にはenumだけのものをご利用ください)
SQLは下記のようになりました。
WITH
enum_values AS (
SELECT
pg_namespace.nspname AS table_schema,
pg_type.typname AS enum_name,
string_agg(
pg_enum.enumlabel,
', '
ORDER BY
pg_enum.enumsortorder
) AS enum_labels
FROM
pg_type
INNER JOIN pg_enum ON (pg_type.oid = pg_enum.enumtypid)
INNER JOIN pg_namespace ON (pg_type.typnamespace = pg_namespace.oid)
WHERE
pg_type.typtype = 'e'
GROUP BY
pg_namespace.nspname,
pg_type.typname
),
geometry_info AS (
SELECT
f_table_schema AS table_schema,
f_table_name AS table_name,
f_geometry_column AS column_name,
type || ', ' || srid AS geom_details
FROM
geometry_columns
)
SELECT
c.table_name,
c.column_name,
CASE
WHEN c.data_type = 'USER-DEFINED'
AND ev.enum_name IS NOT NULL THEN ev.enum_name || '(' || ev.enum_labels || ')'
WHEN c.data_type = 'USER-DEFINED'
AND c.udt_name = 'geometry' THEN 'geometry(' || g.geom_details || ')'
ELSE c.udt_name
END AS column_type,
c.udt_name AS short_column_type
FROM
information_schema.columns c
LEFT JOIN enum_values ev ON c.table_schema = ev.table_schema
AND c.udt_name = ev.enum_name
LEFT JOIN geometry_info g ON c.table_schema = g.table_schema
AND c.table_name = g.table_name
AND c.column_name = g.column_name
WHERE
c.table_schema = 'public';
geometryの詳細情報はgeometry_columnsから取得しています。
short_column_typeはgeometryでの表示のままにしています。
これをDatabaseTypeとして設定します。名前はpgsql-postgisとしました。
extends=pgsql11
selectColumnTypesSql=WITH enum_values AS (SELECT pg_namespace.nspname AS table_schema, pg_type.typname AS enum_name, string_agg(pg_enum.enumlabel, ', ' ORDER BY pg_enum.enumsortorder) AS enum_labels FROM pg_type INNER JOIN pg_enum ON (pg_type.oid = pg_enum.enumtypid) INNER JOIN pg_namespace ON (pg_type.typnamespace = pg_namespace.oid) WHERE pg_type.typtype = 'e' GROUP BY pg_namespace.nspname, pg_type.typname), geometry_info AS (SELECT f_table_schema AS table_schema, f_table_name AS table_name, f_geometry_column AS column_name, type || ', ' || srid AS geom_details FROM geometry_columns) SELECT c.table_name, c.column_name, CASE WHEN c.data_type = 'USER-DEFINED' AND ev.enum_name IS NOT NULL THEN ev.enum_name || '(' || ev.enum_labels || ')' WHEN c.data_type = 'USER-DEFINED' AND c.udt_name = 'geometry' THEN 'geometry(' || g.geom_details || ')' ELSE c.udt_name END AS column_type, c.udt_name AS short_column_type FROM information_schema.columns c LEFT JOIN enum_values ev ON c.table_schema = ev.table_schema AND c.udt_name = ev.enum_name LEFT JOIN geometry_info g ON c.table_schema = g.table_schema AND c.table_name = g.table_name AND c.column_name = g.column_name WHERE c.table_schema = :schema
実行は先ほどのenumの時と同様です。
schemaspy.t=pgsql-postgis
schemaspy.dp=drivers
schemaspy.host=db
schemaspy.port=5432
schemaspy.db=sample
schemaspy.u=db_user
schemaspy.p=db_password
schemaspy.o=output-postgis
schemaspy.s=public
これらファイルを同じフォルダに配置し、
.
├── drivers
│ └── postgresql-42.7.4.jar
├── pgsql-postgis.properties
├── schemaspy-6.2.4.jar
└── schemaspy-postgis.properties
実行します。
java -jar schemaspy-6.2.4.jar -configFile schemaspy-postgis.properties
下記のようにgeomertyのサブタイプとSRIDの値が表示されるようになりました。さらにわかりやすくなりましたね!


ダイアグラムとして表示される箇所はshort_column_typeでの値となるので、今まで通りです。

動作確認に使ったファイル
今までの説明で利用したファイルは、下記フォルダに配置しています。
おわりに
今回の記事を書こうと思ったのは、PostGIS+SchemaSpyといった組み合わせで使った際に、geometoryとして入れられる型がSchemaSpyからわからなくて不便だな、、といったところからでした。同じような方(かなりニッチな気しますが、、)の役に立ったら幸いです!
今回はカラムのTypeに関する部分ですが、SchemaSpyには他にもカスタマイズ可能な箇所が多々あります。
ここがちょっと物足りない/余計だなといった場合には、ドキュメントを調べてみると良さそうです。
Discussion